新特性总览
- lambda表达式
- Stream操作数组
- Optional取代null
- 简洁的并发编程
- LocalDateTime新的时间API
Lambda表达式
概念:Lambda表达式是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应其中的Lambda抽象(lambda abstraction),是一个匿名函数,既没有函数名的函数。Lambda表达式可以表示闭包(注意和数学传统意义的不同)。你也可以理解为,简洁的表示可传递的匿名函数的一种方式:它没有名称,但它有参数列表、函数主体、返回类型,可能还有一个可以抛出异常的列表。
-
作用:既然是匿名函数,那就类比于匿名内部类的用法咯,哪些地方,会用到一些代码量大但实际逻辑不算复杂的方法调用,就可以用到它。
什么是函数式接口?
答:仅仅只有一个抽象方法的接口。
-
语法:
() -> 表达式() -> {语句;}() -> 对象-
(Class)() -> {语句;}【指定对象类型】public static void doSomething(Runnable r) { r.run(); } public static void doSomething(Task a) { a.execute(); } .... doSomething(() -> System.out.println("DDDD")); // 为了避免隐晦的方法调用,尝试显式地类型转换 doSomething((Runnable)() -> System.out.println("DDDD"));
-
使用场景(很多特殊场景都包含在内)
总的来说,只有在接受函数式接口的地方才可以使用Lambda表达式。
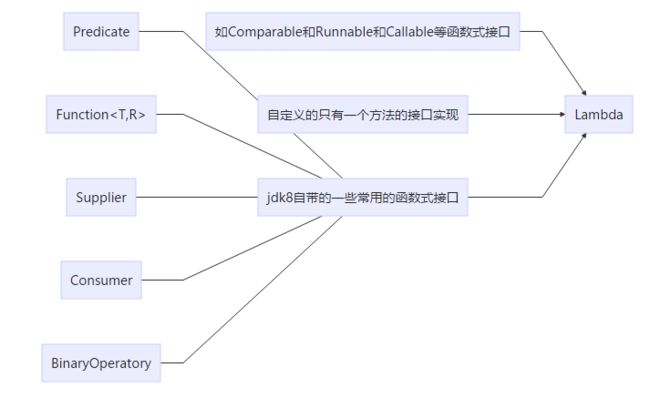 image.png
image.png -
一些Jdk8的lambda语法糖:
Lambda:(Apple a) -> a.getWeight() 方法引用:Apple::getWeight Lambda:() -> Thread.currentThread().dumpStack() 方法引用:Thread.currentThread()::dumpStack Lambda:(str, i) -> str.substring(i) 方法引用:String::substring Lambda:(String s) -> System.out.println(s) 方法引用:System.out::println -
构造函数引用
- 无参构造器
Supplierc1 = Apple::new; Apple apple = c1.get(); // 等价于 Supplier c2 = () -> new Apple(); - 一参构造器
Function - 两参构造器
BiFunction
- 无参构造器
-
简化的数组排序
apples.sort(comparing(Apple::getWeight)); // 其中: // ArrayList.sort() since:1.2 // Comparator.comparing(Function -
更复杂的数组排序
- 倒序
apples.sort(Comparator.comparing(Apple::getWeight).reversed()); - 多条件排序
apples.sort(Comparator.comparing(Apple::getWeight).reversed() .thenComparing(Apple::getCountry));
- 倒序
-
Predicate的复合
以下三个基本谓词,可以配合已有的谓词(Predicate),来制造出更加复杂的谓词。
- negate:“非”
private staticList filter(List list, Predicate predicate) { List result = new ArrayList<>(); for (T t : list) { if (predicate.test(t)) { result.add(t); } } return result; } // 红苹果 Predicate redApplePd = a -> "red".equals(a.getColor()); // 不是红苹果 Predicate notRedApplePd = a -> redApplePd.negate(); // 过滤 List redApple = filter(rawApples, redApplePd); List notRedApple = filter(rawApples, notRedApplePd); - and:“与”
PredicateredHeavyApplePd = ((Predicate ) apple -> apple.color.equals("red")).and(apple -> false); - or:“或”(同理)
- negate:“非”
-
Function的复合
- andThen
f.andThen(g)相当于g(f()),先执行f(),后执行g()Function - compose
f.compose(g)相当于f(g()),先执行g(),后执行f()Function
- andThen
Stream
- 概念:流是Java API新成员,它允许你以声明性方式处理数据集合。
- 特点:
- 流水线:类似“链式调用”,一步接一步。
- 内部迭代:与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
- 作用:
- 减少for循环
- 减少数组操作中可能声明的垃圾变量的数量
- 直观、提高可读性
- 流和集合的区别:
- 类似于看视频,无论点到视频的哪一段,它都能很快加载出来,这就是流。而集合相当于我要把整部电影down下来,才能点哪看哪。
- 集合是内存中的数据结构,它包含数据结构中目前所有的值,集合中每个元素都需要事先计算好,才被放入集合。
- 流是在概念上固定的数据结构,其元素时按需计算的(懒加载)。需要多少就给多少。换一个角度,流像是一个延迟创建的集合:只有在消费者要求的时候才会生成值。
- 看一个例子
如果只用Lambda表达式,那操作数组起来,也还是需要一些for循环的加持。public ListfilterApple(List apples, Predicate criteria) { List result = new ArrayList<>(); apples.forEach(apple -> { if (criteria.test(apple)) { result.add(apple); } }); return result; }
而有了Stream,写起code就简单很多了。ListredHeavyApples = apples.stream() .filter(apple -> "red".equals(apple.color)) .filter(apple -> apple.weight > 120) .collect(Collectors.toList()); - 相关包、类、方法
- 包:
java.util.stream - 接口:
BaseStreamStreamextends BaseStream DoubleStream extends BaseStreamIntStream extends BaseStreamLongStream extends BaseStream
- 方法:
filter(Predicate):Streammap(Function):StreammapToInt(ToIntFunction):LongStreammapToDouble(ToDoubleFunction):DoubleStreammapToLongflatMap(Function>):StreamflatMapToInt()flatMapToLong()flatMapToDouble()distinct():Streamsorted():Streamsorted(Comparator):Streampeek(Consumer):Streamlimit(long):Streamskip(long):StreamforEach(Consumer):voidforEachOrdered()toArray():Object[]toArray(IntFunctionreduce(T, BinaryOperator):T reduce(BinaryOperator):Optional reduce(U, BiFunctioncollect(Supplier, BiConsumer collect(Collector):Rmin(Comparator):Optionalmaxcount():longanyMatch(Predicate):booleanallMatchnoneMatchfindFirst():OptionalfindAnybuilder():Builderempty():Streamof(T...):Streamiterate(T, UnaryOperator):Steram generate(Supplier):Stream concat(Stream, Stream):Stream
- 包:
- 例子:取重的绿苹果,然后升序排序,取它的重量
ListgreenHeavyAppleWeight = apples.stream() .filter(apple -> apple.weight > 120) .filter(apple -> "green".equals(apple.color)) .sorted(comparing(Apple::getWeight)) // Comparator.comparing() .map(apple -> apple.weight) .collect(toList()); // Collectors.toList() - 流只能被消费一次
Listnames = Arrays.asList("Java8", "Lambdas", "In", "Action"); Stream s = names.stream(); s.forEach(System.out::println); // 再继续执行一次,则会抛出异常 s.forEach(System.out::println); - 用
flatMap()实现流的扁平化
没有打平,出来的是两个String[],我需要两个嵌套for 循环来打印内容。而如果用flatMap:String[] words = {"Hello", "World"}; StreamstreamOfWords = Arrays.stream(words); // 没有打平,是两个 String[],我需要两个嵌套for 循环来打印内容 List String[] words = {"Hello", "World"}; StreamstreamOfWords = Arrays.stream(words); // 打平,一个for循环就搞定 List chars = streamOfWords .map(w -> w.split("")) .flatMap(Arrays::stream) .collect(toList()); for (String item: chars) { System.out.print(item + "-"); }
打平之后,直接操作一个数组就好。
- 例子:求最大最小值
Listnumbers = Arrays.asList(2, 5, 3, 4, 1, 6, 3, 5); // way 1 Integer max = numbers.stream().max(Integer::compareTo).orElse(null); // way 2 max = numbers.stream().reduce(Integer::max).orElse(null); - 原始类型流的特化(Stream转IntStream/LongStream/DoubleStream)
