背景:
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换,更多的信息见前一篇说明。它的主要功能有以下几点:
1,不时地监控redis是否按照预期良好地运行;
2,如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
3,能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址。
Redis-Replication
1)搭建
复制的配置很简单,就一个参数:
slaveof <主数据库IP> <端口>
可以添加在配置文件里,也可以在命令行中执行。如主数据库IP是192.168.200.25 端口是6379:(配置多台从数据库的方法也一样)
slaveof 192.168.200.25 6379
注意:通过命令行进行的复制,在主从断开或则主从重启之后复制信息会丢失,即不能保证持久复制,需要再次执行slaveof。但是在配置文件里写死slaveof不会有该问题。默认情况下从库是只读的,不能进行修改,需要修改需要设置配置文件中的slave-read-only为no。在命令行里执行slaveof no one可以让一个从库变成主库。
2)原理(执行步骤)
①从数据库向主数据库发送sync命令。
②主数据库接收sync命令后,执行BGSAVE命令(保存快照),创建一个RDB文件,在创建RDB文件期间的命令将保存在缓冲区中。
③当主数据库执行完BGSAVE时,会向从数据库发送RDB文件,而从数据库会接收并载入该文件。
④主数据库将缓冲区的所有写命令发给从服务器执行。
⑤以上处理完之后,之后主数据库每执行一个写命令,都会将被执行的写命令发送给从数据库。
注意:在Redis2.8之前,主从断线或则重启之后再重连接,都需要做一次完整的sync操作(5步骤),即使断线期间只有几条的更新操作或则是没有操作,导致系统资源极度浪费。Redis2.8之后,会用一个psync来替换sync,不会进行完成的sync操作,只需要同步断线期间的记录。相关参数:repl-backlog-size、repl-backlog-ttl
大致的示意图如下:

3)相关的参数,注释掉的参数都是使用默认值。
################################# REPLICATION #################################
#复制选项,slave复制对应的master。
# slaveof
#如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。
# masterauth
#当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
slave-serve-stale-data yes
#作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)。
slave-read-only yes
#是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。
repl-diskless-sync no
#diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。所以最好等待一段时间,等更多的slave连上来。
repl-diskless-sync-delay 5
#slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
# repl-ping-slave-period 10
#复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
# repl-timeout 60
#是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。默认是no,即使用tcp nodelay。如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。但是这也可能带来数据的延迟。默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no
#复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m。
# repl-backlog-size 5mb
#master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
# repl-backlog-ttl 3600
#当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。而配置成0,永远不会被选举。
slave-priority 100
#redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能。
# min-slaves-to-write 3
#延迟小于min-slaves-max-lag秒的slave才认为是健康的slave。
# min-slaves-max-lag 10
4)总结
Redis目前的复制是异步的,只保证最终一致性,而不是强一致性(主从数据库的更新还是分先后,先主后从)。要是一致性要求高的应用,目前还是读写都在主库上去。
Redis-Sentinel:需要对redis和sentinel的配置文件有rewrite的权限。
1)搭建:(环境:redis服务3个实例10086、10087、10088;sentinel服务3个监控:20086、20087、20088)
sentinel是一个"监视器",根据被监视实例的身份和状态来判断该执行何种操作。通过给定的配置文件来发现主服务器的,再通过向主服务器发送的info信息来发现该主服务器的从服务器。Sentinel 实际上就是一个运行在 Sentienl 模式下的 Redis 服务器,所以我们同样可以使用以下命令来启动一个 Sentinel实例。运行方式如下:
redis-sentinel /path/to/sentinel.conf
参数配置文件:
port 20086 #默认端口26379 dir "/tmp" logfile "/var/log/redis/sentinel_20086.log" daemonize yes #格式:sentinel;#该行的意思是:监控的master的名字叫做T1(自定义),地址为127.0.0.1:10086,行尾最后的一个2代表在sentinel集群中,多少个sentinel认为masters死了,才能真正认为该master不可用了。 sentinel monitor T1 127.0.0.1 10086 2
#sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒,默认30秒。 sentinel down-after-milliseconds T1 15000
#failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。默认180秒,即3分钟。 sentinel failover-timeout T1 120000
#在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。 sentinel parallel-syncs T1 1
#sentinel 连接设置了密码的主和从
#sentinel auth-passxxxxx
#发生切换之后执行的一个自定义脚本:如发邮件、vip切换等
##sentinel notification-script##不会执行,疑问?
