Kafka提供的主要功能
生产者 ——>消息队列 <——消费者
所谓消息对象,本质上就是由生产者向消息队列不断发送消息,而消费者则不断从消息队列拉取消息。
Apache Kafka本质上是一款分布式、基于发布/订阅机制的消息系统,主要使用Scala语言开发而成的。这里使用了【主要】两字,说明Kafka的源码并非全部都使用Scala语言开发,有相当一部分代码是使用Java语言开发的,特别是针对于客户端部分。Kafka的内核基本上都是使用Scala语言开发的,在早期版本的客户端代码中,也是使用Scala语言开发的,不过在新版的Kafka中,客户端代码部分已经换成了Java语言实现。这里所提到的客户端主要是针对于生产者、消费者等功能模块的代码。在老版本的客户端代码中存在一些已知的问题,因此新版本使用Java语言进行了重新,减少了错误的发生并增强了稳定性。
Kafka重要概念
生产者(Producer):顾名思义,生产者就是生产消息的组件,它的主要工作就是源源不断地生产出消息,然后发送给消息队列。生产者可以向消息队列发送各种类型的消息,如狭义的字符串消息,也可以发送二进制消息。生产者是消息队列的数据源,只有通过生产者持续不断地向消息队列发送消息,消息队列才能不断处理消息。
消费者(Consumer):所谓消费者,指的是不断消费(获取)消息的组件,它获取消息的来源就是消息队列(即Kafka本身)。换句话说,生产者不断向消息队列发送消息,而消费者则不断从消息队列中获取消息。这里面的消息队列(即Kafka)则充当一个中介的角色,连接了生产者与消费者这两大功能组件。正是从这个意义上来说,借助于消息队列,我们实现了生产者系统与消费者系统之间的解耦,使得原本需要两个系统之间有紧密联系的状况变成了两个系统可以各针对与Kafka进行编程(只要提前约定好一些契约即可),这可以使得生产者系统完全不需要了解消费者系统的各种信息(比如说消费者系统的地址、端口号、URL 、使用的时REST接口还是RPC等等;反之亦然)。这正是消息队列所提供的另外一个绝佳好处:极大降低了系统之间的耦合度。
代理(Broker):代理这个概念是消息队列领域中一个常见的概念。Broker这个单词原本的意思是经纪人,比如说房地产经纪人、股票经纪人等。在消息队列领域中,它指的其实就是消息队列产品本身,比如说在Kafka这个领域下,Broker其实指的就是一台Kafka Server。换句话说,我们可以将部署的一个Kafka Server看作是一个Broker,就是这样简单。那么从流程上来说,生产者会将消息发送给Broker,然后消费者再从Broker中拉取消息。
主题(Topic):主题是Kafka中一个极为重要的概念。首先,主题是一个逻辑上的概念,它用于从逻辑上来归类与存储消息本身。多个生产者可以向一个Topic发送消息,同时也可以有多个消费者消费一个Topic中的消息。Topic还有分区和副本的概念,后续介绍。Topic与消息这两个概念之间密切相关,Kafka中的每一条消息都归属于某一个Topic,而一个Topic下面可以有任意数量的消息。正是借助于Topic这个逻辑上的概念,Kafka将各种各样的消息进行了分门别类,使得不同的消息归属于不同的Topic,这样就可以很好地实现不同系统的生产者可以向同一个Broker发送消息,而不同系统的消费者则可以根据Topic的名字从Broker中拉取消息。Topic是一个字符串。通过Topic这样一个逻辑上的概念,我们就很好地实现了生产者与消费者之间有针对性的发送与拉取。
消息(Record):消息是整个消息队列中最为基本的一个概念,也是最为原子的一个概念。它指的是生产者发送与消费者拉取的一个原子事物。一个消息需要关联到一个Topic上,表示该消息从属于哪个Topic。消息由一串字节所构成,其中主要由key和value两部分内容,key与value本质上都是字节数组。在发送消息时,我们可以省略掉key部分,而直接使用value部分。正如上一节的示例那样,生产者在发送消息时,发送的内容是【hello world】、【welcome】。实际上,他们都是消息的value,即消息真正的内容本身;key的主要作用则是根据一定的策略,将此消息发送到指定的分区中,这样就可以确保包含同一key值的消息全部都写入到同一个分区中。因此,我们可以得出这样一个结论:对于Kafka的消息来说,真正的消息内容本身是由value所承载的。为了提升消息发送的效率和存储效率,生产者会批量将消息发送给Broker,并根据相应的压缩算法在发送前对消息进行压缩。
