tensorflow学习笔记(一)
简单的例子:
import tensorflow as tf #tensorflow库
import numpy as np #科学计算包
#因为没有别的数据,所以自己创建一组数据
x_data=np.random.rand(100).astype(np.float32) #x_data是一个随机数组,范围0-1创建100个随机数
y_data=x_data*0.2+1 #人为定义了y与x的关系,也就相当于数据标签,对于每每个输入的x,都有一个相应的y,通过训练,我们的目标是让weight=0.2,biases=1,才说明学到东西了
#创建tensorflow的结构
Weights=tf.Variable(tf.random_uniform([1],-1.0,1.0)) #初始值定义为-1到1的一位数组
biases=tf.Variable(tf.zeros([1])) #初始值定义为一维的0数组
y=Weights*x_data+biases #这个是我要预测的y,通过不断更新weight,y会不断的与数据接近
loss = tf.reduce_mean(tf.square(y-y_data)) #定义一个loss函数,平均方差
optimizer = tf.train.GradientDescentOptimizer(0.1) #优化器,选择了梯度下降的优化方法,学习率设置为0.1
train = optimizer.minimize(loss) #用优化器训练loss函数,使其最小化
init = tf.initialize_all_variables() #定义一个初始化变量,使刚才所有定义的变量全部初始化
sess = tf.Session() #启动对话
sess.run(init) #sess.run()运行括号里面的变量,这句意思是说运行刚才定义的变量
for step in range(2000):
sess.run(train) #运行train。即运行优化器,使其最小化loss函数。
if step%50==0 : #每迭代50次,打印一次当前训练结果,此时打印weight和biases的结果
print(step,sess.run(Weights),sess.run(biases))
Session会话控制
#用tensorflow实现两个矩阵相乘
import tensorflow as tf
#定义两个矩阵
matrix1 = tf.constant([[3,3]])
matrix2 = tf.constant([[2],
[2]])
product= tf.matmul(matrix1,matrix2) # tf中的矩阵乘法
#method1 直接开启一个Session
sess=tf.Session()
result=sess.run(product)
print(result)
sess.close()
#method2 第二张用with开启一个Session,注意Session首字母是大写的,并且后面有括号
#后面不加括号会报错:AttributeError: __enter__
with tf.Session() as sess:
result2=sess.run(product)
print(result2)
#result:[[12]]Variable变量
import tensorflow as tf
#tf.Variable()为定义变量,tf.constant()定义常量
state = tf.Variable(0, name='counter') #state定义一个变量,初始值为0给变量起一个名字叫counter
one = tf.constant(1) #定义一个常亮,值为1
new_value=tf.add(state,one) #计算两个数相加
update=tf.assign(state,new_value) #将new_value的值更新给state,相当于一个赋值操作
init=tf.initialize_all_variables() #如果上面定义了变量,则要输入此语句,用来初始化全部变量
#打开一个会话窗口
with tf.Session() as sess:
sess.run(init) #初始化
for _ in range(3):
sess.run(update) #更新state的值
print(sess.run(state)) #打印stateplaceholder传入值占位符
import tensorflow as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output=tf.multiply(input1,input2)
with tf.Session() as sess:
print(sess.run(output,feed_dict={input1:[7.],input2:[2.]}))placeholder意思为先存入一个值,等到运行的时候再去给它传递值,与feed_dict={}是绑定的。只要用到了placeholder存的变量,一定要加上feed_dict={},否则找不到该数据。
添加一个层:add_layer
#添加神经层的函数,它有四个参数:输入、输入的形状、输出的形状和激励函数,
# Wx_plus_b是未激活的值,函数返回激活值。
def add_layer(inputs, in_size, out_size, activation_function=None):
# tf.random_normal()参数为shape,还可以指定均值和标准差
#定义权重,偏差。权重高斯分布的随机数,偏差初始值为0.1
