一 操作系统层面的优化
1 交换分区与内存的比例
vm swappiness
设置如果交换分区太大,则会造成过多占用交换分区内存,导致速度变慢,如果设置过小,则可能会造成内存溢出OOM
对于专用于MYSQL的系统,一般设置为1,对于一般的系统建议设置为10,
临时修改swappiness

永久修改 ![]()


2 I/O 调度
首选 deadline ,其次是noop
文件系统首选是xfs,其次是ext4 ,因为xfs的结构更贴近与mysql的B+树方式
查看系统支持的I/O调度方式
查看当前系统的I/O调度方式
临时修改I/O调度算法
永久修改I/O调度算法![]()
![]()
注意 :
此处boot下的文件不同的Linux版本不同,请根据自己的实际情况选择
需要重启服务器方可生效
![]()
二 数据库配置文件层面优化
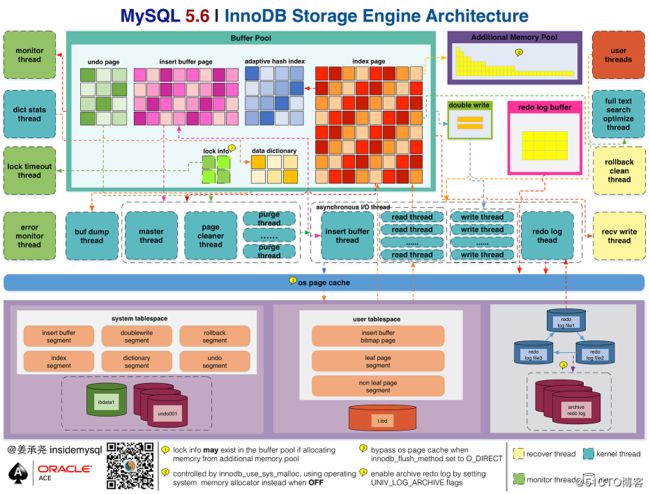
1 innodb存储引擎图集
2 innodb_buffer_pool_size
默认是128M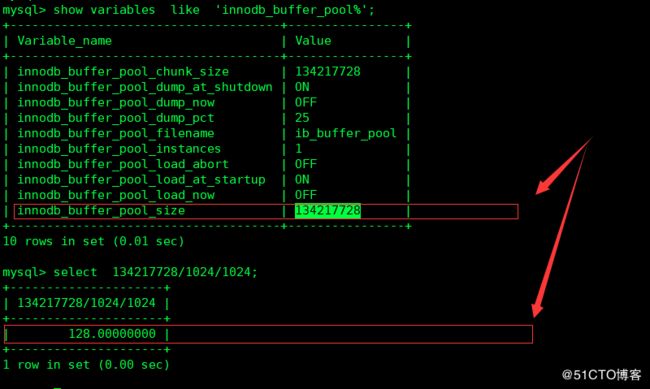
一般的,只跑数据库的服务器其大小设置为内存的50%-80%。
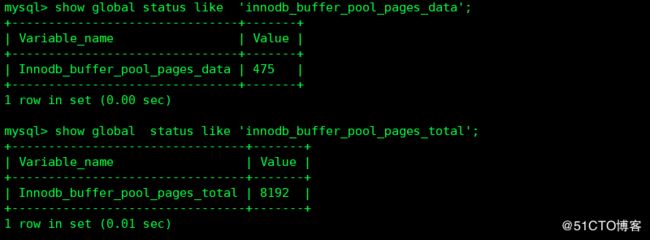

