作者: 一字马胡
作为Java语言的重度使用者,很有必要认识一下Java语言的通用技术栈。我非常喜欢运行于JVM之上的语言,比如Java、Scala等,其中一个重要的原因在于JVM的GC机制,使得使用运行与JVM的各种的语言的时候不需要过于关注内存管理方面的内容,当然,对于一些特殊场景下,内存管理也是必不可少的,特别是对于一些对性能要求极高的应用,但是,在极大概率下,我们在写代码的时候是不需要关心内存管理方面的问题的。当然,除了GC之外,高性能也是我喜欢使用运行于JVM之上的语言的另外一大原因,比如Java语言,性能和直接编译为机器码的语言比如C++不相上下,而在工程效率方面,Java又是具有极大优势的一门语言,开发效率极高,说到开发效率,就得说一下我喜欢Java语言的第三大原因了,那就是Java生态的丰富性,经过多年的发展,Java语言几乎在各种场景下都有成熟的解决方案,比如在Web方向上,有Spring生态,在大数据领域,有Hadoop、spark、flink等一系列成熟的处理框架,所以,无论在什么时候,在做技术语言选型的时候,Java总是应该被优先考虑。
因为Java技术体系的极大丰富性,所以,在学习的时候就不得不选择一些适合与各自领域的、或者感兴趣的内容去学习了,本文算是一种对近一年来使用Java语言的总结,也是对未来学习和使用Java的一种规划,我个人的兴趣点在Web开发、DataFlow、高性能、高并发等内容上,所以,本文所展示的技术栈都将和这些内容相关,但未来会逐渐添加一些新的技术方向,毕竟技术在不断的升级优化,新的技术也将不断出现来取代老的技术,当然,对于后端领域,技术的推陈出新似乎不会那么快速(和大前端相比),一个原因是后端需要提供稳定有保障、高性能的服务,而新的技术可能仅仅满足生产环境的一个或者几个条件,还有待有一些能力较强,愿意冒险的技术人员尝试检验,之后才能逐渐被人们接收,但是,这个过程是很漫长的,并且很多新的技术在这个过程中将会被淹没。
下面,将会由浅入深的罗列我所知道的Java技术栈内容,会用一些简短有力的语言来描述具体的内容,并且会罗列出一些参考资料,以便未来不时之需可以拿来做参考。
Java 语言基础内容
语法及语言特性
第一部分首当其冲就是Java语言基础,包括非常细节的Java语法,也就是怎么使用Java语言来写代码,可能会觉得这个内容很简单,任何一个有计算机基础的人几个小时之内就可以学会使用Java语言来写出具有一定功能的代码,但是基础永远是决定你可以在这门语言上能有多大造诣的关键性因素。对于同一个功能,可以不同的代码来实现,但是,在极端情况下,可能有些代码就会表现得非常差劲,甚至会发生不可扭转的错误。
另外一点,Java语言是面向对象的高级语言,需要在学习和使用Java语言的时候去体会,并且使用这种思想去编程,需要你对Java语言的特性有足够的了解,比如Java是否支持多继承,如何实现多继承,泛型技术等。
在学习Java语言基础这点上,推荐阅读经典的《Java编程思想》,需要多看几遍,并且下意识的去完成章节后面的练习,会有很大的收获。下面是一些需要关注的点,后面的内容中对下面的内容会做更全面的说明:
访问权限(private、protected、public、package-private)
需要关注每个权限的限定范围,为什么需要有访问控制,怎么在实际应用中正确的使用合适的访问权限,这属于比较基础的内容,也是比较简单的,但是正确的使用权限控制是一件不太容易的事情,这需要对代码结构设计、代码风格乃至设计模式都有所了解。-
多态
什么是多态?Java怎么实现多态的?为什么需要多态?如何使用Java实现多态?这几个问题是用来检测是否掌握了多态的问题,简单来说,所谓多态,也就是同一套接口,有不同的实现类,这样,同样是调用接口的同一个方法,但是不同的实现类就会有截然不同的表现,但是多态的细节还需要深入学习总结,多态的价值在于抽象,对于具有相同表现能力的对象进行抽象,然后不同的对象进行不同的实现,当然,说多态的价值在于抽象这种说明并不严谨或者正确,因为作为面向对象思想的三大特性,抽象、继承和多态是相辅相成的,抽象是设计技巧,继承则是纯技术性的特性,而多态将抽象和继承结合起来,这才是重点。
-
接口
