心中无码,自然高清 | 联合去马赛克与超分辨率研究论文Pytorch复现

作者 | 知凡,个人公众号:林木蔚然读书会(ID:EspressoOcean),知乎ID:Uno Whoiam
本文授权转载自知乎
本文结构
简单扫盲
什么是去马赛克
什么是超分辨率
《Deep Residual Network for Joint Demosaicing and Super-Resolution》论文简介
论文创新点
论文模型结构
训练数据
论文模型效果
论文复现
Pytorch代码
Model
DataSet
Train
需要注意的细节
复现结果
数值结果
图片展示
一、简单扫盲
1、什么是去马赛克
首先,去马赛克嘛,大家都知道:

当然不是上图这样的,各位读者姥爷别想歪了,此马赛克非彼马赛克,这个去马赛克是数码相机成像中的一个关键性的环节。要说明白这个得从数码相机的感光元件说起。
我们知道,数码图像是由像素排列成的,而一个像素点是由RGB即红、绿、蓝三种颜色混合而成的,而数码相机的感光元件只能感受到光照的强度,要想在一个点上同时采集红、绿、蓝三种颜色的光照强度,在结构和制作成本上会是一场噩梦。这个问题该如何解决呢?
这个时候布莱斯.拜尔拿着自己发明的Bayer阵列振臂疾呼:弟弟们,大哥来救你们了!
Bayer阵列的思路很简单,既然在一个点上采三种光很难,那就只采一种光呗,何必为难感光元件?既然我们又必须采集到三种不同颜色的光,那么就在感光的排列上做做文章呗:

Bayer阵列
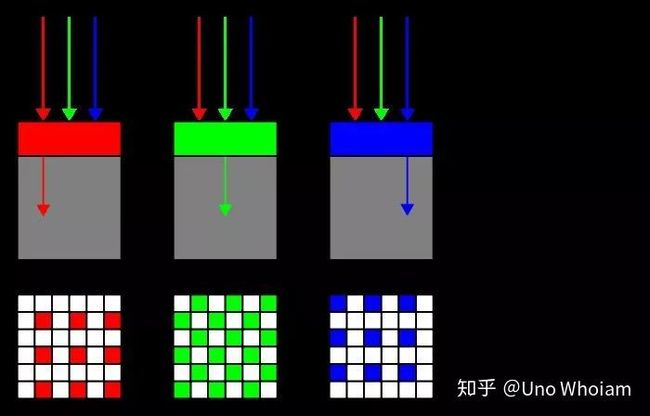
Bayer 阵列感光元件
采集到每个点只能采集到三种颜色的光中的一种,其它两种颜色的光则可以向邻居借得到,而这“借”的过程,我们就称之为“去马赛克”:

左:Bayer阵列图像(RAW图像) 右:高清无码TIFF图像

Bayer阵列图像局部放大

高清图像局部放大
看了这上面的图,知道为啥叫“去马赛克”了吗?
相关的算法有FlexISP、ADMM、DemosaicNet等。
2、什么是超分辨率?
简而言之,就是把低分辨率的图像变成高分辨率的:

深度学习的超分辨率方法已有很多,如SRCNN、FSRCNN、ESPCN、VDSR等。
桂花糖:从SRCNN到EDSR,总结深度学习端到端超分辨率方法发展历程
二、《Deep Residual Network for Joint Demosaicing and Super-Resolution》论文简介
下载地址:https://arxiv.org/abs/1802.06573
1、论文创新点
该论文的最大创新点和其标题一样,是第一次把去马赛克和超分辨率结合在一起做,直接从单通道的RAW图像中挖掘尽可能多的信息,直接生成超分辨率的三通道图片。相对于先做去马赛克,再做超分辨率,这样做的好处在于一可避免两个阶段的错误积累,产生质量更高的图片,二可减少运算量,减少计算时间。
2、论文模型结构
模型分为三个阶段:
a、提取颜色:用4x4的卷积,达到在Bayer图像中提取每个点真实颜色的目的
b、非线性映射:借鉴残差网络的模块构成深层网络提取特征
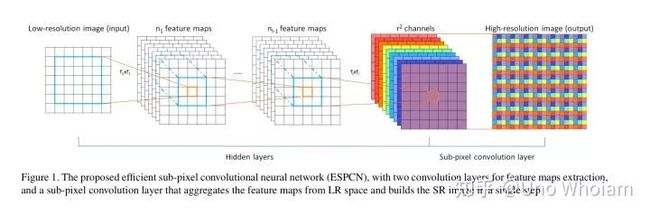
c、图像重构:借鉴ESPCN里的sub-pixel结构,将通道数减少4倍从而使得图像的高和宽分别提升两倍,达到超分辨率的目的
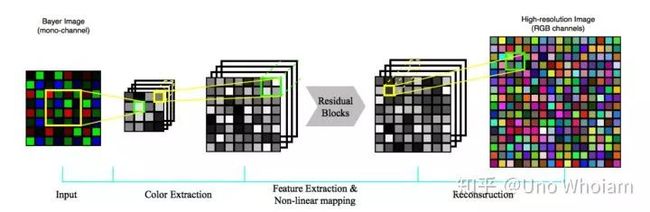
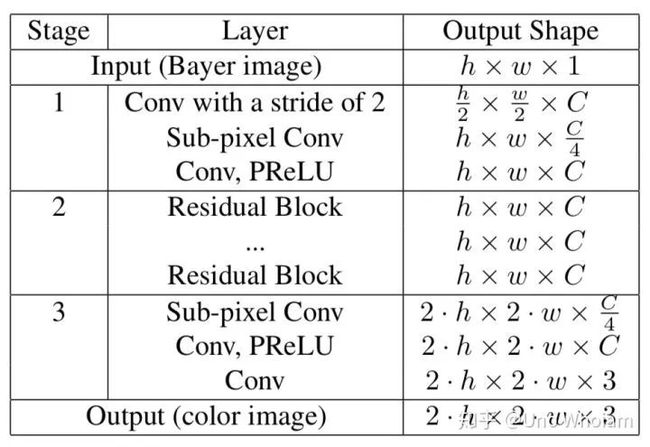
在论文中
a、Feature map的数量C=256。
b、采用的残差网络块的结构如下图,论文采用24个模块:

c、Sub-Pixel可参考ESPCN:
d、Batch Size为16x3x64x64
e、Learning Rate 每10000个batch降低一半
3、训练用的数据集
采用的是RAISE数据集中的6000张高清图片:
下载地址:http://loki.disi.unitn.it/RAISE/
对这些图片的处理如图所示:

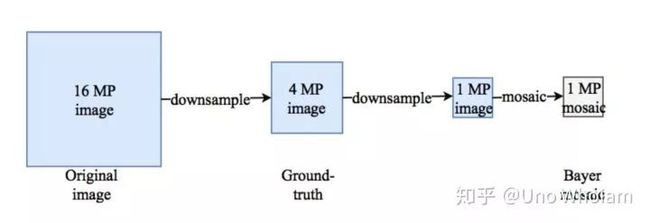
1、将16MP的原始TIFF图像经过三次factor=1.25的resize后变成4MP的TIFF图像
2、将4MP的TIFF图像经过一次factor=2 的resize后变成1MP的TIFF图像
3、将1MP的图像,对于每个像素,抹去G、B,R、B,R,B通道的数据仅留下一个与Bayer阵列相匹配的通道,形成Bayer图像(类似下图),然后将三通道合并成一个通道。
4、至此,训练集已经制作完成,data为1MP的Bayer图像,label是步骤2产生的4MP图像。
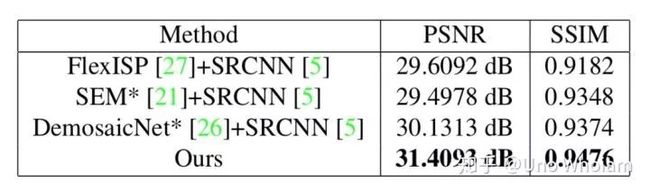
4、论文模型效果