具体限制如下:
计算Innodb_buffer_pool_pages_data/Innodb_buffer_pool_pages_total*100%
当结果 > 95% 则增加 innodb_buffer_pool_size, 建议使用物理内存的 75%
当结果 < 95% 则减少 innodb_buffer_pool_size
建议设置大小为: Innodb_buffer_pool_pages_data* Innodb_page_size* 1.05 / (1024*1024*1024)
命令配置:
mysql 中配置命令:SET GLOBAL innodb_buffer_pool_size= 256M文件中配置命令:innodb_buffer_pool_size=256M
3 表空间相关
1 独占表空间
每个表都将会形成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.idb 文件,其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下他的存储是在表的存储位置中。
独占表空间:默认的文件名为:ibdata1 初始化为12M。
独占表空间在数据库启动时就已经占用内存为12M
查看默认使用的表空间方式
如果为ON,则表示其是独立表空间,如果是oFF,则表示其是共享表空间
配置文件中配置:
此配置只能在配置文件中实现,并且需要进行重启。innodb_data_file_path=ibdata1:12M;ibdata2:12M:autoextend
独占表空间可以配置多个,当每个文件都满了的时候,ibdata2会自动扩展
如果用 autoextend 选项描述最后一个数据文件,当 InnoDB 用尽所有表自由空间后将会自动扩充最后一个数据文件,每次增量为 8 MB。当存储空间满了的时候,可以在其他的磁盘上添加数据文件
添加事例:
pathtodatafile:sizespecification;pathtodatafile:sizespec;.;pathtodatafile:sizespec[:autoextend[:max:sizespecification]]
2 共享表空间
innodb 所有数据都保存在一个单独的表空间里面,而这个表空间可以由多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小限制,而是其自身的限制,其表空间的最大限制为64TB,包含其其他索引大小。
3 两者的优缺点:
共享表空间:
优点:
可以将表空间分成多个文件存放到各个磁盘上,数据和文件放在一起方便管理,
缺点:
1 所有的数据和索引放置在一个恩建中会造成混合存储,
2 当数据量非常大的时候,表做了大量删除操作后表空间将会出现大量的空隙,对于统计分析数据十分不利。其不能进行回缩,当出现临时创建索引或是创建一个临时的操作表空间扩大后,就是删除相关的表也没有办法回缩那部分空间。
独占表空间:
优点:
