此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583]
本项目代码地址为:[https://e.coding.net/secret/ASETest1.git]
• 词频统计 SPEC
写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数
具体要求:
功能1 小文件输入。
功能2 支持命令行输入英文作品的文件名。
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
功能4 从控制台读入英文单篇作品。
• 整体分析:
1、c语言对于文本文件、目录文件的操作比较复杂,调试的时候比较花时间
2、对于单词的处理,包括大小写转换、统计、记录、排序等需要定义合适的数据结构
3、对于不同命令的识别和区分,也是比较麻烦的一部分
4、四个功能逻辑上相互独立,但在实现上又含有相似的部分,因此代码还有可简化的空间
• 重要代码及执行结果
功能一:
1、重点/难点
由于此部分数据来源于文件,因此相对于其他功能,功能一的复杂之处,主要是文件操作以及空间利用上。
2、关键代码片段
(1)动态利用空间
//初始化空间 wordNode* words = (wordNode*)malloc(600 * s * sizeof(wordNode));
//单词数大于600重新申请空间 if (count == 600 * s) { s++; words = (wordNode*)realloc(words, 600 * s * sizeof(wordNode)); for (k = count; k < 600 * s; k++) { (words + k)->frequent = 0; } }
(2)文件操作
//读文件,若文件为空则报提示 FILE* file = fopen(filename, "r"); if (file == NULL) { printf("there is no text\n"); }
//操作完后切记关闭文件 fclose(file);
3、运行结果

功能二:
1、重点/难点
与功能一的主要区别在于命令参数不同,最主要的单词来源都是读文件,因此在“功能一”的基础上,此部分额外要做的就是识别和区分控制台指令
2、关键代码片段
//单词小写化处理 w = tolower(fgetc(file)); while ((!feof(file)) && (isspace(w))) { w = tolower(fgetc(file)); } while (!feof(file)) { //判断单词类型是否为英文或十进制数字 if ((isdigit(w)) || isalpha(w)) { flag = 1; temp[i++] = w; } else//识别特殊符号 { if (flag) { if ((w == '\'') || (w == '-')) { temp[i++] = w; flag = 1; } else { flag = 0; temp[i] = '\0'; i = 0; for (j = 0; j < count; j++) { if (strcmp((words + j)->words, temp) == 0) { (words + j)->frequent++; break; } } if (j == count) { (words + count)->frequent = 1; strcpy((words + count)->words, temp); count++; } if (count == 600 * s) { s++; words = (wordNode*)realloc(words, 600 * s * sizeof(wordNode)); for (k = count; k < 600 * s; k++) { (words + k)->frequent = 0; } } } } } w = tolower(fgetc(file)); }
3、运行结果

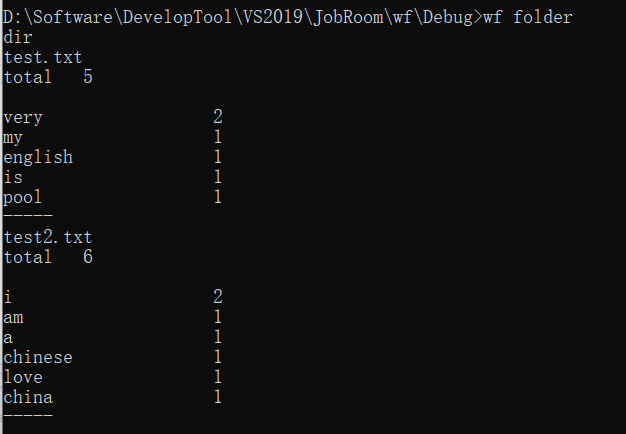
功能三:
1、重点/难点
此功能要求不仅要读取文件,还要批量的读取目录下所有文件内容,因此,识别目录、批量读取目录下所有文件是此部分的重点和难点
2、关键代码片段
//功能三 if (_S_IFDIR & buf.st_mode) { strcat(temp1, argv[1]); //文件夹下的文件绝对目录 strcpy(name, temp1); strcat(name, temp2); count = strlen(name); strcat(temp1, s2); printf("dir\n"); if ((handle = _findfirst(temp1, &filedetial)) != -1L) { do { strcat(name, filedetial.name); printf("%s\n", filedetial.name); function1(name); name[count] = '\0'; printf("-------\n"); } while (_findnext(handle, &filedetial) == 0); } else { printf("无匹配项目\n"); } //退出机制 _findclose(handle); }
3、运行结果
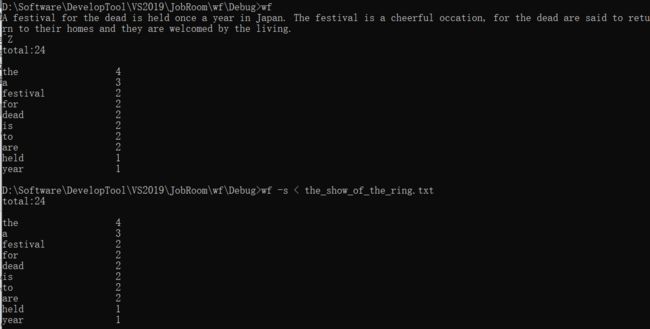
功能四:
1、重点/难点
功能四有两种命令模式:
第一种模式通过标准输入重定向为文件的方式,第二种模式通过控制台输入的方式输入文章,与之前读取文件的方式的不同,是此部分的难点和重点
2、关键代码片段
/* 对每个单词设置结构体 */ typedef struct word { int frequent;//单词频度 char words[50];//单词 }wordNode;
//按照单词频度排序 qsort(words, count, sizeof(wordNode), cmpWords);
/* 按单词频度比较大小 */ int cmpWords(const void* w1, const void* w2) { wordNode* t1 = (wordNode*)w1, * t2 = (wordNode*)w2; if (((t2->frequent) - (t1->frequent)) != 0) { return (t2->frequent) - (t1->frequent); } else { return (t1->words) - (t2->words); } }
3、运行结果
• PSP
要求1 估算你对每个功能 (或/和子功能)的预计花费时间,填入PSP阶段表格,时间颗粒度为分钟。
要求2 记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度要求分钟。
要求3 对比要求1和要求2中每项时间花费的差距,分析原因。
