目录
- 前言、目录、安装环境
- Dynamic Query 原理 Part1
- Dynamic Query 原理 Part2
- Strongly Typed Mapping 原理 Part1 : ADO.NET对比Dapper
- Strongly Typed Mapping 原理 Part2 : Reflection版本
- Strongly Typed Mapping 原理 Part3 : 动态建立方法重要概念「结果反推程式码」优化效率
- Strongly Typed Mapping 原理 Part4 : Expression版本
- Strongly Typed Mapping 原理 Part5 : Emit IL反建立C#代码
- Strongly Typed Mapping 原理 Part6 : Emit版本
- Dapper 效率快关键之一 : Cache 缓存原理
- 错误SQL字串拼接方式,会导致效率慢、内存泄漏
- Dapper SQL正确字串拼接方式 : Literal Replacement
- Query Multi Mapping 使用方式
- Query Multi Mapping 底层原理
- QueryMultiple 底层原理
- TypeHandler 自订Mapping逻辑使用、底层逻辑
- CommandBehavior的细节处理
- Parameter 参数化底层原理
- IN 多集合参数化底层原理
- DynamicParameter 底层原理、自订实作
- 单次、多次 Execute 底层原理
- ExecuteScalar应用
- 总结
1.前言、目录、安装环境
经过业界前辈、StackOverflow多年推广,「Dapper搭配Entity Framework」成为一种功能强大的组合,它满足「安全、方便、高效、好维护」需求。
但目前中文网路文章,虽然有很多关于Dapper的文章但都停留在如何使用,没人系统性解说底层原理。所以有了此篇「深入Dapper源码」想带大家进入Dapper底层,了解Dapper的精美细节设计、高效原理,并学起来实际应用在工作当中。
建立Dapper Debug环境
- 到Dapper Github 首页 Clone最新版本到自己本机端
- 建立.NET Core Console专案

- 需要安装NuGet SqlClient套件、添加Dapper Project Reference
- 下中断点运行就可以Runtime查看逻辑
个人环境
- 数据库 : MSSQLLocalDB
- Visaul Studio版本 : 2019
- LINQ Pad 5 版本
- Dapper版本 : V2.0.30
- 反编译 : ILSpy
2.Dynamic Query 原理 Part1
在前期开发阶段因为表格结构还在调整阶段,或是不值得额外宣告类别轻量需求,使用Dapper dynamic Query可以节省下来回修改class属性的时间。当表格稳定下来后使用POCO生成器快速生成Class转成强型别维护。
为何Dapper可以如此方便,支援dynamic?
追溯Query方法源码可以发现两个重点
- 实体类别其实是
DapperRow再隐性转型为dynamic。

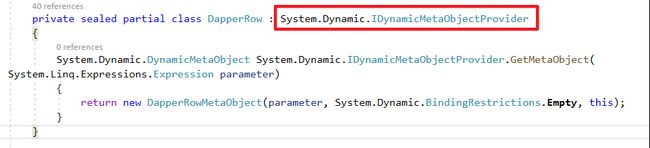
- DapperRow继承
IDynamicMetaObjectProvider并且实作对应方法。
此段逻辑我这边做一个简化版本的Dapper dynamic Query让读者了解转换逻辑 :
- 建立
dynamic类别变量,实体类别是ExpandoObject - 因为有继承关系可以转型为
IDictionary - 使用DataReader使用GetName取得栏位名称,借由栏位index取得值,并将两者分别添加进Dictionary当作key跟value。
- 因为ExpandoObject有实作IDynamicMetaObjectProvider介面可以转换成dynamic
public static class DemoExtension
{
public static IEnumerable Query(this IDbConnection cnn, string sql)
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
yield return reader.CastToDynamic();
}
}
}
}
private static dynamic CastToDynamic(this IDataReader reader)
{
dynamic e = new ExpandoObject();
var d = e as IDictionary;
for (int i = 0; i < reader.FieldCount; i++)
d.Add(reader.GetName(i),reader[i]);
return e;
}
} 
3.Dynamic Query 原理 Part2
有了前面简单ExpandoObject Dynamic Query例子的概念后,接着进到底层来了解Dapper如何细节处理,为何要自订义DynamicMetaObjectProvider。
首先掌握Dynamic Query流程逻辑 :
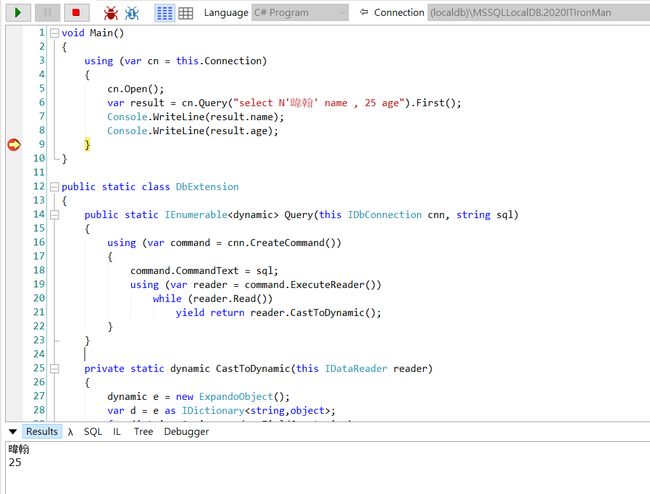
假设使用下面代码
using (var cn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Integrated Security=SSPI;Initial Catalog=master;"))
{
var result = cn.Query("select N'暐翰' Name,26 Age").First();
Console.WriteLine(result.Name);
}取值的过程会是 : 建立动态Func > 保存在缓存 > 使用result.Name > 转成呼叫 ((DapperRow)result)["Name"] > 从DapperTable.Values阵列中以"Name"栏位对应的Index取值
接着查看源码GetDapperRowDeserializer方法,它掌管dynamic如何运行的逻辑,并动态建立成Func给上层API呼叫、缓存重复利用。
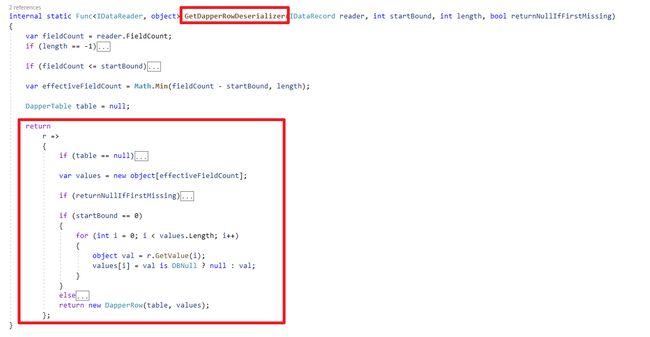
此段Func逻辑 :
DapperTable虽然是方法内的局部变量,但是被生成的Func引用,所以
不会被GC一直保存在内存内重复利用。
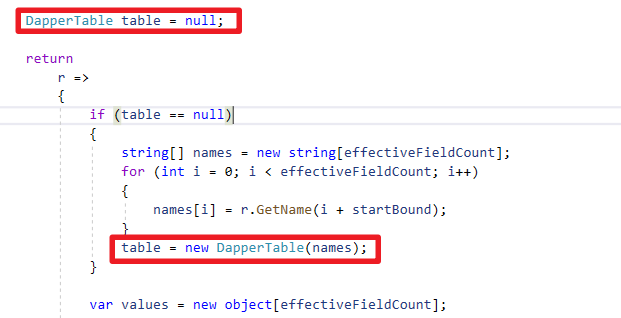
- 因为是dynamic不需要考虑类别Mapping,这边直接使用
GetValue(index)向数据库取值
var values = new object[select栏位数量];
for (int i = 0; i < values.Length; i++)
{
object val = r.GetValue(i);
values[i] = val is DBNull ? null : val;
}- 将资料保存到DapperRow内
public DapperRow(DapperTable table, object[] values)
{
this.table = table ?? throw new ArgumentNullException(nameof(table));
this.values = values ?? throw new ArgumentNullException(nameof(values));
}- DapperRow 继承 IDynamicMetaObjectProvider 并实作 GetMetaObject 方法,实作逻辑是返回DapperRowMetaObject物件。
private sealed partial class DapperRow : System.Dynamic.IDynamicMetaObjectProvider
{
DynamicMetaObject GetMetaObject(Expression parameter)
{
return new DapperRowMetaObject(parameter, System.Dynamic.BindingRestrictions.Empty, this);
}
}DapperRowMetaObject主要功能是定义行为,借由override
BindSetMember、BindGetMember方法,Dapper定义了Get、Set的行为分别使用IDictionary跟DapperRow - SetValue方法
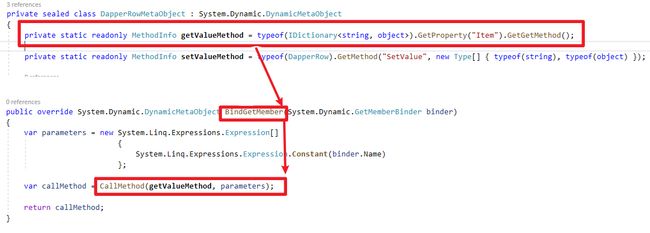
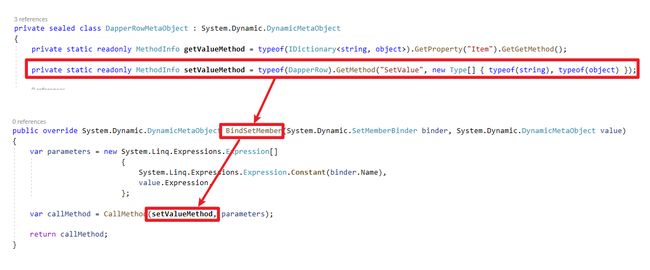
最后Dapper利用DataReader的
栏位顺序性,先利用栏位名称取得Index,再利用Index跟Values取得值
为何要继承IDictionary?
可以思考一个问题 : 在DapperRowMetaObject可以自行定义Get跟Set行为,那么不使用Dictionary - GetItem方法,改用其他方式,是否代表不需要继承IDictionary?