集群(Cluster):集群指的是由多个Broker所共同构成的一个整体,对外提供统一的服务,这类似于我们在部署系统时都会采用集群的方式来进行。借助集群的方式,Kafka消息队列系统可以实现高可用与容错,即一台Broker挂掉也不影响整个消息系统的正确运行。集群中的各台Broker之间是通过心跳(Heartbeat)的方式来检查其机器是否还存活。
控制器(Controller):控制器是集群中的概念。每个集群中会选择出一个Broker担任控制器的角色,控制器是Kafka集群的中心。一个Kafka集群中,控制器这台Broker之外的其他Broker会根据控制器的指挥来实现相应的功能。控制器负责管理Kafka分区的状态、管理每个分区的副本状态、监听Zookeeper中数据的变化并作出相应的反馈等功能。此外,控制器也类似于主从概念(比如说MySQL的主从概念),所有的Broker都会监听控制器Leader的状态,当Leader控制器出现问题或是故障时则重新选择新的控制器Leader,这里面涉及到一个选举算法的问题。
消费者组(Consumer Group):这又是Kafka中的一个核心概念。消费者与消费者之间密切相关。在Kafka中,多个消费者可以共同构成一个消费者组,而一个消费者只能从属于一个消费者组。消费者组最为重要的一个功能是实现广播与单播的功能。一个消费者组可以确保其所订阅的Topic的每个分区只能被从属于该消费者组中的唯一一个消费者所消费;如果不同的消费组订阅了同一个Topic,那么这些消费者组之间是彼此独立的,不会受到相互的干扰。因此,如果我们系统一条消息可以被多个消费者所消费,那么就可以将这些消费者放置到不同的消费者组中,这实际上就是广播的效果;如果希望一条消息只能被一个消费者所消费,那么就可以将这些消费者放置到同一个消费者组中,这实际上就是单播的效果。因此,我们可以将消费者组看作是【逻辑上的订阅者】,而物理上的订阅者则是各个消费者。值得注意的时,消费者组是一个非常、非常、非常重要的概念。很多Kafka初学者都会遇到这样一个问题:将系统以集群的形式部署(比如说部署到3台机器或者虚拟机上),每台机器的指定代码都是完全一样的,那么在运行时,只会有一台机器会持续不断地收到Broker中消息,而其他机器则一条信息业没收到。究其本质,系统部署时采用了集群部署,因此每台机器的代码与配置是完全一样的;这样,这些机器(消费者)都从属于同一个消费者组,既然从属于同一个消费者组,那么这同一个消费者组中,只会有一个消费者会接收到消息,而其他消费者则完全接受不到任何消息,即单播效果。这一点尤其值得注意。
启动ZooKeeper
./zkServer.sh start-foreground
启动Kafka
./kafka-server-start.sh ../config/server.properties
查看主题列表
./kafka-topics.sh --list --zookeeper localhost:2181
输出
__consumer_offsets
mytest
test
我们可以看到,该命令列出了三个主题,其中__consumer_offsets是Kafka Server所创建的用于标识消费者偏移量的主题(Kafka中的消息都是顺序保存在磁盘上的,通过offset偏移量来标识消息的顺序),它由Kafka Server内部使用;另外两个是我自己创建的。
查看某个主题(如test)的详细信息,则执行如下命令
./kafka-topics.sh --describe --topic test --zookeeper localhost:2181
输出
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
输出结果第一行会显示出所有分区的一个总结信息;后续的每一行则给出一个分区的信息,如果只有一个分区,那么就只会显示出一行,正如上述输出那样。
第一行表示的信息为:
主题名:test
分区数:1
副本数:1
第二行表示信息为:
主题名:mytest
当前的分区:0
Leader Broker:0
副本:0
lsr(In-Sync Replica):0
这些主题保存在什么地方呢?
