该笔记整理自Wesley Chun著,孙波翔、李斌、李晗译,人民邮电出版社出版的《Python核心编程》第3版,还结合了《正则表达式30分钟入门教程》,具体内容有部分省略。

1 什么是正则表达式?
正则表达式(简称为regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串。换句话说,正则表达式是一种用来匹配字符串的强有力的武器。
它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
比如,你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
比如,判断一个字符串是否是合法的Email:创建一个匹配Email的正则表达式;用该正则表达式去匹配用户的输入来判断是否合法。
2 常见的符号及含义
2.1 常用元字符
| 代码 | 说明 | 例子 |
|---|---|---|
| . | 匹配除换行符以外的任意字符 | a.a |
| \w | 匹配字母或数字或下划线或汉字,与[A-Za-z0-9_]相同 | [A-Za-z_]\w+ |
| \s | 匹配任意的空白符 | of\sthe |
| \d | 匹配任何十进制数字,与[0-9]相同 | data\d+.txt |
| \b | 匹配单词的开始或结束 | \bThe\b |
| ^ | 匹配字符串的开始 | ^Dear |
| $ | 匹配字符串的结束 | /bin/*sh$ |
- 'py.'可以匹配'pya'、'py2'、'py!'等。
- '00\d'可以匹配'003',但无法匹配'00b'。
- '\d\d\d'可以匹配'010'。
- '\w\w\d'可以匹配'py2'。
- 表示行的开头,\d表示必须以数字开头。
- $表示行的结束,\d$表示必须以数字结束。
2.2 常用限定符和懒惰限定符
| 代码 | 说明 | 例子 |
|---|---|---|
| * | 重复零次或多次前面出现的正则表达式(≥0) | [A-Za-z0-9]* |
| + | 重复一次或多次前面出现的正则表达式(≥1) | [a-z]+.com |
| ? | 重复零次或一次前面出现的正则表达式(0或1) | goo? |
| {n} | 重复n次前面出现的正则表达式 | [0-9]{3} |
| {m,n} | 重复m到n次前面出现的正则表达式 | [0-9]{5,9}先从9开始匹配,长度不够9的时候,匹配8个长度,以此类推 |
| […] | 匹配来自字符集的任意单一字符 | [aeiou] |
| [..x−y..] | 匹配x~y 范围中的任意单一字符 | [0-9],[A-Za-z] |
| *? | 重复任意次,但尽可能少重复 | a.b,如果用它来搜索 aabab 的话,它会匹配整个字符串aabab。而a.?b会匹配aab(第一到第三个字符)和 ab(第四到第五个字符)。 |
| +? | 重复1次或更多次,但尽可能少重复 | |
| ?? | 重复0次或1次,但尽可能少重复 | |
| {m,n}? | 重复m到n次,但尽可能少重复 | |
| {n,}? | 重复n次以上,但尽可能少重复 |
分析:
\d{3}\s+\d{3,8}
我们来从左到右解读一下:
- \d{3}表示匹配3个数字,例如'010';
- \s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;
- \d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用''转义,所以,上面的正则是\d{3}-\d{3,8}。
但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。
要做更精确地匹配,可以用[ ]表示范围,比如:
- [0-9a-zA-Z_]可以匹配一个数字、字母或者下划线。
- [0-9a-zA-Z_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a200','0_b','Pb2017'等。
- [a-zA-Z_][0-9a-zA-Z_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量。
- [a-zA-Z_][0-9a-zA-Z_]{0,19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。

正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
2.3 常用的反义代码
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
| 代码 | 说明 |
|---|---|
| \W | 匹配任意不是字母、数字、下划线、汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
2.4 常用的分组语法
| 代码 | 说明 |
|---|---|
| (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 |
