运动感知快速视频显著性检测Motion-Aware Rapid Video Saliency Detection
文章《Motion-Aware Rapid Video Saliency Detection》
链接 https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8669851
(吐槽!CSDN什么时候能从文档里直接复制公式,或者智能识别图片中的公式呀,打式子很累耶!)
摘要
本文提出了一种计算效率高、精度高的时空突出目标检测方法,用于识别视频序列中最明显的目标。直观地说,视频中潜在的运动是一个比明显的颜色暗示更稳定的显著性指标,而明显的颜色暗示通常包含明显的变化和复杂的结构。在此基础上,建立了一种高效、准确的基于运动信息的时空显著性检测方法利用它来定位视频序列中最动态的区域。我们首先对光流场进行分析,获得前景先验,然后将外观对比、紧度度量等空间显著性特征融入多线索集成框架中,将不同的显著性线索组合在一起,实现时间一致性。在具有挑战性的SegTrackV1、SegTrackV2和FBMS数据集上进行的严格实验表明,我们的方法在100×更快的情况下以0.08秒/帧的速度运行,产生了与最先进的方法相当或更好的性能。该方法具有良好的性能和较快的速度,可以方便地应用于各种视觉领域。
索引词:视频突出目标检测,快速视频显著性检测,时空突出目标检测。
I简介
突出目标检测的目的是识别场景中的突出区域,生成一个显著性映射,表示属于前景对象的像素的概率。由于其在许多计算机视觉应用(包括目标检测、动作识别和视觉数据压缩)方面的潜力,它受到了广泛的关注。
近年,许多显著性检测方法[1]-[11]被提出用于检测静态图像的显著区域,并取得了进步。与图像显著性相比,处理动态场景的工作相对较少,这主要是由于增加了问题的时间维度带来的挑战。
运动信息是视频序列中突出目标定位的关键。当外观提示变得模糊,例如由于对象模糊或背景杂乱,这是更有必要的。众所周知,在运动场景中,人类的感知更关注移动的物体而不是静态物体。因此,许多视频显著性方法总是将运动信息嵌入到它们的框架中。例如[12]、[13]、[17]、[18]可以看做是与运动线索相关的现有图像显著性机制的集合。一些视频分割方法[20]、[21]利用运动边界,而许多运动分析方法[22]、[27]、[28]完全依赖于点轨迹来确定运动对象。
然而,有些缺点是不能忽视的。现有的方法简单地看待运动信息(例如[12],[13],[15],[17],[18])将运动信息作为另一种类型的pixel-wise显著提示或倾向于强调“运动暗示”理论的影响(例如[21],[22],[27],[28]),这使得他们的模型复杂,费时,缺乏鲁棒性,以及对噪声敏感。
针对上述不足,本文提出了一种时空显著性检测方法,通过有效地利用运动线索,从视频序列中识别出明显的目标区域。在运动信息的基础上,将外观对比信息、显著性紧度等空间特征作为补充线索,进一步推断出显著性图。
我们的方法首先在光流场分析的基础上提出了一种运动线索。介绍了用于表示整个场景运动模式的主运动矢量。我们倾向于将场景中具有不同运动的区域设置为突出区域。此外,我们使用一种新的显著性传播策略来提高运动线索的鲁棒性。这种运动线索的显著性检测被证明是有效的,可以快速计算。同时,我们也将外观特征、显著性紧致等空间线索作为互补的空间信息。最后,通过多线索优化框架,系统地融合了运动线索和空间显著性线索,提高了最终结果的时空一致性。综上所述,我们提出的快速视频显著性方法与之前的工作相比有几个优势:
* 提出了一种利用主运动矢量作为运动线索,结合空间线索对场景的显著区域进行定位的显著性检测方法。
* 运动和空间线索以及高效的集成优化策略都被证明是有效的,实现了13 fps的快速处理速度(使用一个CPU)
* 与最先进的方法相比,我们在SegTrackV1、SegTrackV2和FBMS数据集上的实验产生了更好的性能。
II相关工作
A.图像显著性检测
认知心理学认为,人的视觉系统在选择视野中重要的视觉对象时非常有效。为了模拟人类的这种认知能力,提出了一些早期视觉注意模型[30]、[32]来预测人类观察者可能注意的场景位置。近年来,在计算机视觉应用的推动下,显著性检测已扩展到对突出目标的检测。
图像突出目标检测试图识别静态场景中信息量最大、最重要的目标,一般可分为自顶向下和自底向上两种方法。自顶向下的方法[33]、[34]是任务驱动的,通常采用带特定类的监督学习。由于缺乏高层次的知识,自底向上的方法往往是数据驱动的,依赖于对前景对象和背景属性的启发式假设。最广泛使用的假设是对比度优先,它定义一个像素(或一个块),如果它的外观与特定上下文中的其他像素相比是高度突出的。几乎所有显著性方法[7]、[8]、[10]、[11]、[35]都是在这样的假设下建立显著性模型的。