接口是非常重要的类型抽象,所谓接口,就是抽象出一组方法,没有方法实现,具体的方法实现需要子类自己去实现,接口用于向外部暴露出自己的服务能力,告诉调用者服务具有的能力,而某个方法的具体实现则可以有多种多样不同的形式,接口使用interface关键字来定义,和接口类似的是抽象类,抽象类使用abstract关键字来限定类,当然,抽象类和接口都是无法实例化的,都需要实例化其子类(实现类),抽象类可以有一些通用方法的实现,对于有个性化需求的方法,可以抽象为抽象方法,供子类实现,抽象类经常用于实现模板设计模式,抽象类和接口的本质是抽象,只不过接口相当于所有方法都是抽象的,而抽象类中可以有具体的实现方法。
-
内部类、嵌套类
所谓内部类,就是将一个类的定义放到了另外一个类里面,嵌套类则是静态内部类,内部类可以访问外围类的所有成员而不需要特殊的条件,而且不管嵌套基层,这种特性依然生效。静态内部类则相当于一个独立的类,它只是被放到了一个外围类内部,并且在new一个静态内部类的对象的时候需要带上外围类作为前缀才行,静态内部类不能像内部类一样访问外围类,它只能范围外围类中的静态成员。内部类的价值在于实现多重继承,Java语言本身是不支持多重继承的(单一继承),当然,如果想实现多重继承的效果,可以使用实现多个接口的方式,内部类也可以用于实现多重继承的效果。 -
枚举
在java中使用enum来定义一个枚举类型,所谓枚举,就是一些固定的常量,比如颜色,则使用枚举可以定义红色、白色、黑色等,当需要表示一种颜色的时候,可以使用该枚举类型去表示。当然,如果仅仅是这样,那么枚举存在的意义似乎不是很大,使用类似‘static final int XXX = XXX’这样也可以达到枚举的效果,无法就是定义一些常量,然后使用不同的常量值表示不同的枚举值而已。在java中,枚举类型是一种非常强大的类型 ,你可以在枚举类中添加方法,就像在普通类中那样,需要知道的是,任何使用enum定义的枚举类型,编译器会自动为你生成一个集成java.lang.Enum的类,而java是单继承的,所以你不能继承一个枚举类型,但是你可以将枚举类型放在一个接口里面,然后接口里面的枚举实现接口,并且进行扩展,这样就实现了继承枚举类型的效果。枚举还有一些高级的用法,比如使用枚举来实现线程安全的单例模式,状态机、责任链等,使用枚举会使得我们的代码更加漂亮,学习枚举以及掌握枚举类型是非常有必要的,后面会进行更为丰富的学习与总结。
-
注解
在开发过程中时常会碰到注解,注解是一种标记,比如@Override注解标记一个方法是覆盖方法,我们可以定义自己的注解,并且可以基于注解做一些处理,注解(Annotation)信息携带在对象的Class信息中,可以在Class信息中找到对象所属类型的注解信息,一个类可以有注解,一个字段也可以有注解,在Spring开发中就有字段注解。 -
异常处理
这是一个沉重的话题,但是又不得不提一下,异常处理系统是java语言中至关重要的一部分,正确的抛出异常,处理异常是非常重要的,恰当的异常可以辅助解决问题,而不恰当的问题使得出现问题的时候百思不得其解。 -
数组
想象一下不支持数组的编程语言是一种怎么样的存在,我至今没有接触过不支持数组类型的编程语言,这也说明数组这种类型是一种非常重要的类型,在java中,反而我们使用数组的时间并不多,而List、Set之类的容器成了首选,当然,ArrayList是使用最为频繁的容器,内部依然是一个数组。其次,在java中,数组也是对象,你可以使用数组和null值做比较判断,但是数组是一种神奇的对象,至于怎么神奇,需要日后专门探索一下。关键的内容为数组的结构,以及怎么使用数组等。 -
集合
对象的容器,List、Set、Map,尽管研究去吧,从线程不安全的集合到线程安全的集合,jdk中关于集合的内容很多,也很值得仔细研究,比如ArrayList是在嗯么实现的,具体实现的细节比如怎么实现扩容的,为什么不支持多线程,怎么样使得ArrayList支持多线程等。又比如HashMap是怎么实现的,各个版本的区别又是什么,为什么要改成现在这样的结构等等。
-
字符串
String是一种java中最为频繁使用的类型,它足够简单,你可以随意使用,并且提供了足够多的方法来进行字符串处理,但另外一方面,它又足够复杂,总之,学会使用以及研究它的本质是非常值得的一件事情。
-
反射技术
反射就是在运行时可以获取到一个类的方法、字段信息的一种技术,这种技术非常有用。 -
泛型技术
泛型技术使得Object可以暂时不用代替“所有类型”了! -
IO、NIO、AIO、文件操作(Files)
网络编程(socket编程),文件读写等内容。 -
并发
jdk并发包中的内容。 -
AST
