基于taobao的验证码识别
验证码介绍
现在的验证码主要分为4类:识图验证码、计算验证码、滑块验证码、语音验证码。本文只针对taobao的识图验证码进行识别。目标验证码如下:

可以看到这类验证码都是变形、粘连、大小不一、位置不固定的,不再像以前的可分割的验证码了,也就增加了机器识别的难度。这类粘连验证码就是本文主要的研究对象。
识别步骤
(1)图片预处理
灰度化、 二值化、去噪声(本文验证码无噪声,没有此步骤)等
(2)字符切割
CFS连通域分割、滴水法
(3)分类模型训练
支持向量机或神经网络。本文训练的是卷积神经网络
图片预处理
图片预处理之后的效果:

(1)灰度化
彩色图片的像素点是由R、G、B三个原色组成,其值在0-255之间,有三个通道。灰度图是指只含有亮度信息,不含彩色信息的图像,即只有一个通道。灰度化就是将彩色图像转为灰度图像的过程。本文采用的灰度化方法是加权平均法。
def rgb2gray(img): # 求灰度值
return np.dot(img[...,:3], [0.299, 0.587, 0.114])(2)二值化
二值化是指将灰度图像转换成只有黑白两色的图像,通常做法是选择一个阈值,如果灰度图像上的像素大于该阈值则为白色,否则为黑色。
def binary(gray):# 二值化
height,width=gray.shape
bin = gray.copy()
for i in range(height):
for j in range(width):
if (gray[i,j]<=130):
bin[i,j]=0
else:
bin[i,j]=1
return bin字符切割
由于粘连的字符不好识别,所以我们将粘连的字符切割为单个字符,再训练模型进行识别。
(1)竖直投影法
竖直投影法是最简单的字符分割方法,根据相邻的波谷或者极大极小值来确定字符边界,常用于字符没有粘连的情况,如车牌识别。但是由于目标验证码倾斜程度不小并且大多粘连,对于倾斜严重但实际并未粘连的两个字符,竖直投影的效果不太好,因此未采用这种方法。
(2)CFS连通域分割法
假定每个字符由单独的一个连通域组成,因此只需要将不同连通域加以标记,就可分割出字符。此方法要求字符不粘连,无论旋转或扭曲。找到一个黑色像素并开始判断,直到所有相连的黑色像素都被遍历标记过后即可判断出字符的分割位置。
其算法原理:
1.对二值化之后的图像,从左往右,从上往下扫描图片,遇到黑点,并且该点没有被访问,则将该点压栈,并标记为已经访问。
2.如果栈不空,则继续探测周围4个点(四邻域,也可选择八邻域),并执行步骤1;如果栈空,则代表已经探测完一个字符块,并将该字符块的最左最右、最上最下坐标保存(本文只保存左右)。
3.探测结束,最后通过每个字符的坐标进行切割。
代码(复制别人的:https://www.cnblogs.com/qqandfqr/p/7866650.html):
# ---------------------------------------CFS连通域------------------------------------------
import queue
def cfs(im,x_fd,y_fd): # 用队列和集合记录遍历过的像素坐标代替单纯递归以解决cfs访问过深问题
xaxis=[]
yaxis=[]
visited =set()
q = queue.Queue()
q.put((x_fd, y_fd))
visited.add((x_fd, y_fd))
offsets=[(1, 0), (0, 1), (-1, 0), (0, -1)]#四邻域
while not q.empty():
x,y=q.get()
for xoffset,yoffset in offsets:
x_neighbor,y_neighbor = x+xoffset,y+yoffset
if (x_neighbor,y_neighbor) in (visited):
continue # 已经访问过了
visited.add((x_neighbor, y_neighbor))
try:
if im[x_neighbor, y_neighbor] == 0:
xaxis.append(x_neighbor)
yaxis.append(y_neighbor)
q.put((x_neighbor,y_neighbor))
except IndexError:
pass
# print(xaxis)
if (len(xaxis) == 0 | len(yaxis) == 0):
xmax = x_fd + 1
xmin = x_fd
ymax = y_fd + 1
ymin = y_fd
else:
xmax = max(xaxis)
xmin = min(xaxis)
ymax = max(yaxis)
ymin = min(yaxis)
#ymin,ymax=sort(yaxis)
return ymax,ymin,xmax,xmin
def detectFgPix(im,xmax): # 搜索区块起点
h,w = im.shape[:2]
for y_fd in range(xmax+1,w):
for x_fd in range(h):
if im[x_fd,y_fd] == 0:
return x_fd,y_fd
def CFS(im): # 切割字符位置
zoneL=[]#各区块长度L列表
zoneWB=[]#各区块的X轴[起始,终点]列表
zoneHB=[]#各区块的Y轴[起始,终点]列表
xmax=0#上一区块结束黑点横坐标,这里是初始化
for i in range(10): #几个字符,最终运行几次
try:
x_fd,y_fd = detectFgPix(im,xmax)
