Hive on Spark解析(转自Intel李锐)
摘要:Hive是基于Hadoop平台的数据仓库,已经成为Hadoop事实上的SQL引擎标准。相较于Impala、Shark等,Hive拥有更为广泛的用户基础以及对SQL语法更全面的支持。这里,将走进Hive on Spark世界。
Hive是基于Hadoop平台的数据仓库,最初由Facebook开发,在经过多年发展之后,已经成为Hadoop事实上的SQL引擎标准。相较于其他诸如Impala、Shark(SparkSQL的前身)等引擎而言,Hive拥有更为广泛的用户基础以及对SQL语法更全面的支持。Hive最初的计算引擎为MapReduce,受限于其自身的Map+Reduce计算模式,以及不够充分的大内利用,MapReduce的性能难以得到提升。
Hortonworks于2013年提出将Tez作为另一个计算引擎以提高Hive的性能。Spark则是最初由加州大学伯克利分校开发的分布式计算引擎,借助于其灵活的DAG执行模式、对内存的充分利用,以及RDD所能表达的丰富语义,Spark受到了Hadoop社区的广泛关注。在成为Apache顶级项目之后,Spark更是集成了流处理、图计算、机器学习等功能,是业界公认最具潜力的下一代通用计算框架。鉴于此,Hive社区于2014年推出了Hive on Spark项目(HIVE-7292),将Spark作为继MapReduce和Tez之后Hive的第三个计算引擎。该项目由Cloudera、Intel和MapR等几家公司共同开发,并受到了来自Hive和Spark两个社区的共同关注。目前Hive on Spark的功能开发已基本完成,并于2015年1月初合并回trunk,预计会在Hive下一个版本中发布。本文将介绍Hive on Spark的设计架构,包括如何在Spark上执行Hive查询,以及如何借助Spark来提高Hive的性能等。另外本文还将介绍Hive on Spark的进度和计划,以及初步的性能测试数据。
背景
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。
在介绍Hive on Spark的具体设计之前,先简单介绍一下Hive的工作原理,以便于大家理解如何把Spark作为新的计算引擎供给Hive使用。
在Hive中, 一条SQL语句从用户提交到计算并返回结果,大致流程如下图所示(Hive 0.14中引入了基于开销的优化器(Cost Based Optimizer,CBO),优化的流程会略有不同。
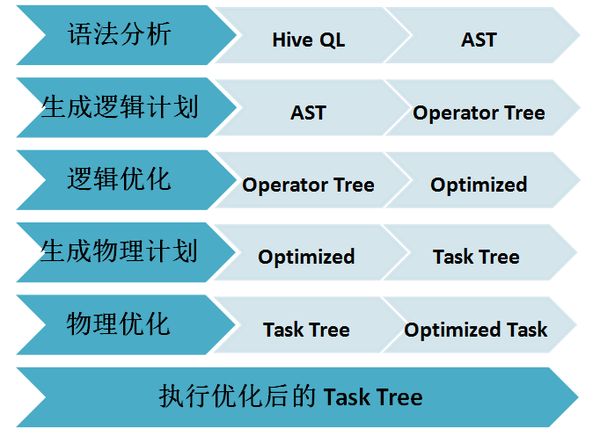
图1:SQL语句执行流程
语法分析阶段,Hive利用Antlr将用户提交的SQL语句解析成一棵抽象语法树(Abstract Syntax Tree,AST)。
生成逻辑计划包括通过Metastore获取相关的元数据,以及对AST进行语义分析。得到的逻辑计划为一棵由Hive操作符组成的树,Hive操作符即Hive对表数据的处理逻辑,比如对表进行扫描的TableScanOperator,对表做Group的GroupByOperator等。
逻辑优化即对Operator Tree进行优化,与之后的物理优化的区别主要有两点:一是在操作符级别进行调整;二是这些优化不针对特定的计算引擎。比如谓词下推(Predicate Pushdown)就是一个逻辑优化:尽早的对底层数据进行过滤以减少后续需要处理的数据量,这对于不同的计算引擎都是有优化效果的。
