
前言
java有类文件,Python有import机制,Ruby有require等,而Javascript 通过
defer 和 async属性
- defer 会让该标签引用的脚本在DOM完全解析之后,并且引用的其他脚本执行完成之后,才会执行;多个defer会按照在页面上出现的顺序依次执行
- async 类似于异步回调函数,加载完成或,渲染引擎就会立即停下来去执行该脚本,多个async脚本不能后保证执行的顺序
CommonJs
Node 的模块系统就是参照着CommonJs规范所实现的
const path = require('path') path.join(__dirname,path.sep)path.join 必然是依赖于path模块加载完成才能使用的,对于服务器来说,因为所有的资源都存放在本地,所以各种模块各种模块加载进来之后再执行先关逻辑对于速度的要求来说并不会是那么明显问题。
特点:
- 一个文件就是一个模块,拥有单独的作用域;
- 普通方式定义的变量、函数、对象都属于该模块内;
- 通过require来加载模块;
- 通过exports和modul.exports来暴露模块中的内容;
- 模块加载的顺序,按照其在代码中出现的顺序。
- 模块可以多次加载,但只会在第一次加载的时候运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果;模块的加载顺序,按照代码的出现顺序是同步加载的;
require(同步加载)基本功能:读取并执行一个JS文件,然后返回该模块的exports对象,如果没有发现指定模块会报错;
exports:node为每个模块提供一个exports变量,其指向module.exports,相当于在模块头部加了这句话:var exports = module.exports,在对外输出时,可以给exports对象添加方法(exports.xxx等同于module.exports.xxx),不能直接赋值(因为这样就切断了exports和module.exports的联系);
module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。
- module对象的属性:
- module.id模块的识别符,通常是带有绝对路径的模块文件名。
- module.filename 模块的文件名,带有绝对路径。
- module.loaded 返回一个布尔值,表示模块是否已经完成加载。
- module.parent 返回一个对象,表示调用该模块的模块。
- module.children 返回一个数组,表示该模块要用到的其他模块。
- module.exports 表示模块对外输出的值。
例子:
- 注意在这种方式下module.exports被重新赋值了,所以之前使用exports导出的hello不再有效(模块头部var exports = module.exports)
exports.hello = function() { return 'hello'; }; module.exports = 'Hello world';/因此一旦module.exports被赋值了,表明这个模块具有单一出口了
AMD
Asynchronous Module Definition异步加载某模块的规范。试想如果在浏览器中(资源不再本地)采用commonjs这种完全依赖于先加载再试用方法,那么如果一个模块特别大,网速特别慢的情况下就会出现页面卡顿的情况。便有了异步加载模块的AMD规范。require.js便是基于此规范
require(['module1','module2'....], callback); reqire([jquery],function(jquery){ //do something }) //定义模块 define(id, [depends], callback); //id是模块名,可选的依赖别的模块的数组,callback是用于return出一个给别的模块用的函数熟悉的回调函数形式。
Node的模块实现
Node 对于模块的实现以commonjs为基础的同时也增加了许多自身的特性
Node模块的引入的三个步骤
- 路径分析
- 文件定位
- 在
require参数中如果不写后缀名,node会按照.js,.node,.json的顺序依次补足并try- 此过程会调用
fs模块同步阻塞式的判断文件是否存在,因此非js文件最后加上后缀- 编译执行
.js文件会被解析为 JavaScript 文本文件,.json文件会被解析为 JSON 文本文件。.node文件会被解析为通过 dlopen 加载的编译后的插件模块.Node的模块分类
- 核心模块 Node本身提供的模块,比如
path,buffer,http等,在Node编译过程中就加载进内存,因此会省掉文件定位和编译执行两个文件加载步骤- 文件模块 开发人员自己写的模块,会经历完整的模块引入步骤
Node也会优先从缓存中加载引入过的文件模块,在Node中第一次加载某一个模块的时候,Node就会缓存下该模块,之后再加载模块就会直接从缓存中取了。这个“潜规则”核心模块和文件模块都会有。
require('./test.js').message='hello' console.log(require.cache); console.log(require('./test.js').message)//hello上述代码说明第二次加载依旧使用了第一次加载进来之后的模块并没有重新加载而是读取了缓存中的模块,因为重新加载的某块中并没有message。打印出来的require.cache包含了本模块的module信息和加载进来的模块信息。
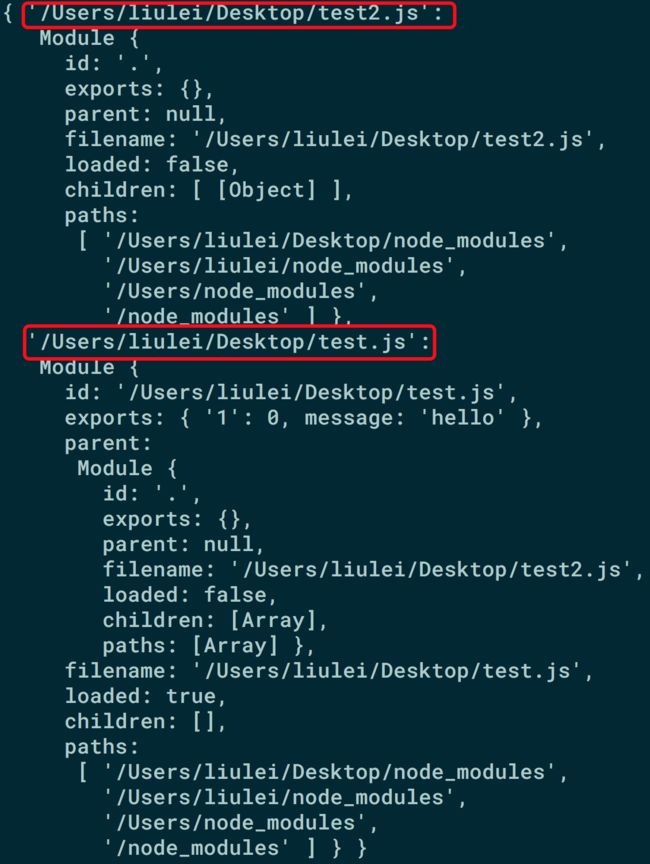
那么如果你想要多次执行某一个模块,要么你手动像下面这样删除该模块的缓存记录之后再重新加载使用,要么应该在模块中暴露一个工厂函数,然后调用那个函数多次执行该模块,与vue-ssr的创建应用实例的工厂函数意思相近。
