NIO中缓冲区是数据传输的基础,JDK通过ByteBuffer实现,Netty框架中并未采用JDK原生的ByteBuffer,而是构造了ByteBuf。
ByteBuf对ByteBuffer做了大量的优化,比如说内存池,零拷贝,引用计数(不依赖GC),本文主要是分析这些优化,学习这些优化思想,学以致用,在实际工程中,借鉴这些优化方案和思想。
直接内存和堆内存
首先先讲一下这里面需要用的基础知识,在JVM中 内存可分为两大块,一个是堆内存,一个是直接内存。这里简单介绍一下
堆内存:
堆内存是Jvm所管理的内存,相比方法区,栈内存,堆内存是最大的一块。所有的对象实例实例以及数组都要在堆上分配。
Java的垃圾收集器是可以在堆上回收垃圾。
直接内存:
JVM使用Native函数在堆外分配内存,之后通过Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。直接内存不会受到Java堆的限制,只受本机内存影响。
Java的GC只会在老年区满了触发Full GC时,才会去顺便清理直接内存的废弃对象。
JDK原生缓冲区ByteBuffer
在NIO中,所有数据都是用缓冲区处理的。读写数据,都是在缓冲区中进行的。缓存区实质是是一个数组,通常使用字节缓冲区——ByteBuffer。
属性:
| 属性 |
说明 |
| capacity |
缓冲区的大小,一旦申请将不能改变 |
| position |
位置索引,表示读模式或者写模式数据的位置,读模式和写模式切换的时候position会被重置为0,positon最大可谓capacity-1。 |
| limit |
在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。读模式下,limit等于buffer的capacity |
| mark |
标记,指一个备忘位置,调用mark()来设定mark=position,调用reset()来设定postion=mark,标记未设定前是未定义的. |
使用方式:
ByteBuffer可以申请两种方式的内存,分别为堆内存和直接内存,首先看申请堆内存。
// 申请堆内存 ByteBuffer HeapbyteBuffer = ByteBuffer.allocate(1024);
很简单,就一行代码,再看看allocate方法。
public static ByteBuffer allocate(int capacity) { if (capacity < 0) throw new IllegalArgumentException(); return new HeapByteBuffer(capacity, capacity); }
其实就是new一个HeapByteBuffer对象。这个 HeapByteBuffer继承自ByteBuffer,构造器采用了父类的构造器,如下所示:
HeapByteBuffer(int cap, int lim) { // package-private super(-1, 0, lim, cap, new byte[cap], 0); /* hb = new byte[cap]; offset = 0; */ } //ByteBuffer构造器 ByteBuffer(int mark, int pos, int lim, int cap, // package-private byte[] hb, int offset) { super(mark, pos, lim, cap); this.hb = hb; this.offset = offset; }
结合ByteBuffer的四个属性,初始化的时候就可以赋值capaticy,limit,position,mark,至于byte[] hb, int offsef这两个属性,JDK文档给出的解释是backing array,and array offset。它是一个回滚数组,offset是数组的偏移值。
申请直接内存:
// 申请直接内存 ByteBuffer DirectbyteBuffer = ByteBuffer.allocateDirect(1024);
allocateDirect()实际上就是new的一个DirectByteBuffer对象,不过这个new 一个普通对象不一样。这里使用了Native函数来申请内存,在Java中就是调用unsafe对象
public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); } DirectByteBuffer(int cap) { // package-private super(-1, 0, cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L, (long)cap + (pa ? ps : 0)); Bits.reserveMemory(size, cap); long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); if (pa && (base % ps != 0)) { // Round up to page boundary address = base + ps - (base & (ps - 1)); } else { address = base; } cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); att = null; }
申请方法不同的内存有不同的用法。接下来看一看ByteBuffer的常用方法与如何使用
ByteBuffer的常用方法与使用方式
Bytebuf的读和写是使用put()和get()方法实现的
// 读操作 public byte get() { return hb[ix(nextGetIndex())]; } final int nextGetIndex() { if (position >= limit) throw new BufferUnderflowException(); return position++; } // 写操作 public ByteBuffer put(byte x) { hb[ix(nextPutIndex())] = x; return this; } final int nextPutIndex() { if (position >= limit) throw new BufferOverflowException(); return position++; }
从代码中可以看出,读和写操作都会改变ByteBuffer的position属性,这两个操作是共用的position属性。这样就会带来一个问题,读写操作会导致数据出错啊,数据位置出错。
ByteBuffer提供了flip()方法,读写模式切换,切换的时候会改变position和limit的位置。看看flip()怎么实现的:
public final Buffer flip() { // 1. 设置 limit 为当前位置 limit = position; // 2. 设置 position 为0 position = 0; mark = -1; return this; }
这里就不重点介绍了,有些细节可以自己去深究。
Netty的ByteBuf
Netty使用的自身的ByteBuf对象来进行数据传输,本质上使用了外观模式对JDK的ByteBuffer进行封装。
相较于原生的ByteBuffer,Netty的ByteBuf做了很多优化,零拷贝,内存池加速,读写索引。
为什么要使用内存池?