生成物理计划即针对不同的引擎,将Operator Tree划分为若干个Task,并按照依赖关系生成一棵Task的树(在生成物理计划之前,各计算引擎还可以针对自身需求,对Operator Tree再进行一轮逻辑优化)。比如,对于MapReduce,一个GROUP BY+ORDER BY的查询会被转化成两个MapReduce的Task,第一个进行Group,第二个进行排序。
物理优化则是各计算引擎根据自身的特点,对Task Tree进行优化。比如对于MapReduce,Runtime Skew Join的优化就是在原始的Join Task之后加入一个Conditional Task来处理可能出现倾斜的数据。
最后按照依赖关系,依次执行Task Tree中的各个Task,并将结果返回给用户。每个Task按照不同的实现,会把任务提交到不同的计算引擎上执行。
总体设计
Hive on Spark总体的设计思路是,尽可能重用Hive逻辑层面的功能;从生成物理计划开始,提供一整套针对Spark的实现,比如SparkCompiler、SparkTask等,这样Hive的查询就可以作为Spark的任务来执行了。以下是几点主要的设计原则。
尽可能减少对Hive原有代码的修改。这是和之前的Shark设计思路最大的不同。Shark对Hive的改动太大以至于无法被Hive社区接受,Hive on Spark尽可能少改动Hive的代码,从而不影响Hive目前对MapReduce和Tez的支持。同时,Hive on Spark保证对现有的MapReduce和Tez模式在功能和性能方面不会有任何影响。
对于选择Spark的用户,应使其能够自动的获取Hive现有的和未来新增的功能。
尽可能降低维护成本,保持对Spark依赖的松耦合。
基于以上思路和原则,具体的一些设计架构如下。
新的计算引擎
Hive的用户可以通过hive.execution.engine来设置计算引擎,目前该参数可选的值为mr和tez。为了实现Hive on Spark,我们将spark作为该参数的第三个选项。要开启Hive on Spark模式,用户仅需将这个参数设置为spark即可。
以Hive的表作为RDD
Spark以分布式可靠数据集(Resilient Distributed Dataset,RDD)作为其数据抽象,因此我们需要将Hive的表转化为RDD以便Spark处理。本质上,Hive的表和Spark的HadoopRDD都是HDFS上的一组文件,通过InputFormat和RecordReader读取其中的数据,因此这个转化是自然而然的。
使用Hive原语
这里主要是指使用Hive的操作符对数据进行处理。Spark为RDD提供了一系列的转换(Transformation),其中有些转换也是面向SQL的,如groupByKey、join等。但如果使用这些转换(就如Shark所做的那样),就意味着我们要重新实现一些Hive已有的功能;而且当Hive增加新的功能时,我们需要相应地修改Hive on Spark模式。有鉴于此,我们选择将Hive的操作符包装为Function,然后应用到RDD上。这样,我们只需要依赖较少的几种RDD的转换,而主要的计算逻辑仍由Hive提供。
由于使用了Hive的原语,因此我们需要显式地调用一些Transformation来实现Shuffle的功能。下表中列举了Hive on Spark使用的所有转换。
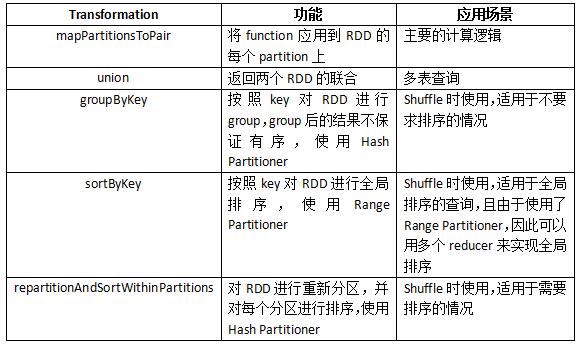
对repartitionAndSortWithinPartitions 简单说明一下,这个功能由SPARK-2978引入,目的是提供一种MapReduce风格的Shuffle。虽然sortByKey也提供了排序的功能,但某些情况下我们并不需要全局有序,另外其使用的Range Partitioner对于某些Hive的查询并不适用。