三、论文复现
1、Pytorch代码:
1.1、Model:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
# ResNet
# https://blog.csdn.net/sunqiande88/article/details/80100891
class ResidualBlock(nn.Module):
def __init__(self):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, bias=True),
nn.PReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, bias=True),
)
self.shortcut = nn.Sequential()
self.active_f = nn.PReLU()
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = self.active_f(out)
return out
class Net(nn.Module):
def __init__(self, resnet_level=2):
super(Net, self).__init__()
# ***Stage1***
# class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
self.stage1_1_conv4x4 = nn.Conv2d(in_channels=1, out_channels=256,
kernel_size=4, stride=2, padding=1, bias=True)
# Reference:
# CLASS torch.nn.PixelShuffle(upscale_factor)
# Examples:
#
# >>> pixel_shuffle = nn.PixelShuffle(3)
# >>> input = torch.randn(1, 9, 4, 4)
# >>> output = pixel_shuffle(input)
# >>> print(output.size())
# torch.Size([1, 1, 12, 12])
self.stage1_2_SP_conv = nn.PixelShuffle(2)
self.stage1_2_conv4x4 = nn.Conv2d(in_channels=64, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=True)
# CLASS torch.nn.PReLU(num_parameters=1, init=0.25)
self.stage1_2_PReLU = nn.PReLU()
# ***Stage2***
self.stage2_ResNetBlock = []
for i in range(resnet_level):
self.stage2_ResNetBlock.append(ResidualBlock())
self.stage2_ResNetBlock = nn.Sequential(*self.stage2_ResNetBlock)
# ***Stage3***
self.stage3_1_SP_conv = nn.PixelShuffle(2)
self.stage3_2_conv3x3 = nn.Conv2d(in_channels=64, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=True)
self.stage3_2_PReLU = nn.PReLU()
self.stage3_3_conv3x3 = nn.Conv2d(in_channels=256, out_channels=3,
kernel_size=3, stride=1, padding=1, bias=True)
def forward(self, x):
out = self.stage1_1_conv4x4(x)
out = self.stage1_2_SP_conv(out)
out = self.stage1_2_conv4x4(out)
out = self.stage1_2_PReLU(out)
out = self.stage2_ResNetBlock(out)
out = self.stage3_1_SP_conv(out)
out = self.stage3_2_conv3x3(out)
out = self.stage3_2_PReLU(out)
out = self.stage3_3_conv3x3(out)
return out
1.2、DataSet:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import torch.utils.data as data
from PIL import Image
import random
import numpy as np
# Reference link:
# 如何构建数据集
# https://oidiotlin.com/create-custom-dataset-in-pytorch/
# https://www.pytorchtutorial.com/pytorch-custom-dataset-examples/
# transforms 函数的使用
# https://www.jianshu.com/p/13e31d619c15
# ToTensor:convert a PIL image to tensor (H*W*C) in range [0,255] to a torch.Tensor(C*H*W) in the range [0.0,1.0]
# torch.set_default_tensor_type('torch.DoubleTensor')
class CustomDataset(data.Dataset):
# file_path TXT文件路径
# random_augment=1 随机裁剪数据增强
# block_size=64 裁剪大小
def __init__(self, file_path, block_size=64):
with open(file_path, 'r') as file:
self.imgs = list(map(lambda line: line.strip().split(' '), file))
self.Block_size = block_size
print("DataSet Size is: ", self.__len__())
# print(len(self.imgs))
# for i in self.imgs:
# print(len(i))
def __getitem__(self, index):
# 注意!!! 读入的Bayer图像最左上为:
# R G
# G B
# Reference API
# class torchvision.transforms.RandomCrop(size, padding=0, pad_if_needed=False)
# class torchvision.transforms.Compose([transforms_list,])->生成一个函数
data_path, label_path = self.imgs[index]
# print(index, data_path, label_path)
data = Image.open(data_path).convert('L')
label = Image.open(label_path).convert('RGB')
trans = transforms.Compose([transforms.ToTensor()])
data_img = trans(data)
label_img = trans(label)
return data_img, label_img
def __len__(self):
return len(self.imgs)
1.3、Train:
import torch
import torch.utils.data as data
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import time
from PIL import Image
from DataSet import CustomDataset
from NewResNet import Net
from multiprocessing import Process
from Test_class import Run_test
# *** 超参数*** `
Parameter_path = './Final_train_LR.txt'
MODEL_PATH = './Final_Model.pkl'
EPOCH = 1
HALF_LR_STEP = 40000
LR = 0.0001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 训练集与测试集的路径
train_data_path = "./8K_TRAIN_DATA/8K_TRAIN_DATA.txt"
test_data_path = "./8K_CROSS_DATA/8K_CROSS_DATA.txt"
BATCH_BLOCK_SIZE = 64
BATCH_SIZE = 8
DATA_SHUFFLE = True
# 检查GPU是否可用
print("cuda:", torch.cuda.is_available(), "GPUs", torch.cuda.device_count())
# 保存和恢复模型
# https://www.cnblogs.com/nkh222/p/7656623.html
# https://blog.csdn.net/quincuntial/article/details/78045036
#
# 保存
# torch.save(the_model.state_dict(), PATH)
# 恢复
# the_model = TheModelClass(*args, **kwargs)
# the_model.load_state_dict(torch.load(PATH))
# # 只保存网络的参数, 官方推荐的方式
# torch.save(net.state_dict(), 'net_params.pkl')
## 加载网络参数
# net.load_state_dict(torch.load('net_params.pkl'))
print("Loading the LR...")
try:
P = open(Parameter_path)
P = list(P)
LR = float(P[0])
except:
print("Loading LR fail...")
print("Loading the saving Model...")
MyNet = Net(24).to(device)
try:
MyNet.load_state_dict(torch.load(MODEL_PATH))
except:
print("Loading Fail.")
pass
print("Loading the Training data...")
MyData = CustomDataset(file_path=train_data_path,
block_size=BATCH_BLOCK_SIZE)
# CLASS torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False,
# sampler=None, batch_sampler=None, num_workers=0, collate_fn=
# pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
train_data = data.DataLoader(dataset=MyData,
batch_size=BATCH_SIZE,
shuffle=DATA_SHUFFLE)
# CLASS torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
Optimizer = torch.optim.Adam(MyNet.parameters(), lr=LR, betas=(0.9, 0.999), eps=1e-08)
# CLASS torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
Loss_Func = nn.MSELoss()
counter = 0
print("Start training...")
for epoch in range(EPOCH):
for step, (data, label) in enumerate(train_data):
counter = counter + 1
if counter != 0 and counter % HALF_LR_STEP == 0:
LR = LR / 2
Optimizer = torch.optim.Adam(MyNet.parameters(), lr=LR, betas=(0.9, 0.999), eps=1e-08)
with open(Parameter_path, 'w') as f:
f.write(str(LR))
print('LR:', LR)
data, label = data.to(device), label.to(device)
start = time.perf_counter()
out = MyNet(data)
# print(type(out), out.shape)
loss = Loss_Func(out, label)
Optimizer.zero_grad()
loss.backward()
Optimizer.step()
print(loss)
print(epoch, step)
print("Time:", time.perf_counter() - start)
if counter != 0 and 0 == counter % 100:
print("Saving the model...")
torch.save(MyNet.state_dict(), MODEL_PATH)
2、需要注意的细节
a、卷积层大小的选择
VGG告诉了我们,没啥特殊的情况,3x3就是最好的选择。
b、训练集的制作
论文将HD图片裁剪成128x128的大小作为DNN模型的输出,后将128x128制作成64x64的Bayer图像作为模型的输入,必须要注意的是,每张64x64的图像像素的Bayer排列必须一致。我设定的Bayer排列从左上角开始为:
# R G
# G B
如果输入图像从左上角开始的Bayer排列不同,输出的颜色将会错乱。
c、生成图像
模型训练好后,想要生成高清图像,如果显存没法一次性将1MP大小的Bayer图片放进去,那么切成一块一块放进去,然后一块块拼起来即可。
但切块再拼起来的图块与图块之间会有明显的不连续:

左:原始图像 右:神经网络合成的图像 PSNR=25.1418

右图局部放大,拼接痕迹明显
为了避免生成的图像块与块之间存在不连续的情况,我的具体流程如下:
将Bayer图像对镜像Padding成图块的整数倍大小,比如HxW的原始图像,镜像Padding成(ceil(H/B)xB+2xS)+(ceil(W/B)xB+2xS)的大小,ceil表示上取整,B为块的边长,S为2的倍数,取2就可以。输入的图像要大一圈,然后取产生图像的中间部分做拼接,最后的图像就是连续的,如果不理解可以看示意图:
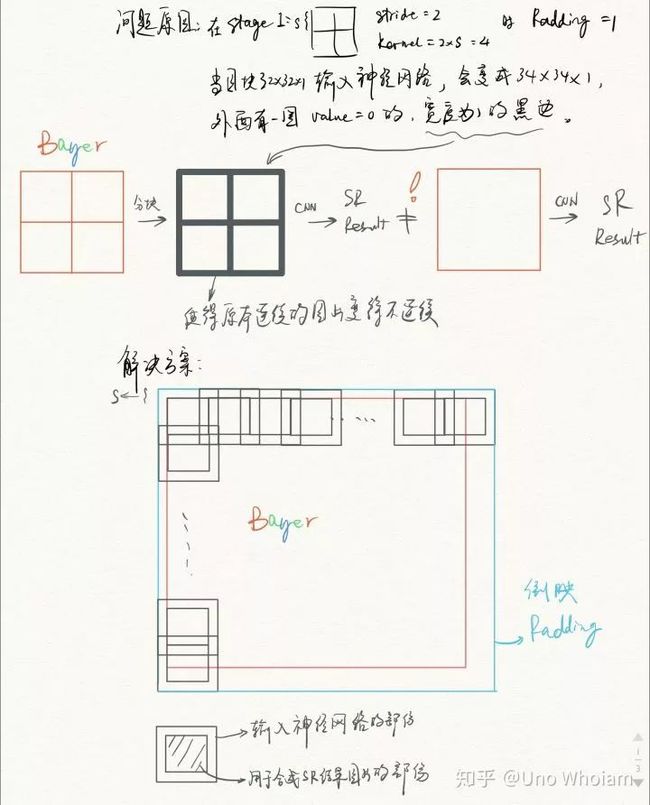
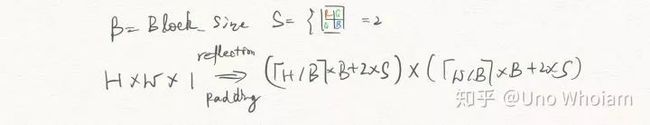
这样就可以解决图像拼接间隙的问题:

左:原始图像 右:神经网络合成的图像 PSNR=25.1272

然而,一个现象是,拼接痕迹没了,但图像的PSNR值也会降低一些。如下表所示:
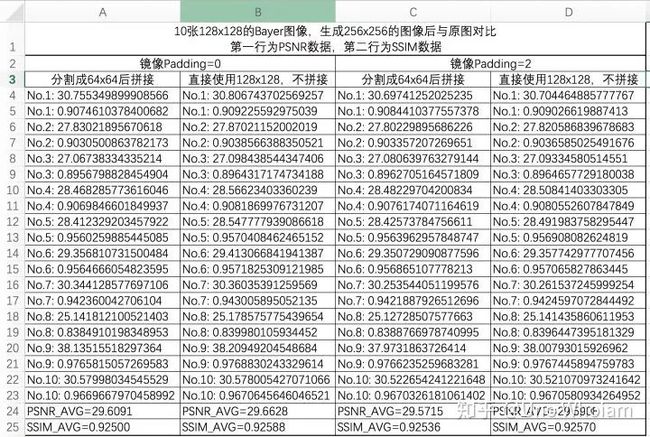
当然不切割直接输入模型生成图片(B列)效果最好,然而图片太大会爆显存,真是纠结。
3、复现结果
a、数值结果

与论文结果对比:
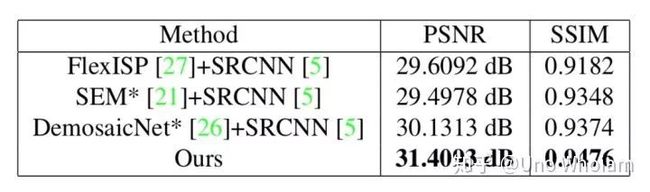
SSIM值没有论文高,但很接近,PSNR值更好一些。
BTW,SSIM计算出的结果与其计算时选用的window size即滑窗大小很有关系,滑窗大小越大,SSIM越高,本文在计算时采用的11x11大小的滑窗,这与提出SSIM的论文《Image Quality Assessment: From Error Visibility to Structural Similarity》中一致。
(相关地址:http://www.voidcn.com/article/p-auyocqzg-bac.html)
b、图片展示
左为原始图片,右为神经网络模型生成的图片:

PSNR: 31.197238996689617 SSIM: 0.9097831587657645

PSNR: 32.89967806219095 SSIM: 0.9294818208128227

PSNR: 33.15050503169419 SSIM: 0.9472909901611216

PSNR: 30.873442524392864 SSIM: 0.9473571002561766

PSNR: 25.052382881653507 SSIM: 0.9404708529075997

PSNR: 38.69040333179672 SSIM: 0.9570685066296898
原文链接:
https://zhuanlan.zhihu.com/p/56493507
(本文为 AI科技大本营转载文章,转载请联系原作者)
在线分享会
◆
3月21日晚8点
◆
近年来,聊天机器人技术及产品得到了快速的发展,本课程将全面阐述聊天机器人的技术框架及工程实现细节,并对于聊天机器人的下一代范式:虚拟生命,进行了详细的剖析,同时,聚焦知识图谱在实现认知智能过程中的重要作用,给出了知识图谱的落地实践。

推荐阅读:
Pig变飞机?AI为什么这么蠢 | Adversarial Attack
3.15曝光:40亿AI骚扰电话和11家合谋者
如何从零开始用PyTorch实现Chatbot?(附完整代码)
杨超越第一,Python第二
麦克阿瑟奖得主Dawn Song:区块链能保密和保护隐私?图样图森破!
315 后,等待失业的程序员
大数据背后的无奈与焦虑:“128元连衣裙”划分矮穷挫与白富美?
京东强推 995 工作制,中国式变态加班何时休?
教训!学 Python 没找对路到底有多惨?

❤点击“阅读原文”,查看历史精彩文章。