require('./test.js').message='hello' delete require.cache['/absolute-path/test.js'] console.log(require('./test.js').message)//undifined可见当删除了相关模块的缓存,再一次加载时则不再有message了。
// Vue-ssr工厂函数,目的是为每个请求创立一个新的应用实例 const Vue = require('vue') module.exports = function createApp (context) { return new Vue({ data: { url: context.url }, template: `访问的 URL 是: {{ url }}` }) }
- 模块包装器
Node在加载模块之后,执行之前则会使用函数包装器将模块代码包装,从而实现将顶层变量(
var,let,const)作用域限制在模块范围内,提供每一个特定在该模块的顶层全局变量module,exports,__dirname(所在文件夹的绝对路径),__filename(绝对路径加上文件名)(function(exports, require, module, __filename, __dirname) { // 模块的代码实际上在这里 });关于模块的具体编译执行过程,这次就不深入讨论了,足够花心思在好好重新深入总结重写一篇了,顺便再次安利朴灵大大的《深入浅出nodejs》
ES6中模块的解决方案
终于,ES6在语言层面上提供了JS一直都没有的模块功能,使得在继Commonjs之于服务端,AMD之于浏览器之外提供了一个通用的解决方案。
1.设计思想
尽量静态化(静态加载),使得编译时就能确定模块间的依赖关系以及输入输出的变量。
2.关键语法
- export
export可以输出变量:
export var a = 1输出函数:
export function sum(x, y) { return x + y; };输出类:export class A{}
结尾大括号写法:export {a , sum , A}
尤为注意的一点就是export所导出的接口一定要和模块内部的变量建立一一对应的关系
对于一个模块来说,它就是一个默认使用了严格模式的文件('use strict'),而别的文件要想使用该模块,就必须要求该模块内有export主动导出的内容
例子:
export 1 //直接导出一个数字是不可以的 var a= 2 export a //间接导出数字也是不可以的! export {a}//正确 export function(){} //错误 function sum(){} export sum //错误 export {sum}//正确export个人最为重要的一点就是可以取到模块内的实时的值
例子:
export var foo = 'bar'; setTimeout(() => foo = 'baz', 500);引用该模块的文件在定时器时间到的时候则会得到改变后的值
- export default
实质: 导出一个叫做default(默认的)变量,本质是将后面的值,赋给default变量,所以情况就和export 不同了
不同点:
- export 导出的变量,在import的时候必须要知道变量名,否则无法加载,export default就允许随意取名直接加载,并且不用使用大括号;
- export default 后面不能跟变量声明语句
// 第一组 export default function crc32() {} import crc32 from 'crc32'; // 输入 // 第二组 export function crc32() {}; import {crc32} from 'crc32'; // 输入 export var a = 1;// 正确 var a = 1; export default a;// 正确 export default var a = 1;// 错误export default 每一个模块只允许有一个
- import
与导出export对应,引用则是import
export {a,b} || \/ import { a as A ,b as B} from './test.js';主要特点:
使用import加载具有提升的效果,即会提到文件头部进行:
foo(); import { foo } from 'my_module';该代码会正常执行。
*加载默认加载全部导出的变量
import * as A from './a.js'import 加载进来的变量是不允许改变的。
浏览器对ES6模块的加载
type='module',此时浏览器就会知道这是ES6模块,同时会自动给他加上前文提到的defer属性,即等到所有的渲染操作都执行完成之后,才会执行该模块
Node 对ES6模块的加载
由于Node有自己的模块加载机制,所以在Node8.5以上版本将两种方式的加载分开来处理,对于加载ES6的模块,node要求其后缀名得是
.mjs,然后还得加上--experimental-modules参数,然后两种机制还不能混用。确实还是很麻烦的,所以现在Node端想用import主流还是用babel转义。对比ES6 module和Node的commonjs
差异:
- 静态加载VS运行时加载
首先看下面一段代码:
if (x > 2) { import A from './a.js'; }else{ import B from './b.js'; }这段代码会报错,因为JS引擎在处理import是在编译时期,此时不会去执行条件语句,因此这段代码会出现句法错误,相反,如果换成:
if (x > 2) { const A =require('./a.js'); }else{ const B =require('./b.js'); }commonjs是在运行时加载模块,因此上面代码就会成功运行
由于动态加载功能的要求,才会有了import()函数的提案,这里就不过多赘述。
- 值的引用VS值的拷贝
commonjs模块在加载之后会把原始类型的值缓存,之后该模块的内部变化则不会再影响到其输出的值:
//test.js var counter = 3; function incCounter() { counter++; } module.exports = { counter: counter, incCounter: incCounter, }; ================================== //main.js var test = require('./test'); console.log(test.counter); // 3 test.incCounter(); console.log(test.counter); // 3ES6的模块机制,在引擎静态分析阶段会把import当成是一种只读引用(地址是只读的const,因此不可以在引用该模块的文件里给他重新赋值),等到代码实际运行时,才会根据引用去取值
// test.js export let counter = 3; export function incCounter() { counter++; } // main.js import { counter, incCounter } from './test'; console.log(counter); // 3 incCounter(); console.log(counter); // 4循环加载问题
循环加载指的是,a文件依赖于b文件,而b文件又依赖于a文件
- commonjs的循环加载问题
commonjs是在加载时执行的,他在require的时候就会全部跑一遍,因此他在遇到循环加载的情况就会只输出已经执行的部分,而之后的部分则不会输出,下面是一个例子:
//parent文件 exports.flag = 1; let children = require('./children')//停下来,加载chilren console.log(`parent文件中chilren的flag =${children.flag}`); exports.flag = 2 console.log(`parent文件执行完毕了`); ========================================================= //test2文件 exports.flag = 1; let parent = require('./parent')//停下来,加载parent,此时parent只执行到了第一行,导出结果flag ==1 console.log(`children文件中parent的flag =${parent.flag}`); exports.flag = 2 console.log(`children文件执行完毕了`);
node parent之后运行结果为 Commonjs循环加载
Commonjs循环加载运行parent之后会在第一行导出flag=1,然后去
ruquirechildren文件,此时parent进行等待,等待children文件执行结束,children开始执行到第二行的时候出现“循环加载”parent文件,此时系统自动去找parent文件的exports属性,而parent只执行了一行,但是好在它有exports了flag,所以children文件加再进来了那个flag并继续执行,第三行不会报错,最后在第四行children导出了flag=2,此时parent再接着执行到结束。
- ES6中的循环加载问题
ES6和commonjs本质上不同!因为ES6是引用取值,即动态引用
引用阮一峰老师ES6标准入门的例子
// a.mjs import {bar} from './b'; console.log('a.mjs'); console.log(bar); export let foo = 'foo'; // b.mjs import {foo} from './a'; console.log('b.mjs'); console.log(foo); export let bar = 'bar';执行后的结果:
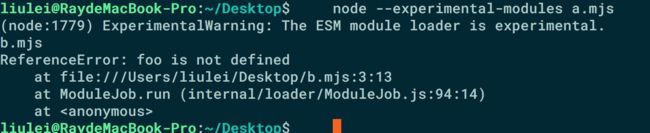 ES6循环加载出错
ES6循环加载出错执行的过程是当a文件防线import了b文件之后就会去执行b文件,到了b文件这边看到了他又引用了a文件,并不会又去执行a文件发生“张郎送李郎”的故事,而是倔强得认为foo这个接口已经存在了,于是就继续执行下去,直到在要引用
foo的时候发现foo还没有定义,因为let定义变量会出现"暂时性死区",不可以还没定义就使用,其实如果改成var声明,有个变量提升作用就不会报错了。改成var声明fooexport let foo = 'foo'; ES6循环加载换成var
ES6循环加载换成var虽然打印的foo是undifined但是并没有影响程序执行,但最好的做法是,改成同样有提升作用的function来声明。最后去执行函数来获得值,最后得到了希望的结果
// a.mjs import {bar} from './b'; console.log('a.mjs'); console.log(bar()); export function foo() { return 'foo' }; // b.mjs import {foo} from './a'; console.log('b.mjs'); console.log(foo()); export function bar() { return 'bar' }; ES6循环加载正确
ES6循环加载正确结束语
其实关于模块还有很多东西还没有梳理总结到,比如node模块的加载过程的细节,和编译过程,再比如如何自己写一个npm模块发布等等都是很值得去梳理总结的,这一次就先到这吧,总之,第一次在自己的博客站正儿八经的写这么长的技术总结博客,组织内容上感觉比较凌乱,还有很多的不足。希望自己以后多多总结提高吧。最后当然还是要感谢开源,感谢提供了那么多优秀资料的前辈们。也欢迎来我的博客网站(https://isliulei.com)指教。
参考文章:
ES6标准入门--阮一峰
Nodejs v8.9.4 官方文档
《深入浅出Nodejs》---朴灵
Commonjs规范