优化多核CPU的TCP新建连接性能--重排spinlock
2018/06/05 凌晨,雨夜!
迟到的雨,还是来了!
人们几乎已经逼近了单CPU的处理时延极限,于是人们希望通过多CPU的方式来提高处理带宽,从而得到更多的处理容量,理论上讲,这无可厚非,但现实中,这太难了。
几乎所有上世纪70年代以来的操作系统都不是为多核CPU并行编程而设计的,因此当它们遇到多核CPU的各种问题时,无一不是东填西补,最终情况依然不容乐观。这里说一个典型的,就是Linux内核协议栈的可伸缩性(scalable)问题,本文主要描述TCP新建连接方面的一个可伸缩性优化措施。
传统上讲,Linux内核协议栈针对同一个Listener的TCP新建连接处理主要拥有两个瓶颈点:
- 单一的accept队列
- 单一的hash表(其实是两张,listener hash,establish hash)
TCP的新建连接会频繁操作上述两个数据结构,在多核CPU情况(后面简称SMP)下,为了保证数据的一致性,lock是绕不开的。不管多少个并行处理的CPU,在TCP新建连接时,必然要在操作上述两个数据结构时被串行化!这是悲哀的。
我们知道,随着CPU核数的增多,每秒能接纳的连接请求数也会随着增多,但由于上述两个串行化点的存在,这意味着lock冲突也会相应的增多!串行化的lock冲突意味着什么?请考虑地铁站入口,人们从多个大门涌入,最终却只有一个安检点,过了这个安检点又呈现了多个闸机…
最终,随着CPU核数的增多,性能并没有能线性地增长,最终的CPU核数/性能曲线便呈现了一种上凸的趋势。这一切都是因为锁。
我们来看一下如何进一步拆解上面两个问题。本文主要描述如何把锁进行更加细粒度的拆解,下一篇文章聊聊cache相关的内容。
单一accept队列问题的解锁
非常幸运,这个问题已经被google的reuseport机制解决了。详情请自行搜索reuseport相关的资料。
值得一提的是,新浪的fastsocket在google的reuseport机制基础上做了一个比较优雅的封装,使得应用程序不用修改就能享受到reuseport的收益,同时进一步地提高了TCP连接的可伸缩性问题。它的项目地址是:https://github.com/fastos/fastsocket
我是在2015年中接触到这个项目的,当时感觉这种实现非常棒。
单一establish hash表问题的解锁
根据我上周的压测,CPS数据获取过程中,短链接会频繁操作establish hash表,频繁调用inet_hash,inet_unhash两个函数(listener hash并不必在意,因为listener socket比较稳定,不会频繁生成和销毁),其中的热点在两个spinlock:
bool inet_ehash_insert(struct sock *sk, struct sock *osk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
struct hlist_nulls_head *list;
struct inet_ehash_bucket *head;
spinlock_t *lock;
bool ret = true;
WARN_ON_ONCE(!sk_unhashed(sk));
sk->sk_hash = sk_ehashfn(sk);
head = inet_ehash_bucket(hashinfo, sk->sk_hash);
list = &head->chain;
// 以hash bucket来lock!!
lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
spin_lock(lock); // 串行化lock
if (osk) {
WARN_ON_ONCE(sk->sk_hash != osk->sk_hash);
ret = sk_nulls_del_node_init_rcu(osk);
}
if (ret)
__sk_nulls_add_node_rcu(sk, list);
spin_unlock(lock);
return ret;
}可以看到,在当前的Linux TCP实现中,每一个hash bucket拥有一个spinlock,其实粒度已经够细了,参见我下面的文章:
Linux socket hash查找的持续优化历程:https://blog.csdn.net/dog250/article/details/80490859
在以往的年代,这里的性能更加糟糕!上述代码是4.14内核,几乎就是最新的版本了,我们看一下它的示意图:
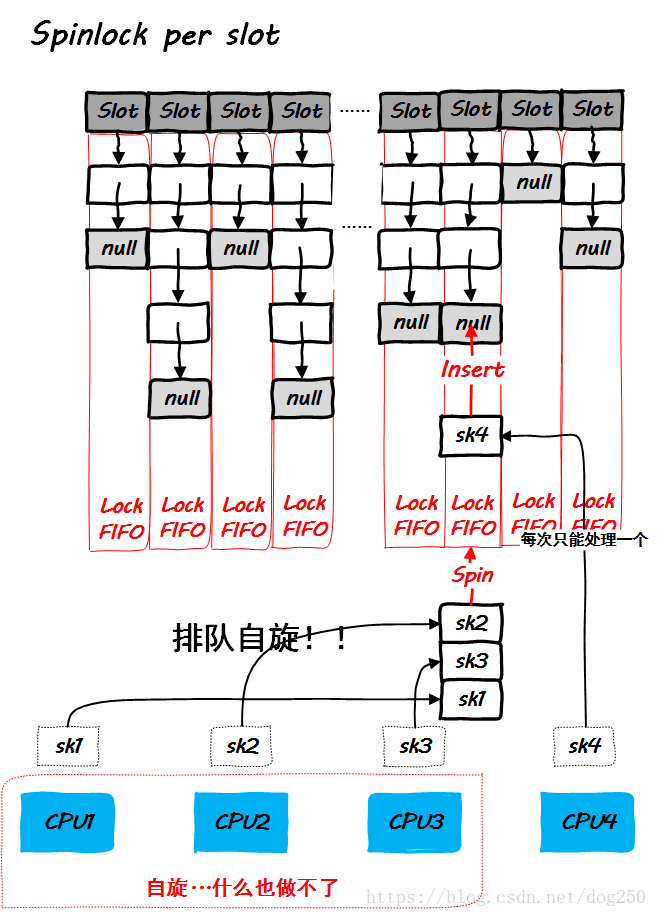
上图的窘局其实是可以破解的,只需要把per slot的spinlock再做细分即可,改为per slot per CPU的spinlock,其实就是把每一个slot的链表摊开成per cpu的即可。这里决定一个socket应该给哪个CPU先使用一个最简单的策略,即调用inet_hash的时候哪个CPU在处理,就给哪个CPU。
