梅尔倒谱系数(MFCC)
梅尔倒谱系数(Mel-scale FrequencyCepstral Coefficients,简称MFCC)。依据人的听觉实验结果来分析语音的频谱,
MFCC分析依据的听觉机理有两个
第一Mel scale:人耳感知的声音频率和声音的实际频率并不是线性的,有下面公式
$$f_{mel}=2595*\log _{10}(1+\frac{f}{700})$$
$$f = 700 (10^{f_{mel}/2595} - 1)$$
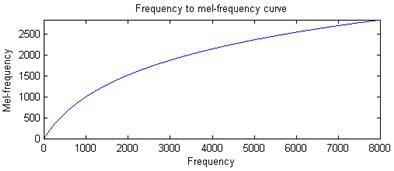
式中$f_{mel}$是以梅尔(Mel)为单位的感知频域(简称梅尔频域),$f$是以$Hz$为单位的实际语音频率。$f_{mel}$与$f$的关系曲线如下图所示,若能将语音信号的频域变换为感知频域中,能更好的模拟听觉过程的处理。
第二临界带(Critical Band):把进入人耳的声音频率用临界带进行划分,将语音在频域上就被划分成一系列的频率群,组成了滤波器组,即Mel滤波器组。
研究表明,人耳对不同频率的声波有不同的听觉敏感度。从200Hz到5000Hz的语音信号对语音的清晰度影响较大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。
由于频率较低的声音(低音)在内耳蜗基底膜上行波传递距离大于频率较高的声音(高音),因此低音容易掩蔽高音。低音掩蔽的临界带宽较高频要小。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种参数比基于声道模型的LPCC相比具有更好的鲁棒性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
求MFCC的步骤
- 将信号帧化为短帧
- 对于每个帧,计算每帧语音的功率谱(周期图估计)
- 将mel滤波器组应用于功率谱,求滤波器组的能量,将每个滤波器中的能量相加
- 取所有滤波器组能量的对数
- DCT变换
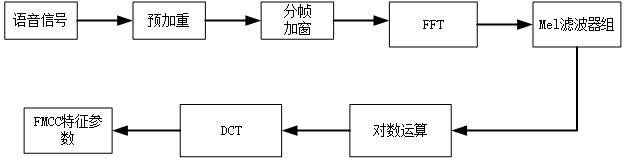
MFCC的提取过程
预处理
预处理包括预加重、分帧、加窗函数。假设我们的语音信号采样频率为8000Hz,语音数据在这里获取
import numpy import scipy.io.wavfile from scipy.fftpack import dct sample_rate, signal = scipy.io.wavfile.read('OSR_us_000_0010_8k.wav') signal = signal[0:int(3.5 * sample_rate)] # 我们只取前3.5s
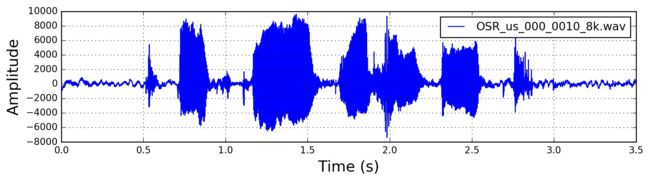
时域中的语音信号
预加重
预加重滤波器在以下几个方面很有用:
- 平衡频谱,因为高频通常与较低频率相比具有较小的幅度,
- 避免在傅里叶变换操作期间的数值问题和
- 改善信号 - 噪声比(SNR)
- 消除发声过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
预加重处理其实是将语音信号通过一个高通滤波器:
$$y(t) = x(t) - \alpha x(t-1)$$
其中滤波器系数(α)的通常为0.95或0.97,这里取pre_emphasis =0.97:
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
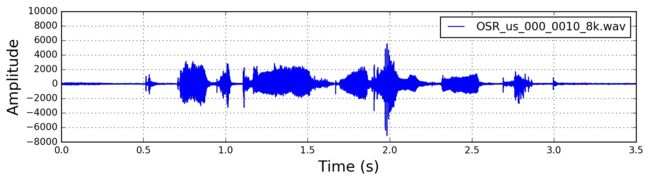
预加重后的时域信号
分帧
在预加重之后,我们需要将信号分成短时帧。因此在大多数情况下,语音信号是非平稳的,对整个信号进行傅里叶变换是没有意义的,因为我们会随着时间的推移丢失信号的频率轮廓。语音信号是短时平稳信号。因此我们在短时帧上进行傅里叶变换,通过连接相邻帧来获得信号频率轮廓的良好近似。
将信号帧化为20-40 ms帧。25毫秒是标准的frame_size = 0.025。这意味着16kHz信号的帧长度为0.025 * 8000 = 200个采样点。帧移通常为10m sframe_stride = 0.01(80个采样点),为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了120个取样点,通常约为每帧语音的1/2或1/3。第一个语音帧0开始,下一个语音帧从160开始,直到到达语音文件的末尾。如果语音文件没有划分为偶数个帧,则用零填充它以使其完成。
