在上一篇博客中介绍的论文“Show and tell”所提出的NIC模型采用的是最“简单”的encoder-decoder框架,模型上没有什么新花样,使用CNN提取图像特征,将Softmax层之前的那一层vector作为encoder端的输出并送入decoder中,使用LSTM对其解码并生成句子。模型非常直观,而且比常规的encoder-decoder框架还要简单一点(图像特征只在开始时刻输入了decoder,此后就不输入了),但是训练的过程非常讲究,因此取得了2015COCO任务的第一名。
attention机制的引入
对于seq2seq任务来说,在没有attention机制的时候,decoder在不同的时刻对接收到的信息进行解码并生成单词时,所接收到的encoder vector都是相同的。但是实际上,在生成不同的词时,所应“关注”的信息是不一样的:比如说想把“我爱自然语言处理”翻译成“I love NLP”时,生成“love”这个词的时候,模型应该更加关注“爱”这个词。attention机制就是为了实现在生成一个词时去关注当前所“应该”关注的显著(salient)信息这一目的,手段就是对输入信息的各个局部赋予权重。这篇博客介绍了在自动文摘任务中,引入attention的比较早期的工作。
Show, Attend and Tell 论文阅读笔记
[1] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention

这篇文章提出了在传统的encoder-decoder框架中结合注意机制的方法,这种结合attention机制的seq2seq学习,已经成为了机器翻译领域里的 state-of-the-art 。
本文的caption模型中,在解码的每个时刻都会接收由attention机制所计算出的编码向量。作者首先指出,此前的工作使用CNN在分类之前的最后一层vector表示作为图像特征的缺点是丢失了能够使caption变得更丰富的一些信息(NIC那篇论文也提到在分类数据集上预训练的CNN抛弃了诸如颜色等对分类没有帮助的特征),因此这里使用 low-level 的表示。随后指出这项工作使用两种attention:“soft” deterministic attention 和 “hard” stochastic attention,通过 $\phi$ 函数来控制。
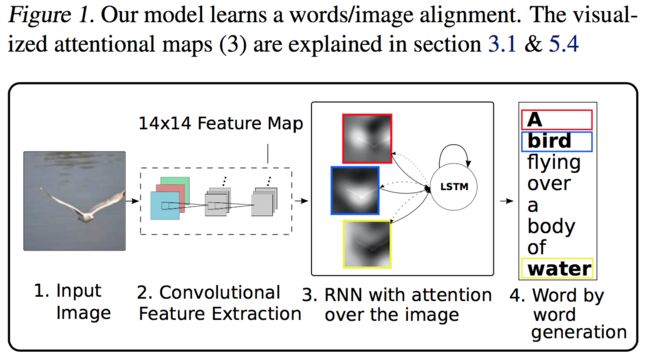
1. 模型结构
(1)encoder:卷积特征
在encoder端,模型使用CNN来提取 L 个 D 维vector,每一个都对应图像的一个区域:
$$a=\{ \textbf{a}_1,...,\textbf{a}_L \},\quad\textbf{a}_i\in\mathbb{R}^D$$
与此前的工作使用Softmax层之前的那一层vector作为图像特征不同,本文所提取的这些vector来自于 low-level 的卷积层,这使得decoder可以通过选择所有特征向量的子集来选择性地聚焦于图像的某些部分。这个样子就有点像NLP里的seq2seq任务了,这里的输入从词序列转变成了图像区域vector的序列。
(2)decoder:LSTM
用RNN来解码并生成词序列,已经是再熟悉不过的套路了,实在是不想再赘述了,但是文中提到了几个比较有意思的点。
模型生成的一句caption被表示为各个词的one-hot编码所构成的集合时:
$$y=\{ \textbf{y}_1,...,\textbf{y}_C \},\quad\textbf{y}_i\in\mathbb{R}^K$$
其中 K 是词表大小,C 是句子长度。
LSTM的数学模型如下(省略偏置,本文所有关于神经网络的式子都省略了偏置):
$$\begin{pmatrix}\textbf{i}_t \\\textbf{f}_t \\\textbf{o}_t \\\textbf{g}_t \\\end{pmatrix}=\begin{pmatrix}\sigma\\ \sigma\\ \sigma\\ \tanh \end{pmatrix}T_{D+m+n, n} \ \begin{pmatrix}E\textbf{y}_{t-1}\\ \textbf{h}_{t-1}\\ \hat{\textbf z}_t \end{pmatrix}$$
$$\textbf{c}_t=\textbf{f}_t \odot \textbf{c}_{t-1} + \textbf{i}_t \odot \textbf{g}_t$$
$$\textbf{h}_t = \textbf{o}_t \odot \tanh(\textbf{c}_t)$$
第一个式子实际上是四个式子,分别得到输入门、遗忘门、输出门和被输入门控制的候选向量。其中,三个门控由sigmoid激活,得到的是元素值皆在 0 到 1 之间的向量,可以将门控的值视作保留概率;候选向量由tanh激活,得到的是元素值皆在 -1 到 1 之间的向量。$T_{s,t}$ 代表的是从 $\mathbb R^s$ 到 $\mathbb R^t$ 的映射。