作用:直接特化为原始类型:int、long、double,避免暗含的装箱成本。以及,有了一些额外的计算方法。
- 映射到数值流:
mapToInt/mapToLong/mapToDouble - 转回对象流:
boxed
- 映射到数值流:
- 特化流的一下额外方法
// 获得 1到100 的所有偶数 IntStream.rangeClosed(1, 100).filter(num -> num%2 == 0).forEach(System.out::println); - 构建流
- 方式一:由值创建流
Streamstream = Stream.of("Java8", "Lambda", "In"); stream.map(String::toUpperCase).forEach(System.out::println); - 方式二:由数组创建流
int[] nums = {2,4,6,7,8,12}; int sum = Arrays.stream(nums).sum(); - 方式三:由集合创建流
Listnums = Arrays.asList(1,2,3,4,5); Stream numStream = nums.stream(); Stream parallelStream = nums.parallelStream(); - 方式四:文件 + NIO 创建流
利用
java.nio.file.Files中的一些静态方法(静态方法 since JDK1.8)都返回一个流。Filessince JDK1.7一个很有用的方法是
Files.lines,它会返回一个由指定文件中的各行构成的字符串流。
long uniqueWords; try (Streamlines = Files.lines(Paths.get(ClassLoader.getSystemResource("data.txt").toURI()), Charset.defaultCharset())) { uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" "))) .distinct() .count(); System.out.println("uniqueWords:" + uniqueWords); } catch (IOException e) { e.fillInStackTrace(); } catch (URISyntaxException e) { e.printStackTrace(); } - 方式五:由函数生成流
不像从固定集合创建的流那样有固定大小的流。由 iterate和 generate 产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去。以下两个操作,可以创建“无限流”,一般配合limit 使用 Stream.iterate(<初始值>, <值的变化函数>) Stream.generate(Supplier s)// 迭代:每次返回前一个元素加2的值 Stream.iterate(0, n -> n + 2) .limit(10) .forEach(System.out::println);
看下面这个例子,对比Lambda表达式(匿名函数)和匿名内部类:// 生成:接收一个Supplier类型的函数(有出无入的函数) Stream.generate(Math::random) .limit(5) .forEach(System.out::println);
如果这个// lambda IntStream twos = IntStream.generate(() -> 2); // 匿名内部类 IntStream twos = IntStream.generate(new IntSupplier() { @Override public int getAsInt() { return 2; } });IntSupplier中不存在成员变量,那么,两者等价。总的来说,匿名内部类更加灵活,而且其output值不一定唯一不变,较为灵活。
- 方式一:由值创建流
- 收集器的用法
- 接口:
java.util.stream.Collector - 作用:对
Stream的处理结果做收集。 - 例子:
-
分组
Listapples = Arrays.asList( new Apple(130, "red"), new Apple(22, "red"), new Apple(60, "green"), new Apple(162, "green"), new Apple(126, "green"), new Apple(142, "green"), new Apple(117, "green") ); // 根据颜色分组 Map -
多级分组
Map -
分组的一些配合操作
Stream.collect(groupingBy(Dish::getType, summingInt(Dish::getCalories))); Stream.collect(groupingBy(Dish::getType, mapping(...))); // 如: Map -
计数
long count = apples.size(); long count = apples.stream().collect(Collectors.counting()); long count = apples.stream().count(); -
汇总
// 求和 int totalWeight = apples.stream().collect(summingInt(Apple::getWeight)); totalWeight = apples.stream().mapToInt(Apple::getWeight).sum(); // 平均数 double avgWeight = apples.stream().collect(averagingDouble(Apple::getWeight)); avgWeight = apples.stream().mapToDouble(Apple::getWeight).average().orElse(-1); // 汇总 IntSummaryStatistics appleStatistics = apples.stream().collect(summarizingInt(Apple::getWeight)); System.out.println(appleStatistics.getMax()); System.out.println(appleStatistics.getMin()); System.out.println(appleStatistics.getAverage()); System.out.println(appleStatistics.getCount()); System.out.println(appleStatistics.getSum()); -
连接字符串
String[] strs = {"Hello", "World"}; String result = Arrays.stream(strs).collect(joining([分隔符])); -
分区
根据Predicate条件,分成true和false两部分集合。
Map看似没有什么特点,但是其实和grouping类似,有一个
downStream:Collector的一个第二参数,这就厉害了,扩展性很强。// 先划分了素食和非素食,然后,每一类里面,去热量最高的一个。 Map
-
- 接口:
- 自定义流(这个就再说咯)
- 并行流
相对于
stream(),用parallelStream()就能把集合转换为并行流。- 概念:并行流就是一个把内容分成多个数据块,并用不同线程分别处理每个数据块的流。
- 方法:
切换为并行流:Stream.parallel() 切换为顺序流:Stream.sequential() // 注意,谁最后调用,流就apply谁。 - 用并行流之前,要测试性能(如果遇到iterator装包解包等的情况,实际上并行锁会更加慢,能用特化流就尽量用特化流)
- Spliterator 定义了并行流如何拆分它要遍历的数据
Optional
- class:
java.util.Optional - 作用:解决和避免NPE异常
- Optional对象的方法
-
get():不推荐使用。如果变量存在,它直接返回封装的变量值,否则就抛出一个NPE或者NoSuchElementException异常。Optional方法 调用get()后抛出异常 Optional.of(null) java.lang.NullPointerException Optional.ofNullable(null) java.util.NoSuchElementException orElse(T other)-
orElseGet(Supplier other):orElse的延迟调用版,Supplier方法只有在Optional对象不含值时才执行。- 适用场景:
- 创建默认值是耗时的工作。
- 或者需要十分确定某个方法仅在Optional为空时才调用。
Person p1 = null; OptionaloptP1 = Optional.ofNullable(p1); Person resultP = optP1.orElseGet(() -> { Person p = new Person(); p.firstName = "Fang"; return p; }); System.out.println("resultP.firstName: " + resultP.firstName); - 适用场景:
-
orElseThrow(Supplier exceptionSupplier):定制抛出的异常。 -
ifPresent(Consumer):当变量值存在时执行一个作为参数传入的方法,否则不做任何操作。Person p1 = new Person(); OptionaloptP1 = Optional.ofNullable(p1); optP1.ifPresent(person -> System.out.println("Haha")); -
filterPerson p1 = new Person(); p1.firstName="Fang"; p1.lastName="Hua"; Person resP = Optional.ofNullable(p1).filter(person -> "Hua".equals(person.lastName)).orElseGet(() -> { Person newP = new Person(); newP.firstName= "Ming"; return newP; }); System.out.println(resP.firstName); // Ming - 当然,还有一些方法与Stream接口相似,如
map和flatMap
-
- 例子:
- 对象嵌套取值
- old
@Test public void test_optional_1() { Person person = new Person(); // 当然从重构角度来看,这里是不对的,我们知道太多这个类内部的东西,是需要重构的 String name = person.getCar().getInsurance().getName(); } public class Person { private Car car; public Car getCar() { return car; } } public class Car { private Insurance insurance; public Insurance getInsurance() { return insurance; } } public class Insurance { private String name; public String getName() { return name; } } - new