实际上,这些信息都是保存在ZooKeeper中的。Kakfa是重度依赖于ZooKeeper的。ZooKeeper保存了Kafka所需的原信息以及关于主题、消费者偏移量等诸多信息。
打开一个新的命令窗口,进入ZooKeeper的bin目录中,执行如下脚本
./zkCli.sh -server localhost:2181
上述命令表示使用ZooKeeper客户端脚本工具连接到本机的2181ZooKeeper Server上。
连接成功后显示
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
执行ls /命令则输出 / 下面的所有节点,如下所示
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
执行'ls2 / '命令输出/下面的所有节点和其他相关信息(ls2 = ls +stat)
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x110
cversion = 13
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 11
执行`ls /config/topics'则输出,同样执行ls2 会输出更多信息
[mytest, test, __consumer_offsets]
创建一个新主题mytest2,命令如下:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytest2
当执行完上述命令后,控制台输出
Created topic "mytest2".
则表示主题mytest2已经创建成功。
--replication-factor 与--partitions,这两个参数,前者表示主题拥有的副本数,后者表示主题拥有的分区数。关于分区与副本的概念,后续介绍。
接下里执行如下命令
./kafka-topics.sh --list --zookeeper localhost:2181
控制台输出
__consumer_offsets
mytest
mytest2
test
可以看到,多了一个新的主题mytest2。
现在,向新创建的主题mytest2发送若干条消息,执行如下命令:
./kafka-console-producer.sh --broker-list localhost:9092 --topic mytest2
然后,启动两个Kafka Consumer。新开两个控制台窗口,分别执行如下命令:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2 --from-beginning
现在,这两个Kafka Consumer都在等待mytest2主题上新消息的到来。
在生产者控制台输入如下字符串并回车:
hello world
这时,我们发现两个Kafka Consumer均收到该条消息。
再在生产者控制台输入如下字符串并回车:
welcome
我们发现,两个Kafka Consumer也都收到了该条消息。
通过这个操作过程,我们能够看到多个Kafka Consumer可以消费同一个主题的同一条消息,这显然就是广播概念,即多个客户端是可以获取到同一主题的同一条消息并进行消费的。
下面关闭这两个Kafka Consumer(ctrl+c);然后再分别在这两个控制台窗口中执行上述同样的命令:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2 --from-beginning
我们发现,消费者窗口中会显示出Kafka Server中mytest2主题已经拥有的两条消息:
hello world
welcome
现在再次关闭两个Kafka Consumer;然后分别在这两个控制台窗口中 执行如下命令(与上述命令相比,去掉了--from-beginning