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate # 从秒转换为采样点 signal_length = len(emphasized_signal) frame_length = int(round(frame_length)) frame_step = int(round(frame_step)) # 确保我们至少有1帧 num_frames = int(numpy.ceil(float(numpy.abs(signal_length - frame_length)) / frame_step)) pad_signal_length = num_frames * frame_step + frame_length z = numpy.zeros((pad_signal_length - signal_length)) # 填充信号,确保所有帧的采样数相等,而不从原始信号中截断任何采样 pad_signal = numpy.append(emphasized_signal, z) indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T frames = pad_signal[indices.astype(numpy.int32, copy=False)]
加窗
将每一帧乘以汉明窗,以增加帧左端和右端的连续性。抵消fft假设的数据是无限的,并减少频谱泄漏。
假设分帧后的信号为S(n), n=0,1…,N-1, N为窗口长度,那么乘上汉明窗
$${S}'(n)=S(n)\times W(n)$$
后 ,汉明窗W(n)形式如下:
$$W\left( n,a \right)=\left( 1-a \right)-a\times \cos \left( \frac{2\pi n}{N-1} \right),0\le n\le N-1$$
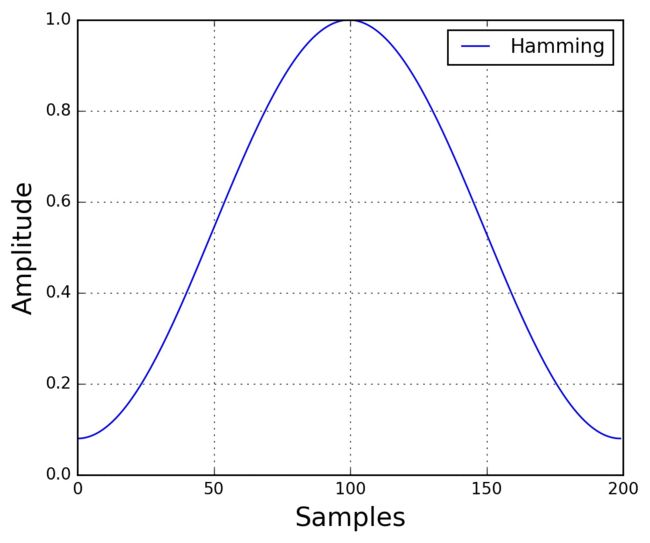
frames *= numpy.hamming(frame_length) # frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # 内部实现
FFT
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。对分帧加窗后的各帧信号进行做一个N点FFT来计算频谱,也称为短时傅立叶变换(STFT),其中N通常为256或512,NFFT=512;
$$S_i(k)=\sum_{n=1}^{N}s_i(n)e^{-j2\pi kn/N} 1\le k \le K$$
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # fft的幅度
能量谱
计算功率谱(周期图),对语音信号的频谱取模平方(取对数或者去平方,因为频率不可能为负,负值要舍去)得到语音信号的谱线能量。
$$P = \frac{|FFT(x_i)|^2}{N}$$
其中,$X_i$是信号X的第$i$帧,这可以用以下几行来实现:
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # 功率谱
使用Mel刻度滤波器组过滤
计算通过Mel滤波器,将功率谱通过一组Mel刻度(这里取40个)的三角滤波器组提取带宽。
这个Mel滤波器组就像人类的听觉感知系统(耳朵),人耳只关注某些特定的频率分量(人的听觉对频率是有选择性的)。它对不同频率信号的灵敏度是不同的,换言之,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。
我们可以用下面的公式,在语音频率和Mel频率间转换
$$f_{mel}=2595*\log _{10}(1+\frac{f}{700})$$
$$f = 700 (10^{f_{mel}/2595} - 1)$$
定义一个有M个三角滤波器的滤波器组(滤波器的个数和临界带的个数相近),中心频率为f(m) ,中心频率响应为1,并且朝向0线性减小,直到它达到响应为0的两个相邻滤波器的中心频率,如下图所示。M通常取22-40,26是标准,本文取nfilt = 40。各f(m)之间的间隔随着m值的增大而增宽,如图所示:
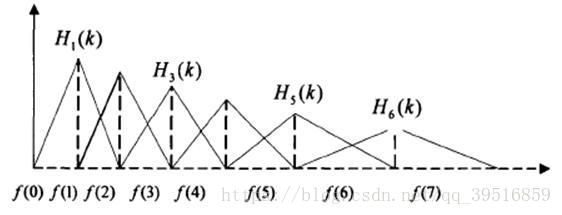
在Mel-Scale上的滤波器组
这可以通过以下等式建模,三角滤波器的频率响应定义为:
$$H_m(k) =
\begin{cases}
\hfill 0 \hfill & k < f(m - 1) \\
\\
\hfill \dfrac{k - f(m - 1)}{f(m) - f(m - 1)} \hfill & f(m - 1) \leq k < f(m) \\
\\
\hfill 1 \hfill & k = f(m) \\
\\