public String getCarInsuranceName(Person person) { return Optional.ofNullable(person).flatMap(Person::getCar) .flatMap(Car::getInsurance) .map(Insurance::getName) .orElse("Unknown"); } public class Person { private String sex; private String firstName; private String lastName; private Optionalcar = Optional.empty(); public Optional getCar() { return car; } } public class Car { private Optional insurance = Optional.empty(); public Optional getInsurance() { return insurance; } } public class Insurance { private String name; public String getName() { return name; } }
- old
- 封装可能为空的值
Object value = map.get("key"); // 加上 Optional Optional - 异常与Optional 去替代 if-else判断
public static OptionalstringToInt(String s) { try { return Optional.of(Integer.parseInt(s)); } catch (NumberFormatException e) { return Optional.empty(); } } - 两个Optional对象的组合
public Insurance findBestInsurance(Person person, Car car) { Insurance insurance = new Insurance(); insurance.name = person.firstName + person.lastName + " --insurance 01"; return insurance; } public OptionalnullSafeFindBestInsurance(Optional person) { if (person.isPresent() && person.get().getCar().isPresent()) { Car car = person.get().getCar().get(); return Optional.of(findBestInsurance(person.get(), car)); } else { return Optional.empty(); } }
- 对象嵌套取值
- 原理:
- 变量存在时,Optional类只是对类简单封装。
- 变量不存在时,缺失的值会被建模成一个“空”的Optional对象,由方法
Optional.empty()返回。 -
Optional.empty()是一个静态工厂方法,
函数式编程(Stream+Lambda)
函数式编程 VS 命令式编程
- 命令式编程关注怎么做,而函数式编程关注做什么
- 函数式编程 可读性强,但运行速度不见得更快。
例子
1. for循环取数组最小值
int[] nums = {1,3,-1,6,-20};
int min = Integer.MAX_VALUE;
for (int i:nums) {
if(i < min) {
min = i;
}
}
变成
int min2 = IntStream.of(nums).parallel().min().getAsInt();
2. 接口的实现/匿名内部类转Lambda
/// 接口实现
Object target = new Runnable() {
@Override
public void run() {
System.out.println("新建一个线程");
}
};
new Thread((Runnable) target).start();
/// 匿名内部类
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("BBB");
}
}).start();
变成
Object target2 = (Runnable)() -> System.out.println("新建一个线程2");
Runnable target3 = () -> System.out.println("新建一个线程3");
System.out.println("target2 == target3 :" + (target2 == target3)); // false
new Thread((Runnable) target2).start();
new Thread(() -> System.out.println("BBB")).start()
3. Lambda创建自定义接口的实例对象
必备条件:
- 该接口中只能有一个抽象方法
- 在接口上加上@FunctionalInterface注解(可选:为了编译器的校验,有这个注解的接口,当存在多个抽象方法时,是会编译报错的。)
JDK8 中,接口中可以定义静态方法和默认方法。
@FunctionalInterface
interface Interface1 {
int doubleNum(int i);
default int add(int x, int y) {
return x + y;
}
static int sub(int x, int y) {
return x - y;
}
}
@FunctionalInterface
interface Interface2 {
int doubleNum(int i);
default int add(int x, int y) {
return x + y;
}
}
@FunctionalInterface
interface Interface3 extends Interface1, Interface2 {
@Override
default int add(int x, int y) {
return Interface1.super.add(x, y);
}
}
@Test
public void test_lambda_1() {
Interface1 i1 = (i) -> i * 2;
System.out.println("Interface1.sub(10, 3): " + Interface1.sub(10, 3));
System.out.println("i1.add(3,7):" + i1.add(3, 7));
System.out.println("i1.doubleNum(20):" + i1.doubleNum(20));
Interface2 i2 = i -> i * 2;
Interface3 i3 = (int i) -> i * 2;
Interface3 i4 = (int i) -> {
System.out.println(".....");
return i * 2;
};
}
4. Lambda与Function
String cityName= "HongKong";
int stateCode=237;
String street = "东岸村黄皮树下街1号";
String locationID = "";
Function locationIDBuilder = locId -> locId + cityName; // Step 1
locationID = locationIDBuilder
.andThen(locId -> locId + ",区号:" + stateCode) // Step 2
.andThen(locId -> locId+",街道:" + street).apply(locationID); // Step 3
System.out.println("locationID:" + locationID);
JDK 1.8 API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上
| name | type | description |
|---|---|---|
| Consumer | Consumer< T > | 接收T对象,不返回值 |
| Predicate | Predicate< T > | 接收T对象并返回boolean |
| Function | Function< T, R > | 接收T对象,返回R对象 |
| Supplier | Supplier< T > | 提供T对象(例如工厂),不接收值 |
| UnaryOperator | UnaryOperator | 接收T对象,返回T对象 |
| BinaryOperator | BinaryOperator | 接收两个T对象,返回T对象 |
Lambda 与 设计模式
策略模式
interface ValidationStrategy {
boolean execute(String s);
}
static class IsAllLowerCase implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("[a-z]+");
}
}
static class IsNumeric implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("\\d+");
}
}
static class Validator {
private final ValidationStrategy validationStrategy;
public Validator(ValidationStrategy validationStrategy) {
this.validationStrategy = validationStrategy;
}
public boolean validate(String s) {
return validationStrategy.execute(s);
}
}
正常来说,要new一些策略来当参数传。
IsNumeric isNumeric = new IsNumeric();
IsAllLowerCase isAllLowerCase = new IsAllLowerCase();
Validator validatorA = new Validator(isNumeric);
Validator validatorB = new Validator(isAllLowerCase);
使用lambda,让new尽量少出现在code中。
Validator validatorA = new Validator(s -> s.matches("\\d+"));
Validator validatorB = new Validator(s -> s.matches("[a-z]+"));
模板模式(抽象类的应用)
public abstract class AbstractOnlineBank {
public void processCustomer(int id) {
