数据仓库是面向主题的、集成的、时变的和非易失的有组织的数据集合,支持管理决策制定。不同于面向OLTP(On-Line Transaction Processing)数据库建设,数据仓库为OLAP(On-Line Analytical Processing)而生。
本文着手规划cover糖豆全业务线的数据仓库建设。先给出糖豆数仓模型,给出糖豆数仓的理论依据;再在此基础上根据糖豆各业务线的实际需求,给出各个业务主题的具体数据集市建设模型。
一、数据仓库的分层结构
一般情况下,数据仓库往往采用三层结构。底层是数据仓库服务器,在我们这里就是由hive cover的分布式文件存储系统。中间层是OLAP服务器。上层是用户,包括查询和报表工具。
联机分析处理(OLAP)可以在使用多维数据模型的数据仓库或数据集市上进行。典型的 OLAP操作包括上卷、下钻(钻过、钻透)、切片和切块、转轴(旋转),以及求等级、计算平均值和增长率等统计操作。使用数据立方体结构,OLAP 操作可以有效地实现。
OLAP服务器可以是关系OLAP(ROLAP),多维OLAP(MOLAP),或混合OLAP(HOLAP)。ROLAP服务器使用扩充的关系 DBMS,将多维数据上的 OLAP 操作映射成标准的关系操作。MOLAP 服务器直接将多维数据视图映射到数组结构。HOLAP 是 ROLAP 和 MOLAP 的结合。例如,它可以对历史数据使用 ROLAP,而将频繁访问的数据放在一个分离的 MOLAP 存储中。
关于这部分内容更多的了解可以参考《数据挖掘概念与技术》中关于数据仓库的介绍。在本规划中着重介绍的是底层——数据仓库服务器层,也就是hive数据仓库的建设。重点涉及基础层(ODS)、中间层(EDW)、集市层(ADM)的规划建设。中间层(OLAP服务器层)与顶层(前端可视化层),暂不考虑,将来可能会考虑采用业界开源/免费的集成解决方案,如airbnb开源的Superset (之前叫做Caravel / Panoramix)、一直免费的saiku。
hive数据仓库部分,我们将按传统数据仓库分层思想,分为三层:
- ODS(Operation Data Storage)层——操作数据存储层,在这里就是原始数据层。主要包括三部分数据,从业务服务器实时采集的业务原始日志、对业务原始日志解析后结构化的日志宽表、通过sqoop从业务数据库导入的业务数据。这层数据处理原则是不丢失,尽量保证数据的原貌。除了不能解析的异常日志,尽量保证日志条数不丢失;日志字段不清洗,不care日志字段的具体取值是否合法,只负责字段的结构化存储。这部分数据需要全量压缩保存。这层存储的是最细粒度的数据。
- EDW(Enterprise Data Warehouse)层——企业级数据仓库层,在这里就是中间基础数据层。EDW在传统行业一般是指整个数仓,甚至包括ODS层;在大型的集团公司,EDW一般指各独立业务线的数仓,如财务数仓,交易数仓,日志数仓。在我们这里,EDW主要是日志数仓明细,也有称作DWB(DataWare Base)层的。中间基础数据层的数据应该是一致的、准确的、干净的,它对原始数据层进行了清洗转换。这层存储的也是最细粒度的数据,和ODS层相同。