除了对比度先验外,最近的几部著作[6]、[9]、[37]-[39]、[49]都提出了基于边界先验的算法,即图像边界区域更有可能作为背景,以进一步增强计算的显著性。其良好的性能表明边界先验是一种有效的线索。
B.视频显著性检测
近十年来,随着对静态图像中不同视觉区域检测的深入研究,视频序列的时空显著性检测被提出为一项相关的新任务。大多数视频显著性方法都是自底向上的,将运动作为一种附加特征,对现有的空间显著性检测方案进行简单的扩展。例如,Gao等人[35]通过在动态场景中添加一个预测人眼注视的运动通道,继承了他们的图像显著性模型[36]。Mahadevan等人基于[36]中的空间显著性模型,将中心环绕假设与基于运动的感知分组相结合,进行时空显著性检测。在[13]中,引入了从给定视频中提取的局部回归核,用于测量像素(或体素)与其周围环境的相似性。他们通过直接从三维立方体中添加一个特征向量来扩展动态场景的图像显著性模型。在[18]中,一种基于各种空间特征的统计框架。提出了用于视频显著性检测的对比度、光照和颜色)和运动线索。[14]采用空时显著性,利用不同的低帧率特征和基于区域的对比度分析,从高帧率输入中生成低帧率视频。Fang等人通过基于自适应熵的不确定性加权方法将时空显著性图合并。Kim等人利用时间梯度图之间的绝对差和(SAD)得到三个不同尺度的显著性图,并计算多尺度图的加权和。Wang等人[20][23]提出了一种基于测地线距离的视频显著性方法,并在指导视频对象分割之前使用这种显著性。Wang等人使用由时空边缘或外观和运动构造的无向帧内和帧间图,以及一个骨架抽象步骤来增强显著性估计。最近的视频显著性方法[16]、[20]虽然性能有所提高,但计算成本很高,限制了其实用性。近年来,基于深度学习的突出目标检测方法[47]、[47]、[49]也取得了较好的效果。
III我们的方法
我们的目标是从视频序列中自动检测最重要的视觉目标区域。我们的方法主要分为三个阶段:
1)通过分析光流的显著性估计(Sec.III--A);
2)基于显著性和背景区域的颜色分布以及显著性紧密性的显著性估计(Sec.III--B);
3)在考虑空间一致性和时间一致性的前提下,采用多线索整合方法进行显著性线索整合(Sec.III--C)。
A.运动分析显著性
以往对运动物体[40]、[41]的注意效应的研究表明,视觉注意对物体的运动通常有较强的反应。我们从基于光流的运动估计开始我们的算法,从一对时间上相邻的帧捕获运动线索。这样的光流场提供了密集的运动矢量,每个矢量代表局部运动的绝对值。此外,感知到的物体运动往往表明相对于背景的运动。相对于背景运动更强的物体更容易吸引注意力。我们进一步注意到背景的运动是相对稳定和平滑的,这说明运动往往属于整个场景。而物体运动通常是变化的,在光流场中占据一个小而独特的模式。从图1第二行可以看出这种现象。
 图1:在动态场景中,运动是突出区域的一个强指标。从上到下:输入帧,光流场,通过Eqn.1得到运动线索的原始显著性映射,通过Eqn.2得到运动线索的细化显著性映射。注意,改进的运动线索显著性图显著抑制了假反应。相对于复杂多变的外观,光学流场具有更强的稳定性和统一性。
图1:在动态场景中,运动是突出区域的一个强指标。从上到下:输入帧,光流场,通过Eqn.1得到运动线索的原始显著性映射,通过Eqn.2得到运动线索的细化显著性映射。注意,改进的运动线索显著性图显著抑制了假反应。相对于复杂多变的外观,光学流场具有更强的稳定性和统一性。
基于以上观察,可以通过一个区域与整个场景的运动差异来衡量该区域的显著性。对于一个输入视频序列,,我们用[22]的算法计算出两个连续帧的光流场。然后,我们首先计算这个帧在位置处的基于运动的显著性:

其中叫![]() 做主要运动矢量,是光流场中运动矢量的平均值。直观的感觉是,整个场景的运动模式比背景的运动模式相似得多,而突出的物体通常比背景小,所以它有一个相对清晰(紧凑)的运动矢量。图1的第三行给出了计算结果。
做主要运动矢量,是光流场中运动矢量的平均值。直观的感觉是,整个场景的运动模式比背景的运动模式相似得多,而突出的物体通常比背景小,所以它有一个相对清晰(紧凑)的运动矢量。图1的第三行给出了计算结果。
式1中的显著性测量是合理的,但在背景运动模式不完全均匀或光流估计错误的情况下可能会失效。为了克服这个问题,我们进一步估计了四个额外的主运动矢量。这是从光流场的四个边界(上、下、左、右)的平均运动矢量得到的(在所有实验中,边界大小固定为20像素)。然后,我们将式1修改为:

![]() 对应五个主要的运动矢量(意味着整个流场的运动矢量和四个边界)。根据式2,将像素
对应五个主要的运动矢量(意味着整个流场的运动矢量和四个边界)。根据式2,将像素![]() 在帧中的显著性度量为其到这5个平均运动矢量的最短运动距离。如图1最后一行所示,附加的主运动矢量极大地提高了显著性估计。
在帧中的显著性度量为其到这5个平均运动矢量的最短运动距离。如图1最后一行所示,附加的主运动矢量极大地提高了显著性估计。
在式2中,我们的基于光流的显著性线索![]() 的计算速度非常快,但它不够健壮,因为它只考虑单个帧内的运动线索。因此,在某些帧中不准确的光流估计几乎是不可能避免的。此外,运动物体可能在某些帧内保持静止,使得相邻帧间的光流场失去了分辨能力。
的计算速度非常快,但它不够健壮,因为它只考虑单个帧内的运动线索。因此,在某些帧中不准确的光流估计几乎是不可能避免的。此外,运动物体可能在某些帧内保持静止,使得相邻帧间的光流场失去了分辨能力。
我们认为,时间上相邻的帧是高度相关的,人类的感知以马尔可夫方式利用动态信息,而不是单独处理每一帧。这就促使我们在整个视频序列中传播运动线索的帧向显著性,进一步建立运动线索的鲁棒显著性响应。
为了提高计算效率,我们用SLIC[25]的方法计算一组超像素![]() 来表示每个帧
来表示每个帧![]() 。将表
。将表![]() 示帧
示帧![]() 的超像素运动线索
的超像素运动线索![]() 的显著性映射缩写为
的显著性映射缩写为![]() 。我们迭代地将运动线索
。我们迭代地将运动线索![]() 的帧显著性从第一帧传播到最后一帧,每次一帧。当
的帧显著性从第一帧传播到最后一帧,每次一帧。当![]() 存在像素根据光流向
存在像素根据光流向![]() 移动时,帧的超像素和帧的超像素暂时连接在一起?然后
移动时,帧的超像素和帧的超像素暂时连接在一起?然后![]() 的更新方程为:
的更新方程为:

其中![]() 控制着积累速率。
控制着积累速率。
![]() 和
和![]() 的相关系数
的相关系数![]() 反应了它们之间的根据光流和颜色信息的相关度:
反应了它们之间的根据光流和颜色信息的相关度:
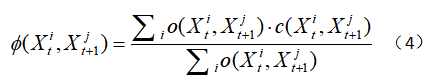
其中运动迁移权重![]() 是通过连接光流场来判断超像素
是通过连接光流场来判断超像素![]() 中的像素与
中的像素与![]() 中的像素的关联程度/关联比重(我觉得它这的
中的像素的关联程度/关联比重(我觉得它这的![]() 可以直接用光流场的光流值来计算,光流值大,说明运动剧烈,两个相邻帧之间的关系就较小,关联程度就较小)。还有外观相似性
可以直接用光流场的光流值来计算,光流值大,说明运动剧烈,两个相邻帧之间的关系就较小,关联程度就较小)。还有外观相似性![]() :
:
![]()
为了得到更好的显着性传播结果,我们计算了超像素间平均RGB颜色的欧氏距离。在式3中,运动线索的显著性是通过在整个视频序列中累积运动线索的帧向显著性映射来更新的。除了正向传播外,类似的反向步骤也从最后一帧运行到第一个帧。运动线索![]() 的最终显著性映射是这两个步骤的归一化和。
的最终显著性映射是这两个步骤的归一化和。
由于显著性传播是基于运动和外观线索的,因此我们能够建立一个更有效、更完整的显著性线索,对光流误差具有鲁棒性。同时,利用时间一致性可以正确地恢复某些帧中初始缺失的目标。如图2所示,在实践中,我们发现这种方法简单而有效,并且令人惊讶地优于许多最先进的方法,如我们在第IV-D节的实验部分所示。
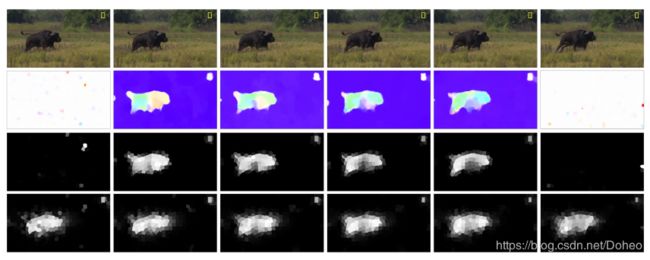 图2 显著性传播示例。从上到下:连续六帧,光流场,通过式2细化运动线索显著性图,通过式3更新运动线索显著性图。一些错误的光流估计(第一帧和第六帧)导致不满意的显著性结果。然而,当我们从单帧之外观察时,视频序列中光流场的一致性为区分突出区域提供了一种选择。通过显著性传播策略,得到了一个鲁棒的、完整的显著性线索。
图2 显著性传播示例。从上到下:连续六帧,光流场,通过式2细化运动线索显著性图,通过式3更新运动线索显著性图。一些错误的光流估计(第一帧和第六帧)导致不满意的显著性结果。然而,当我们从单帧之外观察时,视频序列中光流场的一致性为区分突出区域提供了一种选择。通过显著性传播策略,得到了一个鲁棒的、完整的显著性线索。
B.通过空间注意线索的显著性
