什么是实时流计算?
主要的处理模式可以分为:流处理,批处理
流处理是直接处理,有时也分为在线,离线,近线(straight-through process)
批处理是先存储后处理(store-process)
实时的流计算系统
Yahoo的S4,S4是一个通用的,分布式的,可扩展的,分区容错的,可插拔的流式系统,主要是为了解决:搜索广告的展现、处理用户的点击反馈
Facebook使用puma和hbase相结合来处理实时数据,使批处理计算平台具备一定实时计算能力,不过这不算是一个开源的产品,只是内部使用
Storm是什么?
storm是一个分布式,高容错的实时计算系统,对数据实时计算提供了简单的spout和bolt原语
架构
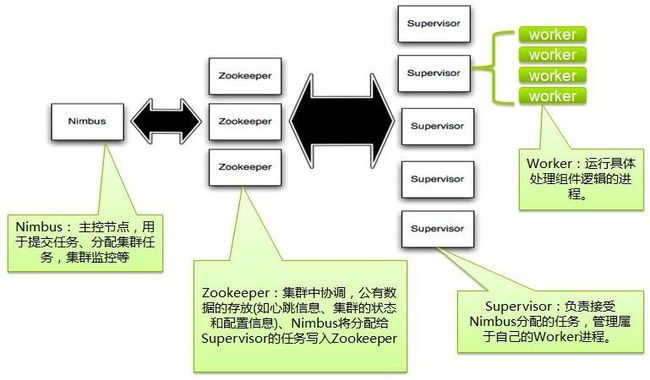
核心组件
Storm的内核都是由clojure编写的(大部分扩展工作都是java编写的)
Nimbus:负责资源分配和任务调度
Supervisor:负责接收nimbus分配的任务,启动和停止属于自己管理的worker进程
Worker:运行具体处理组件逻辑的进程,每个Worker都属于一个特定的Topology,每个supervisor节点的worker进程有多个,每个worker使用一个单独的端口,worker对Topology中的每个组件运行一个或多个Executor线程来提供Task的执行服务
Topology:storm中运行的一个实时应用程序,类似于网络拓扑图的一种虚拟结构.Storm拓扑类似MapReduce任务,一个关键的区别是MapReduce任务运行一段时间后最终会完成,而Storm拓扑一直会运行(直到杀死它),一个Topology是由一组spout组件和Bolt组件组成的图
Spout:在一个Topology中产生源数据的组件,向Topology中发出的Tuple可以是可靠的,也可以是不可靠的,一个可靠的数据源可以重新发射一个Tuple(如果该Tuple没有被Storm成功处理),但是一个不可靠的消息源Spout一旦发出,一个Tuple就把它彻底"遗忘",也就不可能再发了
Bolt:消息的处理者,在一个Topology中接收数据然后执行处理的组件
Bolt的生命周期:首先客户端创建Bolt,然后将其序列化,并提交给集群中的主机,之后集群启动Worker进程,反序列化Bolt,调用prepare方法开始处理元组,接下来,Bolt处理Tuple,Bolt处理一个输入Tuple,发射0个或多个Tuple,然后调用ack通知Storm自己已经处理过这个Tuple了,Storm提供了一个IBasicBolt自动调用ack,Bolt类接收由Spout或者其他上游Bolt类发来的Tuple,对其进行处理
Tuple:一次消息传递的基本单元
Tuple的生命周期:storm 通过调用spout的nextTuple方法来获取下一个Tuple,Spout通过open方法参数里面提供的SpoutOutputCollector来发射新tuple到它的其中一个输出消息流,发射tuple的时候spout会提供一个message-id,后面我们会通过这个tuple-id来追踪这个tuple
然后,这个发射的tuple被传送到消息处理者Bolt那里,storm会跟踪这个消息的树形结构是否创建,根据message-id调用spout那里的ack函数,以确认tuple是否被完全处理,如果tuple超时就会调用spout的fail方法