物理执行计划
通过SparkCompiler将Operator Tree转换为Task Tree,其中需要提交给Spark执行的任务即为SparkTask。不同于MapReduce中Map+Reduce的两阶段执行模式,Spark采用DAG执行模式,因此一个SparkTask包含了一个表示RDD转换的DAG,我们将这个DAG包装为SparkWork。执行SparkTask时,就根据SparkWork所表示的DAG计算出最终的RDD,然后通过RDD的foreachAsync来触发运算。使用foreachAsync是因为我们使用了Hive原语,因此不需要RDD返回结果;此外foreachAsync异步提交任务便于我们对任务进行监控。
SparkContext生命周期
SparkContext是用户与Spark集群进行交互的接口,Hive on Spark应该为每个用户的会话创建一个SparkContext。但是Spark目前的使用方式假设SparkContext的生命周期是Spark应用级别的,而且目前在同一个JVM中不能创建多个SparkContext(请参考SPARK-2243)。这明显无法满足HiveServer2的应用场景,因为多个客户端需要通过同一个HiveServer2来提供服务。鉴于此,我们需要在单独的JVM中启动SparkContext,并通过RPC与远程的SparkContext进行通信。
任务监控与统计信息收集
Spark提供了SparkListener接口来监听任务执行期间的各种事件,因此我们可以实现一个Listener来监控任务执行进度以及收集任务级别的统计信息(目前任务级别的统计由SparkListener采集,任务进度则由Spark提供的专门的API来监控)。另外Hive还提供了Operator级别的统计数据信息,比如读取的行数等。在MapReduce模式下,这些信息通过Hadoop Counter收集。我们可以使用Spark提供的Accumulator来实现该功能。
测试
除了一般的单元测试以外,Hive还提供了Qfile Test,即运行一些事先定义的查询,并根据结果判断测试是否通过。Hive on Spark的Qfile Test应该尽可能接近真实的Spark部署环境。目前我们采用的是local-cluster的方式(该部署模式主要是Spark进行测试时使用,并不打算让一般用户使用),最终的目标是能够搭建一个Spark on YARN的Mini Cluster来进行测试。
实现细节
这一部分我们详细介绍几个重要的实现细节。
SparkTask的生成和执行
我们通过一个例子来看一下一个简单的两表JOIN查询如何被转换为SparkTask并被执行。下图左半部分展示了这个查询的Operator Tree,以及该Operator Tree如何被转化成SparkTask;右半部分展示了该SparkTask执行时如何得到最终的RDD并通过foreachAsync提交Spark任务。
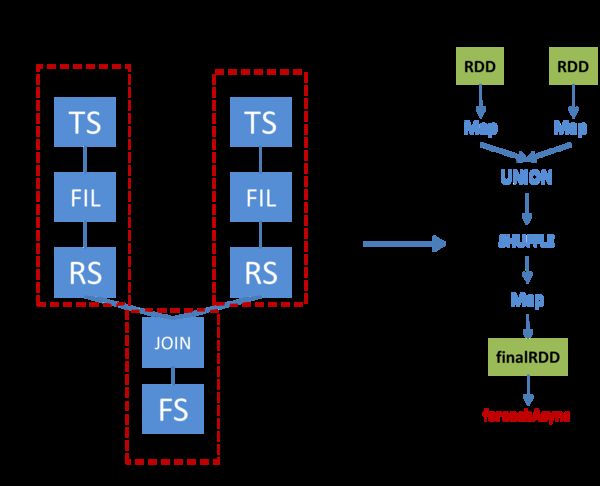
图2:两表join查询到Spark任务的转换
