以下是对三个框架在设计或者说是编码特点中选取的几个我比较关注的点的对比图:
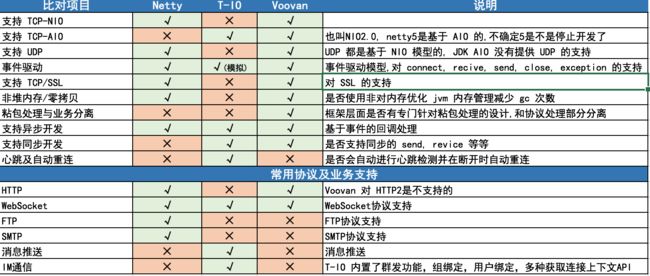
首先我们对几个关键的概念进行一些解析,方便大家更好的理解上面表中的概念:
- NIO、AIO 的区别?
在这里我们来看一下两者最明显的区别,NIO 是由 JDK 来处理异步事件的,就是说由 JDK 来探测系统缓冲区及Socket 的连接状态并通知用户事件被触发,最明显的就是编写 NIO 的时候我们需要对 Selector 进行处理,然后自己对事件进行处理,那么这个时候如果不使用线程来处理的话,就是一个同步的通信模型。而 AIO 这是由 JDK 所在的操作系统通知 JDK 事件被触发,这是基于 Linux 的 Epoll 或者 window 的 Iocp 来完成,且事件在被触发时就是在一个独立的线程中处理的。 理论上 AIO 的性能更好,如果传言是真的不知道为什么 Netty 的作者停止了对 Netty5 AIO 版本的维护。
- 事件驱动
大家都知道异步程序的编写必然伴随着不断的回调,而事件驱动就是将这些回调分类整理统一成不同的事件并出发,暴露给使用者,举个简单的例子,断开连接这个事件,广义的讲有两种情况:服务端主动断开,客户端主动断开,但是对于使用者来说都是断开,都需要出发 close 这个事件,所以框架就需要对这两种事件进行统一,在被触发时给用户一个 close,或者说调用用户的 close 回调。
模拟事件驱动就是框架中没有建立事件处理模型,在整个框架的编码过程中在代码的不同位置统一事件的处理。
- TCP/SSL
首先说明一下只有 TCP 协议才能支持 SSL 通信。而 SSL 通信是通过使用非对称的密钥保证通信的内容不会被中间人进行攻击,因此现在众多的支付功能都采用 SSL 通信的形式,而不是很多朋友理解的加密,因为密钥是公开,所以服务端返回给客户端的信息是完全可以被解密。
- 非堆内存及零拷贝
1. 非堆内存: 首先JVM在管理对象的时候可以使用的有堆内存和非堆内存,堆内存由 JVM 自动管理,大家常见到的 OutOfMemroy 则由于堆内存被完全占用而导致,那么非堆内存不是 JVM 自动管理的,所以理论上可以申请到目前物理内存的最大值,而为什么要使用非对内存呢? 答案是应为 GC, 在高并发的情况下堆内存被不断被申请,当达到 GC 条件时 JVM 会停止响应进行无关联对象的回收,而使用非对内存的时候,由于对象的申请和释放都由开发人员手工实现并完成,所以在临时的某个对象或者缓冲区使用完后就可以进行针对性的释放,同时不占用堆内存,从而减少 GC 的次数,总提上减少 JVM 因 GC 导致的停顿。当然这对开发者也提出了更高的要求。因此理论上使用非堆内存都可以做到并发时的极低的内存消耗。
2. 零拷贝:首先零拷贝的作用也是在于减少JVM堆内存消耗,主要目的是在从缓冲区接收到数据后对数据的解析或处理后在到达开发者提供的回调函数之前不对其进行 copy 操作 或者 降低 copy 操作,那么什么是 copy 操作呢,比如: HeapByteBuffer.get(byte[]) 方法会对数据进行一次拷贝(使用的是System.arraycopy),而DirectByteBuffer虽然分配的是非堆内存单在做 get 方法时也会将数据 copy 到堆内存中,而这种操作在大多数开发者中是会被频繁使用,所以不知道是哪位大神(具我的了解应当的 Netty 的开发者)提出了零拷贝,拯救了我们。
- 粘包处理与业务分离
这个可能就是在框架设计时如何给用户提供更好的体验的问题了(当然并不会取得每个人的欢心,有人爱有人恨,世间万物除了 money 皆是如此),目的是在于能够统一的封装粘包处理代码达到清晰且模块化复用的目的,就我个人而言,我非常厌恶将粘包处理代码编写到解包过滤器或者解码器,这样会导致我在开发新的系统或者某些功能是需要复制并不断的粘贴代码或者某个类,所以 voovan 提出了粘包处理与业务分离的方式,将粘包处理部分的代码作为一个独立的可插入的功能提供给开发者,当然如果用户喜欢在协议解析部分处理,只要在构造服务的时候不要注册粘包处理类,就可以在协议解析的部分自己处理了。
2017-07-01: 关于Netty粘包处理大家有疑问,我在这里补充说明一下 Voovan 的粘包处理的不同:
Voovan 的粘包处理是个独立的一个实现,和解包处理是分开的,这也就是我们在进行解包处理的时候不用考虑包是否完整,同时也方便丢弃那一部分非法的探测包(不需要读取再丢弃,仅仅操作一下指针即可:直接在canSplite方法中清空并重置bytebuffer就可以做到,无须内存操作)从而提升安全性. Voovan 在包不完整的时候会尝试等待一个完整的包。至于为什么拆分粘包处理为一个独立的逻辑? 个人认为判断包是否完整是一套独立的逻辑,可以写的很简单,独立出来对于相当多的一部分把解包处理和粘包处理用一套逻辑来处理的开发者而言,独立的粘包可以提示他们写一个很简单的逻辑来处理粘包,从而有效的提高判断完整报文运行效率。Voovan也提供透传(默认粘包处理器,即不设置粘包处理), 方便开发者保留自己的习惯在解包时处理粘包。当然最终这一切都取决开发者的选择。最后,并不是说 Netty 不支持粘包处理,粘包处理是无论什么语言所有涉及导到Socket 通信都必须要解决的问题,Netty 是否支持粘包处理,仅仅凭借常识推断就可以知道一定是有的。
