【TensorFlow】TensorBoard的使用(三)
在《【TensorFlow】TensorBoard的使用(二)》中讲述了如何使生成的图更具有可阅读性,但是生成的可阅读参数较少,本文旨在增加TensorBoard的展示信息。
主要增加如下信息:
- 权重、偏置等在训练过程中的分布情况:tf.summary.histogram('weights', w)
- 损失值、准确率随着迭代次数的进行,其指标变化情况:tf.summary.scalar('accuracy', accuracy)
- 输入值的显示:tf.summary.image('input', x_image, 3)
本文在《【TensorFlow】TensorBoard的使用(二)》示例的基础上对TensorBoard进行优化。
示例
实现以上三步优化,代码如下:
mnist_board_3.py:
import os
import tensorflow as tf
LOGDIR = './mnist'
mnist = tf.contrib.learn.datasets.mnist.read_data_sets(train_dir=LOGDIR + 'data', one_hot=True)
# 加上name值,方便在tensorboard里面查看
def conv_layer(input, size_in, size_out, name='conv'):
# 定义名字作用域
with tf.name_scope(name):
w = tf.Variable(tf.truncated_normal([5, 5, size_in, size_out], stddev=0.1), name='W')
# w的值也是对训练准确率有很大的影响,下面初始化的方法就会造成网络不收敛,因为训练时w的变化幅度比较小
# w = tf.Variable(tf.zeros([5, 5, size_in, size_out]), name='W')
b = tf.Variable(tf.constant(0.1, shape=[size_out]), name='B')
conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding='SAME')
act = tf.nn.relu(conv + b)
# 分布情况:在训练过程中查看分布情况
tf.summary.histogram('weights', w)
tf.summary.histogram('biases', b)
tf.summary.histogram('activations', act)
return tf.nn.max_pool(act, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def fc_layer(input, size_in, size_out, name='fc'):
with tf.name_scope(name):
w = tf.Variable(tf.truncated_normal([size_in, size_out], stddev=0.1), name='W')
b = tf.Variable(tf.constant(0.1, shape=[size_out]), name='B')
act = tf.nn.relu(tf.matmul(input, w) + b)
tf.summary.histogram('weights', w)
tf.summary.histogram('biases', b)
tf.summary.histogram('activations', act)
return act
def mnist_model(learning_rate, use_two_conv, use_two_fc, hparam):
tf.reset_default_graph()
sess = tf.Session()
# setup placeholders, and reshape the data
x = tf.placeholder(tf.float32, shape=[None, 784], name='x')
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 显示当前的输入:数据集中的图像
tf.summary.image('input', x_image, 3)
y = tf.placeholder(tf.float32, shape=[None, 10], name='labels')
if use_two_conv:
conv1 = conv_layer(x_image, 1, 32, 'conv1')
conv_out = conv_layer(conv1, 32, 64, 'conv2')
else:
conv1 = conv_layer(x_image, 1, 64, 'conv')
conv_out = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
flattened = tf.reshape(conv_out, [-1, 7 * 7 * 64])
if use_two_fc:
fc1 = fc_layer(flattened, 7 * 7 * 64, 1024, 'fc1')
embedding_input = fc1
embedding_size = 1024
logits = fc_layer(fc1, 1024, 10, 'fc2')
else:
embedding_input = flattened
embedding_size = 7 * 7 * 64
logits = fc_layer(flattened, 7 * 7 * 64, 10, 'fc')
with tf.name_scope('loss'):
xent = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y), name='loss')
# 指标变化:随着网络的迭代,loss值的变化
tf.summary.scalar('loss', xent)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(xent)
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 指标变化:随着迭代进行,精度的变化情况
tf.summary.scalar('accuracy', accuracy)
# 把所有要显示的参数聚在一起
summ = tf.summary.merge_all()
emdedding = tf.Variable(tf.zeros([1024, embedding_size]))
assignment = emdedding.assign(embedding_input)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
# 保存路径
tenboard_dir = './tensorboard/test3/'
# 指定一个文件用来保存图
writer = tf.summary.FileWriter(tenboard_dir + hparam)
# 把图add进去
writer.add_graph(sess.graph)
for i in range(2001):
batch = mnist.train.next_batch(100)
# 每迭代5次对结果进行保存
if i % 5 == 0:
[train_accuracy, s] = sess.run([accuracy, summ], feed_dict={x: batch[0], y: batch[1]})
writer.add_summary(s, i)
sess.run(train_step, feed_dict={x: batch[0], y: batch[1]})
def make_hparam_string(learning_rate, use_two_fc, use_two_conv):
conv_param = 'conv=2' if use_two_conv else 'conv=1'
fc_param = 'fc=2' if use_two_fc else 'fc=1'
return 'lr_%.0E,%s,%s' % (learning_rate, conv_param, fc_param)
def main():
# You can try adding some more learning rates
for learning_rate in [1E-4]:
