【TensorFlow】使用RNN预测时间序列
现有一个时间序列international-airline-passengers.csv,怎么使用RNN来预测呢?本文就对其进行详细的阐述。
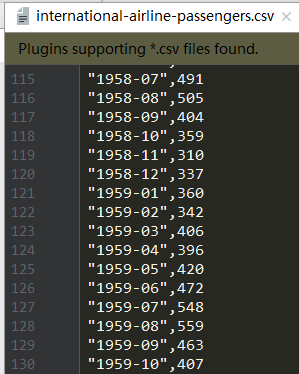
本时间序列一共144行,数据量很小,但是用其来学习RNN的使用已经足够了。
使用RNN预测时间序列的整体思路是:
- 取时间序列的第二列(international-airline-passengers.csv的第一列数据为时间,未在本次程序中使用),由于第二列值差异较大,所以本文采用“(原值-平均值)/标准差”的方法对数据进行标准化处理,前80%的数据作为训练集train_x,后20%的数据作为测试集test_x。
- 设置RNN的参数:input_dim=1、seq_size=5、hidden_dim=100
- 训练集和测试集的标签分别记为train_y、test_y,train_x和train_y的值错开了一个单位,test_x和test_y的值也是错开一个单位,便于计算cost值
- RNN模型的输出out为5个值的一维数组
实现程序
读CSV文件、数据标准化data_loader.py:
import csv
import numpy as np
import matplotlib.pyplot as plt
def load_series(filename, series_idx=1):
try:
with open(filename) as csvfile:
csvreader = csv.reader(csvfile)
data = [float(row[series_idx]) for row in csvreader if len(row) > 0]
# 数据标准化,可以使数据的浮动差异不那么大,使预测结果更准确。np.mean求平均值,np.std求标准差。
normalized_data = (data - np.mean(data)) / np.std(data)
return normalized_data
except IOError:
return None
# 把数据切分成80%训练集、20%测试集
def split_data(data, percent_train=0.80):
num_rows = len(data)
train_data, test_data = [], []
for idx, row in enumerate(data):
if idx < num_rows * percent_train:
train_data.append(row)
else:
test_data.append(row)
return train_data, test_data
if __name__ == '__main__':
timeseries = load_series('international-airline-passengers.csv')
print(np.shape(timeseries))
plt.figure()
plt.plot(timeseries)
plt.show()
144条数据的显示结果:

模型训练rnn_ts.py:
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
import data_loader
import matplotlib.pyplot as plt
class SeriesPredictor:
def __init__(self, input_dim, seq_size, hidden_dim):
# Hyperparameters
self.input_dim = input_dim
self.seq_size = seq_size
self.hidden_dim = hidden_dim
# Weight variables and input placeholders
self.W_out = tf.Variable(tf.random_normal([hidden_dim, 1]), name='W_out')
self.b_out = tf.Variable(tf.random_normal([1]), name='b_out')
self.x = tf.placeholder(tf.float32, [None, seq_size, input_dim])
# 5个小片段,有5个预测值
self.y = tf.placeholder(tf.float32, [None, seq_size])
# Cost optimizer
self.cost = tf.reduce_mean(tf.square(self.model() - self.y))
self.train_op = tf.train.AdamOptimizer(learning_rate=0.01).minimize(self.cost)
# Auxiliary ops
self.saver = tf.train.Saver()
def model(self):
"""
:param x: inputs of size [T, batch_size, input_size]
:param W: matrix of fully-connected output layer weights
:param b: vector of fully-connected output layer biases
"""
cell = rnn.BasicLSTMCell(self.hidden_dim)
outputs, states = tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32)
num_examples = tf.shape(self.x)[0]
W_repeated = tf.tile(tf.expand_dims(self.W_out, 0), [num_examples, 1, 1])
out = tf.matmul(outputs, W_repeated) + self.b_out
out = tf.squeeze(out)
# 返回长度为5的一维数组
return out
def train(self, train_x, train_y, test_x, test_y):
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables()
sess.run(tf.global_variables_initializer())
max_patience = 3
patience = max_patience
# 最小err指定为无限
min_test_err = float('inf')
step = 0
# test_err出现3次浮动停下
while patience > 0:
_, train_err = sess.run([self.train_op, self.cost], feed_dict={self.x: train_x, self.y: train_y})