Dapper这样做的原因之一跟开放原则有关,DapperTable、DapperRow都是底层实作类别,基于开放封闭原则不应该开放给使用者,所以设为private权限。
private class DapperTable{/*略*/}
private class DapperRow :IDictionary, IReadOnlyDictionary,System.Dynamic.IDynamicMetaObjectProvider{/*略*/} 那么使用者想要知道栏位名称怎么办?
因为DapperRow实作IDictionary所以可以向上转型为IDictionary,利用它为公开介面特性取得栏位资料。
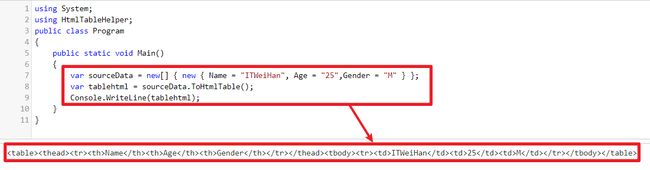
public interface IDictionary : ICollection>, IEnumerable>, IEnumerable{/*略*/} 举个例子,笔者有做一个小工具HtmlTableHelper就是利用这特性,自动将Dapper Dynamic Query转成Table Html,如以下代码跟图片
using (var cn = "Your Connection")
{
var sourceData = cn.Query(@"select 'ITWeiHan' Name,25 Age,'M' Gender");
var tablehtml = sourceData.ToHtmlTable(); //Result : Name Age Gender ITWeiHan 25 M
}
4. Strongly Typed Mapping 原理 Part1 : ADO.NET对比Dapper
接下来是Dapper关键功能 Strongly Typed Mapping,因为难度高,这边会切分成多篇来解说。
第一篇先以ADO.NET DataReader GetItem By Index跟Dapper Strongly Typed Query对比,查看两者IL的差异,了解Dapper Query Mapping的主要逻辑。
有了逻辑后,如何实作,我这边依序用三个技术 :Reflection、Expression、Emit 从头实作三个版本Query方法来让读者渐进式了解。
ADO.NET对比Dapper
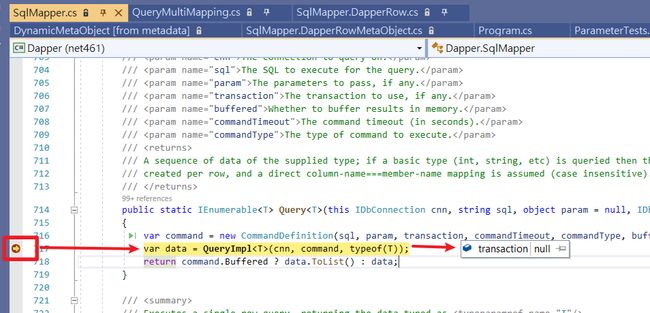
首先使用以下代码来追踪Dapper Query逻辑
class Program
{
static void Main(string[] args)
{
using (var cn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Integrated Security=SSPI;Initial Catalog=master;"))
{
var result = cn.Query("select N'暐翰' Name , 25 Age").First();
Console.WriteLine(result.Name);
Console.WriteLine(result.Age);
}
}
}
public class User
{
public string Name { get; set; }
public int Age { get; set; }
} 这边需要重点来看Dapper.SqlMapper.GenerateDeserializerFromMap方法,它负责Mapping的逻辑,可以看到里面大量使用Emit IL技术。
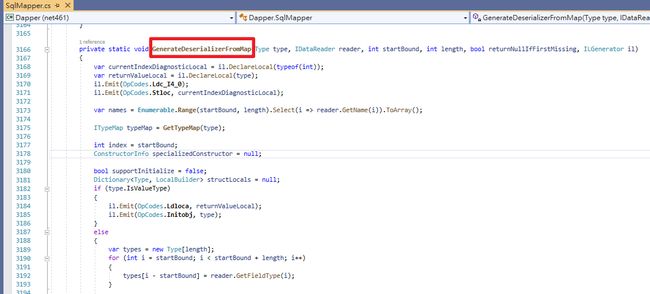
要了解这段IL逻辑,我的方式 :「不应该直接进到细节,而是先查看完整生成的IL」,至于如何查看,这边需要先准备 il-visualizer 开源工具,它可以在Runtime查看DynamicMethod生成的IL。
它预设支持vs 2015、2017,假如跟我一样使用vs2019的读者,需要注意
- 需要手动解压缩到
%USERPROFILE%\Documents\Visual Studio 2019路径下面

.netstandard2.0专案,需要建立netstandard2.0并解压缩到该资料夹
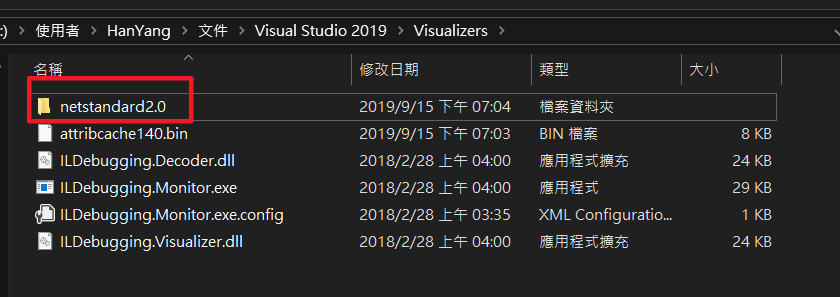
最后重开visaul studio并debug运行,进到GetTypeDeserializerImpl方法,对DynamicMethod点击放大镜 > IL visualizer > 查看Runtime生成的IL代码
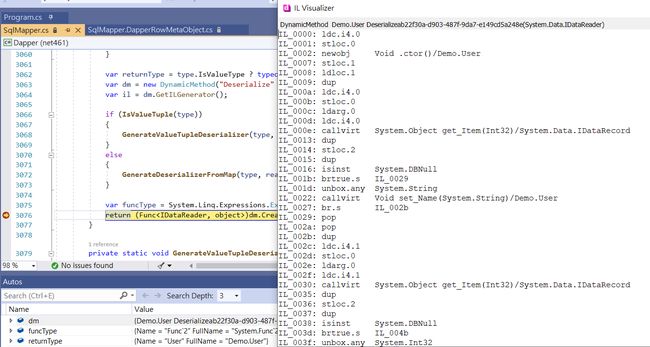
可以得出以下IL
IL_0000: ldc.i4.0
IL_0001: stloc.0
IL_0002: newobj Void .ctor()/Demo.User
IL_0007: stloc.1
IL_0008: ldloc.1
IL_0009: dup
IL_000a: ldc.i4.0
IL_000b: stloc.0
IL_000c: ldarg.0
IL_000d: ldc.i4.0
IL_000e: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0013: dup
IL_0014: stloc.2
IL_0015: dup
IL_0016: isinst System.DBNull
IL_001b: brtrue.s IL_0029
IL_001d: unbox.any System.String
IL_0022: callvirt Void set_Name(System.String)/Demo.User
IL_0027: br.s IL_002b
IL_0029: pop
IL_002a: pop
IL_002b: dup
IL_002c: ldc.i4.1
IL_002d: stloc.0
IL_002e: ldarg.0
IL_002f: ldc.i4.1
IL_0030: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0035: dup
IL_0036: stloc.2
IL_0037: dup
IL_0038: isinst System.DBNull
IL_003d: brtrue.s IL_004b
IL_003f: unbox.any System.Int32
IL_0044: callvirt Void set_Age(Int32)/Demo.User
IL_0049: br.s IL_004d
IL_004b: pop
IL_004c: pop
IL_004d: stloc.1
IL_004e: leave IL_0060
IL_0053: ldloc.0
IL_0054: ldarg.0
IL_0055: ldloc.2
IL_0056: call Void ThrowDataException(System.Exception, Int32, System.Data.IDataReader, System.Object)/Dapper.SqlMapper
IL_005b: leave IL_0060
IL_0060: ldloc.1
IL_0061: ret 要了解这段IL之前需要先了解ADO.NET DataReader快速读取资料方式会使用GetItem By Index方式,如以下代码
public static class DemoExtension
{
private static User CastToUser(this IDataReader reader)
{
var user = new User();
var value = reader[0];
if(!(value is System.DBNull))
user.Name = (string)value;
var value = reader[1];
if(!(value is System.DBNull))
user.Age = (int)value;
return user;
}
public static IEnumerable Query(this IDbConnection cnn, string sql)
{
if (cnn.State == ConnectionState.Closed) cnn.Open();
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
while (reader.Read())
yield return reader.CastToUser();
}
}
} 接着查看此Demo - CastToUser方法生成的IL代码
DemoExtension.CastToUser:
IL_0000: nop
IL_0001: newobj User..ctor
IL_0006: stloc.0 // user
IL_0007: ldarg.0
IL_0008: ldc.i4.0
IL_0009: callvirt System.Data.IDataRecord.get_Item
IL_000E: stloc.1 // value
IL_000F: ldloc.1 // value
IL_0010: isinst System.DBNull
IL_0015: ldnull
IL_0016: cgt.un
IL_0018: ldc.i4.0
IL_0019: ceq
IL_001B: stloc.2
IL_001C: ldloc.2
IL_001D: brfalse.s IL_002C
IL_001F: ldloc.0 // user
IL_0020: ldloc.1 // value
IL_0021: castclass System.String
