在公司写文档时候查到的一些资料,感觉对自己很有帮助,现在整理如下:
介绍
HBase是一个高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统,基于列的存储模式适合于存储非结构化数据。
适用场景
1) 解决受限于HadoopMapReduce的高延迟数据处理机制,HBase可以满足大规模数据实时处理应用的需求;
2) HDFS面向批量访问模式,而HBase是随机访问模式;
3) 应对在数据规模剧增时导致的系统扩展性及其他衍生出的一系列性能问题;
4) 在数据结构变化是不需要停机维护;
5) 不存储空值,有效节约存储空间;
6) 大数据量存储,大数据量高并发操作;
7) 需要对数据随机读写操作;
8) 读写访问均是非常简单的操作。
优势
1) 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串,可根据需要自行进行数据类型转换;
2) 数据操作: HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,HBase在设计上避免了复杂的表和表之间的关系;
3) 存储模式:关系型数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的;
4) 动态扩展:列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型;
5) 数据索引: HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来;
6) 数据维护:在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留;
7) 可伸缩性:实现灵活的水平扩展,能够通过在集群中增加或者减少硬件数量来实现性能的伸缩。
数据的容错和恢复
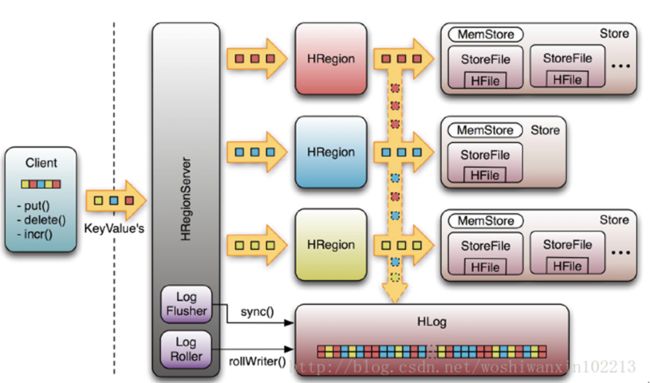
Write-Ahead-Log(WAL)
该机制用于数据的容错和恢复:
每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
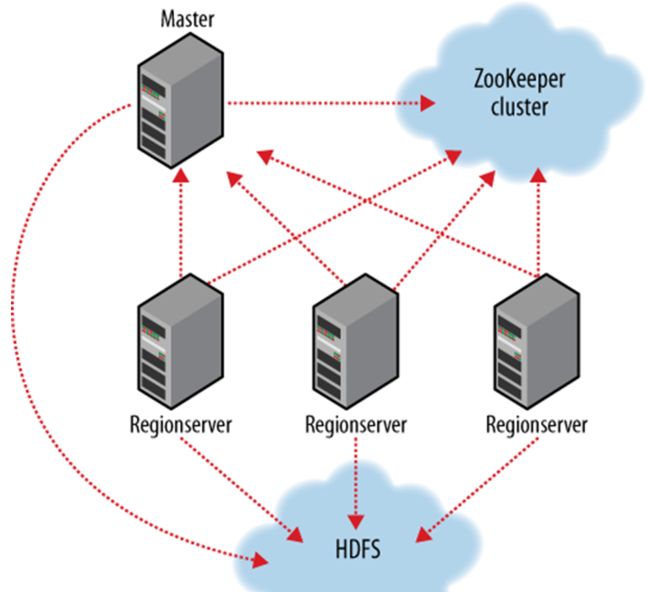
HBase容错性
Master容错:Zookeeper重新选择一个新的Master
无Master过程中,数据读取仍照常进行;
无master过程中,region切分、负载均衡等无法进行;
RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
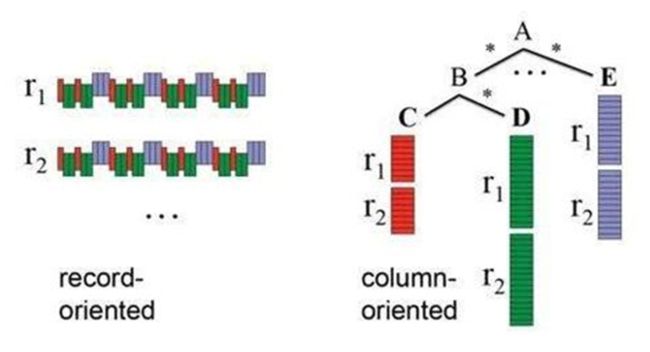
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务
5)稀疏性
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。