每个表都有自己独立的表空间,每个表的数据和索引都会存储在自己的表空间中,可以实现单表在不同数据库中一定,空间可以通过drop进行回收,如果对于统计分析或日志表,删除大量数据可以通过:after table TableName engine=innodb 回收表空间
缺点:
但如果单表增加过大,当单表占用空间过大时,存储空间不足,只能从操作系统层面思考
4 共享表和独立表空间之间的转换
修改配置文件
innodb_file_per_table=1 #表示为独占表空间
innodb_file_per_table=0 #表示为共享表空间运行中修改: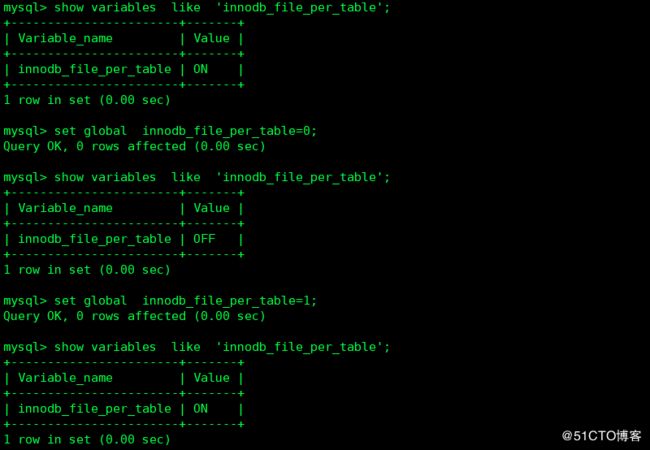
4 缓冲相关
1 查询缓冲
用于对mysql 查询结果进行缓存,如果下次收到同样的查询请求,不会再执行实际的查询处理,而是直接返回结果,这样可以提高查询效率,并提高系统性能,前提是有很多的查询而修改很少,如果修改很多,则没有必要开启此功能。
默认查询缓冲是关闭的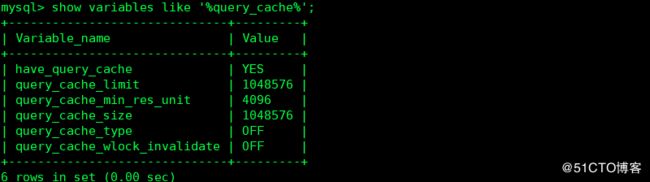
配置方式
query_cache_type=1 #如果设置为0,则表示禁用,如果设置为1,将会缓存所有的结果,除非使用了SQL_NO_CACHE,如果设置为2,表示只缓存在select语句中通过SQL_CACHE 指定需要缓存的查询
query_cache_size=20M #表示缓存设置的大小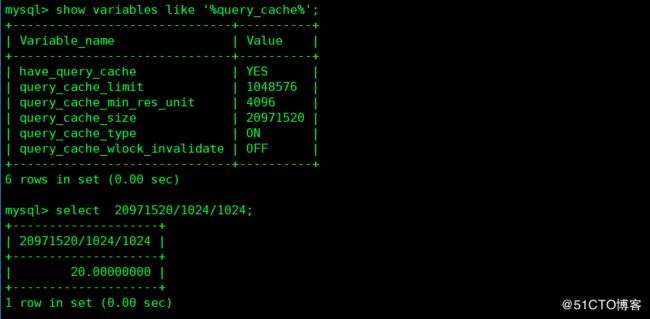
2 排序缓冲
排序是数据库中一个基本功能,用户通过order by 语句能达到将指定的结果集排序的目的,不仅仅是order by,group by, distinct 语句也隐含使用排序。
mysql内部实现排序的方式主要有3种:常规排序、优化排序、优先队列排序,主要涉及3种排序算法:快速排序,归并排序和堆排序。
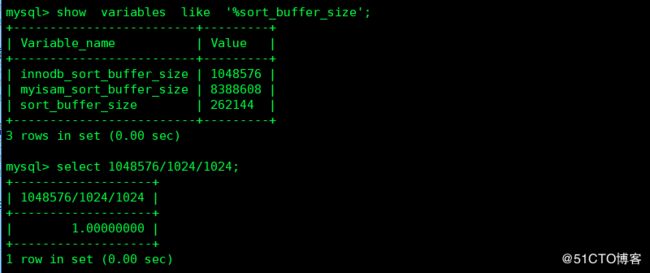
是否使用文件排序主要看sort buffer 是否能够容下需要排序的结果集,这个buffer的大小由sort_buffer_size 参数控制,
1 普通排序缓存
排序缓存是会话缓存,如果客户机向服务器发送的SQL语句中含有设计排序的order by 或者 group by 字句,mysql 就会选择相应的排序算法,在普通排序索引上进行排序,提升排序速度,普通排序索引大小由sort_buffer_size参数决定,如果想要提升排序速度,首先应加上合适的索引,此后则增大排序缓冲。
2 优化排序规则
优化排序规则相对于常规排序,减少了第二次IO,主要区别在于,一次性取出SQL中出现的所有字段放入sort buffer 中而不是只取排序需要的字段,由于sort buffer中包含了查询所需的所有字段,因此排序完成后可以直接返回结果,无需二次取数据,所以如果此时sort_buffer 不够大,则可能导致需要写临时文件,造成额外EI,当然在mysql中提供了max_length_for_sort_data,只有当排序sql里出现的所有字段小于max_length_for_sort_data 时,才能采用优化排序的方式,否则只能用常规排序方式。