Customer customer = Database.getCustomerWithId(id);
makeCustomerHappy(customer);
}
abstract void makeCustomerHappy(Customer customer);
static class Customer {}
static class Database {
static Customer getCustomerWithId(int id) {
return new Customer();
}
}
}
...
AbstractOnlineBank bank = new AbstractOnlineBank() {
@Override
void makeCustomerHappy(Customer customer) {
System.out.println("Hello!");
}
};
bank.processCustomer(1);
bank.processCustomer(2);
用了Lambda,抽象方法都用不着了
public class AbstractOnlineBank {
public void processCustomer(int id, Consumer makeCustomerHappy) {
Customer customer = Database.getCustomerWithId(id);
makeCustomerHappy.accept(customer);
}
static class Customer {}
static class Database {
static Customer getCustomerWithId(int id) {
return new Customer();
}
}
}
...
AbstractOnlineBank bank = new AbstractOnlineBank();
bank.processCustomer(1, customer -> System.out.println("Hello"));
bank.processCustomer(2, customer -> System.out.println("Hi"));
观察者模式
interface Observer{
void inform(String tweet);
}
private static class NYTimes implements Observer {
@Override
public void inform(String tweet) {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY!" + tweet);
}
}
}
private static class Guardian implements Observer {
@Override
public void inform(String tweet) {
if (tweet != null && tweet.contains("queen")) {
System.out.println("Yet another news in London... " + tweet);
}
}
}
private static class LeMonde implements Observer {
@Override
public void inform(String tweet) {
if(tweet != null && tweet.contains("wine")){
System.out.println("Today cheese, wine and news! " + tweet);
}
}
}
interface Subject {
void registerObserver(Observer o);
void notifyObserver(String tweet);
}
private static class Feed implements Subject {
private final List observers = new ArrayList<>();
@Override
public void registerObserver(Observer o) {
observers.add(o);
}
@Override
public void notifyObserver(String tweet) {
observers.forEach(o -> o.inform(tweet));
}
}
好的,看到了有一个观察者接口,并且只有一个方法inform,那么,我们是不是就可以少声明这几个实现类呢?
Feed feedLambda = new Feed();
feedLambda.registerObserver((String tweet) -> {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY!" + tweet);
}
});
feedLambda.registerObserver((String tweet) -> {
if (tweet != null && tweet.contains("queen")) {
System.out.println("Yet another news in London... " + tweet);
}
});
feedLambda.notifyObserver("Money money money, give me money!");
责任链模式
private static abstract class AbstractProcessingObject {
protected AbstractProcessingObject successor;
public void setSuccessor(AbstractProcessingObject successor) {
this.successor = successor;
}
public T handle(T input) {
T r = handleWork(input);
if (successor != null) {
return successor.handle(r);
}
return r;
}
protected abstract T handleWork(T input);
}
一看到,又是抽象类加不同的实现,那就想到是不是可以用匿名函数实现,而这里,我们使用UnaryOperator:
// 流程A
UnaryOperator headerProcessing = (String text) -> "From Raoul, Mario and Alan: " + text;
// 流程B
UnaryOperator spellCheckerProcessing = (String text) -> text.replaceAll("labda", "lambda");
// A --> B
Function pipeline = headerProcessing.andThen(spellCheckerProcessing);
String result2 = pipeline.apply("Aren't labdas really sexy?!!");
工厂模式
private interface Product {
}
private static class ProductFactory {
public static Product createProduct(String name) {
switch (name) {
case "loan":
return new Loan();
case "stock":
return new Stock();
case "bond":
return new Bond();
default:
throw new RuntimeException("No such product " + name);
}
}
}
static private class Loan implements Product {
}
static private class Stock implements Product {
}
static private class Bond implements Product {
}
简单情况下,可以用Supplier去实现引用方法式的构造器调用,并且减少switch。
private static class ProductFactory {
private static final Map> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
public static Product createProduct(String name) {
Supplier productSupplier = map.get(name);
if (productSupplier != null) {
return productSupplier.get();
}
throw new RuntimeException("No such product " + name);
}
}
当然,如果工厂方法 createProduct 需要接收多个传递给产品构造方法的参数,这种方式的扩展性不是很好。
默认方法
Jdk8开始支持的东西
Jdk8中的接口支持在声明方法的同时提供实现。
- Jdk8支持接口中有静态方法。
interface IBoy { static String getCompany() { return "OOL"; } } - Jdk8支持接口中有默认方法。【jdk8 新功能】
// List.sort() default void sort(Comparator c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIteratori = this.listIterator(); for (Object e : a) { i.next(); i.set((E) e); } } // Collection.stream() default Stream stream() { return StreamSupport.stream(spliterator(), false); }
作用
- 为接口定义默认的方法实现:默认方法提供了接口的这个方法的默认实现,那么,在使用Lambda匿名地构造接口实现时,就不需要显示重写接口的这个方法,默认方法自动就会继承过来。
- 新增的接口,只要加上
default修饰符,就可以不被显式继承,因此,别的地方的代码是不用改动的!!看个例子:jdk8以前的
Iterator接口,实际上用户是不在乎remove()方法的,而且当时是没有forEachRemaining()方法的,那么,当时的做法,就是每次实现这个接口的时候,都需要显式继承并重写remove()方法,很烦。到了jdk8, 有了
default修饰符,那么,我们不想显式重写的remove()方法就可以不用重写了,然后,jdk8新增了forEachRemaining()方法,也不需要其他实现类再去修改code了,因为它压根不需要你显式重写。
解决继承链上的冲突的规则
public interface A {
default void hello() {
System.out.println("Hello from A");
}
}
public interface B extends A {
default void hello() {
System.out.println("Hello from B");
}
}
public class C implements A, B {
public static void main(String[] args) {
// 猜猜打印的是什么?