首先要明白一点,Netty的内存池是不依赖于JVM本身的GC的。
回顾一下直接内存的GC:
上文提到Java的GC只会在老年区满了触发Full GC时,才会去顺便清理直接内存的废弃对象。
JVM中的直接内存,存在堆内存中其实就是DirectByteBuffer类,它本身其实很小,真的内存是在堆外,这里是映射关系。
每次申请直接内存,都先看看是否超限 —— 直接内存的限额默认(可用 -XX:MaxDirectMemorySize 重新设定)。
如果超过限额,就会主动执行System.gc(),这样会带来一个影响,系统会中断100ms。如果没有成功回收直接内存,并且还是超过直接内存的限额,就会抛出OOM——内存溢出。
继续从GC角度分析,DirectByteBuffer熬过了几次young gc之后,会进入老年代。当老年代满了之后,会触发Full GC。
因为本身很小,很难占满老年代,因此基本不会触发Full GC,带来的后果是大量堆外内存一直占着不放,无法进行内存回收。
还有最后一个办法,就是依靠申请额度超限时触发的system.gc(),但是前面提到,它会中断进程100ms,如果在这100ms的之间,系统未完成GC,仍会抛出OOM。
所以这个最后一个办法也不是完全保险的。
Netty使用了引用计数的方式,主动回收内存。回收的对象包括非池直接内存,和内存池中的内存。
内存池的内存泄露检测?
Netty中使用引用计数机制来管理资源,ByteBuf实际上是实现了ReferenceCounted接口,当实例化ByteBuf对象时,引用计数加1。
当应用代码保持一个对象引用时,会调用retain方法将计数增加1,对象使用完毕进行释放,调用release将计数器减1.
当引用计数变为0时,对象将释放所有的资源,返回内存池。
Netty内存泄漏检测级别:
禁用(DISABLED) - 完全禁止泄露检测。不推荐。
简单(SIMPLE) - 告诉我们取样的1%的缓冲是否发生了泄露。默认。
高级(ADVANCED) - 告诉我们取样的1%的缓冲发生泄露的地方
偏执(PARANOID) - 跟高级选项类似,但此选项检测所有缓冲,而不仅仅是取样的那1%。此选项在自动测试阶段很有用。如果构建(build)输出包含了LEAK,可认为构建失败
也可以使用JVM的-Dio.netty.leakDetectionLevel选项来指定泄漏检测级别。
内存跟踪
在内存池中分配内存,得到的ByteBuf对象都是经过toLeakAwareBuffer()方法封装的,该方法作用就是对ByteBuf对象进行引用计数,使用SimpleLeakAwareByteBuf或者AdvancedLeakAwareByteBuf来包装ByteBuf。此外该方法只对非池内存中的直接内存和内存池中的内存进行内存泄露检测。
//装饰器模式,用SimpleLeakAwareByteBuf或AdvancedLeakAwareByteBuf来包装原始的ByteBuf
protected static ByteBuf toLeakAwareBuffer(ByteBuf buf) {
ResourceLeakTracker leak; //根据设置的Level来选择使用何种装饰器 switch (ResourceLeakDetector.getLevel()) { case SIMPLE: //创建用于跟踪和表示内容泄露的ResourcLeak对象 leak = AbstractByteBuf.leakDetector.track(buf); if (leak != null) { //只在ByteBuf.order方法中调用ResourceLeak.record buf = new SimpleLeakAwareByteBuf(buf, leak); } break; case ADVANCED: case PARANOID: leak = AbstractByteBuf.leakDetector.track(buf); if (leak != null) { //只在ByteBuf.order方法中调用ResourceLeak.record buf = new AdvancedLeakAwareByteBuf(buf, leak); } break; default: break; } return buf; }
实际上,内存泄露检测是在AbstractByteBuf.leakDetector.track(buf)进行的,来看看track方法的具体实现。
/**
* Creates a new {@link ResourceLeakTracker} which is expected to be closed via