#sentinel client-reconfig-script##这个会执行
注意:要是参数配置的是默认值,在sentinel运行时该参数会在配置文件文件里被删除掉,直接不显示。也可以在运行时用命令SENTINEL SET command动态修改,后面说明。
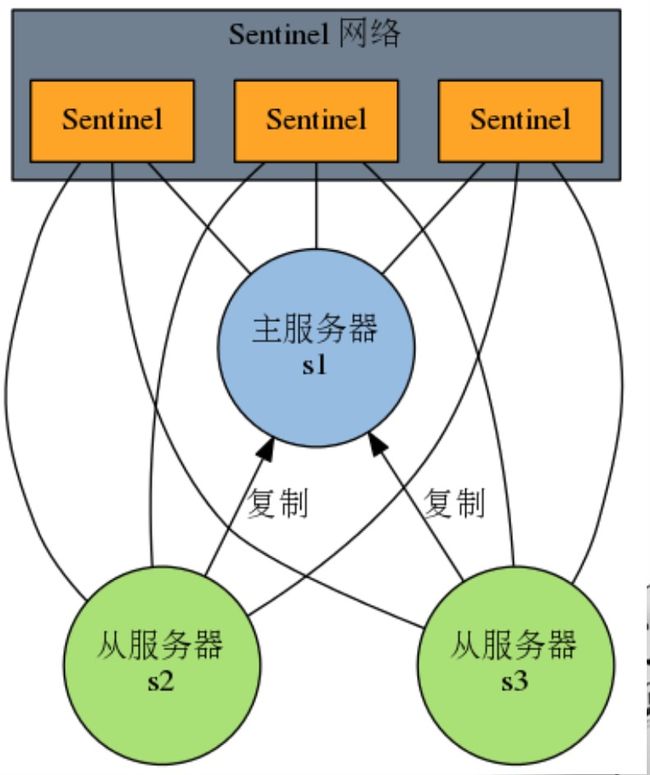
很显然,只使用单个sentinel进程来监控redis集群是不可靠的,当sentinel进程宕掉后(sentinel本身也有单点问题,single-point-of-failure)整个集群系统将无法按照预期的方式运行。所以有必要将sentinel集群,这样有几个好处:
1:即使有一些sentinel进程宕掉了,依然可以进行redis集群的主备切换;
2:如果只有一个sentinel进程,如果这个进程运行出错,或者是网络堵塞,那么将无法实现redis集群的主备切换(单点问题);
3:如果有多个sentinel,redis的客户端可以随意地连接任意一个sentinel来获得关于redis集群中的信息。
本文开启sentinel集群用了3个实例,保证各个端口和目录不一致,配置文件如下:
sentinel_20086.conf :
port 20086 dir "/var/lib/sentinel_20086" logfile "/var/log/redis/sentinel_20086.log" daemonize yes sentinel monitor T1 127.0.0.1 10086 2 sentinel down-after-milliseconds T1 15000 sentinel failover-timeout T1 120000 sentinel parallel-syncs T1 1 #发生切换之后执行的一个自定义脚本:如发邮件、vip切换等 #sentinel notification-script
sentinel_20087.conf :
port 20087 dir "/var/lib/sentinel_20087" logfile "/var/log/redis/sentinel_20087.log" daemonize yes sentinel monitor T1 127.0.0.1 10086 2 sentinel down-after-milliseconds T1 15000 sentinel failover-timeout T1 120000 sentinel parallel-syncs T1 1 #发生切换之后执行的一个自定义脚本:如发邮件、vip切换等 #sentinel notification-script
sentinel_20088.conf :
port 20088 dir "/var/lib/sentinel_20086" logfile "/var/log/redis/sentinel_20088.log" daemonize yes sentinel monitor T1 127.0.0.1 10086 2 sentinel down-after-milliseconds T1 15000 sentinel failover-timeout T1 120000 sentinel parallel-syncs T1 1 #发生切换之后执行的一个自定义脚本:如发邮件、vip切换等 #sentinel notification-script
疑问:这里的参数 sentinel notification-script
启动sentinel:
root@zhoujinyi:/etc/redis# redis-sentinel /etc/redis/sentinel_20086.conf
root@zhoujinyi:/etc/redis# redis-sentinel /etc/redis/sentinel_20087.conf
root@zhoujinyi:/etc/redis# redis-sentinel /etc/redis/sentinel_20088.conf
注意:当一个master配置为需要密码才能连接时,客户端和slave在连接时都需要提供密码。master通过requirepass设置自身的密码,不提供密码无法连接到这个master。slave通过masterauth来设置访问master时的密码。客户端需要auth提供密码,但是当使用了sentinel时,由于一个master可能会变成一个slave,一个slave也可能会变成master,所以需要同时设置上述两个配置项,并且sentinel需要连接master和slave,需要设置参数:sentinel auth-pass
启动后各个sentinel的日志信息如下:
3462:X 08 Jun 18:07:54.820 # Sentinel runid is b44bb512b3b756c97f48aff1dc37b54a30659ee9 3462:X 08 Jun 18:07:54.820 # +monitor master T1 127.0.0.1 10086 quorum 2 #主加入监控 3462:X 08 Jun 18:07:54.823 * +slave slave 127.0.0.1:10087 127.0.0.1 10087 @ T1 127.0.0.1 10086 #检测到一个slave并添加进slave列表 3462:X 08 Jun 18:07:54.823 * +slave slave 127.0.0.1:10088 127.0.0.1 10088 @ T1 127.0.0.1 10086 #检测到一个slave并添加进slave列表 3462:X 08 Jun 18:07:59.515 * +sentinel sentinel 127.0.0.1:20087 127.0.0.1 20087 @ T1 127.0.0.1 10086 #增加了一个sentinel 3462:X 08 Jun 18:08:01.820 * +sentinel sentinel 127.0.0.1:20088 127.0.0.1 20088 @ T1 127.0.0.1 10086 #增加了一个sentinel
关于更多的信息见:
+reset-master-- 当master被重置时. +slave -- 当检测到一个slave并添加进slave列表时. +failover-state-reconf-slaves -- Failover状态变为reconf-slaves状态时 +failover-detected -- 当failover发生时 +slave-reconf-sent -- sentinel发送SLAVEOF命令把它重新配置时 +slave-reconf-inprog -- slave被重新配置为另外一个master的slave,但数据复制还未发生时。 +slave-reconf-done -- slave被重新配置为另外一个master的slave并且数据复制已经与master同步时。 -dup-sentinel -- 删除指定master上的冗余sentinel时 (当一个sentinel重新启动时,可能会发生这个事件). +sentinel -- 当master增加了一个sentinel时。 +sdown -- 进入SDOWN状态时; -sdown -- 离开SDOWN状态时。 +odown -- 进入ODOWN状态时。 -odown -- 离开ODOWN状态时。 +new-epoch -- 当前配置版本被更新时。 +try-failover -- 达到failover条件,正等待其他sentinel的选举。 +elected-leader -- 被选举为去执行failover的时候。 +failover-state-select-slave -- 开始要选择一个slave当选新master时。 no-good-slave -- 没有合适的slave来担当新master selected-slave -- 找到了一个适合的slave来担当新master failover-state-send-slaveof-noone -- 当把选择为新master的slave的身份进行切换的时候。 failover-end-for-timeout -- failover由于超时而失败时。 failover-end -- failover成功完成时。 switch-master -- 当master的地址发生变化时。通常这是客户端最感兴趣的消息了。 +tilt -- 进入Tilt模式。 -tilt -- 退出Tilt模式。
2)原理
①sentinel集群通过给定的配置文件发现master,启动时会监控master。通过向master发送info信息获得该服务器下面的所有从服务器。
②sentinel集群通过命令连接向被监视的主从服务器发送hello信息(每秒一次),该信息包括sentinel本身的ip、端口、id等内容,以此来向其他sentinel宣告自己的存在。
③sentinel集群通过订阅连接接收其他sentinel发送的hello信息,以此来发现监视同一个主服务器的其他sentinel;集群之间会互相创建命令连接用于通信,因为已经有主从服务器作为发送和接收hello信息的中介,sentinel之间不会创建订阅连接。
④sentinel集群使用ping命令来检测实例的状态,如果在指定的时间内(down-after-milliseconds)没有回复或则返回错误的回复,那么该实例被判为下线。
⑤当failover主备切换被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover,即进行failover的sentinel会去获得指定quorum个的sentinel的授权,成功后进入ODOWN状态。如在5个sentinel中配置了2个quorum,等到2个sentinel认为master死了就执行failover。
⑥sentinel向选为master的slave发送SLAVEOF NO ONE命令,选择slave的条件是sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。如果优先级和下标都相同,就选择进程ID较小的。
⑦sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号(config-epoch),当failover执行结束以后,这个版本号将会被用于最新的配置,通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
①到③是自动发现机制:
- 以10秒一次的频率,向被监视的master发送info命令,根据回复获取master当前信息。