SparkCompiler遍历Operator Tree,将其划分为不同的MapWork和ReduceWork。MapWork为根节点,总是由TableScanOperator(Hive中对表进行扫描的操作符)开始;后续的Work均为ReduceWork。ReduceSinkOperator(Hive中进行Shuffle输出的操作符)用来标记两个Work之间的界线,出现ReduceSinkOperator表示当前Work到下一个Work之间的数据需要进行Shuffle。因此,当我们发现ReduceSinkOperator时,就会创建一个新的ReduceWork并作为当前Work的子节点。包含了FileSinkOperator(Hive中将结果输出到文件的操作符)的Work为叶子节点。与MapReduce最大的不同在于,我们并不要求ReduceWork一定是叶子节点,即ReduceWork之后可以链接更多的ReduceWork,并在同一个SparkTask中执行。
从该图可以看出,这个查询的Operator Tree被转化成了两个MapWork和一个ReduceWork。在执行SparkTask时,首先根据MapWork来生成最底层的HadoopRDD,然后将各个MapWork和ReduceWork包装成Function应用到RDD上。在有依赖的Work之间,需要显式地调用Shuffle转换,具体选用哪种Shuffle则要根据查询的类型来确定。另外,由于这个例子涉及多表查询,因此在Shuffle之前还要对RDD进行Union。经过这一系列转换后,得到最终的RDD,并通过foreachAsync提交到Spark集群上进行计算。
运行模式
Hive on Spark支持两种运行模式:本地和远程。当用户把Spark Master URL设置为local时,采用本地模式;其余情况则采用远程模式。本地模式下,SparkContext与客户端运行在同一个JVM中;远程模式下,SparkContext运行在一个独立的JVM中。提供本地模式主要是为了方便调试,一般用户不应选择该模式。因此我们这里也主要介绍远程模式(Remote SparkContext,RSC)。下图展示了RSC的工作原理。
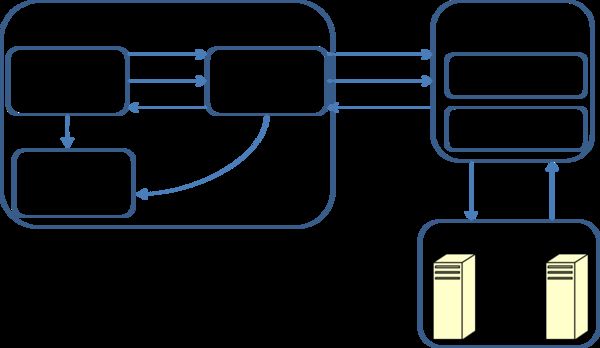
图3:RSC工作原理
用户的每个Session会创建一个SparkClient,SparkClient会启动RemoteDriver进程,并由RemoteDriver创建SparkContext。SparkTask执行时,通过Session提交任务,任务的主体就是对应的SparkWork。SparkClient将任务提交给RemoteDriver,并返回一个SparkJobRef,通过该SparkJobRef,客户端可以监控任务执行进度,进行错误处理,以及采集统计信息等。由于最终的RDD计算没有返回结果,因此客户端只需要监控执行进度而不需要处理返回值。RemoteDriver通过SparkListener收集任务级别的统计数据,通过Accumulator收集Operator级别的统计数据(Accumulator被包装为SparkCounter),并在任务结束时返回给SparkClient。
SparkClient与RemoteDriver之间通过基于Netty的RPC进行通信。除了提交任务,SparkClient还提供了诸如添加Jar包、获取集群信息等接口。如果客户端需要使用更一般的SparkContext的功能,可以自定义一个任务并通过SparkClient发送到RemoteDriver上执行。
理论上来说,Hive on Spark对于Spark集群的部署方式没有特别的要求,除了local以外,RemoteDriver可以连接到任意的Spark集群来执行任务。在我们的测试中,Hive on Spark在Standalone和Spark on YARN的集群上都能正常工作(需要动态添加Jar包的查询在yarn-cluster模式下还不能运行,请参考HIVE-9425)。
优化
我们再来看几个针对Hive on Spark的优化。
Map Join