- ADM(Aggregative Data Model)层——聚合数据层,在这里就是数据集市层。数据集市层对EDW层的数据做不同程度的聚合汇总,已经不存在明显数据。这层数据从纵向上讲是面向业务主题来组织的,用来支撑多维分析,我们采用星形结构。这层中每张事实表中的一行都是一条用户操作记录的聚合,比如用户在某个模块观看某个视频的总时长。
二、糖豆数仓业务模型
1、业务线梳理
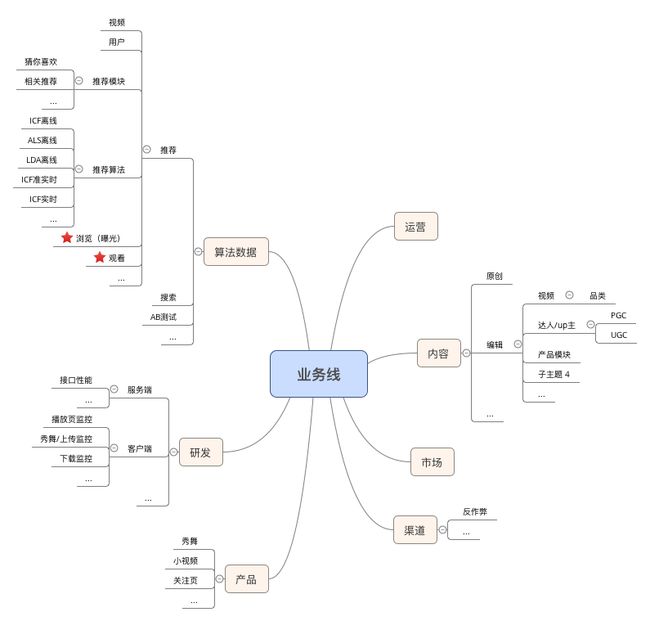
按目前发展状况,根据职能梳理的业务线如下图所示。其中大部分业务线需要根据具体业务需求规划数据集市层建设。优先挑选重要紧急的业务线做。
2、业务主题建模
以推荐业务为主线举例:
推荐目前的产品形态为【猜你喜欢】(包括离线/准实时/实时)与【相关推荐】。推荐业务目前最重要的数据需求之一就是效果对比评估。
所以对于推荐业务主题域,主要的事实表就是用户在推荐产品模块内的操作数据,包括用户的浏览,点击播放,后续的关注、评论等。
在业务建模阶段,我们倾向于使用实体建模法,实体建模可以很轻松的完成对现实世界的抽象,把整个业务划分成一个个的实体,而每个实体之间的关系,以及针对这些关系的说明就是我们数据建模需要做的工作。实体建模的具体介绍可以参考链接1。在实体建模中,任何一个业务都可以划分为3个部分,实体,事件和说明:
实体,主要指领域模型中特定的概念主体,指发生业务关系的对象。
事件,主要指概念主体之间完成一次业务流程的过程,特指特定的业务过程。
-
说明,主要是针对实体和事件的特殊说明。
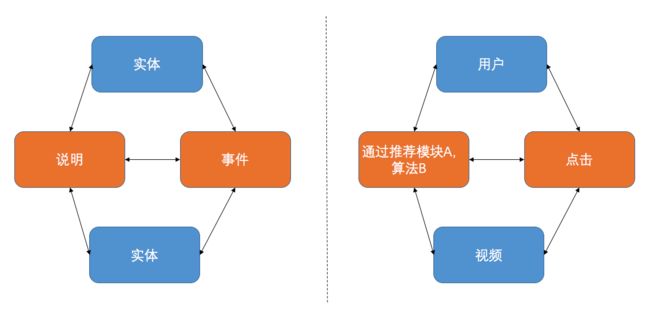
如图所示,我们描述了一个简单的事实:用户在推荐模块A,点击了算法B推荐的视频。以这个业务事实为例,我们可以把“用户”,“视频 ”看成是一个实体,“点击”描述的是一个业务过程,我们在这里可以抽象为一个具体“事件”,而“在推荐模块A,通过算法B”则可以看成是事件“点击”的一个说明。
该主题域内的实体对象有【视频】、【用户】、【推荐算法】、【推荐模块】等,事件有【浏览/曝光】、【播放/点击】。围绕浏览与点击两个事件,组合视频、用户、算法、模块等实体间的关系,就会发现我们的业务相当简单,可以梳理出以下推荐业务事实:
- 用户在某推荐模块浏览某推荐算法推荐的视频
- 被某推荐算法推荐的视频在某推荐模块被用户浏览
- 用户在某推荐模块播放某推荐算法推荐的视频
- 用户在某推荐模块播放某推荐算法推荐的视频时长
基于上面两个基础事实,我们可以再聚合。在推荐评估中,我们非常关注某个算法表现或某个推荐模块的表现。所以,以推荐模块、推荐算法为实体,我们可以梳理出以下事实:
- 推荐模块内各算法推荐的视频的曝光/播放
- 推荐算法在不同推荐模块的推荐视频的曝光/播放
梳理出这些基础业务事实,我们再来看各业务实体的属性/维度。比如,视频这个实体,有时长、up主/作者…;用户实体有是否注册、UGC/PGC、地域等属性。在不同的业务主体域内,同一实体可能有不同的属性/维度,比如用户实体在推荐业务中,我们可能会关注他的画像属性,如兴趣偏好;而在内容编辑业务中,对于用户实体肯定要知道ta是否是up主,是UGC还是PGC。
所以在不同的业务域内,同一实体内的维表可能有不同的字段,这个就是下一步维度建模涉及的问题。维度建模需要手动维护维度表数据的一致性。