为此,我们需要修改下面的数据结构:
struct inet_ehash_bucket {
struct hlist_nulls_head chain;
};这个数据结构便是上图中slot,我们需要将其改成:
struct inet_ehash_bucket {
// struct hlist_nulls_head chain[NR_CPUS]
struct hlist_nulls_head *chain;
};我们稍微修改一下insert函数:
bool inet_ehash_insert(struct sock *sk, struct sock *osk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
struct hlist_nulls_head *list;
struct inet_ehash_bucket *head;
spinlock_t *lock;
bool ret = true;
// 取当前CPU!
int cpu = smp_processor_id();
WARN_ON_ONCE(!sk_unhashed(sk));
sk->sk_hash = sk_ehashfn(sk);
sk->sk_hashcpu = cpu;
head = inet_ehash_bucket(hashinfo, sk->sk_hash);
// 取出对应CPU的list
head = &head[cpu];
list = &head->chain;
lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
// 取出对应CPU的lock
lock = &lock[cpu];
spin_lock(lock);
if (osk) {
WARN_ON_ONCE(sk->sk_hash != osk->sk_hash);
ret = sk_nulls_del_node_init_rcu(osk);
}
if (ret)
__sk_nulls_add_node_rcu(sk, list);
spin_unlock(lock);
return ret;
}是不是简单快捷呢?对应的lookup也要修改,在lookup的过程中,不再recheck slot的一致性,而要recheck CPU的一致性:
struct sock *__inet_lookup_established(struct net *net,
struct inet_hashinfo *hashinfo,
const __be32 saddr, const __be16 sport,
const __be32 daddr, const u16 hnum,
const int dif, const int sdif)
{
INET_ADDR_COOKIE(acookie, saddr, daddr);
const __portpair ports = INET_COMBINED_PORTS(sport, hnum);
struct sock *sk;
const struct hlist_nulls_node *node;
unsigned int hash = inet_ehashfn(net, daddr, hnum, saddr, sport);
unsigned int slot = hash & hashinfo->ehash_mask;
struct inet_ehash_bucket *head = &hashinfo->ehash[slot];
int cpu = smp_processor_id(), self; // 从当前CPU开始!如果底层有做CPU绑定的话,这样做就对了。
self = cpu;
begin:
head = &head[cpu];
if (hlist_nulls_empty(&head->chain)) {
goto recheck2;
}
sk_nulls_for_each_rcu(sk, node, &head->chain) {
... // 逻辑不变,省略
}
if (get_nulls_value(node) != cpu) {
cpu = 0;
goto begin;
} else if (get_nulls_value(node) == cpu) {
recheck2:
cpu ++;
if (cpu >= nr_cpu_ids)
cpu = 0;
if (cpu == self)
goto out;
goto begin;
}
out:
sk = NULL;
found:
return sk;
}同时,ehash的每一个slot在初始化的时候,都要初始化成per CPU的(当然,我这里还没有用per CPU的API),并且把hlist的null尾用CPU id来初始化!