- 以1秒一次的频率,向所有redis服务器、包含sentinel在内发送PING命令,通过回复判断服务器是否在线。
- 以2秒一次的频率,通过向所有被监视的master,slave服务器发送当前sentinel,master信息的消息。
④是检测机制,⑤和⑥是failover机制,⑦是更新配置机制。
注意:因为redis采用的是异步复制,没有办法避免数据的丢失。但可以通过以下配置来使得数据不会丢失:min-slaves-to-write 1 、 min-slaves-max-lag 10。一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。要注意到master也是有可能通过failover变成slave的。如果一个redis的slave优先级配置为0,那么它将永远不会被选为master,但是它依然会从master哪里复制数据。
上面大致讲解了sentinel的运行机制,更多详细说明信息见上一篇文章。
3)运行测试
上面已经搭好了一个简单的测试环境:redis服务3个实例10086(M)、10087(S)、10088(S);sentinel服务3个监控:20086、20087、20088
现在进行一个故障转移的操作:0点30分14秒kill掉10086,Sentinel日志信息:
3466:X 09 Jun 00:30:29.067 # +sdown master T1 127.0.0.1 10086 ##进入主观不可用(SDOWN) 3466:X 09 Jun 00:30:29.169 # +odown master T1 127.0.0.1 10086 #quorum 2/2 ##投票好了,达到了quorum,进入客观不可用(ODOWN) 3466:X 09 Jun 00:30:29.169 # +new-epoch 1 ##当前配置版本被更新 3466:X 09 Jun 00:30:29.169 # +try-failover master T1 127.0.0.1 10086 ##达到failover条件,正等待其他sentinel的选举 3466:X 09 Jun 00:30:29.179 # +vote-for-leader e106f1eaffdaa10babef3f5858a7cb8d05ffe9ea 1 ##选举 3466:X 09 Jun 00:30:29.183 # 127.0.0.1:20088 voted for e106f1eaffdaa10babef3f5858a7cb8d05ffe9ea 1 ##选举 3466:X 09 Jun 00:30:29.184 # 127.0.0.1:20086 voted for e106f1eaffdaa10babef3f5858a7cb8d05ffe9ea 1 ##选举 3466:X 09 Jun 00:30:29.241 # +elected-leader master T1 127.0.0.1 10086 ##执行failover 3466:X 09 Jun 00:30:29.242 # +failover-state-select-slave master T1 127.0.0.1 10086 ##开始要选择一个slave当选新master 3466:X 09 Jun 00:30:29.344 # +selected-slave slave 127.0.0.1:10088 127.0.0.1 10088 @ T1 127.0.0.1 10086 ##找到了一个适合的slave来担当新master 3466:X 09 Jun 00:30:29.344 * +failover-state-send-slaveof-noone slave 127.0.0.1:10088 127.0.0.1 10088 @ T1 127.0.0.1 10086 ##当把选择为新master的slave的身份进行切换 3466:X 09 Jun 00:30:29.447 * +failover-state-wait-promotion slave 127.0.0.1:10088 127.0.0.1 10088 @ T1 127.0.0.1 10086 3466:X 09 Jun 00:30:30.206 # +promoted-slave slave 127.0.0.1:10088 127.0.0.1 10088 @ T1 127.0.0.1 10086 3466:X 09 Jun 00:30:30.207 # +failover-state-reconf-slaves master T1 127.0.0.1 10086 ##Failover状态变为reconf-slaves 3466:X 09 Jun 00:30:30.273 * +slave-reconf-sent slave 127.0.0.1:10087 127.0.0.1 10087 @ T1 127.0.0.1 10086 ##sentinel发送SLAVEOF命令把它重新配置,重新配置到新主 3466:X 09 Jun 00:30:31.250 * +slave-reconf-inprog slave 127.0.0.1:10087 127.0.0.1 10087 @ T1 127.0.0.1 10086 ##slave被重新配置为另外一个master的slave,但数据复制还未发生 3466:X 09 Jun 00:30:31.251 * +slave-reconf-done slave 127.0.0.1:10087 127.0.0.1 10087 @ T1 127.0.0.1 10086 ##slave被重新配置为另外一个master的slave并且数据复制已经与master同步 3466:X 09 Jun 00:30:31.340 # -odown master T1 127.0.0.1 10086 ##离开客观不可用(ODOWN) 3466:X 09 Jun 00:30:31.340 # +failover-end master T1 127.0.0.1 10086 ##failover成功完成 3466:X 09 Jun 00:30:31.341 # +switch-master T1 127.0.0.1 10086 127.0.0.1 10088 ##master的地址发生变化 3466:X 09 Jun 00:30:31.341 * +slave slave 127.0.0.1:10087 127.0.0.1 10087 @ T1 127.0.0.1 10088 ##检测到一个slave并添加进slave列表 3466:X 09 Jun 00:30:31.351 * +slave slave 127.0.0.1:10086 127.0.0.1 10086 @ T1 127.0.0.1 10088 3466:X 09 Jun 00:30:46.362 # +sdown slave 127.0.0.1:10086 127.0.0.1 10086 @ T1 127.0.0.1 10088 ##原主进入主观不可用状态
通过日志信息看到,15秒(down-after-milliseconds)之后进行了failvoer操作,最后操作成功,10088变成了新主,可以通过info sentinel和sentinel maters查看主的信息。把原主开起来,日志信息:
3466:X 09 Jun 01:00:35.306 # -sdown slave 127.0.0.1:10086 127.0.0.1 10086 @ T1 127.0.0.1 10088 ##离开主观不可用状态 3466:X 09 Jun 01:00:45.249 * +convert-to-slave slave 127.0.0.1:10086 127.0.0.1 10086 @ T1 127.0.0.1 10088 ## 检测到一个slave并添加进slave列表
通过日志看到,原主起来之后变成了从。这里可以发现在redis配置文件(可写权限)的最后被添加了:
# Generated by CONFIG REWRITE slaveof 127.0.0.1 10088
在新主上操作,可以同步复制到从库:
root@zhoujinyi:~# redis-cli -p 10088 127.0.0.1:10088> set dxy dxy OK 127.0.0.1:10088> get dxy "dxy" 127.0.0.1:10088> root@zhoujinyi:~# redis-cli -p 10086 127.0.0.1:10086> get dxy "dxy" 127.0.0.1:10086> root@zhoujinyi:~# redis-cli -p 10087 127.0.0.1:10087> get dxy "dxy"
上面测试说明sentinel自动failover成功。要是kill掉一个sentinel实例会怎么样?可以看日志:
3466:X 09 Jun 01:14:51.039 # +sdown sentinel 127.0.0.1:20088 127.0.0.1 20088 @ T1 127.0.0.1 10087 ##进入主观不可用 3466:X 09 Jun 01:15:32.610 # -sdown sentinel 127.0.0.1:20088 127.0.0.1 20088 @ T1 127.0.0.1 10087 ##进入客观不可用 3466:X 09 Jun 01:15:34.497 * -dup-sentinel master T1 127.0.0.1 10087 #duplicate of 127.0.0.1:20088 or a79f189986ab9d3940de48099e18a99abef4d595 ##删除指定master上的冗余sentinel时 (当一个sentinel重新启动时,可能会发生这个事件) 3466:X 09 Jun 01:15:34.498 * +sentinel sentinel 127.0.0.1:20088 127.0.0.1 20088 @ T1 127.0.0.1 10087 ##检测到一个sentinel,并进入列表
说明sentinel实例也被其他sentinel监视(上面介绍了各个sentinel相互通信),防止sentinel单点故障。通过日志看到这么多信息,这里需要注意下下面的概念:
① Leader选举:
其实在sentinels故障转移中,仍然需要一个“Leader”来调度整个过程:master的选举以及slave的重配置和同步。当集群中有多个sentinel实例时,如何选举其中一个sentinel为leader呢?