在Sec.III-A中,我们主要讨论了基于运动分析的显著性线索。除了运动线索,空间特征也为视觉注意提供了有意义的线索。因此,我们提出了一套空间特征,从空间角度补充了基于运动的显著性。对于运动线索SM的显著性映射,我们将前景和背景对象分离,找出不确定区域。在此基础上,提出了最小势垒距离和中心偏置,为进一步的显着性计算和优化奠定了基础。我们的前景和背景分离策略建立在两个原则之上:首先,前景对象在外观上往往与背景不同;其次,在空间上越靠近最集中的显著性区域的区域总是越能吸引更多的吸引力。第一个原则的灵感来自于前景对象的定义,第二个原则反映了显著性的紧致性。应用这两个原理来计算我们的空间显著性估计。
受到第一条原则的启发。根据运动线索估计的显著性![]() ,我们首先选择了超像素的两个子集:所有超像素
,我们首先选择了超像素的两个子集:所有超像素![]() 中突出子集和背景子集。我们使用两个阈值和在每个帧从超像素中得到这两个子集,计算如下:
中突出子集和背景子集。我们使用两个阈值和在每个帧从超像素中得到这两个子集,计算如下:

用上面这两个式子区分超像素集为突出子集或是背景子集。剩下的,也就是在两个阈值中间的就是所谓的不确定子集——不能区分它们到底属于背景还是前景。
根据这两个阈值,我们定义运动显著超像素和运动背景超像素为:

将用上面两个阈值区分开各自集合在一起,就得到所谓的运动显著区域超像素集和背景运动超像素集(因为背景可能也在运动,只不过运动方式和显著性区域不同,被区分了出来。)
我们的目标是找到与运动显著超像素更相似、与背景超像素不同的空间显著超像素。第t个帧![]() 中,超像素
中,超像素![]() 。其中空间显著值
。其中空间显著值![]() 是
是![]() 的缩写,
的缩写,![]() 是背景值,这两个是这么计算的:
是背景值,这两个是这么计算的:
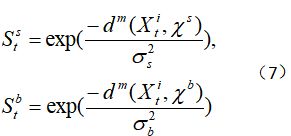
其中![]() 表示两个区域的距离,我们运用Minimum Barrier Distance(MBD)方法去测量两个区域的距离。
表示两个区域的距离,我们运用Minimum Barrier Distance(MBD)方法去测量两个区域的距离。
其中路径![]() 是由k个超像素组成的序列,其中相邻的是连续的超像素对。在我们的方法中,我们考虑了4条相邻路径。 MBD是用来测量通过这个路径连接的两个超像素
是由k个超像素组成的序列,其中相邻的是连续的超像素对。在我们的方法中,我们考虑了4条相邻路径。 MBD是用来测量通过这个路径连接的两个超像素![]() 和
和![]() 之间,最大值和最小值之间的绝对差:
之间,最大值和最小值之间的绝对差:
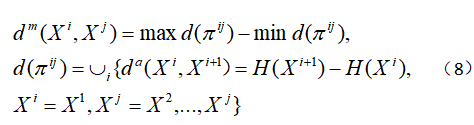
集![]() 包含所有路径上的每个相邻超像素可行的距离,只有两个值的最大和最小值的设置选择计算MBD的距离。
包含所有路径上的每个相邻超像素可行的距离,只有两个值的最大和最小值的设置选择计算MBD的距离。![]() 表示外观距离[24],我们将其计算为两个外观特征的欧式距离。
表示外观距离[24],我们将其计算为两个外观特征的欧式距离。![]() 表示超像素
表示超像素![]() 中CIELAB颜色空间(国际照明委员会)像素的平均值。在人类色彩视觉方面,CIELAB在感知上是一致的,更接近人类视觉系统对色彩距离的感知距离。该距离经过几次迭代,得到了满意的结果,可以认为该距离在路径上的超像素个数上具有线性复杂度。最后,空间显著性
中CIELAB颜色空间(国际照明委员会)像素的平均值。在人类色彩视觉方面,CIELAB在感知上是一致的,更接近人类视觉系统对色彩距离的感知距离。该距离经过几次迭代,得到了满意的结果,可以认为该距离在路径上的超像素个数上具有线性复杂度。最后,空间显著性![]() 可以表示为:
可以表示为:

至此,梳理一下我们得到的东西——超像素所包含的运动线索的显著性映射![]() ,空间显著性映射
,空间显著性映射![]() 。第二个原理进一步改进了基于外观直方图的显著性。对于第t帧
。第二个原理进一步改进了基于外观直方图的显著性。对于第t帧![]() ,计算显著性区域的中心
,计算显著性区域的中心![]() :
:

这个应用指数函数往高显著性像素点进行倾斜。利用突出区域的中心![]() ,根据区域到显著中心的距离计算出区域成为突出对象的概率。利用每个帧的显著性区域中心,根据距离远近就能判断这块区域是显著性目标的概率——突出物体的概率与距离显著中心的距离成反比。将二维高斯函数下位置x的似然
,根据区域到显著中心的距离计算出区域成为突出对象的概率。利用每个帧的显著性区域中心,根据距离远近就能判断这块区域是显著性目标的概率——突出物体的概率与距离显著中心的距离成反比。将二维高斯函数下位置x的似然![]() 赋值为:
赋值为:
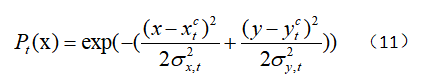
其中偏差:

然后在式11中应用这种基于显著性紧性的概率图![]() 来更新基于外观直方图的显著性
来更新基于外观直方图的显著性 ![]()
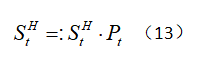
通过基于外观直方图的显著性提示和集中的显著性区域,得到了空间显著性映射。图3中的第3行显示了空间显著性检测结果,该结果比运动线索的显著性分析突出了更多的显著性目标区域。在下一节中,我们将进一步讨论多线索的集成,以增强显著性检测结果。
 图3 时空显著能量函数的图解。从上到下:连续6帧,通过式3得到运动线索SM的显著性图,通过式13得到基于外观直方图的显著性线索SH,通过式15得到空间光滑项,通过式3得到时间光滑项,通过式18得到最终显著性结果S。最后一行显示,通过有效地融合不同的线索,最终的显著性结果是有希望的,并且由于时间平滑项而表现出时间一致性。
图3 时空显著能量函数的图解。从上到下:连续6帧,通过式3得到运动线索SM的显著性图,通过式13得到基于外观直方图的显著性线索SH,通过式15得到空间光滑项,通过式3得到时间光滑项,通过式18得到最终显著性结果S。最后一行显示,通过有效地融合不同的线索,最终的显著性结果是有希望的,并且由于时间平滑项而表现出时间一致性。
C.线索整合
为了统一多个显著性线索,我们首先将运动线索![]() 和空间显著性线索
和空间显著性线索![]() 归一化到[0,1]范围。与以往使用加权线性组合等简单组合规则的工作不同,我们基于多层元胞自动机融合了不同的显著性线索,同时考虑了空间平滑性和时间平滑性。最后的视频显著性图
归一化到[0,1]范围。与以往使用加权线性组合等简单组合规则的工作不同,我们基于多层元胞自动机融合了不同的显著性线索,同时考虑了空间平滑性和时间平滑性。最后的视频显著性图![]() 是四个显著性图的组合,由能量函数描述:
是四个显著性图的组合,由能量函数描述:
![]()
在上式中,![]() 和
和![]() 是式2和式13中的运动和空间显著性映射。后两项分别为空间平滑项
是式2和式13中的运动和空间显著性映射。后两项分别为空间平滑项![]() 和时间平滑项
和时间平滑项![]() ,分别增强了空间邻域连续性和时间邻域显著性一致性。空间平滑项定义为:
,分别增强了空间邻域连续性和时间邻域显著性一致性。空间平滑项定义为:
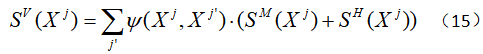
其中![]() 表示帧内的空间邻域超像素。系数
表示帧内的空间邻域超像素。系数![]() 表明加权空间和颜色距离之间的关系,它被描述为:
表明加权空间和颜色距离之间的关系,它被描述为:

空间距离![]() 被定义为指数加权距离之间的两个相邻超像素的中心。
被定义为指数加权距离之间的两个相邻超像素的中心。![]() 表示SecIII-A定义的超像素间的平均颜色距离。
表示SecIII-A定义的超像素间的平均颜色距离。
对于时间一致性![]() ,我们使用式3来保持时间一致性,用
,我们使用式3来保持时间一致性,用![]() 代替
代替![]() 作为输入。图3给出了一个例子。这里可能会有筒子们有疑问,用
作为输入。图3给出了一个例子。这里可能会有筒子们有疑问,用![]() 代替
代替![]() ,可是
,可是![]() 不是要依靠
不是要依靠![]() 求得的吗?这里是酱的,或者看后面的伪代码总结,先算式2,在线索融合的地方再用式3做前后的传播修正。
求得的吗?这里是酱的,或者看后面的伪代码总结,先算式2,在线索融合的地方再用式3做前后的传播修正。
现在我们有了一个包含四个显著性映射![]() 的集合。在常规的优化方法中,很难确定每一项的权重。在我们的方法中,我们使用了一种有效的方法,称为多层细胞自动机,它使用自适应阈值而不是手动设置系数,以纳入N个显着映射。多层元胞自动机将不同显著性映射中具有相同坐标的像素设置为相邻像素。对于显著性映射上的任何像素,它在其他映射上可能有N-1个邻居。多层细胞自动机的直觉是,第N个凸起的一个像素映射,其卓越价值将会增强,如果它的关键是前台根据其他N \ n(就是除了第n个显著图以外的N-1个显著图)映射OTSU法[42]是用来计算的自适应阈值二值化特点的地图,并且还可以获得最佳的图像二值化的阈值计算最大的类间方差。对于一个图像,阈值γ计算为:
的集合。在常规的优化方法中,很难确定每一项的权重。在我们的方法中,我们使用了一种有效的方法,称为多层细胞自动机,它使用自适应阈值而不是手动设置系数,以纳入N个显着映射。多层元胞自动机将不同显著性映射中具有相同坐标的像素设置为相邻像素。对于显著性映射上的任何像素,它在其他映射上可能有N-1个邻居。多层细胞自动机的直觉是,第N个凸起的一个像素映射,其卓越价值将会增强,如果它的关键是前台根据其他N \ n(就是除了第n个显著图以外的N-1个显著图)映射OTSU法[42]是用来计算的自适应阈值二值化特点的地图,并且还可以获得最佳的图像二值化的阈值计算最大的类间方差。对于一个图像,阈值γ计算为:
![]()
其中![]() 表示前景区域占整个映射的比重,
表示前景区域占整个映射的比重,![]() 则表示背景的比重。(二值分类图0表示前景,1表示背景,所以
则表示背景的比重。(二值分类图0表示前景,1表示背景,所以![]() )。
)。![]() 和
和![]() 分别表示前景和背景的像素的均值。
分别表示前景和背景的像素的均值。
对于第n个显著性映射,它的阈值被表示为![]() 。这第n个优化的显著性映射
。这第n个优化的显著性映射![]() 可以这样定义:
可以这样定义:

![]() 表示一个控制二值显著性映射图之间差异的常数,根据[39]的经验设置
表示一个控制二值显著性映射图之间差异的常数,根据[39]的经验设置![]() 为0.15。如果
为0.15。如果![]() 里的像素有比
里的像素有比![]() 里更低的值,那么它应该被分类为前景,它的显著性值应该增加
里更低的值,那么它应该被分类为前景,它的显著性值应该增加![]() 。相反,那么它的显著性值就要减少
。相反,那么它的显著性值就要减少![]() 。
。
对式18的优化进行多次递归处理,直到的显著性映射基本不变,最终的显著性映射计算为S{1}。图3的最后一行显示了优化后的最终结果——可以清楚地看到,检测到的显著性对象比优化后的显著性映射更加均匀突出。

IV实验结果
略。想看戳链接。
V总结
我们提出了一种快速、准确的视频序列显著性分析方法。与现有的单纯利用运动信息作为外观分析附加特征的方法不同,我们利用光流场作为主要特征,结合空间线索对视频的突出区域进行定位。针对以往任务模型复杂、耗时、鲁棒性差、对噪声敏感的缺点,我们建立了一种高效、准确的时空检测方法,并采用了高效的集成策略,总运行时间仅为0.08秒/帧。我们提出的方法首先通过分析光流场来确定突出区域,并引入一种鲁棒性显著性传播方案。此外,利用外观直方图和显著性紧性推断空间显著性。最后,采用多线索融合策略,巧妙地结合了各种显著性线索,提高了显著性检测结果。我们在大量的实验中证明了我们的方法的能力,这些实验显示了高质量的显著性图。据我们所知,我们的方法是CPU性能上最快的显著方法之一。在未来的工作中,我们打算进一步探索对人类显著性刺激的快速检测方法,以及将显著性目标检测作为中间结果在视频分割等更多视觉任务中的应用。
引用
[1] J. Han, D. Zhang, X. Hu, L. Guo, J. Ren, F. Wu, “Background priorBased salient object detection via deep reconstruction residual,” IEEE
Trans. on Circuits and Systems for Video Technology, vol. 25, no. 8, pp.
1309-1321, 2015.
[2] R. Achanta, S. Hemami, F. Estrada, and S. Susstrunk, “Frequencytuned salient region detection,” in Proceedings of IEEE Conference on
Computer Vision and Pattern Recognition, pp. 1597–1604, 2009.
[3] J. Shen, Y. Du, X. Li, “Interactive segmentation using constrained
Laplacian optimization,” IEEE Trans. on Circuits and Systems for Video
Technology, vol. 24, no. 7, pp. 1088-1100, 2014.
[4] J. Han, S. He, X. Qian, D. Wang, L. Guo, T. Liu, “An object-oriented
visual saliency detection framework based on sparse coding representations,” IEEE Trans. on Circuits and Systems for Video Technology, vol.