IL_0026: callvirt User.set_Name
IL_002B: nop
IL_002C: ldarg.0
IL_002D: ldc.i4.1
IL_002E: callvirt System.Data.IDataRecord.get_Item
IL_0033: stloc.1 // value
IL_0034: ldloc.1 // value
IL_0035: isinst System.DBNull
IL_003A: ldnull
IL_003B: cgt.un
IL_003D: ldc.i4.0
IL_003E: ceq
IL_0040: stloc.3
IL_0041: ldloc.3
IL_0042: brfalse.s IL_0051
IL_0044: ldloc.0 // user
IL_0045: ldloc.1 // value
IL_0046: unbox.any System.Int32
IL_004B: callvirt User.set_Age
IL_0050: nop
IL_0051: ldloc.0 // user
IL_0052: stloc.s 04
IL_0054: br.s IL_0056
IL_0056: ldloc.s 04
IL_0058: ret
跟Dapper生成的IL比对可以发现大致是一样的(差异部分后面会讲解),代表两者在运行的逻辑、效率上都会是差不多的,这也是为何Dapper效率接近原生ADO.NET的原因之一。
5. Strongly Typed Mapping 原理 Part2 : Reflection版本
在前面ADO.NET Mapping例子可以发现严重问题「没办法多类别共用方法,每新增一个类别就需要重写代码」。要解决这个问题,可以写一个共用方法在Runtime时期针对不同的类别做不同的逻辑处理。
实作方式做主要有三种Reflection、Expression、Emit,这边首先介绍最简单方式:「Reflection」,我这边会使用反射方式从零模拟Query写代码,让读者初步了解动态处理概念。(假如有经验的读者可以跳过本篇)
逻辑 :
- 使用泛型传递动态类别
- 使用
泛型的条件约束new()达到动态建立物件 - DataReader需要使用
属性字串名称当Key,可以使用Reflection取得动态类别的属性名称,在借由DataReader this[string parameter]取得数据库资料 - 使用PropertyInfo.SetValue方式动态将数据库资料赋予物件
最后得到以下代码 :
public static class DemoExtension
{
public static IEnumerable Query(this IDbConnection cnn, string sql) where T : new()
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
while (reader.Read())
yield return reader.CastToType();
}
}
//1.使用泛型传递动态类别
private static T CastToType(this IDataReader reader) where T : new()
{
//2.使用泛型的条件约束new()达到动态建立物件
var instance = new T();
//3.DataReader需要使用属性字串名称当Key,可以使用Reflection取得动态类别的属性名称,在借由DataReader this[string parameter]取得数据库资料
var type = typeof(T);
var props = type.GetProperties();
foreach (var p in props)
{
var val = reader[p.Name];
//4.使用PropertyInfo.SetValue方式动态将数据库资料赋予物件
if( !(val is System.DBNull) )
p.SetValue(instance, val);
}
return instance;
}
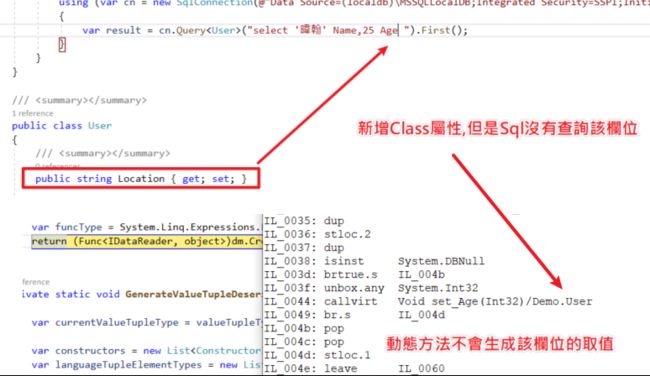
} Reflection版本优点是代码简单,但它有以下问题
- 不应该重复属性查询,没用到就要忽略
举例 : 假如类别有N个属性,SQL指查询3个栏位,土炮ORM每次PropertyInfo foreach还是N次不是3次。而Dapper在Emit IL当中特别优化此段逻辑 :「查多少用多少,不浪费」(这段之后讲解)。
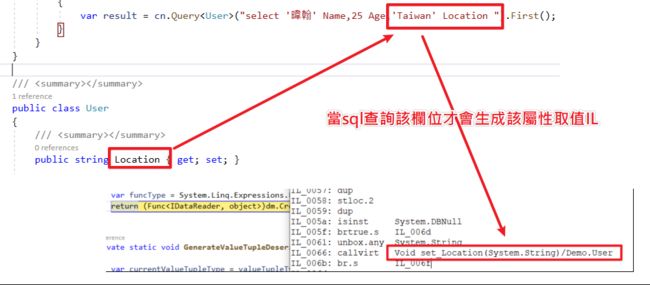
- 效率问题 :
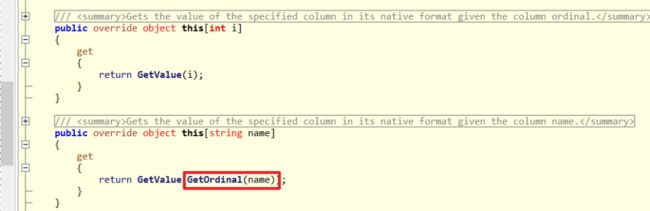
- 反射效率会比较慢,这点之后会介绍解决方式 :
「查表法 + 动态建立方法」以空间换取时间。 - 使用字串Key取值会多呼叫了
GetOrdinal方法,可以查看MSDN官方解释,效率比Index取值差。

6.Strongly Typed Mapping 原理 Part3 : 动态建立方法重要概念「结果反推程式码」优化效率
接着使用Expression来解决Reflection版本问题,主要是利用Expression特性 : 「可以在Runtime时期动态建立方法」来解决问题。
在这之前需要先有一个重要概念 : 「从结果反推最简洁代码」优化效率,举个例子 : 以前初学程式时一个经典题目「打印正三角型星星」做出一个长度为3的正三角,常见作法会是回圈+递回方式
void Main()
{
Print(3,0);
}
static void Print(int length, int spaceLength)
{
if (length < 0)
return;
else
Print(length - 1, spaceLength + 1);
for (int i = 0; i < spaceLength; i++)
Console.Write(" ");
for (int i = 0; i < length; i++)
Console.Write("* ");
Console.WriteLine("");
}但其实这个题目在已经知道长度的情况下,可以被改成以下代码
Console.WriteLine(" * ");
Console.WriteLine(" * * ");
Console.WriteLine("* * * ");这个概念很重要,因为是从结果反推代码,所以逻辑直接、效率快,而Dapper就是使用此概念来动态建立方法。
举例 : 假设有一段代码如下,我们可以从结果得出
- User Class的Name属性对应Reader Index 0 、类别是String 、 预设值是null
- User Class的Age属性对应Reader Index 1 、类别是int 、 预设值是0
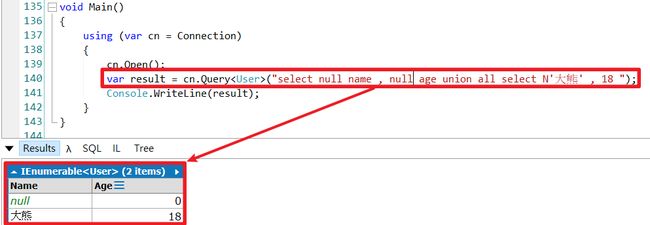
void Main()
{
using (var cn = Connection)
{
var result = cn.Query("select N'暐翰' Name,26 Age").First();
}
}
class User
{
public string Name { get; set; }
public int Age { get; set; }
} 假如系统能帮忙生成以下逻辑方法,那么效率会是最好的
User 动态方法(IDataReader reader)
{
var user = new User();
var value = reader[0];
if( !(value is System.DBNull) )
user.Name = (string)value;
value = reader[1];
if( !(value is System.DBNull) )
user.Age = (int)value;
return user;
}另外上面例子可以看出对Dapper来说SQL Select对应Class属性顺序很重要,所以后面会讲解Dapper在缓存的算法特别针对此优化。
7.Strongly Typed Mapping 原理 Part4 : Expression版本
有了前面的逻辑,就着使用Expression实作动态建立方法。
为何先使用 Expression 实作而不是 Emit ?
除了有能力动态建立方法,相比Emit有以下优点 :
可读性好,可用熟悉的关键字,像是变量Variable对应Expression.Variable、建立物件New对应Expression.New

方便Runtime Debug,可以在Debug模式下看到Expression对应逻辑代码
所以特别适合介绍动态方法建立,但Expression相比Emit无法作一些细节操作,这点会在后面Emit讲解到。
改写Expression版本
逻辑 :
- 取得sql select所有栏位名称
- 取得mapping类别的属性资料 > 将index,sql栏位,class属性资料做好对应封装在一个变量内方便后面使用
- 动态建立方法 : 从数据库Reader按照顺序读取我们要的资料,其中代码逻辑 :
User 动态方法(IDataReader reader)
{
var user = new User();
var value = reader[0];
if( !(value is System.DBNull) )
user.Name = (string)value;
value = reader[1];
if( !(value is System.DBNull) )
user.Age = (int)value;
return user;
}最后得出以下Exprssion版本代码