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 计算W*x+b
Wx_plus_b = tf.matmul(inputs, Weights) + biases # 要求输入向量x是个行向量
#做判断,如果没有激活函数,则直接输出结果,如果有激活函数,则激活函数处理后输出。
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs #输出结果构建一个简单神经网络:build a neural network
## add_layer()函数参照上一条。
import tensorflow as tf
import numpy as np
# 构建训练数据
# np.linspace(-1, 1, 300, dtype=np.float32)在-1和1之间等差生成300个数字
# noise是正态分布的噪声,前两个参数是正态分布的参数,然后是size,x_data.shape表示和x的尺寸一致
x_data = np.linspace(-1, 1, 300, dtype=np.float32)[:, np.newaxis] # 将x_data转换为列向量
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
y_data = np.square(x_data) - 0.5 + noise
# 利用占位符定义我们所需的神经网络的输入。
# 第二个参数为shape:None代表行数不定,1是列数。
# 这里的行数就是样本数,列数是每个样本的特征数。
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
# 输入层1个神经元(每次输入x,输出对应y),隐藏层10个,输出层1个。
# 调用函数定义隐藏层和输出层,输入size是上一层的神经元个数(全连接),输出size是本层神经元个数
L1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
prediction = add_layer(L1, 10, 1, activation_function=None)
# 计算预测值prediction和真实值的误差,对二者差的平方求和再取平均作为损失函数。
# reduction_indices表示最后数据的压缩维度,好像一般不用这个参数(即降到0维,一个标量)。
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)#训练步骤,梯度下降的优化方法,学习率0.2,目标是最小化损失函数
# 初始化变量,激活,执行运算
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) #执行初始化参数
for i in range(1000):
# training开始训练
#feed_dict={}的意义参见上文,也就是说我用到了placeholder存的数据,就要填上数据来源。
#xs数据取自x_data,ys取自y_data
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
#训练50次,打印loss值
if i % 50 == 0:
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
结果可视化
使用可视化工具 import matplotlib.pyplot as plt
将上一个代码的下面一部分替换为此代码段,实现数据的可视化。具体注释见代码。
init=tf.initialize_all_variables()
fig=plt.figure() #生成一个图片框
ax=fig.add_subplot(1,1,1) #生成一个一行一列,位置为1的图片
ax.scatter(x_data,y_data) #用点的形式把x_data,y_data输入到创建的图上
#plt.show() #展示图片
plt.xlim(x_data.min() * 1.1, x_data.max() * 1.1)
plt.ylim(y_data.min() * 1.1, y_data.max() * 1.1) #这两句定义了图片框的大小,为取值范围的1.1倍
with tf.Session() as sess:
sess.run(init)
for _ in range(50000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if _%50==0:
predict_value=sess.run(predict,feed_dict={xs:x_data})
#用一条曲线表示x_data和预测值的关系,‘r-’表示颜色,用曲线的形式表示,lw表示划线的宽度
lines=ax.plot(x_data,predict_value,'g-',lw=5)
plt.pause(0.01) #0.01秒展示一次
ax.lines.remove(lines[0]) #将刚刚画的线抹除,如果没有这句,将会在同一个图片中叠加显示多条线
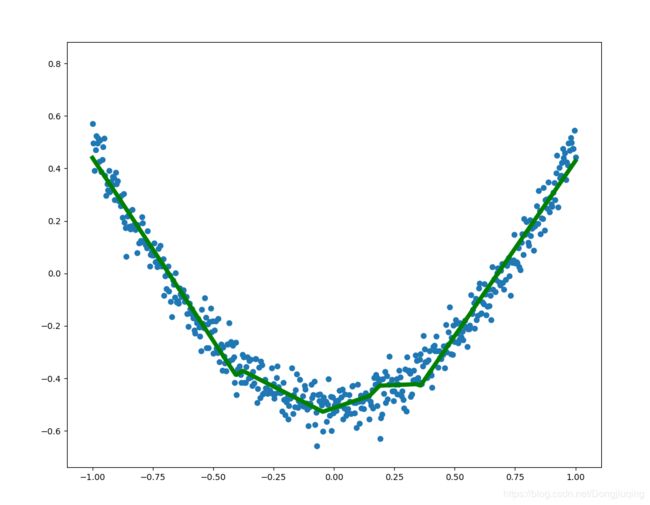
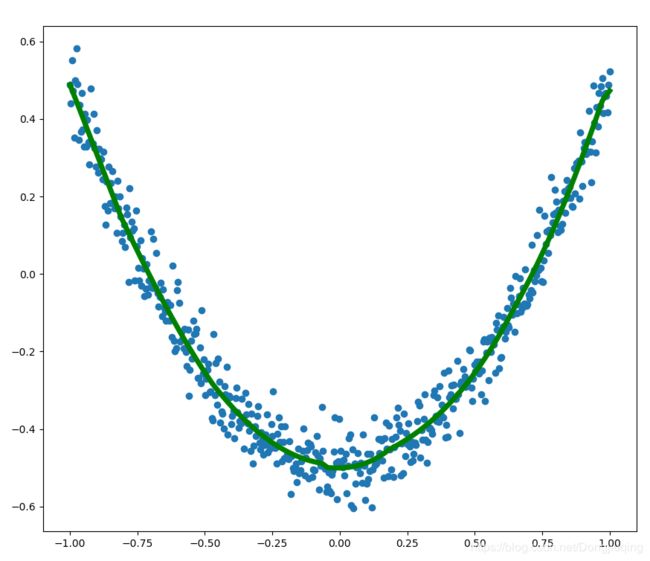
左图这是上述代码可视化的结果,当然,拟合的不是很好,如果想要拟合的更好,建议增加一两层隐藏层,用不同的激活函数,学习率设置为0.1左右,即可得到右图的结果。
参考tensorflow视频课程:https://www.bilibili.com/video/av16001891/?p=16