# print(y_fd,x_fd)
xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd)
L = xmax - xmin
H = ymax - ymin
zoneL.append(L)
zoneWB.append([xmin,xmax])
zoneHB.append([ymin,ymax])
except TypeError:
return zoneL,zoneWB,zoneHB
return zoneL,zoneWB,zoneHB
def cutting_img(im,im_position,xoffset = 1,yoffset = 1):
cut = []
# filename = './out_img/' + img.split('.')[0]
# 识别出的字符个数
im_number = len(im_position[1])
# 切割字符
for i in range(im_number):
im_start_X = im_position[1][i][0]
im_end_X = im_position[1][i][1]
# im_start_Y = im_position[2][i][0]
# im_end_Y = im_position[2][i][1]
# 判断一下
# if im_start_X > 0 : # 非边界
# im_start_X = im_start_X - xoffset
# if im_end_X < im.shape[1]: # 非边界
# im_end_X = im_end_X + xoffset
# if im_start_Y > 0: # 非边界
# im_start_Y = im_start_Y -yoffset
# if im_end_Y < im.shape[0]: # 非边界
# im_end_Y = im_end_Y + yoffset
cropped = im[0:im.shape[0]+1, im_start_X:im_end_X]
# cv2.imwrite(filename + '-cutting-' + str(i) + '.jpg',cropped)
cut.append(cropped)
return cut(3)滴水算法
滴水算法主要是模仿水滴从高处向低处落的过程来对粘连字符进行切割。水滴从字符串顶部在重力的作用下,只能沿字符轮廓向下滴落或水平滚动(周围5个点,具有优先级)。最终水滴所经过的轨迹就构成了字符的切割路径。
滴水法决定因素主要包括:起始点、移动规则以及方向的确定。原理自行百度。
代码(复制别人的,参考链接https://www.jianshu.com/p/deee3e7e463b,好像原作者已经删除):
# --------------------------------------------------滴水法--------------------------------------------------------------
def binImgHist(img, bin_width=1, direction=1): # 二值化图像在y轴或者x轴方向的投影统计
height, width = img.shape
bins = None
if direction == 0:# 在y轴方向上统计
bins = int(height / bin_width)
else:
bins = int(width / bin_width)
# 获取非零元素坐标
nonzero_points = np.nonzero(img != 0)
# 获取非零元素坐标中的x坐标集合或者y坐标集合
nonzero_idx_x = nonzero_points[direction]
# 返回的统计直方图
hist = np.histogram(np.int64(nonzero_idx_x), bins=bins)[0]
return hist
COLOR_BACK = 1 # 背景颜色
COLOR_PEN = 0 # 笔触的颜色
# 首先将原来的图片转换成布尔矩阵
# bool_img = gray == COLOR_PEN
# print(bool_img[15:25,15:25])
# 定义邻居坐标 的位置关系
# NEIGHBOR_IDX = {1: (-1, 0), 2: (-1, 1), 3: (0, 1), 4: (1, 1), 5: (1, 0)}
# 根据不同优先级情况,对应的下一个点的位置 n_i
# CASE_NEXT_POINT = {1: 3, 2: 2, 3: 3, 4: 4, 5: 5, 6: 1}
def is_case_p1(n1, n2, n3, n4, n5):
'''
优先级 :1
下落方向: 正下方
下落位置: n3
备注: 全为背景或者全为笔迹
'''
if n1 and n2 and n3 and n4 and n5 == True:
# 全为数字部分
return True
elif not (n1) and not (n2) and not (n3) and not (n4) and not (n5) == True:
# 全为背景部分
return True
return False
def is_case_p2(n1, n2, n3, n4, n5):
'''
优先级 :2
下落方向: 左下方
下落位置: n2
备注: n2点为背景,且其他点至少有一个为笔迹的颜色
'''
return not (n2) and (n1 or n3 or n4 or n5)
def is_case_p3(n1, n2, n3, n4, n5):
'''