max_sort_length:
order by 或者group by 的时候使用该列的前max_sort_lenth 字节进行排序,操作完成后,将此排序信息记录到本次会话的状态中

3 优先队列排序:为了得到最终的排序结果,我们都需要将所有满足条件的记录进行排序才能返回,那么相对于优化排序方式,还有优化空间,5.6版本针对order by limit M,N 语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆栈排序实现。详情请见:https://www.cnblogs.com/zhoujinyi/p/5437289.html
查看排序统计信息:
sort_merge_passes: 使用临时文件完成排序操作的次数,mysql在进行排序操作时,首先尝试在普通排序缓存中完成排序,如果缓存空间不够,mysql将利用缓存进行多次排序,并把每次排序的结果存放在临时文件中,最后再把临时文件中的数据进行排序,sort_merge_passes 值就是记录了使用文件进行排序的次数,由于文件排序要涉及到读文件,所以其消耗系统资源较大,因此如果sort_merge_passes很大,就表示需要注意sort_buffer_size。
sort_range
使用范围排序的次数
sort_rows
已经排序的记录行数
sort_scan
通过全表扫描完成排序的次数
3 join连接缓冲
join 缓存是会话缓存,如果两张表相连,但是无法使用索引,mysql将为每张表分配join连接缓存。

5 统计大小
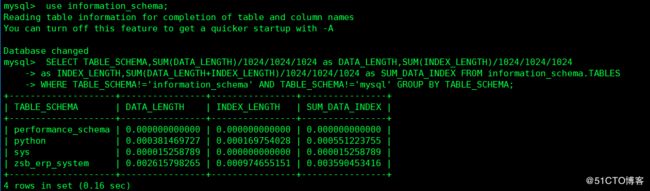
1 统计每个库大小:
命令:
use information_schema;
SELECT TABLE_SCHEMA,SUM(DATA_LENGTH)/1024/1024/1024 as DATA_LENGTH,SUM(INDEX_LENGTH)/1024/1024/1024
as INDEX_LENGTH,SUM(DATA_LENGTH+INDEX_LENGTH)/1024/1024/1024 as SUM_DATA_INDEX FROM information_schema.TABLES
WHERE TABLE_SCHEMA!='information_schema' AND TABLE_SCHEMA!='mysql' GROUP BY TABLE_SCHEMA;2 统计所有数据库的大小

6 事务的隔离级别
默认使用的是RR 可重复读
| 事物隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重读读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
RU 的作用是当终端A修改的数据没有提交,但终端B已经能够查询到终端A修改的数据。如果A 因某种情况而撤销操作,则B读取到的数据将会变成脏数据。
RC 的作用是当A修改的数据没有提交,B 读取不到A 已经修改的数据,此时解决了脏读,但是一旦A的数据提交,B会立刻读取到A的数据,此时。读取到的数据将会产生不一致现象,此时成为重复读。
RR 客户端A查看数据,客户端B修改数据并提交,客户端A此时查询到的数据和之前B没有修改查询到的数据一致,不可重复读解决,可重复读的隔离级别下使用了MVCC机制,A事物中读取的是记录的快照版本,而非最新的版本,B事物的更新是创建了一个新版本来更新,不同事物的读和写是分离的。
SZ 同一时刻只能查看一张表,表被锁了,因此不会出现幻读,但此时并发低,很少用到。
7 redo 日志相关
1 redo log 日志刷新
1代表实时刷新 (默认配置)
0每隔1秒刷新一次
2交由操作系统管理(判断当前的繁忙程度来进行刷新)
2 innodb_log_buffer_size
innodb_log_buffer_size 确保有足够大的日志缓冲区来保存脏数据在被写入到日志文件之前,因此其设置也不应过大,明智的做法是设置为1M到8M,一个大的日志缓冲允许大型事物运行而不需要再事物提交之往磁盘上写日志,因此,除非有大型事物,否则没有必要如此。

3 redo 磁盘上的大小
决定了redo 的切换频率,默认为48M,一方面不能设置得太大,如果设置得很大,在恢复时可能需要很长时间,另一方面又不能太小,否则可能导致一个事务的日志需要多次切换重做日志文件。在32位计算机上日志文件的合并大小必须小于4BG,默认是5M,值越大,在缓冲池中越少需要检查点刷新行为,以节约磁盘I/O,但其崩溃恢复也会更慢
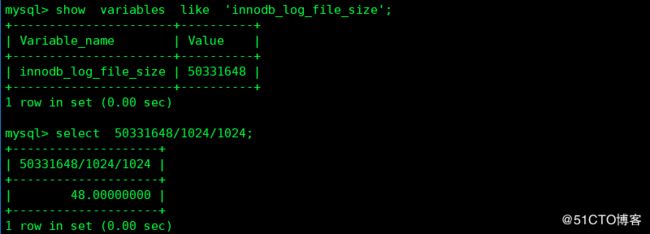
4 innodb_log_files_in_group
在日志组中日志文件的数量,innodb以循环的方式写入,如果此时设置为1,则可能会导致redo日志覆盖,从而影响恢复,建议选择默认设置。