public static class DemoExtension
{
public static IEnumerable Query(this IDbConnection cnn, string sql) where T : new()
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
var func = CreateMappingFunction(reader, typeof(T));
while (reader.Read())
{
var result = func(reader as DbDataReader);
yield return result is T ? (T)result : default(T);
}
}
}
}
private static Func CreateMappingFunction(IDataReader reader, Type type)
{
//1. 取得sql select所有栏位名称
var names = Enumerable.Range(0, reader.FieldCount).Select(index => reader.GetName(index)).ToArray();
//2. 取得mapping类别的属性资料 > 将index,sql栏位,class属性资料做好对应封装在一个变量内方便后面使用
var props = type.GetProperties().ToList();
var members = names.Select((columnName, index) =>
{
var property = props.Find(p => string.Equals(p.Name, columnName, StringComparison.Ordinal))
?? props.Find(p => string.Equals(p.Name, columnName, StringComparison.OrdinalIgnoreCase));
return new
{
index,
columnName,
property
};
});
//3. 动态建立方法 : 从数据库Reader按照顺序读取我们要的资料
/*方法逻辑 :
User 动态方法(IDataReader reader)
{
var user = new User();
var value = reader[0];
if( !(value is System.DBNull) )
user.Name = (string)value;
value = reader[1];
if( !(value is System.DBNull) )
user.Age = (int)value;
return user;
}
*/
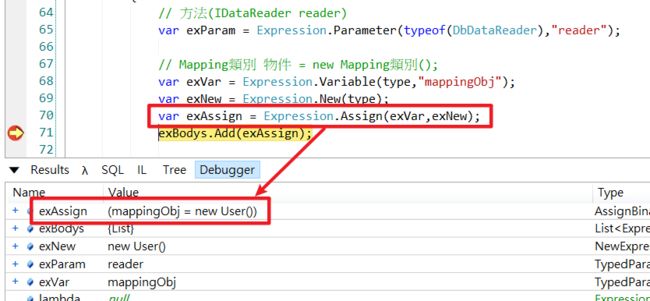
var exBodys = new List();
{
// 方法(IDataReader reader)
var exParam = Expression.Parameter(typeof(DbDataReader), "reader");
// Mapping类别 物件 = new Mapping类别();
var exVar = Expression.Variable(type, "mappingObj");
var exNew = Expression.New(type);
{
exBodys.Add(Expression.Assign(exVar, exNew));
}
// var value = defalut(object);
var exValueVar = Expression.Variable(typeof(object), "value");
{
exBodys.Add(Expression.Assign(exValueVar, Expression.Constant(null)));
}
var getItemMethod = typeof(DbDataReader).GetMethods().Where(w => w.Name == "get_Item")
.First(w => w.GetParameters().First().ParameterType == typeof(int));
foreach (var m in members)
{
//reader[0]
var exCall = Expression.Call(
exParam, getItemMethod,
Expression.Constant(m.index)
);
// value = reader[0];
exBodys.Add(Expression.Assign(exValueVar, exCall));
//user.Name = (string)value;
var exProp = Expression.Property(exVar, m.property.Name);
var exConvert = Expression.Convert(exValueVar, m.property.PropertyType); //(string)value
var exPropAssign = Expression.Assign(exProp, exConvert);
//if ( !(value is System.DBNull))
// (string)value
var exIfThenElse = Expression.IfThen(
Expression.Not(Expression.TypeIs(exValueVar, typeof(System.DBNull)))
, exPropAssign
);
exBodys.Add(exIfThenElse);
}
// return user;
exBodys.Add(exVar);
// Compiler Expression
var lambda = Expression.Lambda>(
Expression.Block(
new[] { exVar, exValueVar },
exBodys
), exParam
);
return lambda.Compile();
}
}
} 查询效果图 :
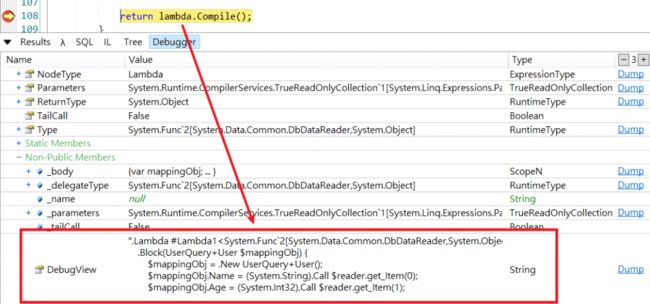
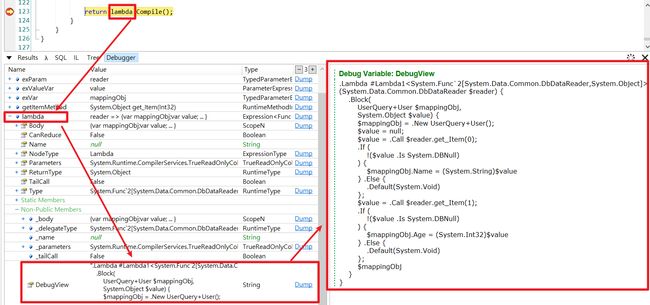
最后查看Expression.Lambda > DebugView(注意是非公开属性)验证代码 :
.Lambda #Lambda1(System.Data.Common.DbDataReader $reader) {
.Block(
UserQuery+User $mappingObj,
System.Object $value) {
$mappingObj = .New UserQuery+User();
$value = null;
$value = .Call $reader.get_Item(0);
.If (
!($value .Is System.DBNull)
) {
$mappingObj.Name = (System.String)$value
} .Else {
.Default(System.Void)
};
$value = .Call $reader.get_Item(1);
.If (
!($value .Is System.DBNull)
) {
$mappingObj.Age = (System.Int32)$value
} .Else {
.Default(System.Void)
};
$mappingObj
}
} 
8. Strongly Typed Mapping 原理 Part5 : Emit IL反建立C#代码
有了前面Expression版本概念后,接着可以进到Dapper底层最核心的技术 : Emit。
首先要有个概念,MSIL(CIL)目的是给JIT编译器看的,所以可读性会很差、难Debug,但比起Expression来说可以做到更细节的逻辑操作。
在实际环境开发使用Emit,一般会先写好C#代码后 > 反编译查看IL > 使用Emit建立动态方法,举例 :
1.首先建立一个简单打印例子 :
void SyaHello()
{
Console.WriteLine("Hello World");
}2.反编译查看IL
SyaHello:
IL_0000: nop
IL_0001: ldstr "Hello World"
IL_0006: call System.Console.WriteLine
IL_000B: nop
IL_000C: ret 3.使用DynamicMethod + Emit建立动态方法
void Main()
{
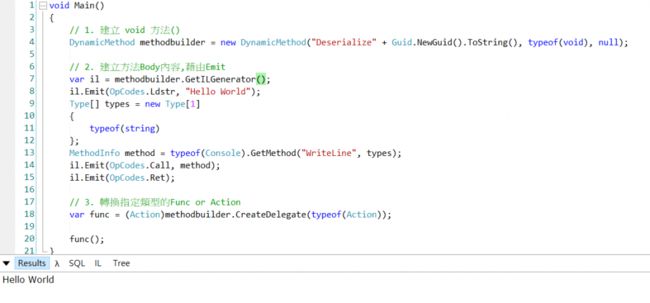
// 1. 建立 void 方法()
DynamicMethod methodbuilder = new DynamicMethod("Deserialize" + Guid.NewGuid().ToString(),typeof(void),null);
// 2. 建立方法Body内容,借由Emit
var il = methodbuilder.GetILGenerator();
il.Emit(OpCodes.Ldstr, "Hello World");
Type[] types = new Type[1]
{
typeof(string)
};
MethodInfo method = typeof(Console).GetMethod("WriteLine", types);
il.Emit(OpCodes.Call,method);
il.Emit(OpCodes.Ret);