- 异步开发与同步开发
异步开发与同步开发的本质区别在编码上就是是否使用回调,异步开发需要开发者注册回调的函数,供框架在需要时调用,不会对当前线程产生阻塞,没有阻塞也就意味着Socket 通信的缓冲区中的内容不会因为阻塞而长时间的等待造成并发性能的下降。同步开发则是用户调用 send 或者 recive 时线程是阻塞的必须等到有合规的内容时才会继续接收缓冲区内未处理的数据。
那么是否是异步就会一定比同步好呢?答案是否定的,异步虽然性能高,但也同时加大了编码和调试的难度,所以我个人推荐仅在提供Socket服务的时候使用,因为我们无法预测并发情况,所以还是做万全的准备比较好。那么同步使用在作为Socket客户端时就有了他得天独后的优势,方便开发且方便调试。
- 心跳及重连
关于心跳及重连相信我就不做过多的描述了,简单介绍一下:
心跳:Socket服务端和客户端之间定时发送和应答的内容,用于判断连接是否断开以便通知开发者进行响应的处理。
重连:主要是指在Socket客户端通过心跳或者 Socket 事件发现连接被断开后自动的重新发起到服务端的连接。
- 什么是 TCP 长连接和短连接?
个人认为长连接和短连接没有实际本质的区别只是开发者使用场景的不同。
TCP长连接: 长连接就是一个持续不断的 TCP 连接 , 主要作用是在一次 connet 后,不断的进行无数组业务单元的信息传递,直到关闭,长连接长时间不断开最少会霸占一个线程进行事件监听,所以过多的客户端容易降低性能。典型场景: 部分IM通信软件,以及数据同步系统。
TCP短连接:短连接就是在和服务端通信的过程中是一次connect 交互完一组业务单元后连接关闭,下次交互的过程中再建立连接。短连接虽然不会长期霸占一个线程用作监听,但他每次的连接和断开会消耗一定 IO 资源,但好在Socket 通信往往不像磁盘或者内存 IO 操作需要纳秒级的响应。
就我个人的理解 HTTP1.0、HTTP1.1、HTTP2、网游服务端都是短连接的形式,一组相关的业务单元传输完毕后,等待超时后,就会主动关闭连接。一般 web 服务器的 keepalive 的超时时间都不会设置的太长,而且会根据当前线程的情况自动调整,线程越多超时时间越短,线程越少超时时间越长。
关于性能测试:
并发性能的概念
QPS(query per second)平均每秒请求数, 如每秒处理请求 10k 。
BPS (bytes per second)平均每秒传输字节数, 如每秒传输80mb 。
首先要说的是 QPS,这个是对异步通信框架线程和竞争锁的管理,线程和竞争锁管理的不好会数出现锁阻塞导致系统停止响应,测试 QPS 会导致不断的接受连接,申请线程,处理业务,关闭连接,释放线程等操作。调大线程池有助提高 QPS 的测试结果。
个人对异步框架的测试QPS时的理解是连接->发送->响应->关闭为一个 QPS.因为这样才能相对准确的测试出其基线性能.
例如:voovan 在 [连接->发送->响应->关闭 为 1 个QPS] 的测试情况下是10000+ 的QPS.
而增加 keepalive 方式后 voovan 在 [连接->发送->响应->发送->响应->关闭 为 2 个QPS] 的测试情况下是18000+ 的QPS.
可见不同的QPS 的定义对测试结果有相当大的影响.
BPS 测试最大吞吐量是对内存和 IO 性能管理的考验,管理的不好的话就会出现频繁的 GC 停顿直到系统无响应或者 OutOfMemroy,测试BPS会不断在发送过程中充满整个Socket 缓冲区,充分启用网卡的能力发送数据。如果是从文件读数据,还要考虑你的磁盘性能。调大缓冲区设置有助于提高 BPS 的测试结果。
QPS 实测得到的结果可能更适用于多数场景,因为无论是游戏服务端,APP 服务端还是日常的 Web 服务都是客户端数量无法估量,而每次交互过程中的数据量又是非常有限的,多则上百k,少则几 k,几十k,而且大多数应该是几 k,几十 k 的场景,所以网络上很多的测试案例更关注的是 QPS。
而 BPS 的应用场景多处于有限个节点的大量数据同步,这个场景更关注的是吞吐性能,而非响应情况。
大家如果自己进行性能测试的时候如果想要测试出某个框架的极限性能需要关注上面两个黑体字所提到的优化内容.因为每个框架对于出厂时的设置是由倾向的,最起码要站在一个相对公平的环境下进行测试。