new C().hello();
}
}
以上问题,就是菱形继承问题,如果父子接口有同名的default方法,那么,以上代码编译不通过。
我们需要重写这个方法:
public class C implements A, B {
public static void main(String[] args) {
new C().hello();
}
@Override
public void hello() {
A.super.hello();
}
OR
@Override
public void hello() {
B.super.hello();
}
OR
@Override
public void hello() {
System.out.println("Hello from C!");
}
}
组合式异步编程
- 术语: CompletableFuture
- 背景:
- Jdk 7 中引入了“并行/合并框架”
注意:并行和并发的区别:
- 并行(parallellism):
- 并行指的是同一个时刻,多个任务确实真的在同时运行。多个任务不抢对方资源。
- 例子:两个人,各自一边吃水果,吃完就吃pizza。【有多个CPU内核时,每个内核各自不占对方的资源,各做各的事,是可以达到真正意义上的“同时”的。】
- 并发(concurrency):
- 并发是指在一段时间内宏观上多个程序同时运行。多个任务互相抢资源。
- 例子:一个人,同时做多件事情。【单核计算器中,是不可能“同时”做两件事的,只是时间片在进程间的切换很快,我们感觉不到而已。】
- 并行(parallellism):
- Jdk 8 中引入了并行流
- Jdk 8 中改进了
Future接口,并且,新增了CompletableFuture接口。 - 如果我们现在有一个大的耗时任务要处理,我们可以将其拆分为多个小任务,让其并行处理,最终再将处理的结果统计合并起来, 那么,我们可以结合 并行/合并框架 + 并行流 来快速实现。
- Jdk 7 中引入了“并行/合并框架”
RecursiveTask(JDK 1.7)
例子:实现一个100000个自然数的求和。
class SumTask extends RecursiveTask {
public static final int Flag = 50;
long[] arr;
int start;
int end;
public SumTask(long[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
public SumTask(long[] arr) {
this.arr = arr;
this.start = 0;
this.end = arr.length;
}
@Override
protected Long compute() {
// 如果不能进行更小粒度的任务分配
int length = end - start;
if (length <= Flag) {
return processSequentially();
}
//分治
int middle = (start + end) / 2;
SumTask sumTaskOne = new SumTask(arr, start, middle);
SumTask sumTaskTwo = new SumTask(arr, middle, end);
invokeAll(sumTaskOne, sumTaskTwo);
Long join1 = sumTaskOne.join();
Long join2 = sumTaskTwo.join();
return join1 + join2;
}
// 小任务具体是做什么
private long processSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += arr[i];
}
return sum;
}
}
@Test
public void test() {
long[] arr = new long[1000];
for (int i = 0; i < arr.length; i++) {
arr[i] = (long) (Math.random() * 10 + 1);
}
// 线程池(since 1.7)
ForkJoinPool forkJoinPool = new ForkJoinPool(5);
ForkJoinTask forkJoinTask = new SumTask(arr);
long result = forkJoinPool.invoke(forkJoinTask);
System.out.println(result);
}
- 总结: 分支/合并框架让你得以用递归方式将可以并行的任务拆分成更小的任务,在不同的线程上执行,然后将各个子任务的结果合并起来生成整体结果。
Spliterator(可分迭代器 JDK 1.8)
(一)背景
- jdk 1.8 加入,和Iterator一样,也用于遍历数据源元素,但它是为了并行执行而设计的。
- jdk8已经为集合框架中的所有数据结构提供了一个默认的Spliterator实现。
- 目的:
- 为了优化在并行流做任务处理时的数据源拆分遍历时,使用Iterator的装包和解包的性能开销。
- 配合并行流更快地遍历和处理元素。
- 内部方法:
public interface Spliterator{ // 如果还有元素要遍历, 返回true boolean tryAdvance(Consumer action); // 把一些元素拆分给第二个Spliterator,不断对 Spliterator 调用 trySplit直到它返回 null ,表明它处理的数据结构不能再分割 Spliterator trySplit(); // 估计剩下多少元素要遍历 long estimateSize(); // 用于影响开分过程的配置参数 int characteristics(); } - 延迟绑定的Spliterator:Spliterator可以在第一次遍历、第一次拆分或第一次查询估计大小时绑定元素的数据源,而不是在创建时就绑定。这种情况下,它称为延迟绑定(late-binding)的 Spliterator 。
(二)例子
例子:一个自定义的并行迭代器,用于处理单词数量统计
// 首先,我们有一个英文句子,我们要统计它的单词数量
public static final String SENTENCE =
" Nel mezzo del cammin di nostra vita " +
"mi ritrovai in una selva oscura" +
" che la dritta via era smarrita ";
- 方法一:通常手段,写一个方法,直接实现统计逻辑
public static int countWords1(String s) { int counter = 0; boolean lastSpace = true; for (char c : s.toCharArray()) { if (Character.isWhitespace(c)) { lastSpace = true; } else { if (lastSpace) { counter ++; } lastSpace = Character.isWhitespace(c); } } return counter; } - 方法二:利用jdk8 stream的函数声明式来简化代码,但是要实现辅助对象了
实现了辅助对象后,实现一个传stream处理的方法,去调用private static class WordCounter { private final int counter; private final boolean lastSpace; public WordCounter(int counter, boolean lastSpace) { this.counter = counter; this.lastSpace = lastSpace; } // 如何改变WordCounter的属性状态 public WordCounter accumulate(Character c) { if (Character.isWhitespace(c)) { return lastSpace ? this : new WordCounter(counter, true); } else { return lastSpace ? new WordCounter(counter + 1, false):this; } } // 调用此方法时,会把两个子counter的部分结果进行汇总。 // 其实就是 把内部计数器相加 public WordCounter combine(WordCounter wordCounter) { return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace); } public int getCounter() { return counter; } }
用以上这种方式,就只能实现串行的处理public static int countWords2(Streamstream) { WordCounter wordCounter = stream.reduce(new WordCounter(0, true),WordCounter::accumulate, WordCounter::combine); return wordCounter.getCounter(); } @Test public void test_2() { Streamstream = IntStream.range(0, SENTENCE.length()) .mapToObj(SENTENCE::charAt); System.out.println("Found " + countWords2(stream) + " words"); } - 方法三:使用jdk8中的可分迭代器,模拟jdk7的拆分/合并模式去实现并行迭代处理过程:
有了自定义的可分迭代器,我们就可以用并行的处理方式了:public class WordCounterSpliterator implements Spliterator{ private final String string; private int currentChar = 0; public WordCounterSpliterator(String string) { this.string = string; } /** * 把String中当前位置的char 传给 Consumer,并让其位置+1, * 作为参数传递的Consumer是一个java内部类,在遍历流时将要处理的char传给一系列要对其执行的函数。 * 这里只有一个归约函数,即 WordCounter 类的 accumulate方法。 * 如果新的指针位置小于 String 的总长,且还有要遍历的 Character ,则tryAdvance 返回 true 。 */ @Override public boolean tryAdvance(Consumer action) { action.accept(string.charAt(currentChar++)); return currentChar < string.length(); } @Override public Spliterator trySplit() { // 像 RecursiveTask 的 compute 方法一样(分支/合并框架的使用方式) int currentSize = string.length() - currentChar; // 定义不再拆分的界限(不断拆分,直到返回null) if (currentSize < 10) { return null; } for (int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++) { if (Character.isWhitespace(string.charAt(splitPos))) { // 类似RecursiveTask那样,递归拆分 Spliterator spliterator = new WordCounterSpliterator(string.substring(currentChar, splitPos)); currentChar = splitPos; return spliterator; } } return null; } @Override public long estimateSize() { return string.length() - currentChar; } @Override public int characteristics() { return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE; } } @Test public void test_3() { Spliteratorspliterator = new WordCounterSpliterator(SENTENCE); Stream stream = StreamSupport.stream(spliterator, true); System.out.println("Found " + countWords2(stream.parallel()) + " words"); }
CompletableFuture(Jdk 1.8)
- 翻译:可完备的Future
- 简单来说,就是写法更灵活、code可读性更好的Future。
- 是除了并行流之外的另一种并行方式,只是使用场景不同。
(一)一个商店商品报价的例子
普通的方法去写一个同步的计算报价的方法:
private static class Shop {
private final String name;
private final Random random;
public Shop(String name) {
this.name = name;
random = new Random(name.charAt(0) * name.charAt(1) * name.charAt(2));
}
public double getPrice(String product) {
return calculatePrice(product);
}
private double calculatePrice(String product) {
delay(1000);
return random.nextDouble()*product.charAt(0) + product.charAt(1);
}
}
......
@Test
public void test_1() {
Shop nike = new Shop("nike");
Shop adidas = new Shop("adidas");
System.out.println("nike Kobe1 price : "+ nike.getPrice("Kobe1"));
System.out.println("nike Rose3 price : "+ adidas.getPrice("Rose3"));
}
我们先用CompletableFuture来让计算变成异步。
- 首先,用一个线程去执行对应逻辑,并且返回一个
CompletableFuture实例:private static class Shop { ............ public FuturegetPriceAsync(String product) { CompletableFuture futurePrice = new CompletableFuture<>(); new Thread(() -> { double price = calculatePrice(product); futurePrice.complete(price); }).start(); return futurePrice; } ............ } - 好,然后我们在执行此方法时,就实现了异步。
@Test public void test_2() throws ExecutionException, InterruptedException { Shop nike = new Shop("nike"); Shop adidas = new Shop("adidas"); Futureprice1 = nike.getPriceAsync("Kobe1"); Future price2 = adidas.getPriceAsync("Kobe1"); System.out.printf("nike Kobe1 price :%.2f%n",price1.get()); System.out.printf("nike Kobe1 price :%.2f%n", price2.get()); }
(二)Future的局限性
看到上面,我们发现,其实,和用Future去handle结果返回,好像差不多。
- 我们可以用
Future.get(timeout, TimeUnit)来防止一直拿不到值而等待的情况。 - 可以用
Future.isDone()来判断当前任务是否跑完,然后做不同的handle逻辑。
@Test
public void test_1() throws InterruptedException, ExecutionException {
ExecutorService executor = Executors.newCachedThreadPool();
Future future = executor.submit(this::doSthAsync);
System.out.println("好,任务起来了,我去干别的先了");
for (int i = 0; i < 2; i++) {
System.out.println("主线程正在干活。。");
Thread.sleep(500L);
}
try {
System.out.println("异步任务返回了: " + future.get(2, TimeUnit.SECONDS));
} catch (TimeoutException e) {
System.out.println("异步任务出了异常!!!");
e.printStackTrace();
}
}
这里,就要说一下Future的局限性了。
- 我们很难表述
Future结果之间的依赖性。比如这样一个案例:“当长时间计算任务完成时,请将该计算的结果通知到另一个长时间运行的计算任务,这两个计算任务都完成后,将计算的结果与另一个查询操作结果合并”。 - 以下场景,
Future都难以表述:- 将两个异步计算合并为一个——这两个异步计算之间相互独立,同时第二个又依赖于第一个的结果。
- 等待Future集合中的所有任务都完成。
- 仅等待Future集合中最快结束的任务完成(有可能因为它们试图通过不同的方式计算同一个值),并返回它的结果。
- 通过编程方式完成一个Future任务的执行(即以手工设定异步操作结果的方式)。
- 应对Future的完成事件(即当Future的完成事件发生时会收到通知,并能使用Future计算的结果进行下一步的操作,不只是简单地阻塞等待操作的结果)。