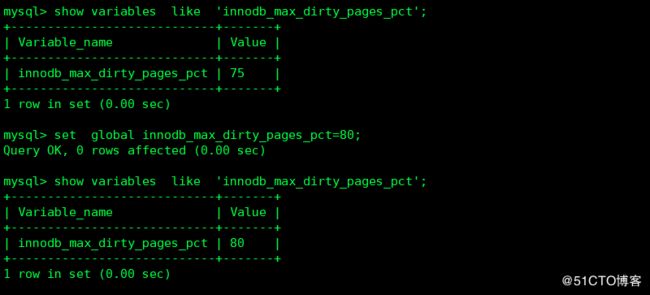
5 innodb_max_dirty_pages_pct

这是一个范围从0到100 的整数,默认是75.innodb的主线程试着从缓冲池写页面,使得脏页的百分比不超过这个值,如果你有SUPER权限,则可以在运行过程中进行修改。
8 MySQL 登陆相关
1 交互式等待时间

2 非交互等待时间

此处如果设置过大,则会造成大量的链接,导致新的链接不能进入,从而影响系统的性能
3 最大链接数

默认是151 个链接
4 用户链接数

其中Threads_connected 表示用户连接数
对于mysql服务器最大连接数值的设置范围比较理想的是:服务器响应的最大连接数值占服务器上限连接数值的比例值在10%以上,如果在10%以下,说明mysql服务器最大连接上限值设置过高。
9 二进制日志相关
1 二进制日志记录格式

默认是statement
3种格式:
1 statement 记录SQL语句,其日志记录量小,节约磁盘IO空间但其必须要记录上下文信息,保证在从服务器上执行结果和主服务器上相容,对一些非正确性函数无法进行正确复制,可能造成mysql复制的主备服务器数据不一致。
2 row * 以行记录的方式存在,推荐使用
使mysql主从复制更加安全,对每一行的数据修改比基于段的复制高效,由于误操作修改数据库信息,且没有备库可恢复时,可用过对日志数据操作反向处理回复数据,但其机理日志量较大
binlog_row_image = [FULL|MINMAL|NOBLOB]
查看binlog_row_image参数的默认值:
FULL:记录修改行的所有列数据
MINMAL:仅记录修改行中有发生数据变化的列,
NOBOLB:和full方式类似,仅仅当blog和text 这些列进行修改是时,不会记录这些属性的列
3 mixed 过度版 混合日志格式
特点:根据sql语句由系统决定基于段和基于行的日志格式中进行选择
2 二进制日志刷新方式binlog 日志的刷新
1 代表事实刷新
0 代表交由操作系统刷
n代表n个事务刷新一次
默认是交由操作系统刷新,可进行修改: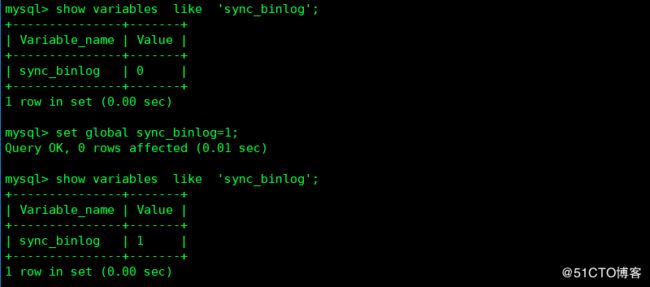
3 binglog文件大小
如果binlog 文件大小过小,则会产生多个binlog文件,如果设置过大则恢复不易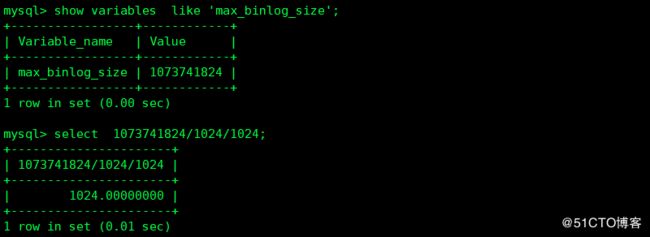
4 binlog 使用内存大小
binlog使用内存的大小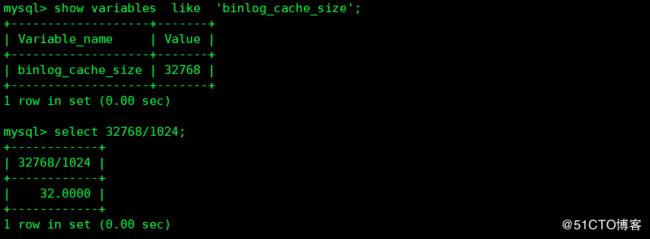
binlog 使用内存的最大尺寸,(针对事物语句)
如果事物需要的内存超过此字节,则服务器会生成:ERROR 1197 (HY000): Multi-statement transaction required more than,其最低是4096,推荐的最大值设置为4GB,因为目前的mysql当二进制日志位置大于4GB不会生效。
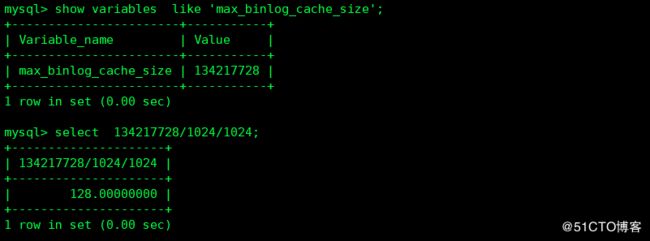
max_binlog_stmt_cache_size 针对非事物语句,当发现Binlog_cache_disk_use或者Binlog_stmt_cache_disk_use比较大时就需要考虑增大cache的大小
5 二进制日志的过期时间
用于设置日志日志多少时间过期
11 慢查询相关
mysql的慢查询日志是mysql提供的一种日志记录,用来记录在mysql中响应时间超过阈值的语句,具体是指运行时间超过long_query_time的语句,默认是10S,及运行10秒以上的语句时慢查询语句。
一般来说,慢查询发生在大表,且查询条件的字段没有建立索引,此时,要匹配查询条件的字段会进行全表扫描。
1 开启慢查询
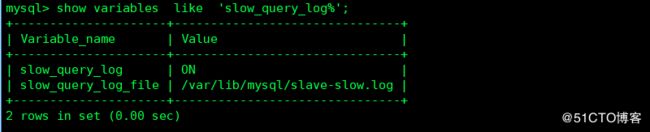
2 查看慢查询时间