// 3. 转换指定类型的Func or Action
var action = (Action)methodbuilder.CreateDelegate(typeof(Action));
action();
}
但是对已经写好的专案来说就不是这样流程了,开发者不一定会好心的告诉你当初设计的逻辑,所以接着讨论此问题。
如果像是Dapper只有Emit IL没有C# Source Code专案怎么办?
我的解决方式是 : 「既然只有Runtime才能知道IL,那么将IL保存成静态档案再反编译查看」
这边可以使用MethodBuild + Save方法将IL保存成静态exe档案 > 反编译查看,但需要特别注意
- 请对应好参数跟返回类别,否则会编译错误。
- netstandard不支援此方式,Dapper需要使用
region if 指定版本来做区分,否则不能使用,如图片
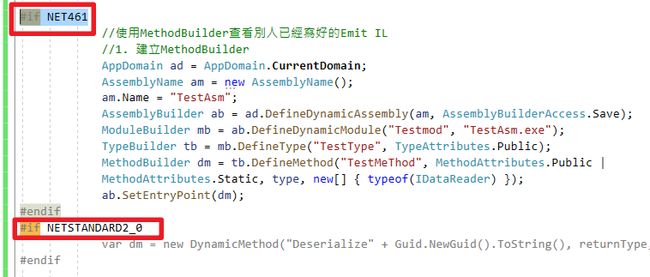
代码如下 :
//使用MethodBuilder查看别人已经写好的Emit IL
//1. 建立MethodBuilder
AppDomain ad = AppDomain.CurrentDomain;
AssemblyName am = new AssemblyName();
am.Name = "TestAsm";
AssemblyBuilder ab = ad.DefineDynamicAssembly(am, AssemblyBuilderAccess.Save);
ModuleBuilder mb = ab.DefineDynamicModule("Testmod", "TestAsm.exe");
TypeBuilder tb = mb.DefineType("TestType", TypeAttributes.Public);
MethodBuilder dm = tb.DefineMethod("TestMeThod", MethodAttributes.Public |
MethodAttributes.Static, type, new[] { typeof(IDataReader) });
ab.SetEntryPoint(dm);
// 2. 填入IL代码
//..略
// 3. 生成静态档案
tb.CreateType();
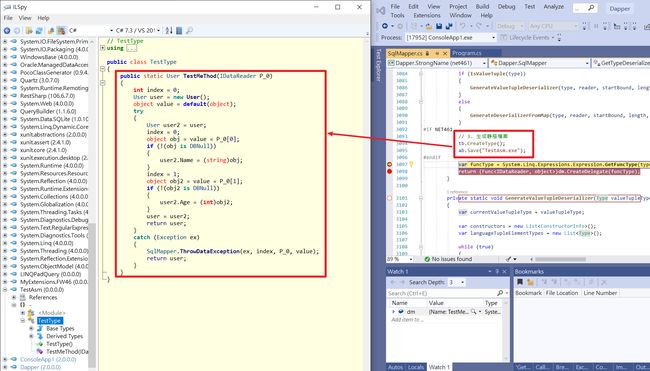
ab.Save("TestAsm.exe");接着使用此方式在GetTypeDeserializerImpl方法反编译Dapper Query Mapping IL,可以得出C#代码 :
public static User TestMeThod(IDataReader P_0)
{
int index = 0;
User user = new User();
object value = default(object);
try
{
User user2 = user;
index = 0;
object obj = value = P_0[0];
if (!(obj is DBNull))
{
user2.Name = (string)obj;
}
index = 1;
object obj2 = value = P_0[1];
if (!(obj2 is DBNull))
{
user2.Age = (int)obj2;
}
user = user2;
return user;
}
catch (Exception ex)
{
SqlMapper.ThrowDataException(ex, index, P_0, value);
return user;
}
}
有了C#代码后再来了解Emit逻辑会快很多,接着就可以进到Emit版本Query实作部分。
9.Strongly Typed Mapping 原理 Part6 : Emit版本
以下代码是Emit版本,我把C#对应IL部分都写在注解。
public static class DemoExtension
{
public static IEnumerable Query(this IDbConnection cnn, string sql) where T : new()
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
var func = GetTypeDeserializerImpl(typeof(T), reader);
while (reader.Read())
{
var result = func(reader as DbDataReader);
yield return result is T ? (T)result : default(T);
}
}
}
}
private static Func GetTypeDeserializerImpl(Type type, IDataReader reader, int startBound = 0, int length = -1, bool returnNullIfFirstMissing = false)
{
var returnType = type.IsValueType ? typeof(object) : type;
var dm = new DynamicMethod("Deserialize" + Guid.NewGuid().ToString(), returnType, new[] { typeof(IDataReader) }, type, true);
var il = dm.GetILGenerator();
//C# : User user = new User();
//IL :
//IL_0001: newobj
//IL_0006: stloc.0
var constructor = returnType.GetConstructors(BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic)[0]; //这边简化成只会有预设constructor
il.Emit(OpCodes.Newobj, constructor);
var returnValueLocal = il.DeclareLocal(type);
il.Emit(OpCodes.Stloc, returnValueLocal); //User user = new User();
// C# :
//object value = default(object);
// IL :
//IL_0007: ldnull
//IL_0008: stloc.1 // value
var valueLoacl = il.DeclareLocal(typeof(object));
il.Emit(OpCodes.Ldnull);
il.Emit(OpCodes.Stloc, valueLoacl);
int index = startBound;
var getItem = typeof(IDataRecord).GetProperties(BindingFlags.Instance | BindingFlags.Public)
.Where(p => p.GetIndexParameters().Length > 0 && p.GetIndexParameters()[0].ParameterType == typeof(int))
.Select(p => p.GetGetMethod()).First();
foreach (var p in type.GetProperties())
{
//C# : value = P_0[0];
//IL:
//IL_0009: ldarg.0
//IL_000A: ldc.i4.0
//IL_000B: callvirt System.Data.IDataRecord.get_Item
//IL_0010: stloc.1 // value
il.Emit(OpCodes.Ldarg_0); //取得reader参数
EmitInt32(il, index);
il.Emit(OpCodes.Callvirt, getItem);
il.Emit(OpCodes.Stloc, valueLoacl);
//C#: if (!(value is DBNull)) user.Name = (string)value;
//IL:
// IL_0011: ldloc.1 // value
// IL_0012: isinst System.DBNull
// IL_0017: ldnull
// IL_0018: cgt.un
// IL_001A: ldc.i4.0
// IL_001B: ceq
// IL_001D: stloc.2
// IL_001E: ldloc.2
// IL_001F: brfalse.s IL_002E
// IL_0021: ldloc.0 // user
// IL_0022: ldloc.1 // value
// IL_0023: castclass System.String
// IL_0028: callvirt UserQuery+User.set_Name
il.Emit(OpCodes.Ldloc, valueLoacl);
il.Emit(OpCodes.Isinst, typeof(System.DBNull));
il.Emit(OpCodes.Ldnull);
var tmpLoacl = il.DeclareLocal(typeof(int));
il.Emit(OpCodes.Cgt_Un);
il.Emit(OpCodes.Ldc_I4_0);
il.Emit(OpCodes.Ceq);
il.Emit(OpCodes.Stloc,tmpLoacl);