if step % 100 == 0:
test_err = sess.run(self.cost, feed_dict={self.x: test_x, self.y: test_y})
print('step:{}\t\ttrain err:{}\t\ttest err:{}'.format(step, train_err, test_err))
if test_err < min_test_err:
min_test_err = test_err
patience = max_patience
else:
patience -= 1
step += 1
save_path = self.saver.save(sess, './model/')
print('Model saved to {}'.format(save_path))
def test(self, sess, test_x):
tf.get_variable_scope().reuse_variables()
self.saver.restore(sess, './model/')
output = sess.run(self.model(), feed_dict={self.x: test_x})
return output
def plot_results(train_x, predictions, actual, filename):
plt.figure()
num_train = len(train_x)
# 训练集。plt.plot(x,y,format_string,**kwargs) x轴数据,y轴数据
plt.plot(list(range(num_train)), train_x, color='b', label='training data')
# 预测集
plt.plot(list(range(num_train, num_train + len(predictions))), predictions, color='r', label='predicted')
# 真实值
plt.plot(list(range(num_train, num_train + len(actual))), actual, color='g', label='test_data')
# 加图例
plt.legend()
if filename is not None:
plt.savefig(filename)
else:
plt.show()
if __name__ == '__main__':
# 序列长度,基于一个小片段去预测下一个值
seq_size = 5
predictor = SeriesPredictor(input_dim=1, seq_size=seq_size, hidden_dim=100)
data = data_loader.load_series('international-airline-passengers.csv')
# 数据切分成训练集,测试集
train_data, actual_vals = data_loader.split_data(data)
train_x, train_y = [], []
for i in range(len(train_data) - seq_size - 1):
# 训练数据和标签错开了1个单位
train_x.append(np.expand_dims(train_data[i:i + seq_size], axis=1).tolist())
train_y.append(train_data[i + 1: i + seq_size + 1])
test_x, test_y = [], []
for i in range(len(actual_vals) - seq_size - 1):
test_x.append(np.expand_dims(actual_vals[i:i + seq_size], axis=1).tolist())
test_y.append(actual_vals[i + 1: i + seq_size + 1])
predictor.train(train_x, train_y, test_x, test_y)
with tf.Session() as sess:
# [:, 0]为什么是0呢?不应该是-1么?
# 1、用训练好的模型'./model/'预测,所以第一个值也是基于前面序列预测到的。
# 2、画图时使预测值和真实值具有对照性。
predicted_vals = predictor.test(sess, test_x)[:, 0]
print('predicted_vals', np.shape(predicted_vals))
plot_results(train_data, predicted_vals, actual_vals, 'predictions.png')
# 拿出训练集最后5个数据
prev_seq = train_x[-1]
predicted_vals = []
for i in range(20):
next_seq = predictor.test(sess, [prev_seq])
# 把预测的结果当做当前的结果值,继续预测。
predicted_vals.append(next_seq[-1])
# np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组;np.hstack:按水平方向(列顺序)堆叠数组构成一个新的数组
# prev_seq[1:]取第二至第五个数据,一共4个数据
prev_seq = np.vstack((prev_seq[1:], next_seq[-1]))
plot_results(train_data, predicted_vals, actual_vals, 'hallucinations.png')
运行结果:
step:0 train err:1.8898743391036987 test err:2.7799108028411865
step:100 train err:0.04205527901649475 test err:0.2253977209329605
step:200 train err:0.039602071046829224 test err:0.28264862298965454
step:300 train err:0.03779347985982895 test err:0.2434949427843094
step:400 train err:0.03636837378144264 test err:0.2533899247646332
Model saved to ./model/
predicted_vals (22,)predictions.png:
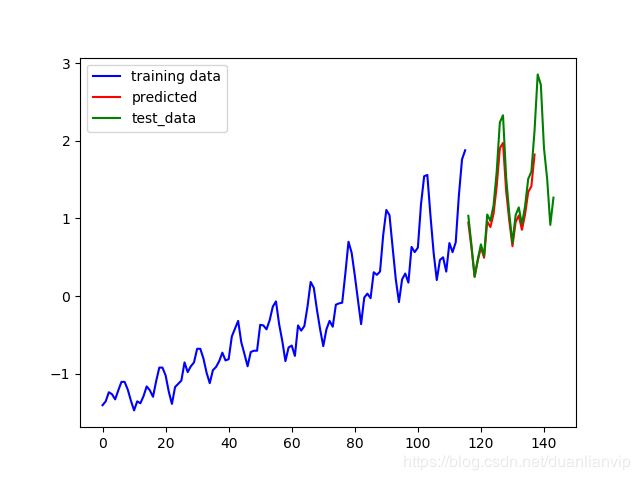
hallucinations.png:

停止迭代方法大概有三种:
- 精度大于某个阈值停下来。例:acc>=0.98停下来;
- 测试err出现几次浮动停下来;
- 迭代次数达到XXX次停下来。
本文采用的是第二种方法。