三、糖豆数仓维度建模(事实星座模型)
上面以推荐业务主线为例,我们分析了推荐主题的业务模型。上面的建模分析仍处于数据仓库建模的业务建模或领域建模阶段,该节段仍然是对现实业务的初步抽象分析。数仓建设最重要的步骤是逻辑建模,最终的代码实施则是物理建模阶段。逻辑建模直接决定了物理建模的成败,它决定物理模型实现的难度与是否能满足业务分析需求。
糖豆数仓的逻辑建模我们采用最流行的多维分析模型——星形模型。通常,多维数据模型用于数据仓库和数据集市的设计。这种模型采用星形模式、雪花模式或事实星座模式。多维数据模型的核心是数据立方体。数据立方体由大量事实(或度量)和许多维度组成。维度是一个组织想要记录的实体或透视,是自然分层的。支撑多维分析的关键就在于维度建模。
进行维度建模之前,我们首先了解两个概念:
事实表——发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件。在上面的业务建模中,我们已经梳理推荐业务的业务事实,对应的,就是一张张事实表。
维度表/维表——每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。 维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。
还以推荐业务为例,我们来分析推荐主题的维度建模。考虑用户在推荐模块点击视频的事实。我们建一个大的,包含大量数据、不含冗余数据的中心表(事实表)——推荐点击表;一组小的附属表(维表),每个维度都有一个单独的维表。假设推荐点击事实表有用户、地域、版本、视频、ABTag、模块、算法等维度,包含点击次数一个度量。为尽量减小事实表的尺寸,事实表中的维度都用标示id。每个维表包含一组属性,这些属性可能有一定程度的冗余。例如,地域中广州和深圳都属于华南地区一线城市,区域和城市级别属性会有冗余。多个事实表可能需要共享维表,如推荐点击事实表和推荐播放事实表就会共享地域、用户、版本等许多维表。这种多个事实表可以共享维表的模式可以看做是星形模式的合集,因此被称作星系模式,或者叫做事实星座模型。在我们的业务中,多维建模就是根据业务事实,建立这种事实星座模型。

图中示例的推荐点击事实表是只做了轻度聚合的事实表,还包含很多细粒度的数据,如用户diu。在数据集市中,往往根据业务主题纵向发展,做不同层次的聚合。我们对上述事实表,对用户做聚合,就能得到视频被点击人数和次数的二次聚合事实表。对用户浏览视频的事实表做聚合,得到视频被曝光人数和次数的事实表。两者关联就得到视频的点击率。所以,这些基础的、粒度最细的事实表的建设对于面向主题的数据集市的建设非常重要。在这些大事实表的基础上,对各种维度做不同粒度的聚合,就构成了立体式有各种粒度数据的数据集市。在聚合的过程总对于次数这种度量,可以做任意维度的组合聚合;而对于人数这种涉及去重的度量,不同维度的聚合只能做独立的去重计算。所以对于去重聚合,要事先考虑好需要用到的维度,再做计算。
四、糖豆数仓规划
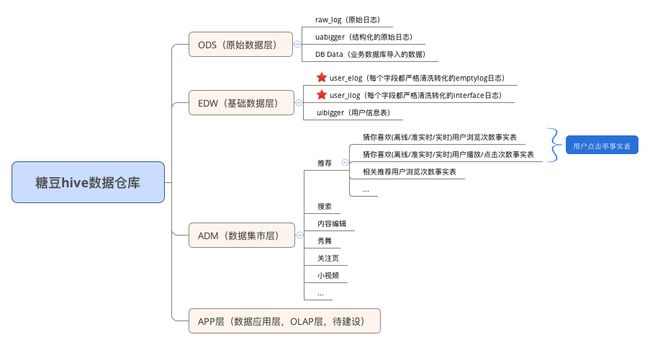
根据目前糖豆业务线,结合目前已有的数据表,糖豆数仓的大体构成如下图。
参考
1、浅谈数据仓库建设中的数据建模方法
2、数据挖掘概念与技术
3、漫谈数据仓库之维度建模