目标检测新方法:CornerNet详解
为了提升速度与精度,时下目标检测领域出现了Anchor
Free的方法,不再依靠先验框的设定进行平铺式分类或者回归,而是选用关键点与深度学习相结合的方式,往往还会使用Attention的机制,比较流行的有CenterNet,CornerNet,当然还有一些最新的,比如:RepPoints等等,总之这方面真的太火了。。
原文:https://arxiv.org/abs/1808.01244
源码:https://github.com/umich-vl/CornerNet
CornerNet: Detecting Objects as Paired Keypoints (ECCV2018)
Hei Law, Jia Deng
University of Michigan, Ann Arbor
目录
1 Motivation
2 Contribution
3 Framework
3.1 overview
3.2 Backbone: Hourglass Network
3.3 prediction modules
3.4 Corner pooling
4 Train
4.1 Loss function
4.2 Training details
5 Test
6 性能对比
7总结
1 Motivation
在state-of-the-art的目标检测算法中,都用到了设置anchor-box的方法。anchor-box的使用使得one-stage的算法性能能够挑战two-stage。但是使用anchor-box会有两个缺点:
1) anchor-box的数量需要设置很多 (DSSD: more than40k, RetinaNet: more than 100k) 。其中只有一小部分和ground truth重合,生成了大量的负例,造成正负样本不平衡,降低了训练效率。
2) anchor-box的使用引入了很多超参数,如anchor的数量,大小,长宽比。增加了算法的设计难度。
本文提出一种新的检测方法,使用一对关键点:框的左上角和右下角来代替bounding box。
2 Contribution
1.用一对corner代替了anchor box,并提出了一种新的one-stage检测方法。
2. 提出了一种新的池化方法:corner pooling。
3 Framework
3.1 overview
 图1 overview of CornerNet
图1 overview of CornerNet
CornerNet是一种one-stage检测方法,其框架如图1所示。主干网采用了Hourglass Network。主干网后紧跟两个prediction modules,其中一个检测top-left corners ,另一个检测bottom-right corners,最后对两组corner进行筛选,组合,修正得到object的一对corners,从而定位object的box。
 图2 Heatmaps和Embeddings
图2 Heatmaps和Embeddings
Heatmaps和Embeddings都是prediction modules最后生成出来的特征图,top-left corners 和bottom-right corners各有一组。Heatmaps预测哪些点最有可能是Corners点,Embeddings用于表征属于相同对象的corner的相似度。它们的通道数都为C,C是object的类别数 (不包括background) 。最后的Offsets用于对corner的位置进行修正。每个corner修正前的坐标位置就是该corner在feature maps上的坐标点映射回原图的位置。
从图2中我们可以看出,绿框中两个corner对应位置的Embedding的features分布相似度高,所以代表这对corner属于同一个object,黄框同理。
3.2 Backbone: Hourglass Network
Hourglass Network出自论文:Stacked Hourglass Networks for Human Pose Estimation。这里不再阐述具体结构,原作者也只用了很小的篇幅描述这部分内容。
 图3 Hourglass Network结构
图3 Hourglass Network结构
一个Hourglass Network由若干个Hourglass组成,Hourglass的具体结构如图4。
 图4 A single Hourglass
图4 A single Hourglass
Hourglass先由卷积和池化将feature maps下采样到一个很小的尺度,之后再用nearest neighbor upsampling的方法进行上采样,将feature maps还原到最开始的尺度。不难看出,下采样和上采样是对称的,并且在每个upsampling层都有一个skip connection,skip connection上是一个residual modules。
使用这种沙漏结构的目的是为了反复获取不同尺度下图片所包含的信息。例如一些局部信息,包括脸部和手部信息。人体姿态估计也需要对整个人体做一个理解,也就是一些全局信息,包括人体的方位,肢体的动作以及相邻关节点的关系。最后通过上采样和残差结构将局部信息和全局信息组合起来。
CornerNet采用了2个Hourglass组成的Hourglass Network,作者在使用Hourglass时做了一些小调整,包括:
1) Hourglass在下采样时不再进行max-pooling,而是在卷积时通过stride=2进行下采样。下采样的卷积进行5次,输出feature maps的通道数分别为(256, 384, 384, 384, 512)
2) 在每个skip connection,有两个residual modules。
3) 图片进入Hourglass前,进行了2次下采样。使用一个kernel size=7*7,stride=2,channel=128的卷积和一个stride=2,channel=256的residual block,将width和height缩小为以前的1/4。
3.3 prediction modules
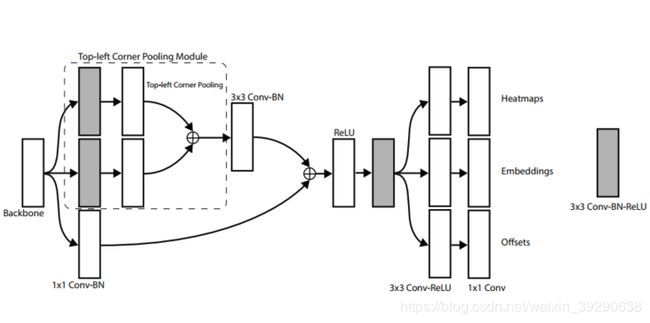 图5 prediction modules (Top-left)
图5 prediction modules (Top-left)
Top-left和bottom-right的prediction modules结构相同,我们以Top-left为例,如图5所示。Prediction modules的前半部分类似残差结构。Backbone中的feature maps进入prediction modules后分成三条支路:上面两条支路经过3*3的卷积后,进行corner pooling,相加汇集成1路,随后再进行3x3的卷积和batch normalization;最下面的支路进行1*1的卷积和batch normalization 后,与上路相加后送入到Relu函数中。随后,再对feature maps进行3*3的卷积,接着分三路3*3的卷积+Relu后产生了Heatmaps, Embeddings, Offsets三组feature maps。(在最后一层,原作者给的图和其文字描述不一致)
3.4 Corner pooling
 图6 corner pooling (Top-left)
图6 corner pooling (Top-left)
Corner pooling是作者在CornerNet中提出的一种新的池化方式,用在prediction modules中。如果读者们仔细思考这种池化方式,会发现Corner pooling设计得十分精妙。
池化方法如图6所示(以Top-left为例,Bottom-right与其方向相反)。对于第1组feature maps,对每行feature scores按从右向左的顺序选择已滑动过范围的最大值,对于第2组feature maps,对每列feature scores按从下向上的顺序选择已滑动过范围的最大值。
那么,作者提出corner pooling的动机是什么呢?其实为了更好地适应corner的检测。在目标检测的任务中,object的corner往往在object之外,所以corner的检测不能根据局部的特征,而是应该对该点所在行的所有特征与列的所有特征进行扫描。
举个例子,如果我们能在某行和某列检测到同一个object的边界特征,那么这行和这列的交点就是corner,这是一种间接且有效的找corner的方法。
还有一点值得注意的是,池化时不能直接对整行或整列进行max pooling,当一张图上有多个目标时,这样会导致误检。
4 Train
4.1 Loss function
对于Heatmaps, Embeddings, Offsets三组feature maps,都各自用于一种loss计算。
Heatmaps: detecting corners
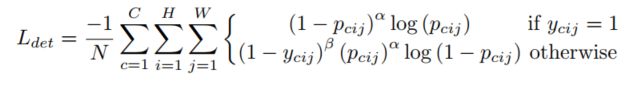
该loss是Focal loss的变体,其中,pcij代表类别C的predicted corner在位置 (i, j) 处的得分,得分越高就越可能是corner。ycij表示ground truth的Heatmaps,由Gaussian公式![]() 算出,中心点是ground truth的位置,σ=1/3,是一个超参数。(1-ycij)可以理解predicted corner到gt corner的距离,只是这个距离被Gaussian非线性化了,使得负样本的惩罚减少了。
算出,中心点是ground truth的位置,σ=1/3,是一个超参数。(1-ycij)可以理解predicted corner到gt corner的距离,只是这个距离被Gaussian非线性化了,使得负样本的惩罚减少了。
Embeddings: grouping corners
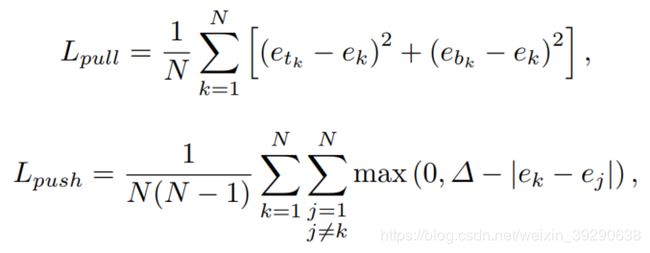
其中,etk是object左上角的embedding得分,ebk是object右下角的embedding得分,ek代表etk和ebk的均值。N代表gt中的object数量。
Pull loss越小,则同一object的左上角和右下角的embedding得分距离越小;Push loss越小,则不同object的左上角和右下角的embedding得分距离越大。
Offsets: correcting corners’ position