* {@link ResourceLeakTracker#close(Object)} when the related resource is deallocated. * * @return the {@link ResourceLeakTracker} or {@code null} */ @SuppressWarnings("unchecked") public final ResourceLeakTracker track(T obj) { return track0(obj); } @SuppressWarnings("unchecked") private DefaultResourceLeak track0(T obj) { Level level = ResourceLeakDetector.level; // 不进行内存跟踪 if (level == Level.DISABLED) { return null; } if (level.ordinal() < Level.PARANOID.ordinal()) { //如果监控级别低于PARANOID,在一定的采样频率下报告内存泄露 if ((PlatformDependent.threadLocalRandom().nextInt(samplingInterval)) == 0) { reportLeak(); return new DefaultResourceLeak(obj, refQueue, allLeaks); } return null; } //每次需要分配 ByteBuf 时,报告内存泄露情况 reportLeak(); return new DefaultResourceLeak(obj, refQueue, allLeaks); }
再来看看返回对象——DefaultResourceLeak,他的实现方式如下:
private static final class DefaultResourceLeak
extends WeakReference
它继承了虚引用WeakReference,虚引用完全不影响目标对象的垃圾回收,但是会在目标对象被VM垃圾回收时加入到引用队列,
正常情况下ResourceLeak对象,会将监控的资源的引用计数为0时被清理掉。
但是当资源的引用计数失常,ResourceLeak对象也会被加入到引用队列.
存在着这样一种情况:没有成对调用ByteBuf的retain和relaease方法,导致ByteBuf没有被正常释放,当ResourceLeak(引用队列) 中存在元素时,即表明有内存泄露。
Netty中的 reportLeak()方法来报告内存泄露情况,通过检查引用队列来判断是否有内存泄露,并报告跟踪情况.
方法代码如下:
Handler中的内存处理机制
Netty中有handler链,消息有本Handler传到下一个Handler。所以Netty引入了一个规则,谁是最后使用者,谁负责释放。
根据谁最后使用谁负责释放的原则,每个Handler对消息可能有三种处理方式
- 对原消息不做处理,调用 ctx.fireChannelRead(msg)把原消息往下传,那不用做什么释放。
- 将原消息转化为新的消息并调用 ctx.fireChannelRead(newMsg)往下传,那必须把原消息release掉。
- 如果已经不再调用ctx.fireChannelRead(msg)传递任何消息,那更要把原消息release掉。
假设每一个Handler都把消息往下传,Handler并也不知道谁是启动Netty时所设定的Handler链的最后一员,所以Netty在Handler链的最末补了一个TailHandler,如果此时消息仍然是ReferenceCounted类型就会被release掉。
总结:
1.Netty在不同的内存泄漏检测级别情况下,采样概率是不一样的,在Simple情况下出现了Leak,要设置“-Dio.netty.leakDetectionLevel=advanced”再跑一次代码,找到创建和访问的地方。
2.Netty中的内存泄露检测是通过对ByteBuf对象进行装饰,利用虚引用和引用计数来对非池中的直接内存和内存池中内存进行跟踪,判断是否发生内存泄露。
3.计数器基于 AtomicIntegerFieldUpdater,因为ByteBuf对象很多,如果都把int包一层AtomicInteger花销较大,而AtomicIntegerFieldUpdater只需要一个全局的静态变量。
Netty中的内存单位
Netty中将内存池分为五种不同的形态:Arena,ChunkList,Chunk,Page,SubPage.