il.Emit(OpCodes.Ldloc,tmpLoacl);
var labelFalse = il.DefineLabel();
il.Emit(OpCodes.Brfalse_S,labelFalse);
il.Emit(OpCodes.Ldloc, returnValueLocal);
il.Emit(OpCodes.Ldloc, valueLoacl);
if (p.PropertyType.IsValueType)
il.Emit(OpCodes.Unbox_Any, p.PropertyType);
else
il.Emit(OpCodes.Castclass, p.PropertyType);
il.Emit(OpCodes.Callvirt, p.SetMethod);
il.MarkLabel(labelFalse);
index++;
}
// IL_0053: ldloc.0 // user
// IL_0054: stloc.s 04 //不需要
// IL_0056: br.s IL_0058
// IL_0058: ldloc.s 04 //不需要
// IL_005A: ret
il.Emit(OpCodes.Ldloc, returnValueLocal);
il.Emit(OpCodes.Ret);
var funcType = System.Linq.Expressions.Expression.GetFuncType(typeof(IDataReader), returnType);
return (Func)dm.CreateDelegate(funcType);
}
private static void EmitInt32(ILGenerator il, int value)
{
switch (value)
{
case -1: il.Emit(OpCodes.Ldc_I4_M1); break;
case 0: il.Emit(OpCodes.Ldc_I4_0); break;
case 1: il.Emit(OpCodes.Ldc_I4_1); break;
case 2: il.Emit(OpCodes.Ldc_I4_2); break;
case 3: il.Emit(OpCodes.Ldc_I4_3); break;
case 4: il.Emit(OpCodes.Ldc_I4_4); break;
case 5: il.Emit(OpCodes.Ldc_I4_5); break;
case 6: il.Emit(OpCodes.Ldc_I4_6); break;
case 7: il.Emit(OpCodes.Ldc_I4_7); break;
case 8: il.Emit(OpCodes.Ldc_I4_8); break;
default:
if (value >= -128 && value <= 127)
{
il.Emit(OpCodes.Ldc_I4_S, (sbyte)value);
}
else
{
il.Emit(OpCodes.Ldc_I4, value);
}
break;
}
}
} 这边Emit的细节概念非常的多,这边无法全部都讲解,先挑出重要概念讲解
Emit Label
在Emit if/else需要使用Label定位,告知编译器条件为true/false时要跳到哪个位子,举例 : 「boolean转整数」,假设要简单将Boolean转换成Int,C#代码可以用「如果是True返回1否则返回0」逻辑来写:
public static int BoolToInt(bool input) => input ? 1 : 0;当转成Emit写法的时候,需要以下逻辑 :
- 考虑Label动态定位问题
- 先要建立好Label让Brtrue_S知道符合条件时要去哪个Label位子
(注意,这时候Label位子还没确定) - 继续按顺序由上而下建立IL
- 等到了
符合条件要运行区块的前一行,使用MarkLabel方法标记Label的位子。
最后写出的C# Emit代码 :
public class Program
{
public static void Main(string[] args)
{
var func = CreateFunc();
Console.WriteLine(func(true)); //1
Console.WriteLine(func(false)); //0
}
static Func CreateFunc()
{
var dm = new DynamicMethod("Test" + Guid.NewGuid().ToString(), typeof(int), new[] { typeof(bool) });
var il = dm.GetILGenerator();
var labelTrue = il.DefineLabel();
il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Brtrue_S, labelTrue);
il.Emit(OpCodes.Ldc_I4_0);
il.Emit(OpCodes.Ret);
il.MarkLabel(labelTrue);
il.Emit(OpCodes.Ldc_I4_1);
il.Emit(OpCodes.Ret);
var funcType = System.Linq.Expressions.Expression.GetFuncType(typeof(bool), typeof(int));
return (Func)dm.CreateDelegate(funcType);
}
} 这边可以发现Emit版本
优点 :
- 能做更多细节的操作
- 因为细节颗粒度小,可以优化的效率更好
缺点 :
- 难以Debug
- 可读性差
- 代码量变大、复杂度增加
接着来看Dapper作者的建议,现在一般专案当中没有必要使用Emit,使用Expression + Func/Action已经可以解决大部分动态方法的需求,尤其是Expression支援Block等方法情况。连结 c# - What's faster: expression trees or manually emitting IL

话虽如此,但有一些厉害的开源专案就是使用Emit管理细节,如果想看懂它们,就需要基础的Emit IL概念。
10.Dapper 效率快关键之一 : Cache 缓存原理
为何Dapper可以这么快?
前面介绍到动态使用 Emit IL 建立 ADO.NET Mapping 方法,但单就这功能无法让 Dapper 被称为轻量ORM效率之王。
因为动态建立方法是需要成本、并耗费时间的动作,单纯使用反而会拖慢速度。但当配合 Cache 后就不一样,将建立好的方法保存在 Cache 内,可以用『空间换取时间』概念加快查询的效率,也就是俗称查表法。
接着追踪Dapper源码,这次需要特别关注的是QueryImpl方法下的Identity、GetCacheInfo

Identity、GetCacheInfo
Identity主要封装各缓存的比较Key属性 :
- sql : 区分不同SQL字串
- type : 区分Mapping类别
- commandType : 负责区分不同数据库
- gridIndex : 主用用在QueryMultiple,后面讲解。
- connectionString : 主要区分同数据库厂商但是不同DB情况
- parametersType : 主要区分参数类别
- typeCount : 主要用在Multi Query多映射,需要搭配override GetType方法,后面讲解
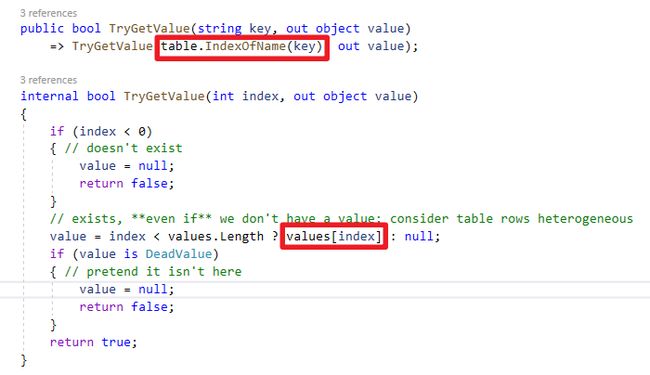
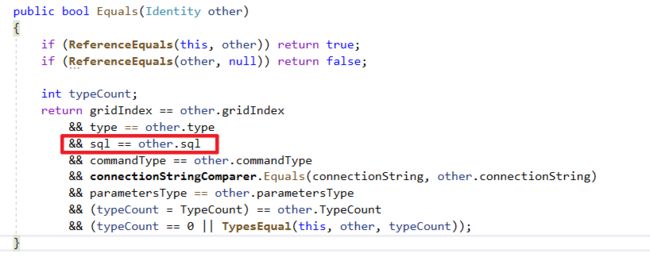
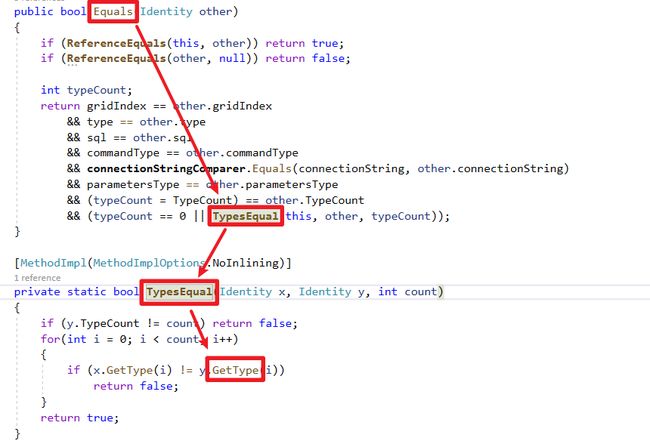
接着搭配GetCacheInfo方法内Dapper使用的缓存类别ConcurrentDictionary,使用TryGetValue方法时会去先比对HashCode接着比对Equals特性,如图片源码。
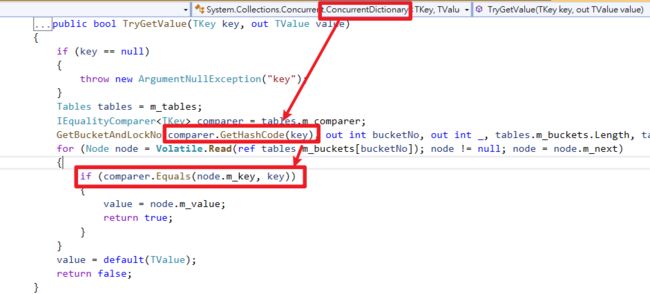
将Key类别Identity借由override Equals方法实现缓存比较算法,可以看到以下Dapper实作逻辑,只要一个属性不一样就会建立一个新的动态方法、缓存。
public bool Equals(Identity other)
{
if (ReferenceEquals(this, other)) return true;
if (ReferenceEquals(other, null)) return false;
int typeCount;
return gridIndex == other.gridIndex
&& type == other.type
&& sql == other.sql
&& commandType == other.commandType
&& connectionStringComparer.Equals(connectionString, other.connectionString)
&& parametersType == other.parametersType
&& (typeCount = TypeCount) == other.TypeCount
&& (typeCount == 0 || TypesEqual(this, other, typeCount));
}以此概念拿之前Emit版本修改成一个简单Cache Demo让读者感受:
public class Identity
{
public string sql { get; set; }