最右边括号里的三个量是四个式子共有的三个输入量:$E\textbf y_{t-1}$ 是look-up得到词 $y_{t-1}$ 的 m 维词向量;$\textbf h_{t-1}$ 是上一时刻的隐状态;$\hat{\textbf z}_t\in\mathbb R^D$ 是LSTM真正意义上的“输入”,代表的是捕捉了特定区域视觉信息的上下文向量,既然它和时刻 t 有关,就说明它是一个动态变化的量,在不同的时刻将会捕捉到与本时刻相对应的相关图像区域。这个量将由attention机制计算得到,后面会详细介绍。相比之下,在上篇博客所介绍的NIC模型中,解码过程除了在首个时刻输入了图像特征之外,随后并不存在这个输入,而本文的模型则与标准的encoder-decoder框架一样,将encoder端得到的信息在每一时刻都输入decoder。
第二个式子是更新旧的细胞状态,element-wise 的运算表示三个门控将对各自控制的向量的每个元素做“取舍”:0 到 1 分别代表完全抛弃到完全保留。
第三个式子是得到隐状态。值得注意的是,作者给出了隐状态和细胞状态的初始值的计算方式,使用两个独立的多层感知机,感知机的输入是各个图像区域特征的平均:
$$\textbf c_0=f_{\text{init,c}}(\frac1L\sum_{i=1}^L\textbf a_i)$$
$$\textbf h_0=f_{\text{init,h}}(\frac1L\sum_{i=1}^L\textbf a_i)$$
有了隐状态,就可以计算词表中各个词的概率值,那么取概率最大的那个作为当前时刻生成的词,并将作为下一时刻的输入。其实就是个全连接层:
$$p(\textbf{y}_t|\textbf{a}, \textbf y_1,...,\textbf y_{t-1}) \propto \exp (L_o (E \textbf{y}_{t-1} + L_h \textbf{h}_t + L_z \hat{\textbf{z}}_t))$$
2. attention机制
下面就是重头戏,本文提出的两种attention机制。
通过attention机制计算出的 $\hat{\textbf z}_t$ 被称为 context vector,是捕捉了特定区域视觉信息的上下文向量。
首先需要明确,attention要实现的是在解码的不同时刻可以关注不同的图像区域,进而可以生成更合理的词。那么,在attention中就有两个比较关键的量,一个是和时刻 t 相关,对应于解码时刻;另一个是输入序列的区域 $\textbf a_i$,对应图像的一个区域。
实现这种机制的方式就是在时刻 t ,为输入序列的各个区域 i 计算出一个权重 $\alpha_{ti}$ 。因为需要满足输入序列的各个区域的权重是加和为一的,使用Softmax来实现这一点。至于Softmax需要输入的信息,则如上所讲,需要包含两个方面:一个是被计算的区域 $\textbf a_i$ ,另一个就是上一时刻 t-1 的信息 $\textbf h_{t-1}$ :
$$e_{ti}=f_{\text{att}}(\textbf a_i,\textbf h_{t-1})$$
$$\alpha_{ti}=\frac{\exp(e_{ti})}{\sum_{k=1}^L\exp(e_{tk})}$$
式中的 $f_{\text{att}}$ 是耦合计算区域 i 和时刻 t 这两个信息的打分函数。文中使用多层感知机,也算是最常用的了,我觉得是因为内积太简单,而双线性的参数太多,索性用最简单粗暴的 MLP 。但是我也看过一些paper里面用好几次attention时用不一样的打分函数。
现在,有了权重,就可以计算 $\hat{\textbf z}_t$ 了:
$$\hat{\textbf z}_t=\phi(\{\textbf a_i\},\{\alpha_{ti}\})$$
这个函数 $\phi$ 就代指文中提出的两种attention机制,对应于将权重施加到图像区域到两种不同的策略。
(1)Stochastic “Hard” Attention
首先介绍文中提出的第一种attention机制,hard attention。
在 hard attention 机制中,权重 $\alpha_{ti}$ 所扮演的角色是图像区域 $\textbf a_i$ 在时刻 t 被选中作为输入decoder的信息的概率,有且仅有一个区域会被选中。为此,引入变量 $s_{t,i}$ ,当区域 i 被选中时取值为 1 ,否则为 0 。那么有
$$\hat{\textbf z}_t=\sum_{i}s_{t,i}\textbf a_i$$
这里面还尚未解决的问题就是 $s_{t,i}$ 怎么求。在本文中,将 $s_t$ 视作隐变量,为参数是 $\{\alpha_i\}$ 的多元贝努利分布(贝努利分布就是两点分布):
$$p(s_{t,i}=1|s_{j
为了使用极大似然估计,需要将隐变量 marginalize out,然后用marginal log-likelihood的下界(variational lower bound)来作为目标函数 $L_s$ ,这一思路就是EM算法的思路:
$$\begin{aligned}\log p(\textbf y|\textbf a)&=\log\sum_sp(s|\textbf a)p(\textbf y|s,\textbf a)\\&\geq \sum_sp(s|\textbf a)\log p(\textbf y|s,\textbf a)\end{aligned}$$
$$L_s=\sum_sp(s|\textbf a)\log p(\textbf y|s,\textbf a)$$
式中的 $\textbf y$ 是为图像 $\textbf a$ 生成的一句caption(由一系列one-hot编码构成的词序列)。不等号那里是琴生不等式(Jensen,我一直叫琴生,因为好听~~)。