在配置文件中“can-failover”“quorum”参数,以及“is-master-down-by-addr”指令配合来完成整个过程。
A) “can-failover”用来表明当前sentinel是否可以参与“failover”过程,如果为“YES”则表明它将有能力参与“Leader”的选举,否则它将作为“Observer”,observer参与leader选举投票但不能被选举;
B) “quorum”不仅用来控制master ODOWN状态确认,同时还用来选举leader时最小“赞同票”数;
C) “is-master-down-by-addr”,在上文中以及提到,它可以用来检测“ip + port”的master是否已经处于SDOWN状态,不过此指令不仅能够获得master是否处于SDOWN,同时它还额外的返回当前sentinel本地“投票选举”的Leader信息(runid);
每个sentinel实例都持有其他的sentinels信息,在Leader选举过程中(当为leader的sentinel实例失效时,有可能master server并没失效,注意分开理解),sentinel实例将从所有的sentinels集合中去除“can-failover = no”和状态为SDOWN的sentinels,在剩余的sentinels列表中按照runid按照“字典”顺序排序后,取出runid最小的sentinel实例,并将它“投票选举”为Leader,并在其他sentinel发送的“is-master-down-by-addr”指令时将推选的runid追加到响应中。每个sentinel实例都会检测“is-master-down-by-addr”的响应结果,如果“投票选举”的leader为自己,且状态正常的sentinels实例中,“赞同者”的自己的sentinel个数不小于(>=) 50% + 1,且不小与
在sentinel.conf文件中,我们期望有足够多的sentinel实例配置“can-failover yes”,这样能够确保当leader失效时,能够选举某个sentinel为leader,以便进行failover。如果leader无法产生,比如较少的sentinels实例有效,那么failover过程将无法继续。
② failover过程:
在Leader触发failover之前,首先wait数秒(随即0~5),以便让其他sentinel实例准备和调整(有可能多个leader??),如果一切正常,那么leader就需要开始将一个salve提升为master,此slave必须为状态良好(不能处于SDOWN/ODOWN状态)且权重值最低(redis.conf中)的,当master身份被确认后,开始failover
A)“+failover-triggered”: Leader开始进行failover,此后紧跟着“+failover-state-wait-start”,wait数秒。
B)“+failover-state-select-slave”: Leader开始查找合适的slave
C)“+selected-slave”: 已经找到合适的slave
D) “+failover-state-sen-slaveof-noone”: Leader向slave发送“slaveof no one”指令,此时slave已经完成角色转换,此slave即为master
E) “+failover-state-wait-promotition”: 等待其他sentinel确认slave
F)“+promoted-slave”:确认成功
G)“+failover-state-reconf-slaves”: 开始对slaves进行reconfig操作。
H)“+slave-reconf-sent”:向指定的slave发送“slaveof”指令,告知此slave跟随新的master
I)“+slave-reconf-inprog”: 此slave正在执行slaveof + SYNC过程,如过slave收到“+slave-reconf-sent”之后将会执行slaveof操作。
J)“+slave-reconf-done”: 此slave同步完成,此后leader可以继续下一个slave的reconfig操作。循环G)
K)“+failover-end”: 故障转移结束
L)“+switch-master”:故障转移成功后,各个sentinel实例开始监控新的master。
4)命令查看、修改
查看:
①:info命令
127.0.0.1:20086> info # Server redis_version:3.0.0 #版本号 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:e7768317ba5bdca5 redis_mode:sentinel #开启模式 os:Linux 3.16.0-71-generic x86_64 #系统位数 arch_bits:64 multiplexing_api:epoll gcc_version:4.8.2 process_id:2767 #线程ID run_id:319d8c58b9bf26c26ca040b53bdc0764a543648b tcp_port:20086 #端口 uptime_in_seconds:923 #允许时间 uptime_in_days:0 hz:11 lru_clock:6041117 config_file:/etc/redis/sentinel_20086.conf #配置文件 # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 master0:name=T1,status=ok,address=127.0.0.1:10087,slaves=2,sentinels=3 #主name,主ip,多少个slave,多少个sentinel
也可以单个显示:info server、info sentinel。
②:sentinel masters,显示被监控的所有master以及它们的状态。要是有多个master就显示多个(复用,监控多个redis,即一个配置文件写多个),例子就1个master