Map Join是Hive中一个很重要的优化,其原理是,如果参与Join的较小的表可以放入内存,就为这些小表在内存中生成Hash Table,这样较大的表只需要通过一个MapWork被扫描一次,然后与内存中的Hash Table进行Join就可以了,省去了Shuffle和ReduceWork的开销。在MapReduce模式下,通过一个在客户端本地执行的任务来为小表生成Hash Table,并保存在本地文件系统上。后续的MapWork首先将Hash Table上传至HDFS的Distributed Cache中,然后只要读取大表和Distributed Cache中的数据进行Join就可以了。
Hive on Spark对于Map Join的实现与MapReduce不同。最初我们考虑使用Spark提供的广播功能来把小表的Hash Table分发到各个计算节点上。使用广播的优点是Spark采用了高效的广播算法,其性能应该优于使用Distributed Cache。而使用广播的缺点是会为Driver和计算节点带来很大的内存开销。为了使用广播,Hash Table的数据需要先被传送到Driver端,然后由Driver进行广播;而且即使在广播之后,Driver仍需要保留这部分数据,以便应对计算节点的错误。虽然支持Spill,但广播数据仍会加剧Driver的内存压力。此外,使用广播相对的开发成本也较高,不利于对已有代码的复用。
因此,Hive on Spark选择了类似于Distributed Cache的方式来实现Map Join(请参考HIVE-7613),而且为小表生成Hash Table的任务可以分布式的执行,进一步减轻客户端的压力。下图描述了Hive on Spark如何生成Map Join的任务。
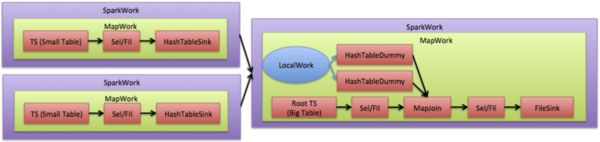
图4:Hive on Spark Join优化
不同于MapReduce,对于Hive on Spark而言,LocalWork只是为了提供一些优化时的必要信息,并不会真正被执行。对于小表的扫描以独立的SparkTask分布式地执行,为此,我们也实现了能够分布式运行的HashTableSinkOperator(Hive中输出小表Hash Table的操作符),其主要原理是通过提高HDFS Replication Factor的方式,使得生成的HashTable能够被每个节点在本地访问。
虽然目前采取了类似Distributed Cache的这种实现方式,但如果在后期的测试中发现广播的方式确实能够带来较大的性能提升,而且其引入的内存开销可以被接受,我们也会考虑改用广播来实现Map Join。
Table Cache
Spark的一个优势就是可以充分利用内存,允许用户显式地把一个RDD保存到内存或者磁盘上,以便于在多次访问时提高性能。另外,在目前的RDD转换模式中,一个RDD的数据是无法同时被多个下游使用的(请参考SPARK-2688),当一个RDD需要通过不同的转换得到不同的子节点时,就要被计算多次。这时,我们也应该使用Cache来避免重复计算。
在Shark和SparkSQL中,都允许用户显式地把一张表Cache来提高对该表的查询性能;对于Hive on Spark,我们也应该充分利用这一特性。
一个应用场景是Multi Insert查询,即同一个数据源经过运算后需要被插入到多个表中的情况。比如以下查询。

在这种情况下,对应的SparkWork中,一个MapWork/ReduceWork会有多个下游的Work,如果不进行Cache,那么共享的数据源就会被计算多次。为了避免这种情况,我们会将这些MapWork/ReduceWork复制成多个,每个对应一个下游的Work(请参考HIVE-8118),并对其共享的数据源进行Cache(由于IOContext的同步问题,该功能尚未完成,预计会在HIVE-9492中实现)。