# Include 'False' as a value to try different model architectures.
for use_two_fc in [True]:
for use_two_conv in [True]:
# Construct a hyperparameter string for each one(example: 'lr_1E-3,fc=2,conv=2')
hparam = make_hparam_string(learning_rate, use_two_fc, use_two_conv)
print('Starting run for %s' % hparam)
# Actually run with the new settings
mnist_model(learning_rate, use_two_fc, use_two_conv, hparam)
if __name__ == '__main__':
main()
展示
执行上述程序,生成test3文件夹,运行TensorBoard,显示如下。
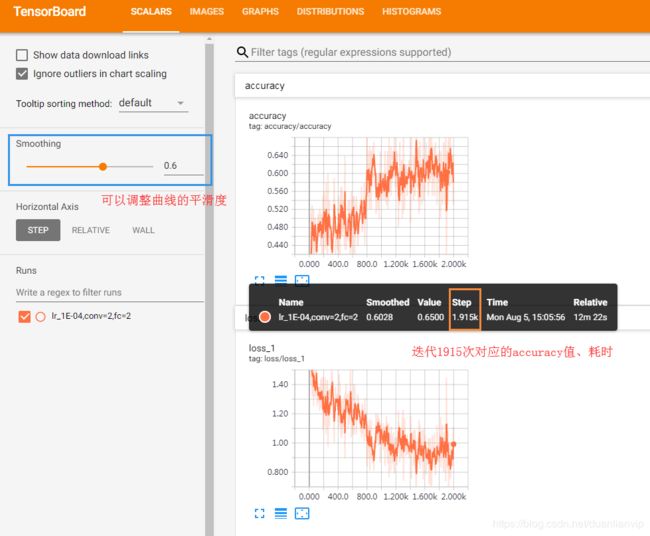
损失值、准确率随着迭代次数的进行,其指标变化情况:
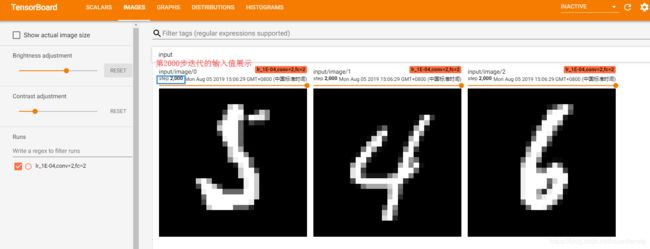
输入值的显示:
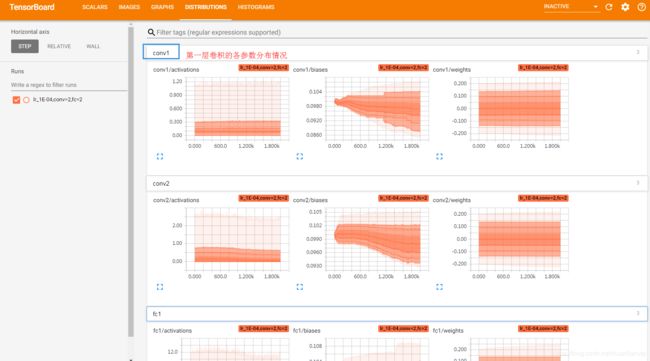
权重、偏置等在训练过程中的分布情况(二维显示):
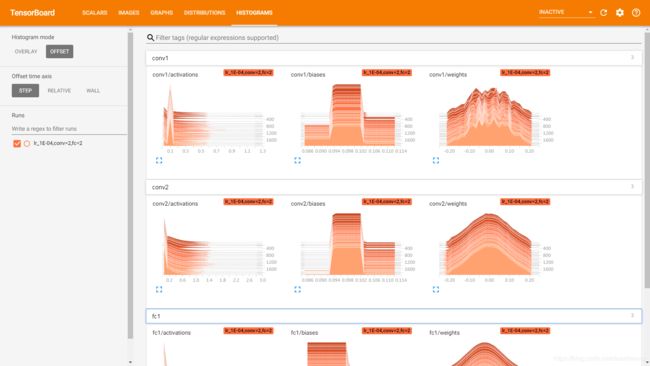
权重、偏置等在训练过程中的分布情况(三维显示):
上图展示的数据比文章《【TensorFlow】TensorBoard的使用(二)》明显增多,可以观察loss、accuracy值的变化情况,那么能否对比不同的参数(w、b、学习率)值之间的loss、accuracy变化情况呢?以此来直观的挑选出最佳参数值?答案当然是可以的。
下篇文章讲述如何实现上述情况——利用TensorBoard进行参数选择。