| (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (? | 匹配前面不是exp的位置 |
| (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
- 比如 \b\w+(?=ing\b) ,匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing. 时,它会匹配sing和danc。
- 比如 (?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
2.5 常用的处理选项
| 名称 | 说明 |
|---|---|
| re.IGNORECASE | 匹配时不区分大小写 |
| re.MULTILINE | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置。) |
| re.DOTALL | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| re.VERBOSE | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| re.DEBUG | 显示编译表达式的debug信息 |

3 re模块
当严格讨论与字符串中模式相关的正则表达式时,我们会用术语“匹配”(matching),指的是术语“模式匹配”(pattern-matching)。
在Python术语中,主要有两种方法完成模式匹配:“搜索”(searching),即在字符串任意部分中搜索匹配的模式;而“匹配”(matching)是指判断一个字符串能否从起始处全部或者部分地匹配某个模式。搜索通过search()函数或方法来实现,而匹配通过调用match()函数或方法实现。
Python提供re模块,包含所有正则表达式的功能。由于Python的字符串本身也用\转义,所以要特别注意:
s = 'ABC\-001',对应的正则表达式字符串变成:'ABC-001'。
使用Python的r前缀,就不用考虑转义的问题了:
s = r'ABC-001',对应的正则表达式字符串不变:'ABC-001'。
写正则表达式的良好习惯是:
reg_pattern = r'^(这里面填上你想要的表达式)$'
以r'^开始,以$'结尾。
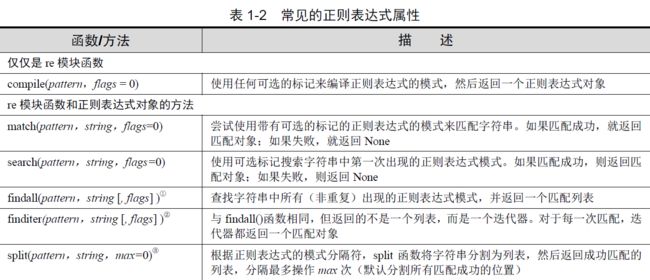
3.1 compile编译
在模式匹配发生之前,正则表达式模式必须编译成正则表达式对象。由于正则表达式在执行过程中将进行多次比较操作,因此强烈建议使用预编译。而且,既然正则表达式的编译是必需的,那么使用预编译来提升执行性能无疑是明智之举。re.compile()能够提供此功能。
其实模块函数会对已编译的对象进行缓存,所以不是所有使用相同正则表达式模式的search()和match()都需要编译。即使这样,你也节省了缓存查询时间,并且不必
对于相同的字符串反复进行函数调用。
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
- 编译正则表达式,如果正则表达式的字符串本身不合法,会报错。
- 用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
>>> re_telphone=re.compile(r'^(\d{3})-(\d{3,8})$') # 编译
>>> re_telphone.match('010-12345').groups() # 使用
('010', '12345')
>>> re_telphone.match('010-3456').groups()
('010', '3456')
3.2 match()匹配字符串
先看看如何判断正则表达式是否匹配:
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
没有任何输出
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。
常见的判断方法就是:
test = '用户输入的字符串'
if re.match(r'正则表达式', test):
print('ok')
else:
print('failed')
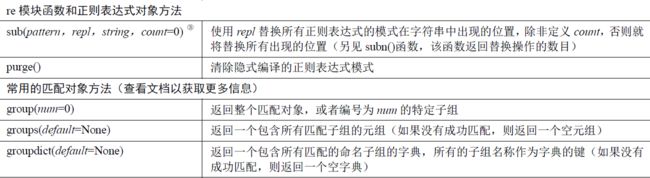
当处理正则表达式时,除了正则表达式对象之外,还有另一个对象类型:匹配对象。这些是成功调用match()或者search()返回的对象。匹配对象有两个主要的方法:group()和groups()。
group()要么返回整个匹配对象,要么根据要求返回特定子组。groups()则仅返回一个包含唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups()返回一个空元组。
>>> m = re.match('foo', 'foo') # 模式匹配字符串
>>> if m is not None: # 如果匹配成功,就输出匹配内容
... m.group()
...
'foo'
>>> m = re.match('foo', 'bar') # 模式并不能匹配字符串
>>> if m is not None: m.group()
...