public CommandType? commandType { get; set; }
public string connectionString { get; set; }
public Type type { get; set; }
public Type parametersType { get; set; }
public Identity(string sql, CommandType? commandType, string connectionString, Type type, Type parametersType)
{
this.sql = sql;
this.commandType = commandType;
this.connectionString = connectionString;
this.type = type;
this.parametersType = parametersType;
unchecked
{
hashCode = 17; // we *know* we are using this in a dictionary, so pre-compute this
hashCode = (hashCode * 23) + commandType.GetHashCode();
hashCode = (hashCode * 23) + (sql?.GetHashCode() ?? 0);
hashCode = (hashCode * 23) + (type?.GetHashCode() ?? 0);
hashCode = (hashCode * 23) + (connectionString == null ? 0 : StringComparer.Ordinal.GetHashCode(connectionString));
hashCode = (hashCode * 23) + (parametersType?.GetHashCode() ?? 0);
}
}
public readonly int hashCode;
public override int GetHashCode() => hashCode;
public override bool Equals(object obj) => Equals(obj as Identity);
public bool Equals(Identity other)
{
if (ReferenceEquals(this, other)) return true;
if (ReferenceEquals(other, null)) return false;
return type == other.type
&& sql == other.sql
&& commandType == other.commandType
&& StringComparer.Ordinal.Equals(connectionString, other.connectionString)
&& parametersType == other.parametersType;
}
}
public static class DemoExtension
{
private static readonly Dictionary> readers = new Dictionary>();
public static IEnumerable Query(this IDbConnection cnn, string sql,object param=null) where T : new()
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
var identity = new Identity(command.CommandText, command.CommandType, cnn.ConnectionString, typeof(T), param?.GetType());
// 2. 如果cache有资料就使用,没有资料就动态建立方法并保存在缓存内
if (!readers.TryGetValue(identity, out Func func))
{
//动态建立方法
func = GetTypeDeserializerImpl(typeof(T), reader);
readers[identity] = func;
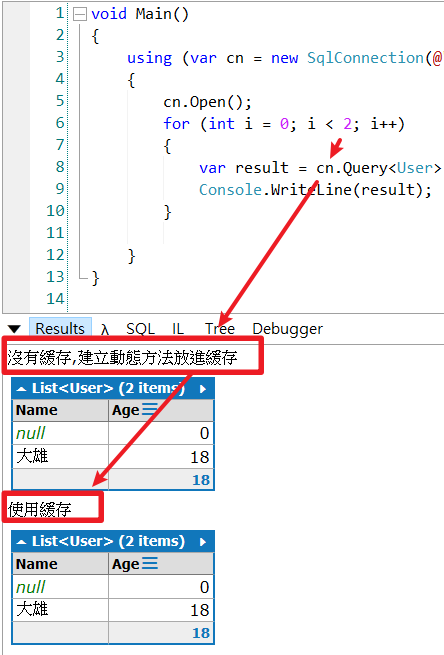
Console.WriteLine("没有缓存,建立动态方法放进缓存");
}else{
Console.WriteLine("使用缓存");
}
// 3. 呼叫生成的方法by reader,读取资料回传
while (reader.Read())
{
var result = func(reader as DbDataReader);
yield return result is T ? (T)result : default(T);
}
}
}
}
private static Func GetTypeDeserializerImpl(Type type, IDataReader reader, int startBound = 0, int length = -1, bool returnNullIfFirstMissing = false)
{
//..略
}
} 效果图 :
11.错误SQL字串拼接方式,会导致效率慢、内存泄漏
了解实作逻辑后,接着延伸一个Dapper使用的重要观念,SQL字串为缓存重要Key值之一,假如不同的SQL字串,Dapper会为此建立新的动态方法、缓存,所以使用不当情况下就算使用StringBuilder也会造成效率慢、内存泄漏问题。
至于为何要以SQL字串当其中一个关键Key,而不是单纯使用Mapping类别的Handle,其中原因之一是跟查询栏位顺序有关,在前面有讲到,Dapper使用「结果反推程式码」方式建立动态方法,代表说顺序跟资料都必须要是固定的,避免SQL Select栏位顺序不一样又使用同一组动态方法,会有A栏位值给B属性错值大问题。
最直接解决方式,对每个不同SQL字串建立不同的动态方法,并保存在不同的缓存。
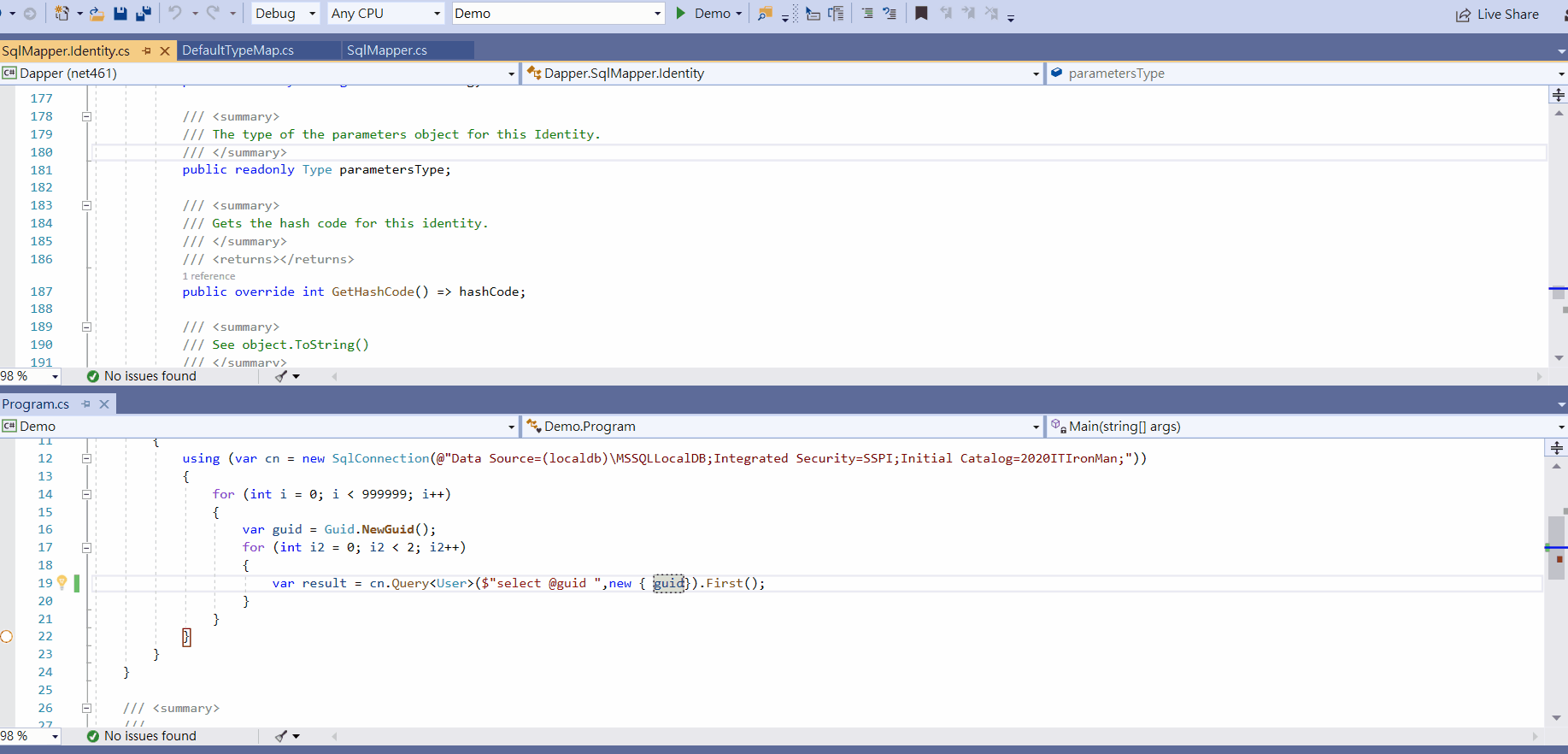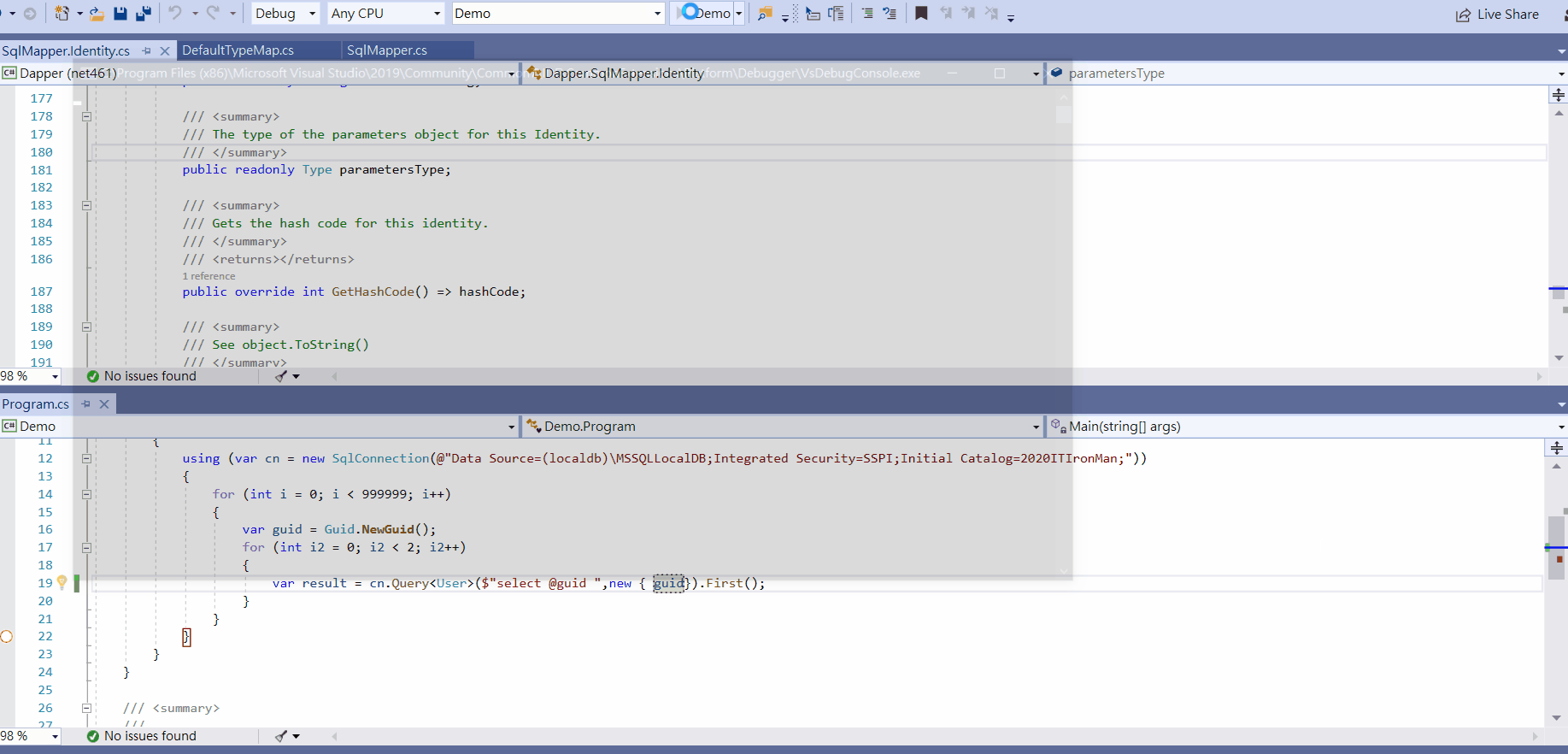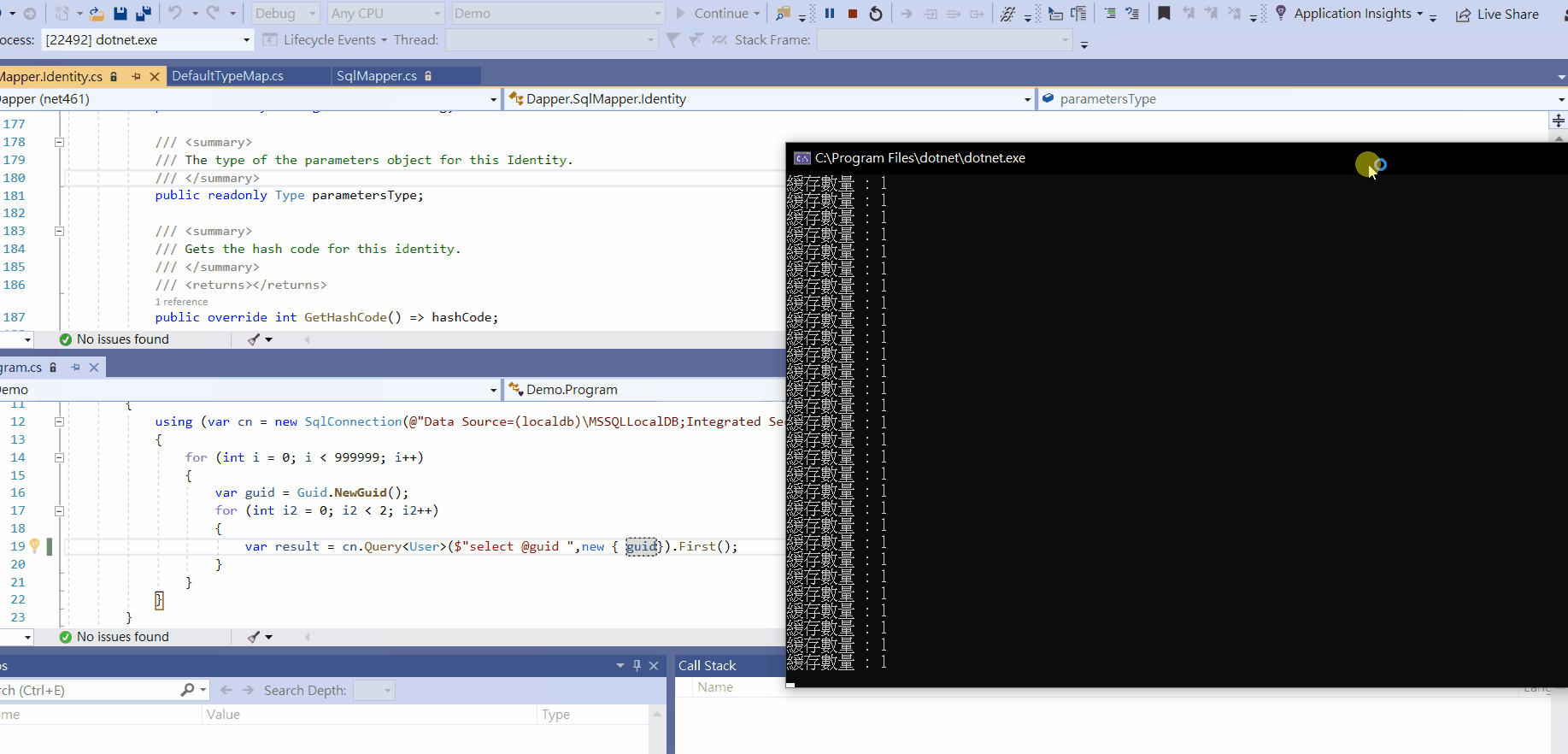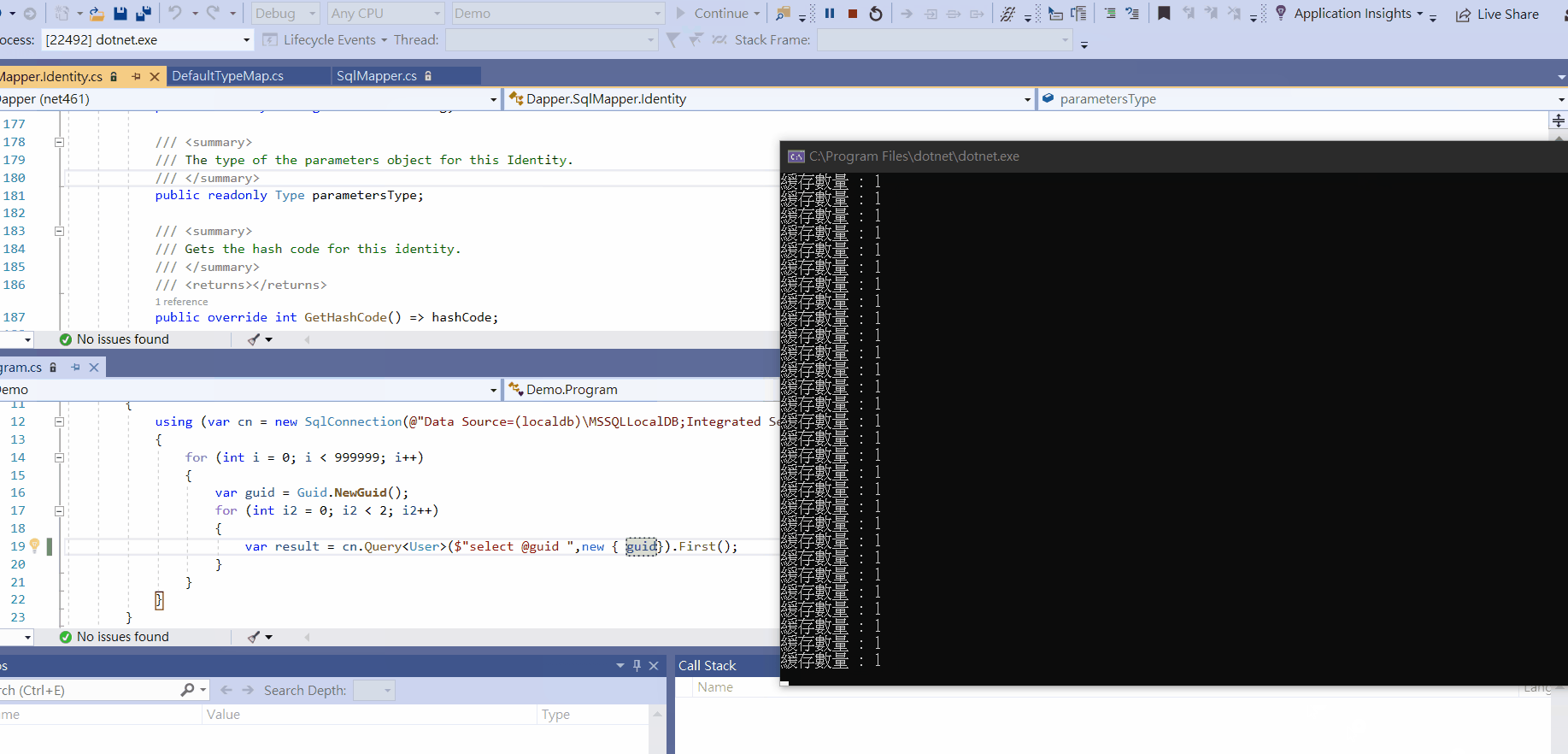
举例,以下代码只是简单的查询动作,查看Dapper Cache数量却达到999999个,如Gif动画显示
using (var cn = new SqlConnection(@"connectionString"))
{
for (int i = 0; i < 999999; i++)
{
var guid = Guid.NewGuid();
for (int i2 = 0; i2 < 2; i2++)
{
var result = cn.Query($"select '{guid}' ").First();
}
}
} 要避免此问题,只需要保持一个原则重复利用SQL字串,而最简单方式就是参数化, 举例 : 将上述代码改成以下代码,缓存数量降为1,达到重复利用目的 :
using (var cn = new SqlConnection(@"connectionString"))
{
for (int i = 0; i < 999999; i++)
{
var guid = Guid.NewGuid();
for (int i2 = 0; i2 < 2; i2++)
{
var result = cn.Query($"select @guid ",new { guid}).First();
}
}
} 
12.Dapper SQL正确字串拼接方式 : Literal Replacement
假如遇到必要拼接SQL字串需求的情况下,举例 : 有时候值使用字串拼接会比不使用参数化效率好,特别是该栏位值只会有几种固定值。
这时候Dapper可以使用Literal Replacements功能,使用方式 : 将要拼接的值字串以{=属性名称}取代,并将值保存在Parameter参数内,举例 :
void Main()
{
using (var cn = Connection)
{
var result = cn.Query("select N'暐翰' Name,26 Age,{=VipLevel} VipLevel", new User{ VipLevel = 1}).First();
}
}为什么Literal Replacement可以避免缓存问题
首先追踪源码GetCacheInfo下GetLiteralTokens方法,可以发现Dapper在建立缓存之前会抓取SQL字串内符合{=变量名称}规格的资料。
private static readonly Regex literalTokens = new Regex(@"(? GetLiteralTokens(string sql)
{
if (string.IsNullOrEmpty(sql)) return LiteralToken.None;
if (!literalTokens.IsMatch(sql)) return LiteralToken.None;
var matches = literalTokens.Matches(sql);
var found = new HashSet(StringComparer.Ordinal);
List list = new List(matches.Count);
foreach (Match match in matches)
{
string token = match.Value;