首先来看Netty最大的内存单位PoolArena——连续的内存块。它是由多个PoolChunkList和两个SubPagePools(一个是tinySubPagePool,一个是smallSubPagePool)组成的。如下图所示:

1.PoolChunkList是一个双向的链表,PoolChunkList负责管理多个PoolChunk的生命周期。
2.PoolChunk中包含多个Page,Page的大小默认是8192字节,也可以设置系统变量io.netty.allocator.pageSize来改变页的大小。自定义页大小有如下限制:1.必须大于4096字节,2.必须是2的整次数幂。
3.块(PoolChunk)的大小是由页的大小和maxOrder算出来的,计算公式是:chunkSize = 2^{maxOrder} * pageSize。maxOrder的默认值是11,也可以通过io.netty.allocator.maxOrder系统变量设置,只能是0-14的范围,所以chunksize的默认大小为:(2^11)*8192=16MB
Page中包含多个SubPage。
PoolChunk内部维护了一个平衡二叉树,如下图所示:
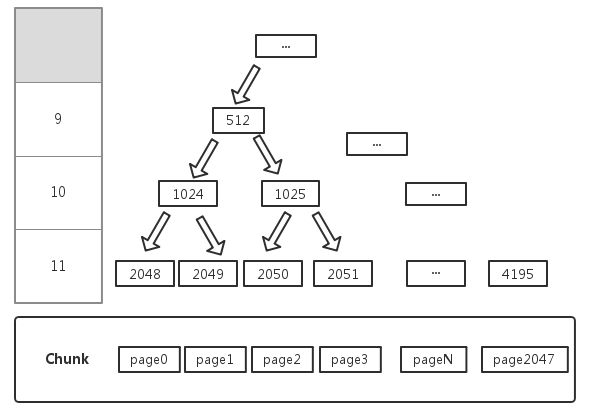
PoolSubPage
通常一个页(page)的大小就达到了10^13(8192字节),通常一次申请分配内存没有这么大,可能很小。
于是Netty将页(page)划分成更小的片段——SubPage
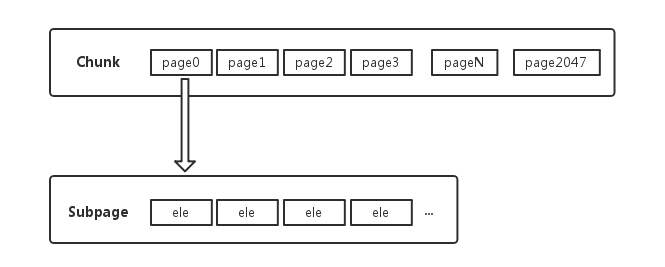
Netty定义这样的内存单元是为了更好的分配内存,接下来看一下一个ByteBuf是如何在内存池中申请内存的。
Netty如何分配内存池中的内存?
分配原则:
内存池中的内存分配是在PoolArea中进行的。
- 申请小于PageSize(默认8192字节)的内存,会在SubPagePools中进行分配,如果申请内存小于512字节,则会在tingSubPagePools中进行分配,如果大于512小于PageSize字节,则会在smallSubPagePools进行分配。
- 申请大于PageSize的内存,则会在PoolChunkList中进行分配。
- 申请大于ChunkSize的内存,则不会在内存池中申请,而且也不会重用该内存。
应用中在内存池中申请内存的方法:
// 在内存池中申请 直接内存 ByteBuf directByteBuf = ByteBufAllocator.DEFAULT.directBuffer(1024); // 在内存池中申请 堆内存 ByteBuf heapByteBuf = ByteBufAllocator.DEFAULT.heapBuffer(1024);
接下来,一层一层的看下来,在Netty中申请内存是如何实现的。就拿申请直接内存举例,首先看directBuffer方法。
// directBuffer方法实现 @Override public ByteBuf directBuffer(int initialCapacity) { return directBuffer(initialCapacity, DEFAULT_MAX_CAPACITY); } // 校验申请大小,返回申请的直接内存 @Override public ByteBuf directBuffer(int initialCapacity, int maxCapacity) { if (initialCapacity == 0 && maxCapacity == 0) { return emptyBuf; } validate(initialCapacity, maxCapacity); return newDirectBuffer(initialCapacity, maxCapacity); } //PooledByteBufAllocator类中的 newDirectBuffer方法的实现 @Override protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) { // Netty避免每个线程对内存池的竞争,在每个线程都提供了PoolThreadCache线程内的内存池 PoolThreadCache cache = threadCache.get(); PoolArenadirectArena = cache.directArena; // 如果缓存存在,则分配内存 final ByteBuf buf; if (directArena != null) { buf = directArena.allocate(cache, initialCapacity, maxCapacity); } else { // 缓存不存在,则分配非池内存 buf = PlatformDependent.hasUnsafe() ? UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) : new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity); } // 通过toLeakAwareBuffer包装成内存泄漏检测的buffer return toLeakAwareBuffer(buf); }