3否记录没有利用索引的查询
默认是OFF,设置为ON表示会记录没有利用索引的查询,一般在性能调优时会暂时开启

12 表缓存相关
1打开文件数量,是该系统的实际值

2 查看打开表缓存大小

3 从服务器发送或接收的最大数据包长度

4 如果内存的临时表超过该值,mysql自动将它转换为硬盘上的MYISAM表,如果你执行许多高级group by 查询并且有大量内存,则可以增加tmp_table_size的值
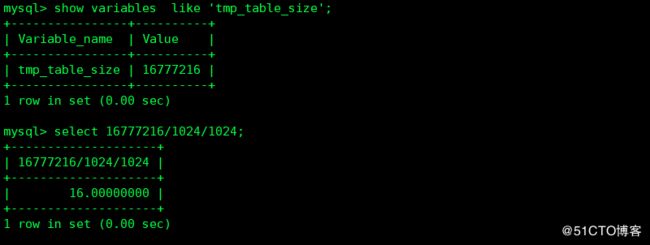
5 该变量设置内存表可以增大到的最大空间大小,该变量用来计算内存表的max_rows 值,在已有的表上没有效果,除非重建表。
三 mysql 其他查询
1 线程相关
A 查看当前的线程

B 查看总线程

cached 被缓存的线程
running 处于激活状态的线程
connected 当前链接的线程
create 被创建的线程
2询吞吐量
由 Questions 指标带来的以客户端为中心的视角常常比相关的Queries 计数器更容易解释。作为存储程序的一部分,后者也会计算已执行语句的数量,以及诸如PREPARE 和 DEALLOCATE PREPARE 指令运行的次数,作为服务器端预处理语句的一部分。

3 碎片的查询和整理

产生碎片的原因
1 主要是因为对大表进行删除操作
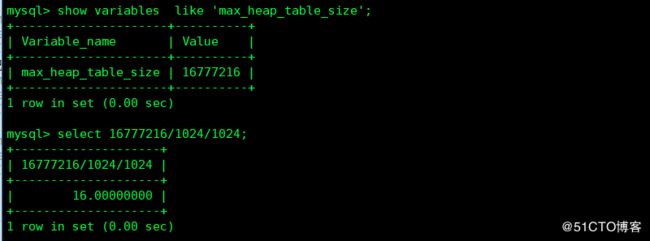
2 其次是随机方式插入新数据,可能导致辅助索产生大量碎片碎片量为 data_length+index_length-rows\*avg_row_length