(三)CompetableFuture与Future间的关系
CompetableFuture之于Future,相当于Stream之于Collection。
(四)CompetableFuture的一些用法
-
CompetableFuture的一些静态方法,直接简化创建Thread的逻辑:
public FuturegetPriceAsync(String product) { CompletableFuture futurePrice = new CompletableFuture<>(); new Thread(() -> { double price = calculatePrice(product); futurePrice.complete(price); }).start(); return futurePrice; } 直接变成一句话
public FuturegetPriceAsync(String product) { return CompletableFuture.supplyAsync(() -> calculatePrice(product)); } supplyAsync方法接受一个生产者(Supplier)作为参数,返回一个CompletableFuture对象,该对象完成异步执行后会读取调用生产者方法的返回值。生产者方法会交由ForkJoinPool池中的某个执行线程(Executor)运行,但是你也可以使用supplyAsync方法的重载版本,传递第二个参数指定不同的执行线程执行生产者方法。
-
再来一个例子,之前是一家Shop做异步处理,这还不能发挥此接口的最大效用,所以,这次,来一打Shops,比较最佳售价。
private final Listshops = Lists.newArrayList(new Shop("BestPrice"), new Shop("LetsSaveBig"), new Shop("MyFavoriteShop"), new Shop("BuyItAll")); 一般情况下,用并行流和CompletableFuture的异步效果是半斤八两的。
/// 并行流的方式 public ListfindPricesParallel(String product) { return shops.parallelStream() .map(shop -> String.format("%s 价格 %.2f", shop.getName() , shop.getPrice(product))) .collect(toList()); } // CompletableFuture的方式 public List findPricesFuture(String product) { List 默认
CompletableFuture.supplyAsyn()内部使用的线程池和ParallelStream使用的是同一个线程池,是默认的固定线程数量的线程池,这个线程数由CPU、JVM配置等决定。具体线程数取决于
Runtime.getRuntime().availableProcessors()的返回值但是,
CompletableFuture是可以配置supplyAsyn()中使用的ThreadFactory的,而ParallelStream是不能的。// 使用自定义的线程池 private final Executor executor = Executors.newFixedThreadPool(100, new ThreadFactory() { @Override public Thread newThread(Runnable runnable) { Thread t = new Thread(runnable); t.setDaemon(true); return t; } }); ... ... public ListfindPricesFuture(String product) { return shops.stream() .map(shop -> CompletableFuture.supplyAsync(() -> "" + shop.getPrice(), executor)) .collect(toList()) .stream() .map(CompletableFuture::join) .collect(toList()); }
并发,用并行流还是CompletableFuture?
| 情况 | 推荐 | 原因 |
|---|---|---|
| 如果你进行的是计算密集型的操作,并且没有I/O | Stream | 实现简单 |
| 如果你并行的工作单元还涉及等待I/O的操作(包括网络连接等待) | CompletableFuture | 高灵活性 |
新的日期和时间API
背景
- Java 1.0
- 特点:只有java.util.Date类
- 缺点:这个类无法表示日期,只能以毫秒的精度表示时间。而且,易用性差,如:
Date date = new Date(114, 2, 18);居然表示2014年3月18日。
- Java 1.1
- 更新:Date类中的很多方法被废弃了,取而代之的是java.util.Calendar类
- 缺点:Calendar类同样很难用,比如:
- 月份依旧是从0开始计算(不过,至少Calendar类拿掉了由1900年开始计算年份这一设计)
- DateFormat方法也有它自己的问题,它不是线程安全的。
LocalDate和LocalTime
相关类:
java.time.LocalDatejava.time.LocalTimejava.time.LocalDateTime
三个类都实现了各种基本计算方法、parse方法、比较方法, 以及各种静态方法。
LocalDate localDate = LocalDate.of(2018, 11, 25);
int year = localDate.getYear();// 2018
Month month = localDate.getMonth(); // 11
int day = localDate.getDayOfMonth(); // 25
DayOfWeek dow = localDate.getDayOfWeek(); // SUNDAY
int len = localDate.lengthOfMonth(); // 本月总天数: 30
boolean leap = localDate.isLeapYear(); // 是不是闰年: false
LocalDate localDate = LocalDate.now();
int year = localDate.get(ChronoField.YEAR);
int month = localDate.get(ChronoField.MONTH_OF_YEAR);
int day = localDate.get(ChronoField.DAY_OF_MONTH);
LocalTime localTime = LocalTime.now();
int hour = localTime.get(ChronoField.HOUR_OF_DAY);
int minute = localTime.get(ChronoField.MINUTE_OF_HOUR);
int second = localTime.get(ChronoField.SECOND_OF_MINUTE);
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println(localDateTime); // 2018-11-25T22:10:08.721
System.out.println(localDateTime.atZone(ZoneId.of("GMT"))); // 2018-11-25T22:11:08.778Z[GMT]
System.out.println(localDateTime.atOffset(ZoneOffset.UTC)); // 2018-11-25T22:11:44.362Z
机器的日期和时间格式
从计算机的角度来看,建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数。
-
相关类:
java.time.Instant
建模方式:以Unix元年时间(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的秒数进行计算。
作用:适用于计算机做高精度运算。
-
用法实例
- Instant.ofEpochSecond(秒/long, 纳秒/long)
Instant.ofEpochSecond(3); // 1970-01-01T00:00:03Z Instant.ofEpochSecond(3, 0); Instant.ofEpochSecond(2, 1_000_000_000); // 2 秒之后再加上100万纳秒(1秒) Instant.ofEpochSecond(4, -1_000_000_000); // 4秒之前的100万纳秒(1秒)
- Instant.ofEpochSecond(秒/long, 纳秒/long)
Duration/Period
Duration
- 作用:Duration类主要用于以秒和纳秒衡量时间的长短
- 注意:不要用机器时间相关API来计算Duration,你看不懂