没有任何输出
>>> m = re.match('foo', 'food on the table') # 匹配成功
>>> m.group()
'foo'
>>> re.match('foo', 'food on the table').group()
'foo'
3.3 search()搜索字符串
想要搜索的模式出现在一个字符串中间部分的概率,远大于出现在字符串起始部分的概率。这也就是search()派上用场的时候了。search()的工作方式与match()完全一致,不同之处在于search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回None。
我们将再次举例说明match()和search()之间的差别。以匹配一个更长的字符串为例,这次使用字符串“foo”去匹配“seafood”:
>>> m = re.match('foo', 'seafood') # 匹配失败
>>> if m is not None: m.group()
...
没有任何输出
可以看到,此处匹配失败。match()试图从字符串的起始部分开始匹配模式;也就是说,模式中的“f”将匹配到字符串的首字母“s”上,这样的匹配肯定是失败的。然而,字符串“foo”确实出现在“seafood”之中(某个位置),所以,我们该如何让Python 得出肯定的结果呢?答案是使用search()函数,而不是尝试匹配。
search()函数不但会搜索模式在字符串中第一次出现的位置,而且严格地对字符串从左到右搜索。
>>> m = re.search('foo', 'seafood') # 使用search()代替
>>> if m is not None: m.group()
...
'foo' # 搜索成功,但是匹配失败
3.4 split()切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']
无法识别连续的空格,用正则表达式试试:
>>> re.split(r'\s+', 'a b c')
['a', 'b', 'c']
无论多少个空格都可以正常分割。
>>> re.split(r'[\s\,]+', 'a,b, c d')
['a', 'b', 'c', 'd']
>>> re.split(r'[\s\,\;]+', 'a,b;; c d')
['a', 'b', 'c', 'd']
>>> re.split(':', 'str1:str2:str3')
[' str1', 'str2', 'str3']
例如,一个用于Web 站点(类似于Google 或者Yahoo! Maps)的简单解析器,该如何实现?用户需要输入城市和州名,或者城市名加上ZIP 编码,还是三者同时输入?这就需要比仅仅是普通字符串分割更强大的处理方式,具体如下。
>>> import re
>>> DATA = ( 'Mountain View, CA 94040',
'Sunnyvale, CA',
'Los Altos, 94023',
'Cupertino 95014',
'Palo Alto CA'
)
>>> for datum in DATA:
print re.split(', |(?= (?:\d{5}|[A-Z]{2})) ', datum)
...
输出结果为:
['Mountain View', 'CA', '94040']
['Sunnyvale', 'CA']
['Los Altos', '94023']
['Cupertino', '95014']
[' Palo Alto', 'CA']
3.5 分组group
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。
group()通常用于以普通方式显示所有的匹配部分,但也能用于获取各个匹配的子组。可以使用groups()方法来获取一个包含所有匹配子字符串的元组。
比如:^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
看一个例子:
>>> m = re.match('(\w\w\w)-(\d\d\d)', 'abc-123')
>>> m.group() # 完整匹配
'abc-123'
>>> m.group(1) # 子组1
'abc'
>>> m.group(2) # 子组2
'123'
>>> m.groups() # 全部子组
(' abc', '123')
>>> m = re.match('ab', 'ab') # 没有子组
>>> m.group() # 完整匹配
'ab'
>>> m.groups() # 所有子组
()
>>> m = re.match('(ab)', 'ab') # 一个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组1
'ab'
>>> m.groups() # 全部子组
('ab',)
>>> m = re.match('(a)(b)', 'ab') # 两个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组1
'a'
>>> m.group(2) # 子组2
'b'
>>> m.groups() # 所有子组
('a', 'b')
>>> m = re.match('(a(b))', 'ab') # 两个子组
>>> m.group() # 完整匹配
'ab'
>>> m.group(1) # 子组1
'ab'
>>> m.group(2) # 子组2
'b'
>>> m.groups() # 所有子组
('ab', 'b')
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('19', '05', '30')
>>> m.group(0)
'19:05:30'
这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'
对于'2-30','4-31'这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
如果您发现文中有不清楚或者有问题的地方,请在下方评论区留言,我会根据您的评论,更新文中相关内容,谢谢!