127.0.0.1:20086> SENTINEL masters 1) 1) "name" #master name 2) "T1" 3) "ip" #master ip 4) "127.0.0.1" 5) "port" #master port 6) "10087" 7) "runid" 8) "508e7de9f5aa4fdb70126d62a54392fbefc0b11b" 9) "flags" 10) "master" 11) "pending-commands" 12) "0" 13) "last-ping-sent" 14) "0" 15) "last-ok-ping-reply" 16) "261" 17) "last-ping-reply" 18) "261" 19) "down-after-milliseconds" #ping的响应时间 20) "15000" 21) "info-refresh" 22) "620" 23) "role-reported" 24) "master" 25) "role-reported-time" 26) "1205058" 27) "config-epoch" #配置文件版本号 28) "2" 29) "num-slaves" #从的数量 30) "2" 31) "num-other-sentinels" #除本身外还有多少个sentinel 32) "2" 33) "quorum" #投票数量 34) "2" 35) "failover-timeout" #failover超时时间 36) "120000" 37) "parallel-syncs" #多少个从同步 38) "1"
③:sentinel master
127.0.0.1:20086> sentinel master T1 1) "name" 2) "T1" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10087" 7) "runid" 8) "508e7de9f5aa4fdb70126d62a54392fbefc0b11b" 9) "flags" 10) "master" 11) "pending-commands" 12) "0" 13) "last-ping-sent" 14) "0" 15) "last-ok-ping-reply" 16) "909" 17) "last-ping-reply" 18) "909" 19) "down-after-milliseconds" 20) "15000" 21) "info-refresh" 22) "5820" 23) "role-reported" 24) "master" 25) "role-reported-time" 26) "1501345" 27) "config-epoch" 28) "2" 29) "num-slaves" 30) "2" 31) "num-other-sentinels" 32) "2" 33) "quorum" 34) "2" 35) "failover-timeout" 36) "120000" 37) "parallel-syncs" 38) "1"
④:sentinel slaves
127.0.0.1:20086> sentinel slaves T1 1) 1) "name" 2) "127.0.0.1:10088" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10088" 7) "runid" 8) "380a4d9e32aefd3a00c7a64ba8bce451643044f1" 9) "flags" 10) "slave" 11) "pending-commands" 12) "0" 13) "last-ping-sent" 14) "0" 15) "last-ok-ping-reply" 16) "15" 17) "last-ping-reply" 18) "15" 19) "down-after-milliseconds" 20) "15000" 21) "info-refresh" 22) "7558" 23) "role-reported" 24) "slave" 25) "role-reported-time" 26) "1934978" 27) "master-link-down-time" 28) "0" 29) "master-link-status" 30) "ok" 31) "master-host" 32) "127.0.0.1" 33) "master-port" 34) "10087" 35) "slave-priority" 36) "100" 37) "slave-repl-offset" 38) "361068" 2) 1) "name" 2) "127.0.0.1:10086" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10086" 7) "runid" 8) "9babf78ee2b420d2671b12f93b68c4d19a5edf08" 9) "flags" 10) "slave" 11) "pending-commands" 12) "0" 13) "last-ping-sent" 14) "0" 15) "last-ok-ping-reply" 16) "15" 17) "last-ping-reply" 18) "15" 19) "down-after-milliseconds" 20) "15000" 21) "info-refresh" 22) "7558" 23) "role-reported" 24) "slave" 25) "role-reported-time" 26) "1934978" 27) "master-link-down-time" 28) "0" 29) "master-link-status" 30) "ok" 31) "master-host" 32) "127.0.0.1" 33) "master-port" 34) "10087" 35) "slave-priority" 36) "100" 37) "slave-repl-offset" 38) "361068"
⑤:sentinel get-master-addr-by-name 返回指定master的ip和端口,如果正在进行failover或者failover已经完成,将会显示被提升为master的slave的ip和端口。
27.0.0.1:20086> sentinel get-master-addr-by-name T1 1) "127.0.0.1" 2) "10087"
⑥:sentinel reset
sentinel reset *
⑦:sentinel failover 强制sentinel执行failover,并且不需要得到其他sentinel的同意。但是failover后会将最新的配置发送给其他sentinel。