这个参数)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2
我们发现,这两个Kakfa Consumer均不会再显示出mytest2主题下的信息。
在生产者窗口中输入如下字符串并回车
people
我们发现,两个Kafka Consumer均收到了该条消息。
通过这个操作过程,实际上我们掌握了--from-beginning参数的作用。它的作用是
如果消费者尚没有已建立的可用于消费的偏移量,那么就从Kafka Server日志中最早的消息开始消费,而非最新的消息开始消费。
再次停止两个Kafka Consumer,然后分别在这两个控制台窗口中输入如下命令:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2 --group mygroup
现在在生产者窗口中输入如下字符串并回车
byebye
观察两个Kafka Consumer控制台窗口,我们发现只会有一个消费者窗口收到该条信息,而另一个Consumer则没有收到。
继续再生产者窗口输入如下字符串并回车:
person
结果与之前一样,依然只有一台Consumer(而且是方才收到byebye消息的那台)收到的该消息。
现在,停止方才收到两条消息的那台Kafka Consumer(ctrl+c),只保留一台Consumer,再在生产者窗口输入如下字符串并回车
beijing
我们发现,继续运行的这台Consumer收到了该条消息。
实际上,上述操作演示了Kafka消费者组的作用。
现在,将运行的这台Kafka Consumer停掉,然后分别启动两个Kafka Consumer,分别在两个控制台中执行如下命令:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2 --group mygroup
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest2 --group mygroup2
注意,上述两个命令式运行在两个控制台窗口中的,他么的区别在于消费者组的名字不同,一个是mygroup,另一个则是mygroup2。
在生产者窗口中输入如下字符串并回车:
tianjing
我们可以清楚地看到,两个Kafka Consumer均收到了该条消息。究其原因,这两个Kafka Consumer归属于不同的消费者组,因此都可以收到该条消息,即实现了广播的效果。
下面,我们尝试将mytest2这个主题删除。
在控制台中执行如下命令(该命令表示删除主题mytest2的信息):
./kafka-topics.sh --zookeeper localhost:2181 --delete --topic mytest2
该命令的输出结果如下所示:
Topic mytest2 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
该输出表示:主题mytest2已经被标记为删除状态。同时还给出了一个提示信息,即如果没有将配置项delete.topic.enable设置为true,那么这个删除操作将不起任何作用。
我们执行如下命令,查看主题
./kafka-topics.sh --zookeeper localhost:2181 --list
输出
__consumer_offsets
mytest
test
从输出中可以清楚的看到,主题mytest2已经消失不见了,为了更加明确该主题已被删除,我们执行如下命令来查看主题mytest2的详细信息:
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic mytest2
执行上述命令后,控制台没有任何输出,这表明主题mytest2已经被删除了。进一步确认一下,回到启动Kafka Server的控制台窗口中,我们会发现窗口输出了如下日志信息
