C/C++编程规范整理
一、基本准备工作
1、设计工程目录结构
(1)基本原则:
【1】工程本身的文件、项目编译生成的中间文件放一个文件夹;
【2】最终生成的目标文件单独放一个文件夹;
【3】如果有工程依赖的库文件等单独放一个文件夹;
【4】用户代码文件放单独一个文件夹,或者将头文件和源文件单独分开放置;
【5】用户代码文件里面如果有比较重要的功能模块单独放一个文件夹,如陀螺仪,气压计,光感,音乐,灯效,图片,字库等。
【6】重要的项目资料单独放一个文件夹保存,如硬件原理图,软件框架图,通信协议,复杂重要功能的说明等等。
【7】必须维护一个软件版本升级记录文档,也可以在某个主要的代码文件内维护(不推荐)。
【8】可以为一些代码阅读工具需要的生成文件开一个文件夹,如SourceInsight。
(2)举例
【1】linux
【2】arm9
【3】stm32

2、版权和版本的申明
(1)基本原则:
位置:位于说明文件或者源文件头部,或者源文件和头文件都加上版本声明。
内容:版权、文件名,概要;版本号-作者-日期+代码更新信息,备注信息;
(2)举例:
【1】

@头文件注释带上函数功能的简要说明,但如果在头文件有对外接口的函数声明,则在函数声明上进行函数功能的注释。

【2】源文件,说明此模块功能,主要函数,被其他函数调用的接口
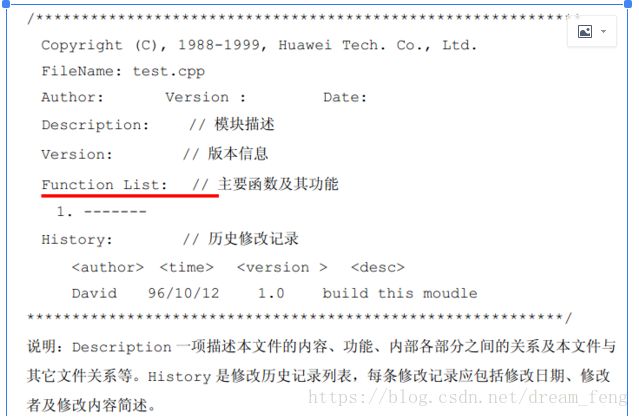
【3】源文件和头文件都加上版本声明:
STM32F10x_FWLib/stm32f10x_adc.h
/********************************************************************************
* @file stm32f10x_adc.h
* @author MCD Application Team
* @version V3.5.0
* @date 11-March-2011
* @brief This file contains all the functions prototypes for the ADC firmware
* library.
******************************************************************************
* @attention
* THE PRESENT FIRMWARE WHICH IS FOR GUIDANCE ONLY AIMS AT PROVIDING CUSTOMERS
******************************************************************************
*/STM32F10x_FWLib/stm32f10x_adc.c
/** ******************************************************************************
* @file stm32f10x_adc.c
* @author MCD Application Team
* @version V3.5.0
* @date 11-March-2011
* @brief This file provides all the ADC firmware functions.
******************************************************************************
* @attention
* THE PRESENT FIRMWARE WHICH IS FOR GUIDANCE ONLY AIMS AT PROVIDING CUSTOMERS
****************************************************************************** */3、头文件的结构和作用
(1)头文件开头处的版权和版本声明。
(2)预处理块。
#ifndef/#def/#endif 防止头文件被重复引用。
(3)其他头文件、函数和类结构声明等。
[1]#include
#include “filename.h”:引用非标准库的头文件,编译器从用户的工作目录开始搜索。
[2]变量和函数,头文件只存声明,不存定义。
二、排版和代码行基本规则
目的:使代码布局整齐清晰,便于阅读和理解。
1、起始代码的缩进:
函数或过程的开始、结构的定义及循环、判断等语句中的代码都要采用缩进风格, case语句下的情况处理语句也要遵从语句缩进要求。
2、缩进规则:
【1】缩进风格:程序块要采用缩进编写,缩进的空格数一般为4个。
【2】不用TAB用空格:以免用不同的编辑器阅读程序时,因 TAB 键所设置的空格数目不同而造成程序布局不整齐。
3、程序块大括号对齐:
【1】WIN和嵌入式底层:程序分界符" {"和“ }”:应该独占一行并且两者位于同一列,同时与引用他们的语句左对齐;
【2】linux:‘{’位于上一行的行末,此时‘}’与‘{’所在行的行首对齐,‘{’前至少有一个空格。
for (...) { //多在linux底层和linux应用编程,单片机嵌入式未见此种用法。
... // program code
}
===
for (...) //windows一般统一用下面这个格式。。。
{
... // program code