现在让我们看看采用per slot per CPU的新方案后,局面在观感上变成了什么样子:
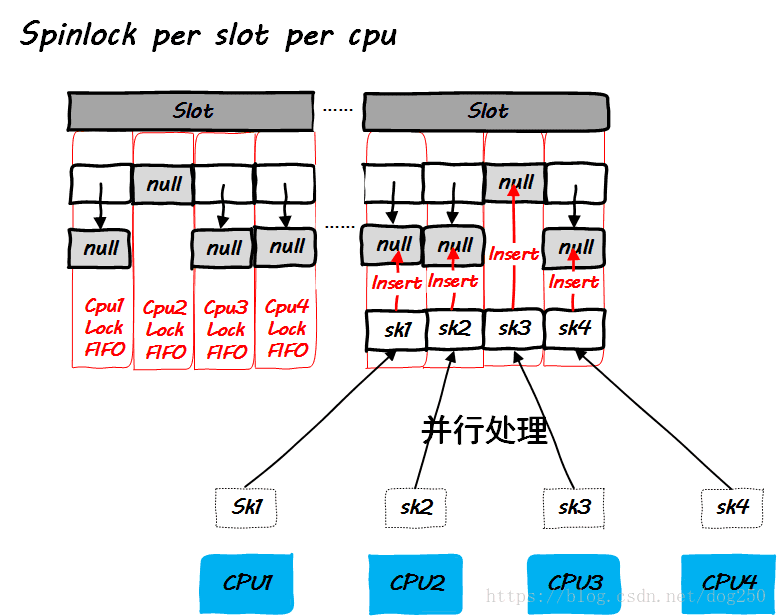
我们知道,spinlock是不可睡眠的,除了被硬中断打破,所有的CPU在调用inet_hash的时候,几乎都是可以无竞争不自旋立即完成的。但是你可能注意到了,我在上文中没有提到inet_unhash的调用,我们知道,unhash的时候也是要持有spinlock的,如何来保证unhash的调用者和当初hash的调用者是同一个CPU呢?
答案显然是不能保证,因此正如nf_conntrack里unconfirm list和dying list的per cpu处理那般,在调用unhash的时候,cpu变量必须从socket里面取出来:
void inet_unhash(struct sock *sk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
spinlock_t *lock;
bool listener = false;
int done;
if (sk_unhashed(sk))
return;
if (sk->sk_state == TCP_LISTEN) {
lock = &hashinfo->listening_hash[inet_sk_listen_hashfn(sk)].lock;
listener = true;
} else {
// 取出hash时的cpu,确保从哪里insert就从哪里remove时而一致性。
int cpu = sk->sk_hashcpu;
if (cpu != smp_processor_id()) {
DEBUG("Shit!:%d", misstat++);
}
lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
lock = &lock[cpu];
}
spin_lock_bh(lock);
...
}现在问题来了。由于Linux调度器的调度策略影响,很有可能调用unhash时的CPU已经不是当初调用hash时的那个CPU了,最终在别的CPU上处理的unhash过程还是可能和其它一个调用hash过程的CPU竞争同一把锁。然而这是没有办法的,调度器不属于协议栈的范畴,我们能做的,仅仅是避免这种情况的发生,比如通过外部的机制或者工具,对进程和CPU进行强绑定或者弱绑定,尽最大的努力避免进程在CPU之间乒乓!
预告
下一篇准备写一下单纯的Linux内核版本的spinlock存在什么问题已经如何去优化它,只要本周大雨持续,我便有更多的时间在雨夜写作,敬请期待!
我的懒惰愚笨之回顾
做出本文描述的这个优化是我周日一天完成的,后来简单压测,发现spinlock热点真的消失了,TCP CPS在我的虚拟实验环境下8核心CPU提高了30%多!很可观的数据了!这还是盲写第一版的简单测试,没有任何进一步调优。当然了,简单配置一下RPS和CPU绑定还是需要的,我说的是代码就这样子了,没有任何进一步的优化。所以总体上讲,我是快乐的!更让我快乐的是,深圳在接下来的一周,持续局部大到暴雨,我并不晓得局部到底在哪里,有时间的话,我会去追。
我不但不擅长大段大段地写代码,也不擅长搬运东西,切菜洗碗也慢,造成这一切的根源就在于我很懒惰,并且也并不聪明,所以在解决任何问题的时候,我都企图寻求最简单的方案,因为我并不聪明,所以如果我找不到,我会去请教聪明的人,希望他们告诉我,迷信点说,我一直都需要点石成金之术,和所有人一样。
和很多人不同的是,他们很聪明却也不去思考,而我虽然愚笨,却一直在努力。
就好比做饭,菜谱超过8步骤,我就放弃,因为太麻烦,用料超过10种,放弃,因为太麻烦,但我依然思考我如何能用最简单的步骤最少的食材做出美味;就好比旅游,我一个人的话,最多一个背包,或者什么都不带,跟别人一起,箱子背包超过3个我就会烦,因为我不擅长搬运,然而我还是会去想如何才能避免搬运大件物品,所以我很擅长打包!
不管怎么说,懒惰和愚笨已经深入到我生活,工作,学习,娱乐的方方面面,我相信很多人跟我一样,因为我相信正态分布和幂律,你永远不要说自己很另类,大部分的所谓自我都处在总人口的长尾。我了解这个事实并且正视它,但很多人不了解且试图规避它,我可以给他们以帮助并且实际上也真的帮助了。这也许就是我虽然不善交际,但也在很多圈子中的原因吧…