由此看出同一个tuple不管是acked还是fail都是由创建它的那个spout发出的,所以即使spout在集群环境中执行了很多的task,这个tuple也不会被其他任务调用或生成acked或failed状态,总之,Storm会利用内部的Acker机制保证每个Tuple被可靠地处理,最后,在任务完成后,Spout调用Close方法结束Tuple的使命
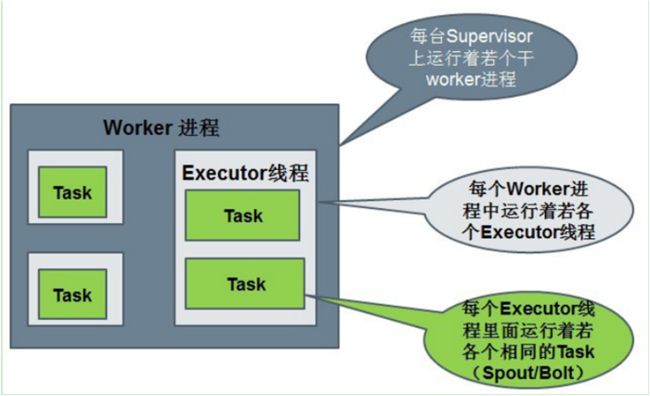
Executor:
产生于Worker进程内部的线程,会执行同一个组件的一个或者多个Task
Task:worker中的每一个spout/bolt的线程称为一个Task
Stream grouping:消息的分组方法
Worker、Task、Executor三者之间的关系:
Worker是进程,Executor对应于线程,Spout或Bolt是一个个的Task;在Storm集群中的一个物理节点启动一个或者多个worker进程,集群中的Topology都是通过这些Worker进程进行的,Worker进程中又会运行一个或多个executor线程,每个Executor线程只运行一个Topology的一个组件(Spout/Bolt)的Task任务,Task又是数据处理的实体单元
同一个Worker只执行同一个Topology相关的Task;在同一个Executor中可以执行多个同类型的Task,即在同一个Executor中,要么全部都是Bolt类的Task,要么全是Spout类的Task;在运行时,Spout和Bolt需要包装成一个又一个的Task
与hadoop角色对比

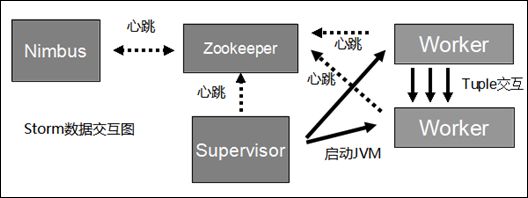
Storm数据交互图
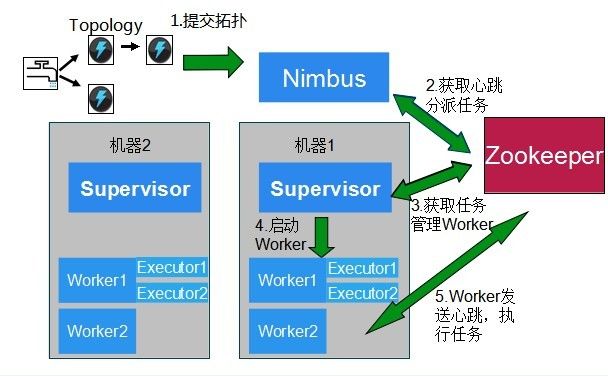
Topology的提交流程图
数据流模型
Topology中,Spout是Stream的源头,负责为Topology从特定数据源发射Stream;Bolt可以接收任意多个Stream作为输入,然后进行数据的加工处理过程,如果需要,Bolt还可以发射出新的Stream给下级Bolt进行处理

Stream消息流:Stream消息流是一个有向无界的Tuple序列,这些Tuple以分布式的方式并行地创建和处理,定义消息流主要是定义消息流的Tuple
Stream:源源不断传递地tuple就组成了stream
Stream Grouping 消息流
Stream Grouping(消息流组)就是用来定义一个流如何分配Tuple到Bolt.Storm包括6种流分组类型
1.随机分组(shuffle Grouping)
随机分发Tuple到Bolt的任务,保证每个任务获得相等数量的Tuple
2.字段分组(Fields Grouping)
根据指定字段分割数据流,并分组.这种grouping机制保证相同field值的tuple会去同一个task.例如对于WordCount来说同一个单词会去同一个task
3.全部分组(AllGrouping)
广播发送,将每一个Tuple发送到所有的Task.谨慎使用
4.全局分组(GlobalGrouping)
所有的Tuple会被发送到某个Bolt中id最小的那个task
5.无分组(NoneGrouping)
不关心Tuple发送给哪个Task来处理,等价于ShuffleGrouping
6.直接分组(DirectGrouping)
直接将Tuple发送到指定的Task来处理
特点
分布式简单
运维简单
高度容错
无数据丢失
多语言
低延迟
高性能
可扩展
进入Storm安装部署以及API:Storm安装部署和API