优先级 :3
下落方向: 正下方
下落位置: n3
备注: 左下角为笔迹的颜色,正下方为背景色
'''
return n2 and not (n3)
def is_case_p4(n1, n2, n3, n4, n5):
'''
优先级 :4
下落方向:右下方
下落位置: n4
备注: 左下角跟正下方为笔迹的颜色,右下方为背景色
'''
return n2 and n3 and not (n4)
def is_case_p5(n1, n2, n3, n4, n5):
'''
优先级 :5
下落方向:右边
下落位置: n5
备注:下方全为笔迹颜色,且左边为背景色
'''
return n2 and n3 and n4 and not (n5)
def is_case_p6(n1, n2, n3, n4, n5):
'''
优先级 6
下落方向:左边
下落点:n1
备注 除了左边是背景色,其他均为笔迹颜色
'''
return not (n1) and n2 and n3 and n4 and n5
def drop_fall(neighbors,CASE_NEXT_POINT = {1: 3, 2: 2, 3: 3, 4: 4, 5: 5, 6: 1}):
'''
传统滴水算法 核心代码
根据优先级实现
neighbors = [n1, n2, n3, n4, n5]
返回 :下落点的邻居编号
'''
for priority in range(1, 7):
if eval('is_case_p{}(*neighbors)'.format(priority)):
return CASE_NEXT_POINT[priority]
def is_legal_pt(img, x, y):
'''
是否为合法的坐标
判断是否超出正常的数值范围
'''
h, w = img.shape
if x < 0 or y < 0 or x >= w or y >= h:
return False
return True
def get_neighbors(bool_img, x, y,NEIGHBOR_IDX = {1: (-1, 0), 2: (-1, 1), 3: (0, 1), 4: (1, 1), 5: (1, 0)}):
'''
给定逻辑图跟坐标, 返回邻居的有序布尔数组
'''
neighbors = []
for n_idx in range(1, 6):
dx, dy = NEIGHBOR_IDX[n_idx]
new_x, new_y = x + dx, y + dy
if not is_legal_pt(bool_img, new_x, new_y):
# 如果坐标不合法 填充背景
neighbors.append(False)
else:
neighbors.append(bool_img[new_y][new_x])
# print(neighbors)
return neighbors
def get_split_path(bool_img,start_x,height,width,NEIGHBOR_IDX = {1: (-1, 0), 2: (-1, 1), 3: (0, 1), 4: (1, 1), 5: (1, 0)}): # 给出分割路径
min_x = 0 # x坐标的左边界
max_x = width - 1 # x坐标的右边界
max_y = height - 1
# 当前的点
cur_pt = (start_x, 0)
# 最近的点
last_pt = cur_pt
# 分割路径
split_path = [cur_pt]
while cur_pt[1] < max_y:
neighbors = get_neighbors(bool_img, cur_pt[0], cur_pt[1])
n_idx = drop_fall(neighbors)
dx, dy = NEIGHBOR_IDX[n_idx]
next_pt = None
next_x, next_y = cur_pt[0] + dx, cur_pt[1] + dy
if not is_legal_pt(bool_img, next_x, next_y):
# x/y越界 向下渗透
next_pt = (cur_pt[0], cur_pt[1] + 1)
else:
next_pt = (next_x, next_y)
# 判断点是否重复出现,左右往复平移
if next_pt in split_path:
# 已经判断重复,进行渗透
next_pt = (cur_pt[0], cur_pt[1] + 1)
cur_pt = next_pt
split_path.append(cur_pt)
return split_path切割后效果:

分类模型
将验证码切割好,手动打标10000张单个验证码字符,再利用keras训练一个类似于mnist例子的卷积模型。在测试集(400张验证码,260张有粘连)上测试,单个验证码字符准确率有0.88,整体验证码准确率有0.68,结果还算勉强。实践证明,这类验证码有粗有细、倾斜粘连,不像mnist那么规范,样本量还是太少,泛性不高,但是人工打标又太费时间。
数字验证码
对于taobao的6位数字验证码也进行了尝试,目标验证码及切割效果如下:
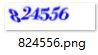
切割过程及效果如下图:

taobao这种验证码很坑的地方在于,第一个字符或最后一个字符只出现部分,甚至偶尔只有5位字符,如下图:

参考链接:
https://www.cnblogs.com/qqandfqr/p/7866650.html
https://www.jianshu.com/p/deee3e7e463b