[2018-05-20 08:54:08,546] INFO Deleting index /tmp/kafka-logs/mytest2-0.fbca21d4e1cf4dd8afe8dacc77146567-delete/00000000000000000000.index (kafka.log.OffsetIndex)
[2018-05-20 08:54:08,559] INFO Deleting index /tmp/kafka-logs/mytest2-0.fbca21d4e1cf4dd8afe8dacc77146567-delete/00000000000000000000.timeindex (kafka.log.TimeIndex)
[2018-05-20 08:54:08,571] INFO Deleted log for partition mytest2-0 in /tmp/kafka-logs/mytest2-0.fbca21d4e1cf4dd8afe8dacc77146567-delete. (kafka.log.LogManager)
从该输出日志中可以清楚地看到,Kafka Server先是删除了与主题mytest2相关的索引信息,然后删除了日志信息,即数据文件。
进入到ZooKeeper下的bin目录,执行如下命令
./zkCli.sh
该命令会连接到ZooKeeper服务端,然后再执行如下命令:
ls /config/topics
该命令的输出如下所示
[mytest, test, __consumer_offsets]
这说明,主题mytest2已经不存在了。
基于以上的操作与相应的输出结果,我们可以确定,主题mytest2及相关数据已经被删除了(主题删除操作是不可逆的)。
值得注意的是,在Kafka1.0之前的版本中,delete.topic.enable属性值默认为false,因此若想删除主题,需要在server.properties配置文件中显式增加delete.topic.enable=true这一项配置。然而,在Kafka1.0中,该配置项默认就是true。因此,,无需显式指定即可成功删除主题;如果不希望删除主题,那么就需要显式将delete.topic.enable=false添加到server.properties配置文件中,这一点尤其要注意。
另外,在Kafka1.0之前的版本中,如果删除了主题,那么被删除的主题名字会保存到ZooKeeper的/admin/delete_topics节点中。虽然主题被删除了,但与主题相关的消息数据依然还会保留,需要用户手动到相关的数据目录下自行删除,然后这一切在Kafka1.0中都发生了变化。在Kafka1.0中,当主题被删除后,与主题相关的数据也会一并删除,并且不可逆。
分区:每个主题可以划分为多个分区(每个主题都至少会有一个分区,在之前的示例中,我们在创建主题时所使用的参数--partitions即表示所创建的主题的分区数,当时指定值为1)。在同一主题下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个偏移量(offset),它是消息在所有分区中的唯一编号,Kafka是通过offset来确保消息在同一个分区的消息是有序的,但是同一主题的多个分区内的消息,Kafka并不会保证其顺序性。
关于分区与主题之间的关系,可以参⻅见下图:
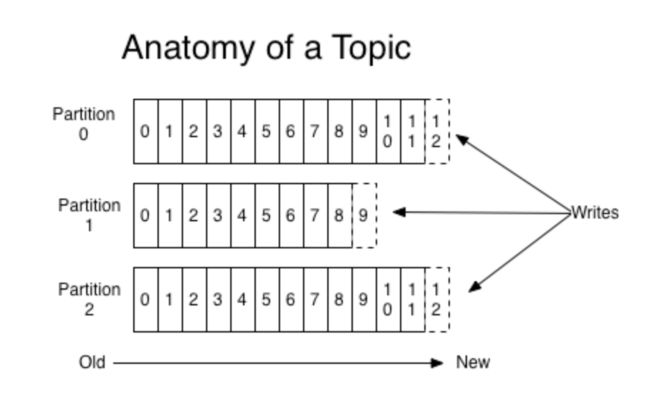
从上图可以看到,消息在每个分区中是严格有序的,⽽不同分区之间的消息则是不保证顺序的。
基于这样的设计策略,Kafka的性能并不会随着分区中消息量的增多而产生损 耗,因此存储较长时间的数据也不会导致什么问题。
Kafka中的消息记录是保存在磁盘上的,通过为每个消息分配一个offset,即可 以很好地确保同一分区中消息的顺序性。另外,Kafka中的消息在磁盘上是有 一定的保留时间的,在这个时间内,消息会存储在磁盘上;当过了这个时间, 消息即会被丢弃掉,从而释放磁盘空间。该参数位于server.properties文件中, 默认为:log.retention.hours=168。即消息默认会保留7天;当然,你可以根 据实际情况来⾃由修改该时间,修改后重启Kafka Server即可⽣生效。