\hfill \dfrac{f(m + 1) - k}{f(m + 1) - f(m)} \hfill & f(m) < k \leq f(m + 1) \\
\\
\hfill 0 \hfill & k > f(m + 1) \\
\end{cases}$$
对于FFT得到的幅度谱,分别跟每一个滤波器进行频率相乘累加,得到的值即为该帧数据在在该滤波器对应频段的能量值。如果滤波器的个数为22,那么此时应该得到22个能量值
low_freq_mel = 0 high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # 将Hz转换为Mel mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 使得Mel scale间距相等 hz_points = (700 * (10**(mel_points / 2595) - 1)) # 将Mel转换为Hz bin = numpy.floor((NFFT + 1) * hz_points / sample_rate) fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1)))) for m in range(1, nfilt + 1): f_m_minus = int(bin[m - 1]) # 左 f_m = int(bin[m]) # 中 f_m_plus = int(bin[m + 1]) # 右 for k in range(f_m_minus, f_m): fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1]) for k in range(f_m, f_m_plus): fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m]) filter_banks = numpy.dot(pow_frames, fbank.T) filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # 数值稳定性 filter_banks = 20 * numpy.log10(filter_banks) # dB
信号的功率谱经过滤波器组后,得到的谱图为:
信号的频谱图
如果Mel scale滤波器组是所需的特征,那么我们可以跳过均值归一化。
能量值取对数
由于人耳对声音的感知并不是线性的,用log这种非线性关系更好描述。取完log以后才可以进行倒谱分析。
$$s\left( m \right)=\ln \left( {{\sum\limits_{K=0}^{N-1}{\left| {{X}_{a}}\left( k \right) \right|}}^{2}}{{H}_{m}}\left( k \right) \right),0\le m\le M$$
离散余弦变换(DCT)
前一步骤中计算的滤波器组系数是高度相关的,这在一些机器学习算法中可能是有问题的。因此,我们可以应用离散余弦变换(DCT)去相关滤波器组系数并产生滤波器组的压缩表示。通常,对于自动语音识别(ASR),保留所得到的倒频谱系数2-13,其余部分被丢弃; num_ceps = 12。丢弃其他系数的原因是它们代表滤波器组系数的快速变化,并且这些精细的细节对自动语音识别(ASR)没有贡献。
$$C(n)=\sum\limits_{m=0}^{N-1}{s( m)\cos( \frac{\pi n( m-0.5)}{M} )},n=1,2,...,L$$
L阶指MFCC系数阶数,通常取2-13。这里M是三角滤波器个数。
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)] # 保持在2-13
可以将正弦提升器(Liftering在倒谱域中进行过滤。 注意在谱图和倒谱图中分别使用filtering和liftering)应用于MFCC以去强调更高的MFCC,其已经声称可以改善噪声信号中的语音识别。
(nframes, ncoeff) = mfcc.shape n = numpy.arange(ncoeff) lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter) mfcc *= lift
由此产生的MFCC:
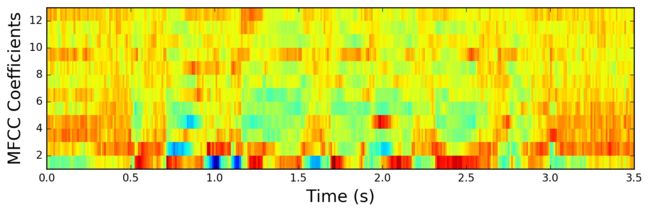
MFCCs
均值归一化
如前所述,为了平衡频谱并改善信噪比(SNR),我们可以简单地从所有帧中减去每个系数的平均值。
filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
均值归一化滤波器组:
归一化滤波器数组
同样对于MFCC:
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
均值归一化MFCC:
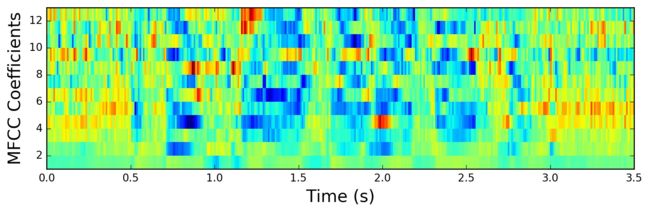
标准的MFCC
总结
在这篇文章中,我们探讨了计算Mel标度滤波器组和Mel频率倒谱系数(MFCC)的过程。
到目前为止,计算滤波器组和MFCC的步骤是根据其动机和实现进行讨论的。值得注意的是,计算滤波器组所需的所有步骤都是由语音信号的性质和人类对这些信号的感知所驱动的。相反,计算MFCC所需的额外步骤是由一些机器学习算法的限制所驱动的。需要离散余弦变换(DCT)来去相关滤波器组系数,该过程也称为白化。特别是,当高斯混合模型 - 隐马尔可夫模型(GMMs-HMMs)非常受欢迎时,MFCC非常受欢迎,MFCC和GMM-HMM共同演化为自动语音识别(ASR)的标准方式2。随着深度学习在语音系统中的出现,人们可能会质疑MFCC是否仍然是正确的选择,因为深度神经网络不太容易受到高度相关输入的影响,因此离散余弦变换(DCT)不再是必要的步骤。值得注意的是,离散余弦变换(DCT)是一种线性变换,因此在语音信号中丢弃一些高度非线性的信息是不可取的。
质疑傅里叶变换是否是必要的操作是明智的。鉴于傅立叶变换本身也是线性运算,忽略它并尝试直接从时域中的信号中学习可能是有益的。实际上,最近的一些工作已经尝试过,并且报告了积极的结果。然而,傅立叶变换操作是很难学习的操作,可能会增加实现相同性能所需的数据量和模型复杂性。此外,在进行短时傅里叶变换(stft)时,我们假设信号在这一短时间内是平稳的,因此傅里叶变换的线性不会构成一个关键问题。
用librosa提取MFCC特征
MFCC特征是一种在自动语音识别和说话人识别中广泛使用的特征。在librosa中,提取MFCC特征只需要一个函数:
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', **kwargs)
参数:
- y:音频时间序列
- sr:音频的采样率
- S:np.ndarray,对数功率梅尔频谱,这个函数既可以支持时间序列输入也可以支持频谱输入,都是返回MFCC系数。
- n_mfcc:int>0,要返回的MFCC数,scale滤波器组的个数,通常取22~40,本文取40
- dct_type:None, or {1, 2, 3} 离散余弦变换(DCT)类型。默认情况下,使用DCT类型2。
- norm: None or ‘ortho’ 规范。如果dct_type为2或3,则设置norm =’ortho’使用正交DCT基础。norm不支持dct_type = 1。
返回:
M:np.ndarray MFCC序列
import librosa y, sr = librosa.load('./train_nb.wav', sr=16000) # 提取 MFCC feature mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40) print(mfccs.shape) # (40, 65)
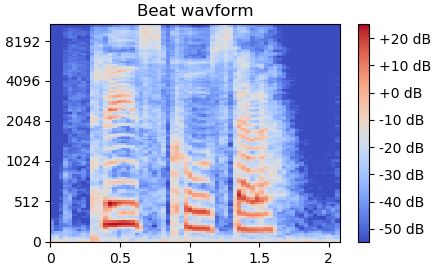
绘制频谱图
Librosa有显示频谱图波形函数specshow( ):
import matplotlib.pyplot as plt import librosa y, sr = librosa.load('./train_wb.wav', sr=16000) # 提取 mel spectrogram feature melspec = librosa.feature.melspectrogram(y, sr, n_fft=1024, hop_length=512, n_mels=128) logmelspec = librosa.power_to_db(melspec) # 转换为对数刻度 # 绘制 mel 频谱图 plt.figure() librosa.display.specshow(logmelspec, sr=sr, x_axis='time', y_axis='mel') plt.colorbar(format='%+2.0f dB') # 右边的色度条 plt.title('Beat wavform') plt.show()
参考文献
MFCC特征参数提取(一)(基于MATLAB和Python实现)
http://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
Mel Frequency Cepstral Coefficient (MFCC) tutorial
音频处理库—librosa的安装与使用