更为一般的应用场景是一张表在查询中被使用了多次的情况,Hive on Spark目前还不会针对这种查询进行Cache,不过在后续的工作中会考虑采用自动的或者用户指定的方式来优化这种查询。
项目进度与计划
Hive on Spark最初在Hive的Git仓库中的spark分支下开发,到2014年12月底,已经完成功能开发,Hive已有的各种查询基本都能支持。2015年1月初spark分支被合并回trunk,预计会在下一个版本中发布(具体版本号待定)。
对于已经搭建好Hadoop和Spark集群的用户,使用Hive on Spark是比较容易的,主要是引入Spark依赖和进行恰当的配置即可,具体步骤可以参考Hive on Spark Getting Started Wiki(https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started)。此外,Cloudera和Intel还在更早的时候提供了亚马逊AWS虚拟机镜像,以方便感兴趣的用户更加快捷的体验Hive on Spark(请参考Hands-on Hive-on-Spark in the AWS Cloud,http://blog.cloudera.com/blog/2014/12/hands-on-hive-on-spark-in-the-aws-cloud/)。
项目的下一阶段工作重点主要在于Bug修复、性能优化,以及搭建基于YARN的Mini Cluster进行单元测试(请参考HIVE-9211)等。为了保证效率,开发工作仍将在spark分支上进行,希望了解项目最新进展的用户可以关注该分支。
初步性能测试
随着项目开发接近尾声,我们也已经开始对Hive on Spark进行初步的性能测试。测试集群由10台亚马逊AWS虚拟机组成,Hadoop集群由HDP 2.2搭建,测试数据为320GB的TPC-DS数据集。目前的测试用例有6条,包含了自定义的查询以及TPC-DS中的两条查询。由于Hive主要用于处理ETL查询,因此我们在TPC-DS中选取用例时,选取的是较为接近ETL查询的用例(TPC-DS中的用例主要针对交互型查询,Impala、SparkSQL等引擎更适合此类查询)。为了更有针对性,测试主要是对Hive on Spark和Hive on Tez进行性能对比,最新的一组测试数据如下图所示(鉴于项目仍在开发中,该数据仅供参考)。
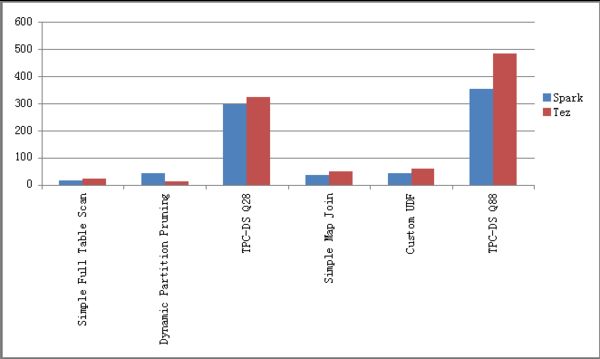
图5:Hive on Spark vs. Hive on Tez
图中横坐标为各个测试用例,纵坐标为所用时间,以秒为单位。
总结
Hive on Spark由多家公司协作开发,从项目开始以来,受到了社区的广泛关注,HIVE-7292更是有超过140位用户订阅,已经成为Hive社区中关注度最高的项目之一。由于涉及到两个开源项目,Hive社区和Spark社区的开发人员也进行了紧密的合作。在开发过程中发现的Spark的不足之处以及新的需求得到了积极的响应(请参考SPARK-3145)。通过将Spark作为Hive的引擎,现有的用户拥有了更加灵活的选择。Hive与Spark两个社区均将从中受益。
本文阐述了Hive on Spark的总体设计思想,并详细介绍了几个重要的实现细节。最后总结了项目进展情况,以及最新的性能数据。希望通过本文能为用户更好的理解和使用Hive on Spark带来帮助。