127.0.0.1:20086> sentinel failover T1 OK 127.0.0.1:20086> sentinel get-master-addr-by-name T1 1) "127.0.0.1" 2) "10088" #主被切换了
⑧:查看其他sentinel信息
sentinel sentinels T1
⑨:检查sentinel监控是否正确
sentinel ckquorum T1
⑩:配置文件丢失,重写配置文件
sentinel flushconfig
修改:包括参数
①:sentinel monitor
127.0.0.1:20086> SENTINEL MONITOR T2 127.0.0.1 10089 2 OK
②:sentinel remove 命令sentinel放弃对某个master的监听。删掉上一个加的:
127.0.0.1:20086> sentinel remove T2 OK
③:sentinel set 这个命令很像Redis的CONFIG SET命令,用来改变指定master的配置。支持多个
127.0.0.1:20086> sentinel masters 1) ... 37) "parallel-syncs" 38) "1" 127.0.0.1:20086> sentinel set T1 parallel-syncs 2 #格式 OK 127.0.0.1:20086> sentinel masters 1) ... 37) "parallel-syncs" 38) "2"
注意:只要是配置文件中存在的配置项,都可以用SENTINEL SET命令来设置。这个还可以用来设置master的属性,比如说quorum(票数),而不需要先删除master,再重新添加master。
5) 增加或删除Sentinel
增加一个sentinel很简单,直接配置好参数开启一个sentinel即可。添加时最好一个接着一个添加,这样可以预防网络隔离带来的问题,可以每个30秒添加一个sentinel。通过SENTINEL MASTER mastername(T1)中的num-other-sentinels来查看是否成功添加sentinel。删除一个sentinel稍微复杂一点,sentinel永远不会删除一个已经存在过的sentinel,即使它已经与组织失去联系。遵循如下步骤:
-
停止所要删除的sentinel
-
发送一个
SENTINEL RESET *命令给所有其它的sentinel实例,如果你想要重置指定master上面的sentinel,只需要把*号改为特定的名字,注意,需要一个接一个发,每次发送的间隔不低于30秒。 -
检查一下所有的sentinels是否都有一致的当前sentinel数。使用
SENTINEL MASTER mastername来查询。
首先 kill 掉一个sentinel
127.0.0.1:20086> sentinel master T1 1) "name" 2) "T1" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10088" ... 31) "num-other-sentinels" 32) "2" ... 127.0.0.1:20086> sentinel reset T1 #重新导入或则执行下面的 (integer) 1 127.0.0.1:20086> sentinel reset * #因为只有监视一个主,所以和上面一致 (integer) 1 127.0.0.1:20086> sentinel masters 1) 1) "name" 2) "T1" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10088" ... ... 31) "num-other-sentinels" #sentinel slave的数量 32) "1" ...
6)删除旧master或者不可达slave
要永久地删除掉一个slave(有可能它曾经是个master),你只需要发送一个SENTINEL RESET master命令给所有的sentinels,它们将会更新列表里能够正确地复制master数据的slave。 遵循如下步骤:
-
停止所要删除的redis slave。
-
发送一个
SENTINEL RESET *命令给所有其它的sentinel实例,如果你想要重置指定master上面的slave,只需要把*号改为特定的名字。 -
检查一下所有的sentinels是否都有一致的当前sentinel数。使用
SENTINEL MASTER mastername来查询。
首先 kill 掉一个slave 127.0.0.1:20086> sentinel masters 1) 1) "name" 2) "T1" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10088" ... 29) "num-slaves" #多少个slave 30) "2" ... 127.0.0.1:20086> sentinel reset T1 #重新导入或则执行下面的 (integer) 1 127.0.0.1:20086> sentinel reset * #和上面一致 (integer) 1 127.0.0.1:20086> sentinel masters 1) 1) "name" 2) "T1" 3) "ip" 4) "127.0.0.1" 5) "port" 6) "10088" ... 29) "num-slaves" #多少个slave 30) "1" ...
注意:要是再次开启关闭掉的redis slave会继续当成一个slave,若要彻底关闭slave,则需要修改关闭掉的redis配置文件中最后的:
# Generated by CONFIG REWRITE slaveof 127.0.0.1 10088 #关闭改参数
7)总结
Redis-Sentinel是Redis官方推荐的高可用性(HA) 解决方案,Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。Sentinel可以监视任意多个主服务器(复用),以及主服务器属下的从服务器,并在被监视的主服务器下线时,自动执行故障转移操作。

为了防止sentinel的单点故障,可以对sentinel进行集群化,创建多个sentinel。
参考文档:
Redis Sentinel机制与用法说明
Redis Replication、Sentinel、Cluster原理说明
Redis哨兵-实现Redis高可用
集群Failover解决方案