一般情况下,内存都是在buf = directArena.allocate(cache, initialCapacity, maxCapacity)这行代码进行内存分配的,也就是说在内存的连续块PoolArena中进行的内存分配。
接下来,我们根据内存分配原则来进行内存研读PoolArena中的allocate方法。
1 PooledByteBufallocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) { 2 PooledByteBuf buf = newByteBuf(maxCapacity); 3 allocate(cache, buf, reqCapacity); 4 return buf; 5 } 6 7 private void allocate(PoolThreadCache cache, PooledByteBuf buf, final int reqCapacity) { 8 final int normCapacity = normalizeCapacity(reqCapacity); 9 if (isTinyOrSmall(normCapacity)) { // capacity < pageSize 10 int tableIdx; 11 PoolSubpage [] table; 12 boolean tiny = isTiny(normCapacity); 13 if (tiny) { // < 512 14 15 // 如果申请内存小于512字节,则会在tingSubPagePools中进行分配 16 if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) { 17 // was able to allocate out of the cache so move on 18 return; 19 } 20 tableIdx = tinyIdx(normCapacity); 21 table = tinySubpagePools; 22 } else { 23 // 如果大于512小于PageSize字节,则会在smallSubPagePools进行分配 24 if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) { 25 // was able to allocate out of the cache so move on 26 return; 27 } 28 tableIdx = smallIdx(normCapacity); 29 table = smallSubpagePools; 30 } 31 32 final PoolSubpage head = table[tableIdx]; 33 34 /** 35 * Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and 36 * {@link PoolChunk#free(long)} may modify the doubly linked list as well. 37 */ 38 synchronized (head) { 39 final PoolSubpage s = head.next; 40 if (s != head) { 41 assert s.doNotDestroy && s.elemSize == normCapacity; 42 long handle = s.allocate(); 43 assert handle >= 0; 44 s.chunk.initBufWithSubpage(buf, handle, reqCapacity); 45 incTinySmallAllocation(tiny); 46 return; 47 } 48 } 49 synchronized (this) { 50 allocateNormal(buf, reqCapacity, normCapacity); 51 } 52 53 incTinySmallAllocation(tiny); 54 return; 55 } 56 if (normCapacity <= chunkSize) { 57 if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) { 58 // was able to allocate out of the cache so move on 59 return; 60 } 61 synchronized (this) { 62 allocateNormal(buf, reqCapacity, normCapacity); 63 ++allocationsNormal; 64 } 65 } else { 66 // Huge allocations are never served via the cache so just call allocateHuge 67 allocateHuge(buf, reqCapacity); 68 } 69 }
如何使用内存池?
底层IO处理线程的缓冲区使用堆外直接缓冲区,减少一次IO复制。业务消息的编解码使用堆缓冲区,分配效率更高,而且不涉及到内核缓冲区的复制问题。
Netty默认不使用内存池,需要在创建服务端或者客户端的时候进行配置。
//Boss线程池内存池配置.
.option(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT)
//Work线程池内存池配置.