java抽象语法树。
JDK类库
Java语言提供了一套非常友好的API给开发者使用,称为JDK,作为Java开发者,需要熟练使用JDK来做日常开发,JDK中的实现是经过大量优化的实现,所以无论是性能还是安全等都是顶级水准,所以,如果一个功能JDK提供了,那就使用JDK提供的,比如很重要的一个功能是数据排序,JDK提供了相应的API来供你做排序,并且是经过优化的,所以,就不要试图实现什么快速排序算法来对你的数据排序(这也可以,但是费工时,最后效果还没有JDK提供的好)。
JDK会随着Java语言的升级而升级,会逐渐丰富整个类库,也会根据语言特性新增一些和语言特性相关的API。推荐使用JDK1.7及以上的版本用于实际开发,本文将使用JDK1.8来进行描述。
下面将对几个常用的JDK类库进行描述,JDK类库非常丰富,在日常开发中可能仅仅使用了JDK中一个非常小的子集,所以,如果对某些部分感兴趣,需要自己去探索发现。
JDK类库-基本类型
类型包括基本数据类型和包装数据类型,基本数据类型包括int、long、float、double、boolean、short、char等,包装数据类型就是对基本类型的包装,比如int的包装类型为Integer,long的包装类型为Long,需要注意的一点是,基本类型的默认值和包装类型的默认值是不一样的,比如int的默认值可能为0,但是Integer的默认值是null(因为是对象),所以在使用的时候就要注意空指针的问题了。
关于数据类型,可能没什么需要多说的,但是还是需要特别说明一下,基本数据类型的包装类型都有一些静态方法来将基本数据类型转换为包装类型,这些方法以"valueOf","parseXXX"开头,很容易识别。
JDK类库-集合
集合在java.util包下,需要说明的一点是,java.util包下都是好东西,包括集合、Stream、并发等一系列内容,属于JDK的精品部分,这个包也是日常开发中使用频率比较高的一个。
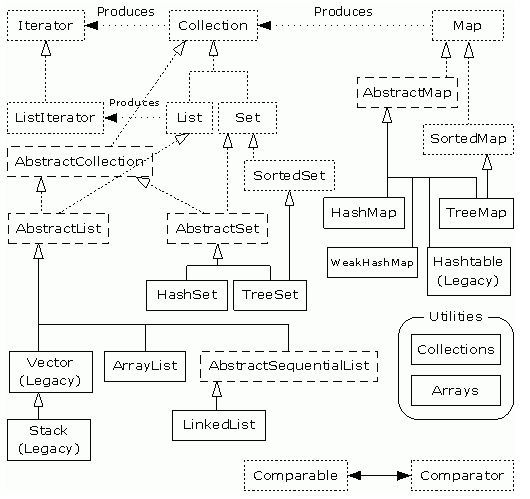
上面的图片展示了Java集合的类图关系,我们需要关注的有这么几个,List、Set、Map,这是三个接口,List是线性表,Set是集合,Map是键值对映射容器,这三种容器适用场景是不一样的,对于List,它常用的实现类有ArrayList、LinkedList,List是一种通用容器,可以存储对象,ArrayList适用于读写少的场景,而LinkedList适用与写多读少的场景,ArrayList内部使用数组来实现,LinkedList内部使用链表来实现。Set和List的区别在于List中存储的对象可以重复,但是Set容器中每个对象只能存储一份,如果已经有一份,那么是存储不进去的,Set的实现类有HashSet和TreeSet。HashSet内部使用HashMap实现,而TreeSet内部使用TreeMap实现。Set的存储对象唯一性这种特性适合用于判断一个对象是否存在于容器中这样的场景,需要注意的是,List也可以实现这种“是否存在”的语义判断,但是List和Set实现的方法是不一样的,复杂度也是不可同日而语的,List实现同样功能的时间复杂度是O(N),而Set则是O(1)。下面是ArrayList和HashSet实现同样功能的代码展示:
ArrayList:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
HashSet:
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
可以看到,ArrayList遍历了一次数组,然后逐一判断,但是HashSet则使用Map的containsKey方法来判断是否存在,而这个复杂度大概率是接近O(1)的。接下来就说Map,这是一种存储键值对映射的容器,常用的Map的实现类包括HashMap,LinkedHashMap,TreeMap,SortdMap,最常用的是HashMap。TreeMap内部还有红黑树实现,而SortedMap则提供排序功能。还有两种重要的数据结构Queue和Stack,在实际项目中。如果想使用Queue和Stack,一般使用LinkedList来实现,LinkedList是一个使用双向链表存储数据的结构,可以实现具有FIFO性质的Queue和FILO性质的Stack,下面是一个使用LinkedList来实现Stack功能的参考,对于Queue也是类似的:
import java.util.LinkedList;
public class WrapStack {
private LinkedList stack;
public WrapStack() {
this.stack = new LinkedList<>();
}
public T pop() {
if (stack == null) {
stack = new LinkedList<>();
return null;
} else {
return stack.removeFirst();
}
}
public void push(T data) {
if (this.stack == null) {
this.stack = new LinkedList<>();
}
if (data == null) {
throw new NullPointerException("The input data must bot null");
}
this.stack.addFirst(data);
}
public boolean isEmpty() {
return this.stack == null || this.stack.isEmpty();
}
public int size() {
if (this.stack == null) {
return 0;
} else {
return this.stack.size();
}
}
}
掌握了这些常用的数据容器之后,接下来就需要了解两个特别重要和实用的和集合相关的util类:Collections和Arrays。
先说Collections,Collections包含大量的操作容器的静态方法,比如排序、拷贝、查找、反转、求min/max、比较、计数、shuffle、check,swap等等,所以几乎你可以想到的操作集合的op都在里面可以找到,可以说是百宝箱了,但是在实际操作中,因为我们可能并不知道这些实用方法确实已经存在,所以可能有时候会自己去造轮子,一方面造轮子是比较费时的,另外一方面对于一些基础功能,需要做足够的测试,包括正确性验证和性能测试,必要的时候还需要做性能优化,整体来说是一件很耗费精力的事情,如果我们知道了这些实用方法的存在,那么在遇到需要某些功能的时候,就会下意识的到这里面来找找是不是已经存在对应的方法,如果没有,那么再自己去写。比如如果需要在集合中查找一个元素是否存在,那么可以使用Collections提供的二分查找算法:
public static
int binarySearch(List> list, T key) {
if (list instanceof RandomAccess || list.size()
int indexedBinarySearch(List> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
...
在日常开发中,使用Collections中最为频繁的功能当属获取一个不可变集合类型,比如返回一个不可变的List,一个不可变的Map等,可以使用Collections.emptyList(),Collections.emptySet(),Collections.emptyMap()等来实现。
接着,说完Collections,再来说说Arrays,Collections是专门为操作集合设计的,而Arrays是为数组设计的,为数组提供一系列便捷的操作,比如排序、查找等,当然,还可以将数组方便的转换成一个新的List,这样就可以使用Collections来操作了。记住一点,所有你能想到的对于数组的操作,首先去Arrays看看有没有现成的方法,如果有,那么使用现有的,如果没有再自己实现。可以看到,Arrays提供了大量的sort/search/fill/copy方法,甚至可以将数组直接转换成一个新的Stream,那样就可以使用Stream的一系列便捷方法来操作数组了。
总结:JAVA集合使用到的频率是非常高的,对List、Set、Map的常用实现类需要熟练掌握使用场景、使用方法等内容,当有对集合操作的需求的时候,首先想到的应该是实现类自身的方法成员,然后就是Collections里面提供的方法,对于数组,如果需要对数组进行排序、查找、初始化等操作的时候,首先应该使用Arrays里面提供的方法,如果不能满足需求,再去寻求其他的方案来实现。