看cuda初级教程视频笔记(周斌讲的)--CUDA编程1
01年开始,研究人员把GPU当做数据并行协处理器(GPGPU)
07年,英伟达发布CUDA (Compute Uniform Device Architecture)统一计算设备架构
08年,OpenCL规范,使得并行计算可以扩展到更多设备平台上去
CUDA的一些信息(线程嘛)
层次化线程集合A hierarchy of thread groups,共享储存Shared memories,同步Barrier Synchronization
CUDA术语 Host和device通常就是指cpu和gpu,采用ANSI标准C的扩展语言编程,编程时候,有主机端和设备端两部分的代码
Kernel,数据并行处理函数,在设备端有硬件负责创建调度线程,在主机端调这个函数
想吃饭了,先不写了~哈哈哈
隔了四天接着学,接着写
float *Md
int size=width*width*sizeof(float);
cudaMalloc((void**)&Md,size);
...
cudaFree(Md);这个(void**)&Md指针是指向设备的指针,cpu不能调用
cudaMemcpy()内存传输 :主机端向主机端,设备端向设备端,主机端向设备端,设备端向主机端
cudaMemcpy(目的地址,原地址,大小,cudaMemcpyHostToDevice);
Matrix Multiply矩阵相乘算法提示:向量,点乘,行优先还是列优先?每次点乘结果输出一个元素
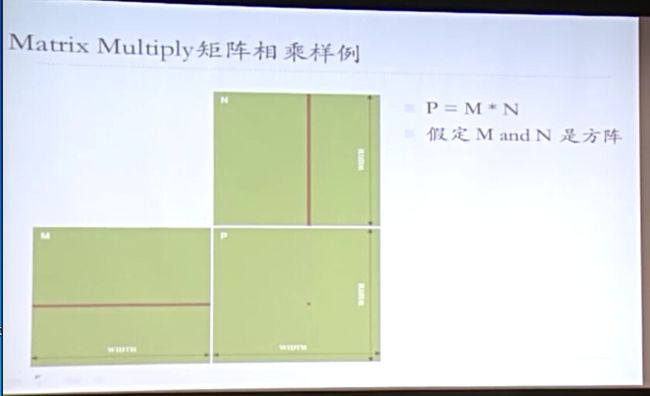
1000*1000矩阵
1,000,000点乘,每一个点需要1000个乘法和1000个加法
void MatrixMulOnHost(float* M,float *N,float* p,int width)
{
for(int i=0;ifloat b=N[k*width+j];sum+=a*b;
}
P[i*width+j]=sum;
}
}第一步,是要管理整个内存,要为输入的原始数据已经输出的结构,这些要分配内存 M N P
第二步,并行运算
第三部,把结果拷贝回来,释放内存
void MatrixMulOnDevice(float* M,float *N,float* p,int width)
{
int size=width*width*sizeof(float);
//第一步,给M和N装填设备内存
cudaMalloc(Md,size);
cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);
cudaMalloc(Nd,size);
cudaMemcpy(Nd,N,size,cudaMemcpyHostToDevice);
cudaMalloc(Pd,size);
//都是GPU上的空间
//2.kernel invocation code
}
__global__ void MatrixMulKernel(loat* Md,float *Nd,float* pd,int width)
{
int tx=threadIdx.x;
int ty=threadIdx.y;
float Pvalue=0;
for(int k=0;k>>(Md,Nd,Pd);
//是不是少了一个参数啊; 之前看的没有这样调用的啊,
dim3 dimBlock(WIDTH,WIDTH);这的是每个block立面的线程数对吗,这就是1,000,000 啊,不是说的好这里的约束是65536个嘛
下面的意思是调用了1个block,然后立面有一百万个线程同时运算,这个参数也有问题,这个课结束了,容我再看看