聚类是一种无监督学习的分类算法,我们一般选择使用k-means,聚类速度快,k-means随机选择重心,然后把样本点分配到离他们最近的类,在通过迭代吧该类的重心移到该类全部成员位置的平均值那里,以此类推进行迭代,但由于没有固定的类别标记,所以类别的数量和聚类的效果就需要我们通过肘部法则和轮廓系数进行判断。
肘部法则--聚类数量选择
肘部法则的计算原理是成本函数,成本函数是类别畸变程度之和,每个类的畸变程度等于每个变量点到其类别中心的位置距离平方和,若类内部的成员彼此间越紧凑则类的畸变程度越小,反之,若类内部的成员彼此间越分散则类的畸变程度越大。在选择类别数量上,肘部法则会把不同值的成本函数值画出来。随着值的增大,平均畸变程度会减小;每个类包含的样本数会减少,于是样本离其重心会更近。但是,随着值继续增大,平均畸变程度的改善效果会不断减低。值增大过程中,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
python代码实现:
#新建模拟变量
import numpy as np
import matplotlib.pyplotas plt
cluster1 = np.random.uniform(0.5,1.5,(2,10))
#随机生成0.5--1.5之间的数值,生成2*20个,2表示的是两个列表,10表示一个列表10行,整个在组成一个数组
cluster2 = np.random.uniform(3.5,4.5,(2,10))
x = np.hstack((cluster1,cluster2))
#此函数为水平按列进行堆叠,如果xy是两个列表则横向堆叠,如果xy分别是2*2列表,则为一列一列的横向堆叠
#所以上面的两个使用hstack之后应该是2*1的列表形式
#另外这个函数必须是加两个括号
x = x.T
plt.figure()
plt.subplot(2,1,1)
plt.axis([0,5,0,5])#设置xy轴范围,和xlim的意思一样,都必须是列表形式呈现
plt.grid(True)#自动排版设置,生成网格线
plt.plot(x[:,0],x[:,1],'k.')#生成点的散点图
#肘部法则计算
from matplotlib.font_managerimport FontProperties
font = FontProperties(fname =r'c:\windows\fonts\msyh.ttc',size =10)
#coding:utf-8
from sklearn.clusterimport KMeans
from scipy.spatial.distanceimport cdist
K =range(1,10)
meandistortion = []
for kin K:
kmeans = KMeans(n_clusters = k)
kmeans.fit(x)
meandistortion.append(
(sum(
np.min(
cdist(x,kmeans.cluster_centers_,'euclidean'), axis =1))) /x.shape[0])
plt.subplot(2,1,2)
plt.plot(K,meandistortion,'bx-')
plt.xlabel('k')
plt.ylabel(u'平均畸变程度',fontproperties = font)
plt.title(u'用肘部法则确定的最佳k值',fontproperties = font)
轮廓系数--聚类效果评估
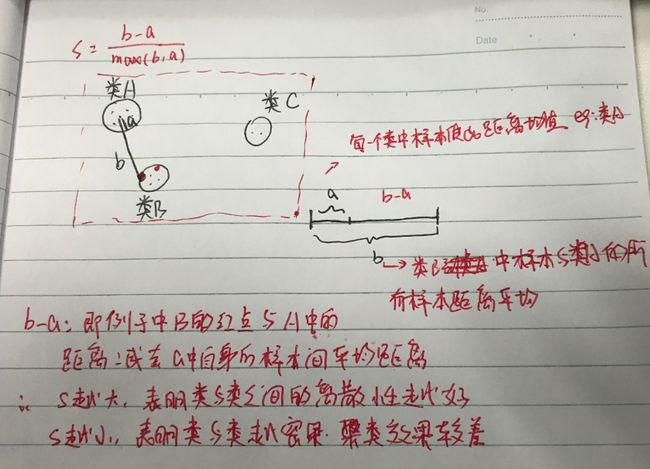
轮廓系数是度量类的密集与分散程度,它会随着类的规模增大而增大,彼此相距很远,本身很密集的类,其轮廓系数较大,彼此集中,本身很大的类,其轮廓系数较小。第一次看这个轮廓系数的时候觉得这个设定真的很经典,所以自己做了一份笔记,直接看图的解释吧
python代码实现:
import numpy as np
from sklearn.clusterimport KMeans
from sklearn import metrics
from matplotlib.font_managerimport FontProperties
font = FontProperties(fname =r'c:\windows\fonts\msyh.ttc',size =10)
#设置字体样式和大小,前面带r表示转义,这个经常用到
import matplotlib.pyplotas plt
plt.figure(figsize = (8,10))#设置画布的尺寸,这个是长方形的
plt.subplot(3,2,1)#设置图形个数,3行2列的第一个
x1 = np.array([1, 2, 3, 1, 5, 6, 5, 5, 6, 7, 8, 9, 7,9])
x2 = np.array([1, 3, 2, 2, 8, 6, 7, 6, 7, 1, 2, 1, 1, 3])
x = np.array(list(zip(x1,x2))).reshape(len(x1),2)
#上面的zip是吧两种观测值变为不同指标的数值,变成横着的括起来
plt.xlim([0,10])
plt.ylim([0,10])#调整坐标轴的范围
plt.title(u'样本',fontproperties = font)
plt.scatter(x1,x2)#是绘制散点图,上面的参数放在前后无所谓
colors = ['b','g','r','c','m','y','k','b']
markers = ['o','s','D','v','^','p','*','+']
test = [2,3,4,5,8]
subplot_counter =1
for tin test:
kmeans_model = KMeans(n_clusters=t).fit(x)
subplot_counter +=1
plt.subplot(3,2,subplot_counter)
for i,L in enumerate(kmeans_model.labels_):
plt.plot(x1[i],x2[i],color = colors[L],marker = markers[L],ls ='None')
#plot其实是折线图,但是此处加上none表示线条为空,即无线条
plt.xlim([0,10])
plt.ylim([0,10])
plt.title(u'K=%s,轮廓系数 = %.03f' %(t,metrics.silhouette_score(
x,kmeans_model.labels_,metric ='euclidean')),fontproperties = font)
#metrics.silhouette_score这个函数是用来计算轮廓系数,第一个是数据集,第二个是标签分类,第三个是计算方法
#euclidean为欧式距离--指标之间的平方和开根号
不过因为k-means随机选择重心点,所以可能会形成局部最优的聚类结果,所以还需重复运行聚类函数,每次重复时,它会随机的从不同的位置开始初始化。最后把最小的成本函数对应的重心位置作为初始化位置。