下图展示了Kafka一个分区中消息的生产与消费情况:
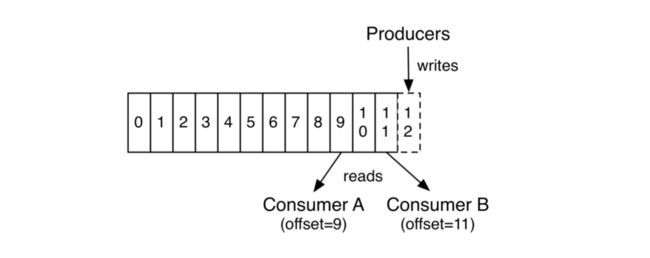
可以看到,每个消息在同一个分区中都有唯一的一个偏移量(offset)。
分区是与主题紧密相联的一个概念。对于每个主题来说,它至少会存在一个分区,这是通过在创建主题时所指定的参数--partitions来确定的。该参数的值是⼀个整数,表示所创建的主题所拥有的分区数量,我们之前在创建主题时都将该参数值设为了1,表示所创建的主题只有一个分区。
每个分区都是一个有序、不可变的消息序列,后续新来的消息会持续不不断地追加到分区的后面,这相当于一个结构化的提交⽇志(⼤家可以将其联想为Git的提交日志,Git日志显然是严格有序的)。分区中的每⼀条消息都会被分配一个连续的id值(即offset),该值用于唯一标识分区中的每一条消息。
分区在Kafka中扮演着如下作⽤:
1.分区中的消息数据是存储在日志文件中的,⽽且同一分区中的消息数据是按照发送顺序严格有序的。分区在逻辑上对应于一个日志,当生产者将消息写⼊分区时,实际上是写入到了分区对应的日志中。⽽日志可以看作是一个逻辑上的概念,它对应于磁盘上的一个⽬录。⼀个日志由多个Segment 构成,每个Segment对应于一个索引文件与一个日志文件。
2.借助于分区,我们可以实现Kafka Server的水平扩展。一台机器,无论是物理机还是虚拟机,运行能力总归是有上限的。当⼀台机器到达能力上限时就无法再扩展,即垂直扩展能力是受到硬件制约的。通过使⽤用分区,我们可以将一个主题中的消息分散到不同的Kafka Server上,这样当机器运行能力不足时,我们只需要增加机器就可以了,在新的机器上创建新的分区,这样理论上就可以实现⽆限的水平扩展能力。
3.分区还可以实现并行处理能力,向⼀个主题所发送的消息会送给该主题所拥有的不同分区中,这样消息就可以实现并行发送和处理,由多个分区来接收所发送的消息。
创建一个新的主题mytest3:
./kafka-topics.sh --zookeeper localhost:2181 --create --topic mytest3 --partitions 3 --replication-factor 1
执行完上述命令后,创建了新主题mytest3,并且将其--partitions参数指定为3,这表示mytest3这个主题指定了3个分区;--replication-factor参数设定为1,表示为分区副本数量为1。
启动生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic mytest3
输入如下
>hello java
>hello kotlin
>hello python
>hello c++
>hello go
>hello jvm
启动消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest3 --from-beginning
输出如下:
hello kotlin
hello go
hello java
hello c++
hello python
hello jvm
显然,我们在消费者端所得到的消息的顺序与发送者发送消息时的顺序是不一样的。
分区有两条重要原则:
1.同一分区内的消息保证严格有序。
2.不同分区的消息不保证顺序性。
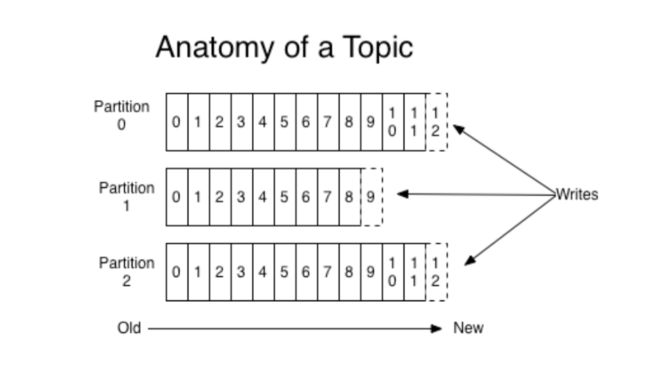
从上图可以看出,右侧的Writes表示生产者向Kafka Server的主题写入消息,该主题有3个分区,因此所写的消息会分布在这3个分区中;当消费者从Kafka Server的该主题拉取消息时,由于存在3个分区,因此这3个分区的消息都会被拉取出来;Kafka Server的分区间是不保证消息的顺序性的,所以会得到如上结果。
那么这些分区中的消息位于哪里呢?