}
4、空行:
每个函数定义结束后,相对独立的程序块之间(逻辑密切除外)、变量说明和程序块中间之后必须加空行。
5、标志符语句独占一行:
if、 for、 do、 while、 case、 switch、 default等语句自占一行,不论语句的执行语句部分无论多少都要加括号{}。
6、长句拆分:
(1)单行单语句,一行不超过一个语句:
不允许把多个短语句写在一行中,即一行只写一条语句。
(2)语句的拆分:
代码长度最好控制在70-80个字符以内,较长的语句( >80字符)要分成多行书写。
函数或过程中的参数较长,循环、判断等语句中有较长的表达式或语句,要进行适应的划分,长表达式要在低优先级操作符处划分新行,操作符放在新行之首,划分出的新行要进行适当的缩进,使排版整齐,语句可读。
【1】report_or_not_flag = ((taskno < MAX_ACT_TASK_NUMBER)
&& (n7stat_stat_item_valid (stat_item))
&& (act_task_table[taskno].result_data != 0));
【2】for (i = 0, j = 0; (i < BufferKeyword[word_index].word_length)
&& (j < NewKeyword.word_length); i++, j++)
【3】 CANx->sTxMailBox[transmit_mailbox].TDLR = (((uint32_t)TxMessage->Data[3] << 24) |
((uint32_t)TxMessage->Data[2] << 16) |
((uint32_t)TxMessage->Data[1] << 8) |
((uint32_t)TxMessage->Data[0]));
7、代码行内的空格和修饰符、括号等:
【1】关键字后留空格:C语言的32个关键字,如if/while/do/case ();
if (NewState != DISABLE)
【2】函数名后不留空格:紧跟括号( , 区别关键字.
void ADC_DiscModeChannelCountConfig(ADC_TypeDef* ADCx, uint8_t Number);
【3】紧跟:(号向后紧跟, )和,和;向前紧跟,不留空格; int a, b, c;
【4】二元操作符:前后加空格;==对等操作
【5】一元操作符:前后不加空格;如"[ ]"和" . "和"->"这类操作符前后不加空格.==关系密切的立即操作符
【6】对于表达式比较长的for语句和if语句,为了紧凑起见可以适当地去掉一些空格:
if ((a>=b) && (c<=d)) // 良好的风格
for (i=0; i<10; i++) // 良好的风格
x = a
==
【7】修饰符紧靠变量名:不会被误认: int *x, y;
==
【8】注意运算符的优先级,并用括号明确表达式的操作顺序:
if ((a | b) < (c & d))
if ((a>=b) && (c<=d)) // 良好的风格
三、注释
目的:增加代码的可读性,帮助更好的理解程序。
1、必要性:
在代码的功能、意图层次上注释,解释代码的目的、功能和采用的方法,提供代码外的信息,帮助理解,已经清楚的语句就不要重复注释。
2、自注释:
通过对函数或过程、变量、结构等正确的命名以及合理地组织代码的结构。
3、及时性和准确性:
边写代码边注释,改了代码也要改注释,不用的注释要删除。
4、注释的量:
一般源程序有效注释量必须在20%以上。必须是有助于对程序的理解,准确易懂、清楚无二义性、简洁明了。
5、注释格式和语言尽量统一:
【1】格式尽量统一用/* */。
【2】格式如果不能非常留意准确用英文表达,则统一用中文,不要中英文混用。
6、注释所在位置和排版:
【1】注释放在语句上方或者右方不放在下方,注释放在上方时必须和上面的代码用空行隔开。
【2】注释应该与所描述内容进行同样缩排保持整齐,方便阅读。
7、注释文件:
【1】如开头部分所说,基本说明性文件,.h文件、.inc文件、编译说明文件等。注释的内容类似头文件注释格式。
【2】如开头部分所说,重要的源文件,注释内容除写上版权这些以外,注明模块功能,主要实现函数,对外接口函数,修改记录等等。
8、注释函数:
一般包含 函数功能,输入参数,输出参数,返回值,备注信息,调用列表等。

@实例:
/**
* @brief /Description: Returns the frequencies of different on chip clocks.
* @param RCC_Clocks: pointer to a RCC_ClocksTypeDef structure which will hold
* the clocks frequencies.
* @note The result of this function could be not correct when using
* fractional value for HSE crystal.
* @retval None
*/
void RCC_GetClocksFreq(RCC_ClocksTypeDef* RCC_Clocks)
@返回值:
[1] Returns negative errno, else the number of messages executed.