整理碎片的方式
1 整理表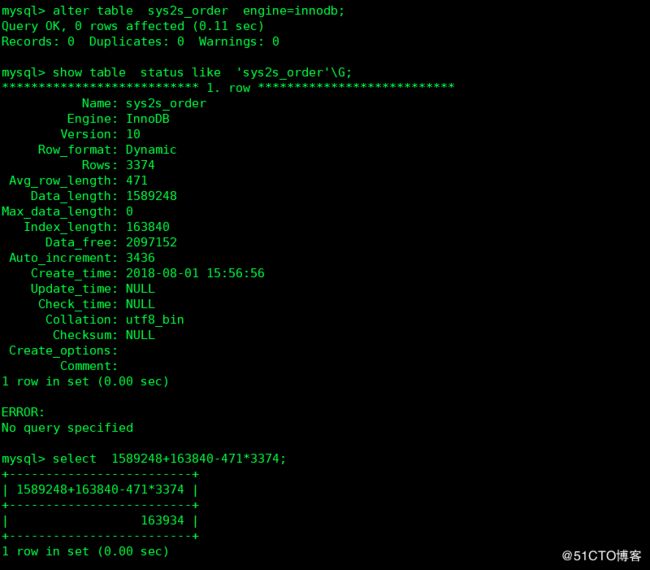
2 导入导出
4 MySQL默认查找配置文件顺序

5 MySQL 统计信息的收集方法
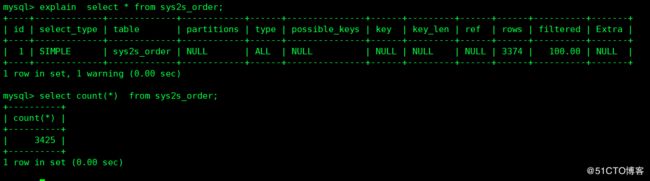
两个结果不一致,表明统计信息不正确
收集统计信息
1 重启mysql 服务
2 遍历tables.
6 设置访问页被放置到热端的时间

如果用户预估自己的活跃的热点数据不止63%,那么在执行SQL语句之前,还可以通过pct 来减少热点数据被刷新出来的概率。
LRU 列表用来管理已经读取的页,当数据库刚启动时,LRU列表时空的,及没有任何的页,这时页都存放在free列表中,当需要从缓冲池中分页时,首选从free列表中查找是否有可用的空闲页,若有,则将该页从free列表重删除,放入到LRU列表中,当页从LRU列表的old部分加入到new部分时,称此时发送我那个的操作为page made young ,而因为innodb_old_blockes_time的设置而导致页没有从old部分移动到new部分的操作成为page not made young,
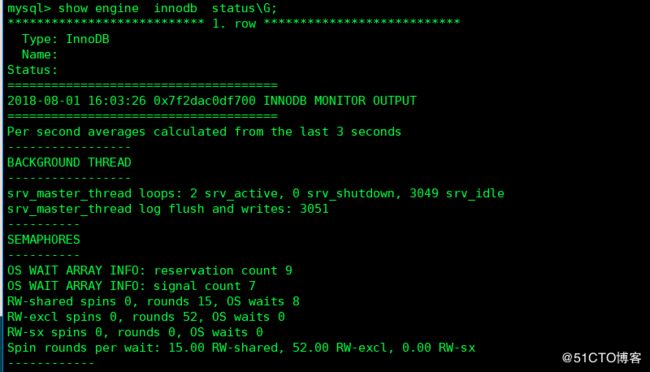
Show engine innodb status显示的不是当前的状态,而是过去某个时间范围内innodb存储引擎的状态。
Innodb 1.2 版本开始,可以通过使用innodb_buffer_pool_stats 来观察缓冲池的运行状态
7 MySQL执行计划分析

先看type,如果当type为all时,表示为全表扫描,后面的rows表示是全表的数据总行,
如果type不为all,则查看rows,扫描多少行数据,再看key ,key 表示可能用到的索引,最后看extra
数据库的优化,大多是优化I/O


其值大于0.5,则可以作为索引,越接近1越好