对目标函数求梯度:
$${\partial L_s \over \partial W} = \sum_s p(s | \mathbf{a}) \left[ {\partial \log p(\mathbf{y} | s, \mathbf{a}) \over \partial W} + \log p(\mathbf{y} | s, \mathbf{a}) {\partial \log p(s | \mathbf{a}) \over \partial W} \right]$$
用 N 次蒙特卡洛采样(可以简单理解为抛硬币)来近似:
$$\overset{\sim}{s}_t \sim \mathrm{Multinoulli}_L (\{ \alpha_i \})$$
$${\partial L_s \over \partial W} \approx {1 \over N} \sum_{n=1}^N p(\overset{\sim}{s}^n | \mathbf{a}) \left[ {\partial \log p(\mathbf{y} | \overset{\sim}{s}^n, \mathbf{a}) \over \partial W} + \log p(\mathbf{y} | \overset{\sim}{s}^n, \mathbf{a}) {\partial \log p(\overset{\sim}{s}^n | \mathbf{a}) \over \partial W} \right]$$
另外,在蒙特卡洛方法估计梯度时,可以使用滑动平均来减小梯度的方差。在第 k 个mini-batch时,滑动平均被估计为先前对数似然伴随指数衰减的累积和
$$b_k=0.9b_{k-1}+0.1\log p(\textbf y|\overset{\sim}{s}_k,\textbf a)$$
为进一步减小方差,引入多元贝努利分布的熵 $\mathbb H[s]$ ;而且对于一张给定图片,0.5的概率将 $\overset{\sim}{s}$ 设置为它的期望值 $\alpha$ 。这两个技术提升了随机算法的robustness(在控制领域音译为鲁棒性,CS领域一般叫健壮性吧)。最终的学习规则为
$$\begin{aligned}{\partial L_s \over \partial W} \approx {1 \over N} \sum_{n=1}^N p(\overset{\sim}{s}^n | \mathbf{a}) &[ {\partial \log p(\mathbf{y} | \overset{\sim}{s}^n, \mathbf{a}) \over \partial W}\\& + \lambda_r (\log p(\mathbf{y} | \overset{\sim}{s}^n, \mathbf{a}) - b) {\partial \log p(\overset{\sim}{s}^n | \mathbf{a}) \over \partial W} \\&+ \lambda_e {\partial \mathbb H[\overset{\sim}{s}^n] \over \partial W} ]\end{aligned}$$
其中的两个系数是超参数。实际上,这个规则等价于REINFORCE:attention选择的一系列action的reward是与在采样attention轨迹下目标句子的对数似然成比例的。
(2)Deterministic “Soft” Attention
相比之下,在 soft attention 机制中,权重 $\alpha_{ti}$ 所扮演的角色是图像区域 $\textbf a_i$ 在时刻 t 的输入decoder的信息中的所占的比例。既然这样,就将各区域 $\textbf a_i$ 与对应的权重 $\alpha_{t,i}$ 做加权求和就可以得到 $\hat{\textbf z}_t$ :
$$\mathbb E_{p(s_t|a)}[\hat{\textbf z}_t]=\sum_{i=1}^L\alpha_{t,i}\textbf a_i$$
这就和机器翻译中非常标准的end-to-end训练非常像了,整个模型光滑、可微,利用反向传播来进行end-to-end的训练。
论文里还介绍了更多细节,比如分析了解码过程的一些情况;强迫使图像的每个区域在整个解码过程中的权重之和都相等(这种做法在目标函数中体现为一个惩罚项),来使图像的各个区域都对生成caption起到贡献;增加一个跟时间有关的维度因子可以让模型的注意力集中在图像的目标上。
3. 实验与例子
这里就不介绍模型本身以外的细节了。从结果上看,当使用BLEU作为指标时,几个数据集上都是hard attention的效果好过soft attention;而当使用Meteor作为指标时,情况相反。在论文的最后作者给出了很多对比hard attention和soft attention的展示的例子,下面摘取一例。
参考:
[1] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
[2] http://www.cosmosshadow.com/ml/神经网络/2016/03/08/Attention.html
[3] http://www.cnblogs.com/alexdeblog/p/3564317.html