[2]* Returns negative errno, or else the number of bytes read/written.
9、代码主要注释内容:
【1】有实际意义的常量、变量、宏:除非其自注释,不然都加上注释。
【2】结构体声明(含数组、结构体、类、枚举等):其注释在上方,结构体中的域在其右方注释。
/* sccp interface with sccp user primitive message name */
enum SCCP_USER_PRIMITIVE
{
N_UNITDATA_IND, /* sccp notify sccp user unit data come */
}
【3】分支语句(条件、循环、switch):每一功能的注释。
【4】大程序块结束:加上注释,便于阅读,如if,while,for这些语句的多层嵌套。
【5】全局变量:要有比较详细的注释,包含其功能、取值范围、调用者和注释事项等。

四、标识符命名
标识shi符就是程序员自己规定的具有特定含义的词,比如类名称,属性名称,变量名和函数名等。标识符由字母、数字、下划线“_”组成,关键字不能作为标识符。
1、基本规则
(1)含义精确:标识符应该 直观且易读,望文知意。要使用准确的英文字符.。
如:CurrentValue不写成NowValue
(2)长度精简:“ min-length && max-information”--最精确精简的词。---长但不要太长
@缩写:可用大家基本可用理解的缩写。temp=>tmp; message=>msg;
(3)变量名组成:使用"名词"或者“形容词+名词”;
@建议除了有具体含义外,还要能表明变量类型:——下面讲的匈牙利命名规则
int iwidth; // i表明该变量为int型,width指明是宽度
(4)函数名组成:全局函数的名字应当使用“动词”或者“动词+名词”(动宾词组)。类的成员函数应当只使用“动词”,被省略掉的名词就是对象本身。
DrawBox(); // 全局函数
box->Draw(); // 类的成员函数
@嵌入式中,如果是相关的模块驱动,前面加上模块名。
void BCT3286_SPI_Init(void);
(5)常量:全用大写的字母,用下划线分割单词。
const int MAX = 100;
const int MAX_LENGTH = 100;
#define MAX_ARRAY 100
#define SHOW_DTDATA (WM_USER+0x101) //记得带上括号
(6)特殊软件库前缀:为了防止某一软件库中的一些标识符和其它软件库中的冲突,可以为各种标识符加上能反映软件性质的前缀。例如三维图形标准OpenGL的所有库函数均以gl开头,所有常量(或宏定义)均以GL开头。
(7)不要出现:
[1]仅靠大小写区分的相识标识符。
[2]相同命名的局部和全局变量。
[3]尽量避免名字中出现数字编号,如Value1,Value2等,除非逻辑上的确需要编号。
(8)切合操作系统: 命名要切合操作系统与开发工具的风格
@Windows和stm32:
[1]变量:标识符采用首字母小写的“大小写”混排addChild;
[2]类名和函数:所有首字母大写的大小写混合,AddChild;
==widows中:
[1]变量和参数用小写字母开头的单词组合而成。
BOOL flag;
int drawMode;
[2]类名和函数名用大写字母开头的单词组合而成。
class LeafNode; // 类名
void SetValue(int value); // 函数名
==stm32中:同windows,差别在如果是底层驱动函数要加上模块名。
---------
@linux应用程序和ARM9嵌入式:
函数和变量这些标识符采用全小写加下划线add_child。
1)变量名必须意义准确。
例如有一个变量用于保存图书的数目,可以命名为number_of_book或者num_of_book。不建议使用i,因为它没有意义。也不建议使用number或book,因为意义不准确。
2)不建议大小写混用。
如定义一个计数变量,int nCount;这在Windows中是一个很好的变量名,其中nCount的首字母n用来说明这个变量的类型是int。但在Linux下不建议大小写混合使用,一般标识符只由小写字母,数字和下划线构成。
3)在失去意义的情况下,尽量使用较短的变量名。
例如有一个变量,用于暂时存储一个计数值,把变量命名为tmp_count显然要比this_is_a_temperary_counter好。
4)不采用匈牙利命名法表示变量的类型。
如int nCount;n用于说明变量的类型,在Linux中不建议这样命名变量。
5)函数名应该以动词开头。
因为函数是一组具有特定功能的语句块。比如一个函数,它用于取得外部输入的数值,则可以命名为get_input_number。
IIS_pin_init();
set_IIS_for_record();
start_IIS();
6)尽量避免使用全局变量
(8)不要出现:
[1]仅靠大小写区分的相识标识符。
[2]相同命名的局部和全局变量。
[3]尽量避免名字中出现数字编号,如Value1,Value2等,除非逻辑上的确需要编号。
2、匈牙利命名法(多用在上位机语言):
在变量名和函数名中加入前缀,以增进人们对程序的理解。
基本原则是:变量名=属性+类型+对象描述,其中每一对象的名称都要求有明确含义,可以取对象名字全称或名字的一部分。
(1)变量属性,前缀
g_ 全局变量(表示global)
s_ 静态变量 (表示static) static int s_initValue;
c_ 常量
m_ c++类成员变量(表示member)这样可以避免数据成员与成员函数的参数同名。
void Object::SetValue(int width, int height)
{
m_width = width;
m_height = height;
}
(2)类型部分:
数组 a
指针 p
函数 fn
无效 v
句柄 h
长整型 l
布尔 b
浮点型(有时也指文件) f
双字 dw
字符串 sz
短整型 n
双精度浮点 d
计数 c(通常用cnt)
字符 ch(通常用c)
整型 i(通常用n)
字节 by
字 w
实型 r
无符号 u
(3)描述部分:
最大 Max
最小 Min
初始化 Init
临时变量 T(或Temp)
源对象 Src
目的对象 Dest
(4)举例:
hwnd : h 是类型描述,表示句柄, wnd 是变量对象描述,表示窗口,所以 hwnd 表示窗口句柄;
pfnEatApple : pfn 是类型描述,表示指向函数的指针, EatApple 是变量对象描述,所以它表示指向 EatApple 函数的函数指针变量。
g_cch : g_ 是属性描述,表示全局变量,c 和 ch 分别是计数类型和字符类型,一起表示变量类型,这里忽略了对象描述,所以它表示一个对字符进行计数的全局变量。
五、宏、全局变量和其他注意
1、宏的使用+定义规范:
(1)由来:不易理解的数字和常量则用有意义的枚举或者宏来替代:
#define BUFF_SIZE 1024
input_data = (char *)malloc(BUFF_SIZE);
(2)宏定义规范
【1】括号:宏定义表达,需要完整的括号。
#define GET_AREA(a,b) ((a) * (b))
【2】大括号:宏中有多条语句,应将语句放在一对大括号中。
#define INTI_RECT_VALUE( a, b ) {\
a = 0;\
b = 0;\
}
2、全局变量:
【1】避免使用: 尽量避免使用,它占用程序空间,同时增大了模块间的耦合性,不利于软件维护。
【2】规范:应明确其含义、作用、取值范围。明确全局变量与操作此变量的函数的关系,如创建、访问、修改。
3、其他原则
[1]专一:一行代码只做一件事情,如只定义一个变量,或只写一条语句。---易阅读和注释。
[2]就近原则:尽可能在定义变量的同时初始化该变量。
[3]数据大小端统一:通信协议中数据的大小端要和整个团队形成统一。
六、函数和类:
====函数
【1】函数名:应能准确描述函数功能,一般以动词加宾语的形式;print_record
【2】参数个数:不宜过多,1-3个为好;
【3】返回值:清楚、明了,让调用者不易忽视错误情况。每种错误的返回值要清晰、明确,防止调用者误用;
@linux中函数的返回值:正常的时候返回0,错误的时候返回-1或者小于零的错误码。
@WINDOWS和stm32函数返回值:
如果GetCommState()函数调用成功,则返回值大于零。若函数调用失败,则返回值为零,如果想得到进一步的错误信息,可以调用GetLastError()函数来获取。
【4】输入参数:检查其有效性,如指针型参数判断是否为空,数组成员是否越界等等;
【5】规模:限制在200行以内(不含空行和注释行);
【6】功能专一:一个函数完成一个特定功能;
【7】功能可预测:输入数据相同,能得到可预期的输出;
【8】代码重用:多段代码重复做一件事,考虑将重复功能实现成一个函数;
【9】独立性:减少与其他函数的联系,提高可读性、维护性和效率。
避免函数本身和函数间的递归调用,递归影响可读性和系统资源如栈空间。
====类的版式
类可以将数据和函数封装在一起,其中函数表示了类的行为(或称服务)。类提供关键字public、protected和private,分别用于声明哪些数据和函数是公有的、受保护的或者是私有的。
主张提倡的书写方式:将public类型的函数写在前面,而将private类型的数据写在后面,这种版式的程序员主张类的设计“以行为为中心”,重点关注的是类应该提供什么样的接口(或服务)。即首先考虑类应该提供什么样的函数。“这样做不仅让自己在设计类时思路清晰,而且方便别人阅读。因为用户最关心的是接口,谁愿意先看到一堆私有数据成员!”
class A
{
public:
void Func1(void);
void Func2(void);
…
private:
int i, j;
float x, y;
…
}