23, no. 12, pp. 2009-2021, 2013.
[5] T. Judd, and K. Ehinger, F. Durand, and A. Torralba, “Learning to predict
where humans look,” Computer Vision, pp. 2106–2113, 2009.
[6] Y. Wei, F. Wen, W. Zhu, and J. Sun, “Geodesic saliency using background
priors,” in Proceedings of European Conference on Computer Vision,
pp. 29–42, 2012.
[7] S. Goferman, L. Zelnik-Manor, and A. Tal, “Context-aware saliency
detection,” in IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 34, no. 10, pp.1915–1926, 2012.
[8] F. Perazzi, P. Krahenbuhl, Y. Pritchand, and A. Hornung, “Saliency filters:
Contrast based filtering for salient region detection,” in Proceedings of
IEEE Conference on Computer Vision and Pattern Recognition, pp. 733–
740, 2012.
[9] B. Jiang, L. Zhang, H. Lu, C. Yang, and M. Yang, “Saliency detection
via absorbing markov chain,” in Proceedings of IEEE International
Conference on Computer Vision, pp. 1665–1672, 2013.
[10] Q. Yan, L. Xu, J. Shi, and J. Jia, “Hierarchical saliency detection,”
in Proceedings of IEEE Conference on Computer Vision and Pattern
Recognition, pp.1155–1162, 2013.
[11] M. Cheng, G. Zhang and N. Mitra,“Global contrast based salient region
detection,” IEEE Trans. on Pattern Analysis and Machine Intelligence,
vol. 37, no. 3, pp.569–582, 2015.
[12] C. Guo, Q. Ma, and L. Zhang, “Spatio-temporal saliency detection using
phase spectrum of quaternion fourier transform,” in Proceedings of IEEE
Conference on Computer Vision and Pattern Recognition, pp. 1–8, 2008.
[13] H. Seo and P. Milanfar,“Static and space-time visual saliency detection
by self-resemblance,” Journal of vision, vol. 9, no. 12, pp. 1–27, 2009.
[14] F. Zhou, S. Kang, and M. Cohen, “Time-mapping using space-time
saliency,” in Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, pp. 3358-3365, 2014.
[15] J. Shen, X. Hao, Z. Liang, Y. Liu, W. Wang, and L. Shao, “Real-time
superpixel segmentation by DBSCAN clustering algorithm,” IEEE Trans.
on Image Processing, vol. 25, no. 12, pp. 5933-5942, 2016.
[16] Y. Fang, Z. Wang, W. Lin, and Z. Fang, “Video saliency incorporating
spatiotemporal cues and uncertainty weighting, ” IEEE Trans. on Image
Processing, vol. 23, no. 9, pp. 3910–3921, 2014.
[17] V. Mahadevan and N. Vasconcelos, “Spatiotemporal saliency in dynamic
scenes,” IEEE Trans. on Pattern Analysis and Machine Intelligence,
vol. 31, no. 1, pp. 171-177, 2010.
[18] E. Rahtu, J. Kannala, M. Salo, and J. Heikkila, “Segmenting salient ¨
objects from images and videos,” in Proceedings of European Conference
on Computer Vision, pp. 366–379, 2010.
[19] W. Kim, C. Jung, and C. Kim, “Spatiotemporal saliency detection and its
applications in static and dynamic scenes,” IEEE Trans. Circuits System
Video Technology, vol. 21, no. 4, pp. 446–456, 2011.
[20] W. Wang, J. Shen, and F. Prikli, “Saliency-aware geodesic video object
segmentation,” in Proceedings of IEEE Conference on Computer Vision
and Pattern Recognition, pp. 3395–3402, 2015.
[21] A. Papazoglou, V. and Ferrari, “Fast object segmentation in unconstrained video,” in Proceedings of IEEE International Conference on
Computer Vision, pp. 1777–1784, 2013.
[22] T. Brox, and J. Malik, “Object segmentation by long term analysis of
point trajectories,” in Proceedings of European Conference on Computer
Vision, pp. 282–295, 2010.
[23] W. Wang, J. Shen, and L. Shao, “Consistent video saliency using local
gradient flow optimization and global refinement,” IEEE Trans. on Image
Processing, vol. 24, no. 11, pp. 4185–4196, 2015.
[24] J. Zhang, S. Sclaroff and Z. Lin, “Minimum barrier salient object
detection at 80 FPS,” in IEEE International Conference on Computer
Vision, pp. 1404–1412, 2016.
[25] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P.Fua, and S.Susstrunk,
“SLIC superpixels compared to state-of-the-art superpixel methods,”
IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 34,
no. 11, pp. 2274–2282, 2012.
[26] W. Wang, J. Shen, R. Yang, and F. Porikli, “Saliency-aware Video
Object Segmentation,” IEEE Trans. on Pattern Analysis and Machine
Intelligence, 2018.
[27] J. Lezama, K. Alahari, J. Sivic, and I. Laptev, “Track to the future:
Spatio-temporal video segmentation with long-range motion cues,” in
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 3369–3376, 2011.