打开Kafka安装目录中config目录下的server.properties配置文件,找到下面这一行
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
log.dirs配置项指定了Kafka的日志文件的存放位置,由于我们并未修改过,因此日志文件默认位置为:/tmp/kafka-logs。进入该目录,查看如下
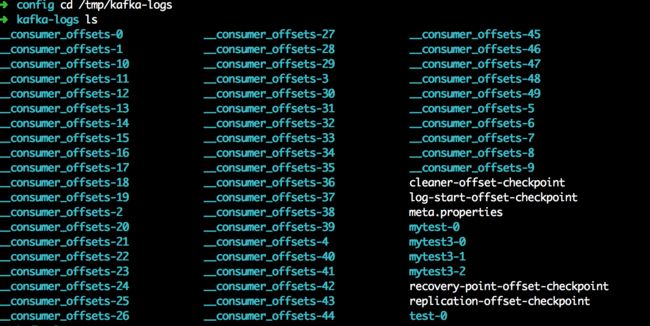
该目录下存在的就是Kafka的各种消息数据以及其它关键数据文件。
值得注意的时,以_consumer_offsets名字开头的目录,一共有50个,分别从0到49。该目录存放的是Kafka用于判定消费者消费偏移量的系统主题(Kafka Server自行创建,共内部使用)。
mytest-0目录,是之前创建的主题,当时只创建了一个分区,所以用mytest-0来表示该分区下的数据文件。
之前创建的mytest2,这里并没有,因为我们前面把mytest2主题删除了。
以mytest3开头的目录共有3个,这正好符合创建mytest3主题时所指定的分区数量3。
在Kafka的文件存储中,如果一个主题下存在多个分区(partitions),那么每个partition就会成为一个目录,partition的命名规则为:主题名+序号。其中,第一个partition序号为0,第二个是1,第三个是2,依次类推。序号最大值为partition数量-1。
与partition相关的另外一个概念segment,称作段。
一个partition是由一系列有序的、不可变的消息所构成。而一个partition中的消息数量可能会非常多,因此显然不能将所有消息保存到同一个文件中。因此,类似于log4j的rollin log,当partition中的消息数量增长到一定程度后,消息文件会进行切割,新的消息文件会被写到一个新的文件中,当新的文件增长到一定程度后,新的消息又会被写到另一个新的文件中,依次类推;而这一个个新的数据文件我们就称为segment(段)
因此,一个partition物理上是由一个或多个segment所构成。每个segment中则保存了真实的消息数据。如下两点需要知晓。
- 每个partition都相当于一个大型文件被分配到多个大小相等的segment(段)数据文件中,每个segment中的消息数量未必相等(这与消息大小有关,不同的消息所占据的磁盘空间显然不同),这个特点使得老的segment文件可以容易就被删除,有助于提升磁盘利用效率。
- 每个partition只需支持顺序读写就可以了,segment文件的生命周期是由Kafka Server的配置参数所确定的。比如说,server.properties文件中的参数项log.retention.hours=168就表示7天后删除老的消息文件。
进入到mytest3-0目录中
➜ kafka-logs cd mytest3-0
➜ mytest3-0 ls
00000000000000000000.index 00000000000000000000.timeindex
00000000000000000000.log leader-epoch-checkpoint
00000000000000000000.index : 这是segment文件的索引文件,它与00000000000000000000.log数据文件是成对出现的。后缀.index就表示这是个索引文件。
00000000000000000000.log :这是segment文件的数据文件,用于存储实际的消息。当然,该文件是二进制格式的。segment文件的命名规则是partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。没有数字则用0填充。由于这里的数据量较少。因此只有一个数据文件。
00000000000000000000.timeindex :该文件是一个基于消息日期的索引文件,主要用途是在一些根据日期或者时间来寻找消息的场景下使用,此外在基于时间的日志rolling或是基于时间的日志保留策略等情况下也会使用。实际上,该文件是Kafka的后续版本中才增加的,早期版本中是没有这个文件的。它是对*.index文件的一个补充。*.index是基于偏移量的索引文件,而*.timeindex则是基于时间戳的索引文件。
leader-epoch-checkpoint : 是leader的一个缓存文件。实际上,它是与Kafka的HW(High Water)与LEO(Log End Offset)相关的一个重要文件。