.childOption(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT);
本人的想法是:
1.I/O处理线程使内存池中的直接内存,开启以上配置
2.在handler处理业务的时候,使用内存池中的堆内存
还有一点值得注意的是:在使用完内存池中的ByteBuf,一定要记得释放,即调用release():
// 在内存池中申请 直接内存 ByteBuf directByteBuf = ByteBufAllocator.DEFAULT.directBuffer(1024); // 归还到内存池 directByteBuf.release();
如果handler继承了SimpleChannelInboundHandler,那么它将会自动释放Bytefuf.详情可见:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { boolean release = true; try { if (acceptInboundMessage(msg)) { @SuppressWarnings("unchecked") I imsg = (I) msg; channelRead0(ctx, imsg); } else { release = false; ctx.fireChannelRead(msg); } } finally { // autoRelease默认为true if (autoRelease && release) { // 释放Bytebuf,归还到内存池 ReferenceCountUtil.release(msg); } } }
零拷贝:
该部分是重点介绍的部分,首先将它与传统的I/O read和write操作作对比,看看有什么不同,首先需要理解一下用户态和内存态的概念
用户态(User Mode)和内核态(Kernel Mode),也可以叫用户空间和内核
用户态:受限的访问内存,并且不允许访问硬件设备。
内核态:本质上是一个软件,可以控制计算机的硬件资源(如网卡,硬盘),可以访问内存所有数据。
用户程序都是运行在用户态中的,比如JVM,就是用户程序,所以它运行在用户态中。
用户态是不能直接访问硬件设备的,如果需要一次I/O操作,那就必须利用系统调用机制切换到内核态(用户态与内核态之间的转换称为上下文切换),进行硬盘读写。
比如说一次传统网络I/O:
第一步,从用户态切换到内核态,将用户缓冲区的数据拷贝到内核缓冲区,执行send操作。
第二步,数据发送由底层的操作系统进行,此时从内核态切换到用户态,将内核缓存区的数据拷贝到网卡的缓冲区
总结:也就是一次普通的网络I/O,至少经过两次上下文切换,和两次内存拷贝。
什么是零拷贝?
当需要传输的数据远大于内核缓冲区的大小时,内核缓冲区就成为I/O的性能瓶颈。零拷贝就是杜绝了内核缓冲区与用户缓冲区的的数据拷贝。
所以零拷贝适合大数据量的传输。
拿传统的网络I/O做对比,零拷贝I/O是怎样的一个过程:
用户程序执行transferTo(),将用户缓冲区待发送的数据拷贝到网卡缓冲区。
很简单,一步完成,中间少了用户态到内存态的拷贝。
Netty中零拷贝如何实现
Netty的中零拷贝与上述零拷贝是不一样的,它并不是系统层面上的零拷贝,只是相对于ByteBuf而言的。
Netty中的零拷贝:
1.CompositeByteBuf,将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝。
使用方式:
CompositeByteBuf compositeByteBuf = Unpooled.compositeBuffer(); compositeByteBuf.addComponents(true, ByteBuf1, ByteBuf1);
注意:addComponents第一个参数必须为true,那么writeIndex才不为0,才能从compositeByteBuf中读到数据。
2.wrapedBuffer()方法,将byte[]数组包装成ByteBuf对象。
byte[] bytes = data.getBytes(); ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
Unpooled.wrappedBuffer(bytes)就是进行了byte[]数组的包装工作,过程中不存在内存拷贝。
即包装出来的ByteBuf和byte[]数组指向了同一个存储空间。因为值引用,所以bytes修改也会影响byteBuf 的值。
3.ByteBuf的分割,slice()方法。将一个ByteBuf对象切分成多个ByteBuf对象。
ByteBuf directByteBuf = ByteBufAllocator.DEFAULT.directBuffer(1024); ByteBuf header = directByteBuf.slice(0,50); ByteBuf body = directByteBuf.slice(51,1024);
header和body两个ByteBuf对象实际上还是指向directByteBuf的存储空间。
总结:
本文很长很长,博主陆陆续续写了有一个月的时间。但是只是窥探Netty内存池中的冰山一角,更多是要在实际项目中进行验证才能起到效果。
关于Netty的文章会持续更新,共勉!~~~喜欢的话,给个推荐,如果不足和错误之处,请予以斧正~
参考:
Netty之有效规避内存泄漏
对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解
Netty4使用心得
Netty内存池原理分析
Netty官方wiki