![]() 代表Offsets的predicted offset;Ok代表gt的offset;N代表gt中的object数量。
代表Offsets的predicted offset;Ok代表gt的offset;N代表gt中的object数量。
我们得到total loss:

其中,α, β, γ是超参数,分别取0.1, 0.1, 1。
4.2 Training details
1) 随机初始化的,没有在任何外部数据集上进行预训练。
2) 遵循Focal loss for dense object detection中的方法设置预测Heatmaps的卷积层的biases。
3) 网络的输入分辨率是511×511, 输出分辨率为128×128。
4) 为了减少过拟合,我们采用了标准的data augmentation,包括随机水平翻转、随机缩放、随机裁剪和随机色彩抖动,其中包括调整图像的亮度,饱和度和对比度。
5) 使用PCA分析图像数据。
6) 使用Adam优化训练损失
5 Test
测试时,使用simple post-processing算法从Heatmaps, Embeddings, Offsets生成边界框。首先在heatmaps上使用3*3的max pooling进行非极大值抑制(NMS)。然后从Heatmaps中选择scores前100的top-left corners和前100的bottom-right corners,corner的位置由Offsets上相应的scores调整。 最后,计算top-left corners和bottom-right corners所对应的Embeddings的L1距离。距离大于0.5或包含不同类别的corners pairs将被剔除。配对上的top-left corners和bottom-right corners以Heatmaps的平均得分用作检测分数。
作者没有使用resize的方法保持输入图像的原始分辨率一致,而是维持原分辨率,用0填充缺失和超出的部分。 原始图像和翻转图像都参与测试,并应用soft-nms来抑制冗余检测。 仅记录前100个检测项。 Titan X(PASCAL)GPU上的每个图像的平均检测时间为244ms。使用检测速度top100的测试图片,计算出CornerNet在TitanX(PASCAL)GPU上的平均推断时间为每张图片224ms。
6 性能对比

7 总结
这篇文章提出了一种全新的one-stage目标检测算法,让人耳目一新。不过虽说是one-stage算法,其速度还是比较慢的。文章里面还有好多细节可以抠,比如说Heatmaps, Embeddings, Offsets的输出按理都应该是0~1之间的一个数,可是作者在这里并没有阐明是怎么处理的,只有撸完代码再回过头来看了。