而且,不要试图在这两类对象之间创建duration,会触发一个DateTimeException异常。而且,不要放一个LocalDate对象作为参数,不合适。LocalTime time1 = LocalTime.of(21, 50, 10); LocalTime time2 = LocalTime.of(22, 50, 10); LocalDateTime dateTime1 = LocalDateTime.of(2018, 11, 17, 21, 50, 10); LocalDateTime dateTime2 = LocalDateTime.of(2018, 11, 17, 23, 50, 10); Instant instant1 = Instant.ofEpochSecond(1000 * 60 * 2); Instant instant2 = Instant.ofEpochSecond(1000 * 60 * 3); // 可用工厂方法定义 Duration threeMinutes = Duration.ofMinutes(3); Duration fourMinutes = Duration.of(4, ChronoUnit.MINUTES); Duration d1 = Duration.between(time1, time2); Duration d2 = Duration.between(dateTime1, dateTime2); Duration d3 = Duration.between(instant1, instant2); // PT1H 相差1小时 System.out.println("d1:" + d1); // PT2H 相差2小时 System.out.println("d2:" + d2); // PT16H40M 相差16小时40分钟 System.out.println("d3:" + d3);
Period
- 作用:以年、月或者日的方式对多个时间单位建模
- 用法:
// 可用工厂方法定义 Period tenDay = Period.ofDays(10); Period threeWeeks = Period.ofWeeks(3); Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1); Period period = Period.between(LocalDate.of(2018, 11, 7), LocalDate.of(2018, 11, 17)); System.out.println("Period between:" + period); // P10D 相差10天
修改、构造时间
简单来说,API给我们划分了读取和修改两类方法:
- 读:
get - 修改:
with
下面这些方法都会生成一个新的时间对象,不会修改源对象:
// 2018-11-17
LocalDate date1 = LocalDate.of(2018, 11, 17);
// 2019-11-17
LocalDate date2 = date1.withYear(2019);
// 2019-11-25
LocalDate date3 = date2.withDayOfMonth(25);
// 2019-09-25
LocalDate date4 = date3.with(ChronoField.MONTH_OF_YEAR, 9);
特别:用TemporalAdjuster实现复杂操作
利用重写各种withXX方法,并自定义TemporalAdjuster参数,就能实现复杂的时间操作:
// 2018-11-17
LocalDate date1 = LocalDate.of(2018, 11, 17);
// 2018-11-19
LocalDate date2 = date1.with(TemporalAdjusters.nextOrSame(DayOfWeek.MONDAY));
// 2018-11-30
LocalDate date3 = date2.with(TemporalAdjusters.lastDayOfMonth());
我们看看这个用TemporalAdjuster接口,其实要自定义很简单,因为它只有一个接口:
@FunctionalInterface
public interface TemporalAdjuster {
Temporal adjustInto(Temporal temporal);
}
Format
- 相关类:
java.time.format.DateTimeFormatter-
java.time.format.DateTimeFormatterBuilder:用于实现更加复杂的格式化
- 特点:
- 所有的
DateTimeFormatter实例都是线程安全的。(所以,你能够以单例模式创建格式器实例,就像DateTimeFormatter所定义的那些常量,并能在多个线程间共享这些实例。)
- 所有的
// Date 转 String
LocalDate date1 = LocalDate.of(2018, 11, 17);
String s1 = date1.format(DateTimeFormatter.BASIC_ISO_DATE); // 20181117
String s2 = date1.format(DateTimeFormatter.ISO_LOCAL_DATE); // 2018-11-17
// String 转 Date
LocalDate date2 = LocalDate.parse("20181117", DateTimeFormatter.BASIC_ISO_DATE);
LocalDate date3 = LocalDate.parse("2018-11-17", DateTimeFormatter.ISO_LOCAL_DATE);
DateTimeFormatter italianFormatter = DateTimeFormatter.ofPattern("d. MMMM yyyy", Locale.ITALIAN);
LocalDate date5 = LocalDate.of(2018, 11, 16);
// 16. novembre 2018
String formattedDate2 = date5.format(italianFormatter);
// 2018-11-16
LocalDate date6 = LocalDate.parse(formattedDate2, italianFormatter);
用DateTimeFormatterBuilder实现细粒度格式化控制:
DateTimeFormatter italianFormatter = new DateTimeFormatterBuilder()
.appendText(ChronoField.DAY_OF_MONTH)
.appendLiteral(". ")
.appendText(ChronoField.MONTH_OF_YEAR)
.appendLiteral(" ")
.appendText(ChronoField.YEAR)
.parseCaseInsensitive()
.toFormatter(Locale.ITALIAN);
LocalDate now = LocalDate.now();
// 17. novembre 2018
String s1 = now.format(italianFormatter);
处理不同的时区和历法
- 相关类:
java.time.ZoneIdjava.time.ZoneOffset
- 特点:
- 新的
java.time.ZoneId类是老版java.util.TimeZone的替代品。 - 更容易处理日光时(Daylight Saving Time,DST)这种问题。
- 新的
// 地区ID都为“{区域}/{城市}”的格式
ZoneId shanghaiZone = ZoneId.of("Asia/Shanghai");
LocalDate date = LocalDate.of(2018, 11, 17);
ZonedDateTime zdt1 = date.atStartOfDay(shanghaiZone);
LocalDateTime dateTime = LocalDateTime.of(2018, 11, 27, 18, 13, 15);
ZonedDateTime zdt2 = dateTime.atZone(shanghaiZone);
Instant instant = Instant.now();
ZonedDateTime zdt3 = instant.atZone(shanghaiZone);
// LocalDateTime 转 Instant
LocalDateTime dateTime2 = LocalDateTime.of(2018, 11, 17, 18, 45);
ZoneOffset newYorkOffset = ZoneOffset.of("-05:00");
Instant instantFromDateTime = dateTime2.toInstant(newYorkOffset);
// 通过反向的方式得到LocalDateTime对象
Instant instant2 = Instant.now();
LocalDateTime timeFromInstant = LocalDateTime.ofInstant(instant2, shanghaiZone);
// OffsetDateTime,它使用ISO-8601的历法系统,以相对于UTC/格林尼治时间的偏差方式表示日期时间。
LocalDateTime dateTime3 = LocalDateTime.of(2018, 11, 17, 18, 45);
OffsetDateTime offsetDateTime = OffsetDateTime.of(dateTime3, newYorkOffset);