[28] K. Fragkiadaki, G. Zhang, and J. Shi, “Video segmentation by tracing
discontinuities in a trajectory embedding,” in Proceedings of IEEE
Conference on Computer Vision and Pattern Recognition, pp. 1846–1853,
2012.
[29] W. Wang, and J. Shen, “Deep visual attention prediction,” IEEE Trans.
on Image Processing, vol. 27, no. 5, pp. 2368-2378, 2018.
[30] L. Itti, C. Koch and E. Niebur, “A model of saliency-based visual
attention for rapid scene analysis,” IEEE Trans. on Pattern Analysis and
Machine Intelligence, vol. 20, no. 11, pp. 1254–1259, 1998.
[31] W. Wang, J. Shen, L. Shao, and F. Porikli, “Correspondence driven
saliency transfer,” IEEE Trans. on Image Processing, vol. 25, no. 11, pp.
5025-5034, 2016.
[32] O. Meur, P. Callet, D. Barba and D. Thoreau, “A coherent computational
approach to model bottom-up visual attention,” IEEE Trans. on Pattern
Analysis and Machine Intelligence, vol. 28, no. 5, pp. 802–817, 2006.
[33] T. Liu, Z. Yuan, J. Sun, J. Wang, N. Zheng, X. Tang and
H. Shum,”Learning to detect a salient object,” IEEE Pattern Analysis
and Machine Intelligence, vol. 33, no. 2, pp. 353–367, 2011.
[34] J. Yang, and M.H. Yang, “Top-down visual saliency via joint CRF
and dictionary learning,” IEEE Trans. on Pattern Analysis & Machine
Intelligence, vol. 39, no. 3, pp. 576–588, 2017.
[35] D. Gao, V. Mahadevan, and N. Vasconcelos, “The discriminant centersurround hypothesis for bottom-up saliency,” Advances in Neural Information Processing Systems,vol. 20, pp. 497–504, 2008.
[36] D. Gao, and N. Vasconcelos, “Bottom-up saliency is a discriminant
process,” in Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, pp. 1–6, 2007.
[37] C. Yang, L. Zhang, H. Lu, X. Ruan, and M. Yang, “Saliency Detection
via Graph-Based Manifold Ranking,” in Proceedings of IEEE Conference
on Computer Vision and Pattern Recognition, pp. 3166-3173, 2013.
[38] W. Zhu, S. Liang, Y. Wei, “Saliency optimization from robust background detection,” in Proceedings of IEEE Conference on Computer
Vision and Pattern Recognition, pp. 2814–2821, 2014.
[39] Y. Qin, H. Lu, Y. Xu, and H. Wang, “Saliency detection via cellular
automata,” in Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, pp. 110–119, 2015.
[40] R.A. Abrams, S.E. Christ, “Motion onset captures attention,” in Psychological Science, vol. 14,no. 5, pp. 427–432, 2010.
[41] P. K. APAMital, T. J. Smith, S. Luke, J. M. Henderson, “Do low-level
visual features have a causal influence on gaze during dynamic scene
viewing?” in Journal of Vision,vol. 13, no. 9, pp. 144, 2013.
[42] N. Otsu, “A threshold selection method from gray-level histograms”
IEEE Trans. on Systems, Man, and Cybernetics,vol. 9, no. 1, 1979.
[43] D. Tsai, M. Flagg, A. Nakazawa, and J.M. Rehg, “Motion coherent
tracking using multi-label MRF optimization,” in International Journal
of Computer Vision, vol. 100, no. 2, pp. 190–202, 2012.
[44] F. Li and T. Kim, A. Humayun, D. Tsai and J. M. Rehg, “Video
segmentation by tracking many figure-ground segments,” in Proceedings
of IEEE International Conference on Computer Vision, pp. 2192–2199,
2013.
[45] W. Wang, J. Shen, and L. Shao, “Video salient object detection via
fully convolutional networks,” IEEE Trans. on Image Processing, vol. 27,
no. 1, pp. 38–49, 2018.
[46] H. Fu, X. Cao, and Z. Tu, “Cluster-based co-saliency detection,” IEEE
Trans. on Image Processing, vol. 22, no. 10, pp. 3766–3778, 2013.
[47] W. Wang, J. Shen, F. Guo, M. Cheng, and A. Borji, “Revisiting video
saliency: a large-scale benchmark and a new model,” in Proceedings of
IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[48] J. Han, D. Zhang, G. Cheng, N. Liu, and D. Xu, “Advanced deeplearning techniques for salient and category-specific object detection: A
Survey,” IEEE Signal Processing Magazine, vol. 35, no. 1, pp. 84–100,
2018.
[49] J. Han, R. Quan, D. Zhang, and F. Nie, “Robust object co-segmentation
using background prior,” IEEE Trans. on Image Processing, vol. 27, no. 4,
pp. 1639-C1651, 2018.