if (found.Add(match.Value))
{
list.Add(new LiteralToken(token, match.Groups[1].Value));
}
}
return list.Count == 0 ? LiteralToken.None : list;
} 接着在CreateParamInfoGenerator方法生成Parameter参数化动态方法,此段方法IL如下 :
IL_0000: ldarg.1
IL_0001: castclass <>f__AnonymousType1`1[System.Int32]
IL_0006: stloc.0
IL_0007: ldarg.0
IL_0008: callvirt System.Data.IDataParameterCollection get_Parameters()/System.Data.IDbCommand
IL_000d: pop
IL_000e: ldarg.0
IL_000f: ldarg.0
IL_0010: callvirt System.String get_CommandText()/System.Data.IDbCommand
IL_0015: ldstr "{=VipLevel}"
IL_001a: ldloc.0
IL_001b: callvirt Int32 get_VipLevel()/<>f__AnonymousType1`1[System.Int32]
IL_0020: stloc.1
IL_0021: ldloca.s V_1
IL_0023: call System.Globalization.CultureInfo get_InvariantCulture()/System.Globalization.CultureInfo
IL_0028: call System.String ToString(System.IFormatProvider)/System.Int32
IL_002d: callvirt System.String Replace(System.String, System.String)/System.String
IL_0032: callvirt Void set_CommandText(System.String)/System.Data.IDbCommand
IL_0037: ret 接着再生成Mapping动态方法,要了解此段逻辑我这边做一个模拟例子方便读者理解 :
public static class DbExtension
{
public static IEnumerable Query(this DbConnection cnn, string sql, User parameter)
{
using (var command = cnn.CreateCommand())
{
command.CommandText = sql;
CommandLiteralReplace(command, parameter);
using (var reader = command.ExecuteReader())
while (reader.Read())
yield return Mapping(reader);
}
}
private static void CommandLiteralReplace(IDbCommand cmd, User parameter)
{
cmd.CommandText = cmd.CommandText.Replace("{=VipLevel}", parameter.VipLevel.ToString(System.Globalization.CultureInfo.InvariantCulture));
}
private static User Mapping(IDataReader reader)
{
var user = new User();
var value = default(object);
value = reader[0];
if(!(value is System.DBNull))
user.Name = (string)value;
value = reader[1];
if (!(value is System.DBNull))
user.Age = (int)value;
value = reader[2];
if (!(value is System.DBNull))
user.VipLevel = (int)value;
return user;
}
} 看完以上例子,可以发现Dapper Literal Replacements底层原理就是字串取代,同样属于字串拼接方式,为何可以避免缓存问题?
这是因为取代的时机点在SetParameter动态方法内,所以Cache的SQL Key是没有变动过的,可以重复利用同样的SQL字串、缓存。
也因为是字串取代方式,所以只支持基本Value类别,假如使用String类别系统会告知The type String is not supported for SQL literals.,避免SQL Injection问题。
13.Query Multi Mapping 使用方式
接着讲解Dapper Multi Mapping(多对应)实作跟底层逻辑,毕竟工作当中不可能都是一对一概念。
使用方式 :
- 需要自己编写Mapping逻辑,使用方式 :
Query(SQL,Parameter,Mapping逻辑Func) - 需要指定泛型参数类别,规则为
Query(最多支持六组泛型参数) - 指定切割栏位名称,预设使用
ID,假如不一样需要特别指定 (这段后面特别讲解) - 以上顺序都是
由左至右
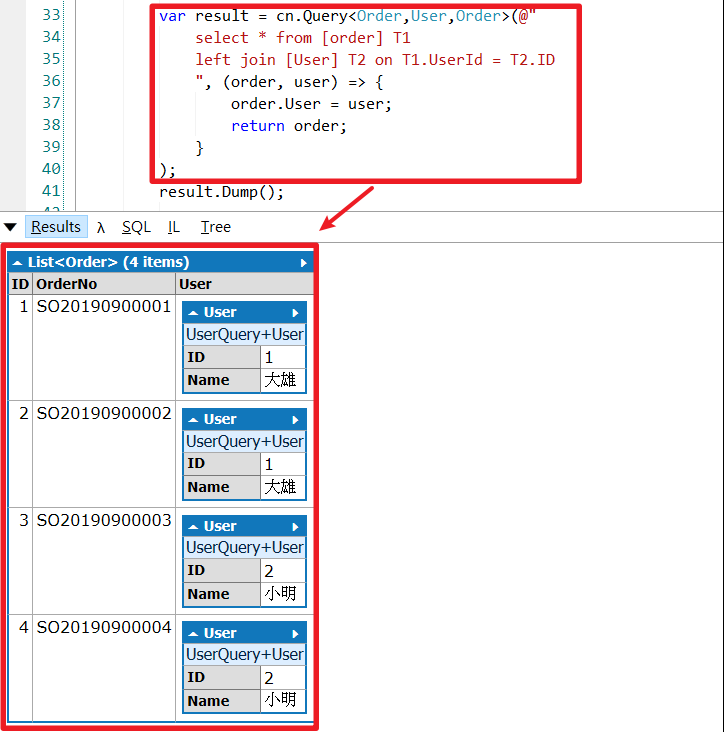
举例 : 有订单(Order)跟会员(User)表格,关系是一对多关系,一个会员可以有多个订单,以下是C# Demo代码 :
void Main()
{
using (var ts = new TransactionScope())
using (var cn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Integrated Security=SSPI;Initial Catalog=master;"))
{
cn.Execute(@"
CREATE TABLE [User]([ID] int, [Name] nvarchar(10));
INSERT INTO [User]([ID], [Name])VALUES(1, N'大雄'),(2, N'小明');
CREATE TABLE [Order]([ID] int, [OrderNo] varchar(13), [UserID] int);
INSERT INTO [Order]([ID], [OrderNo], [UserID])VALUES(1, 'SO20190900001', 1),(2, 'SO20190900002', 1),(3, 'SO20190900003', 2),(4, 'SO20190900004', 2);
");
var result = cn.Query(@"
select * from [order] T1
left join [User] T2 on T1.UserId = T2.ID
", (order, user) => {
order.User = user;
return order;
}
);
ts.Dispose();
}
}
public class Order
{
public int ID { get; set; }
public string OrderNo { get; set; }
public User User { get; set; }
}
public class User
{
public int ID { get; set; }
public string Name { get; set; }
} 
支援dynamic Multi Mapping
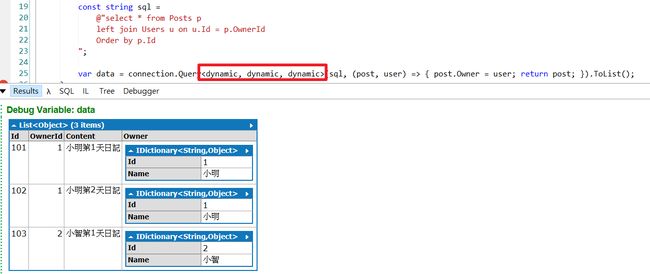
在初期常变动表格结构或是一次性功能不想宣告Class,Dapper Multi Mapping也支援dynamic方式
void Main()
{
using (var ts = new TransactionScope())
using (var connection = Connection)
{
const string createSql = @"
create table Users (Id int, Name nvarchar(20))
create table Posts (Id int, OwnerId int, Content nvarchar(20))
insert Users values(1, N'小明')
insert Users values(2, N'小智')
insert Posts values(101, 1, N'小明第1天日记')
insert Posts values(102, 1, N'小明第2天日记')
insert Posts values(103, 2, N'小智第1天日记')
";
connection.Execute(createSql);
const string sql =
@"select * from Posts p
left join Users u on u.Id = p.OwnerId
Order by p.Id
";
var data = connection.Query(sql, (post, user) => { post.Owner = user; return post; }).ToList();
}
} 
SplitOn区分类别Mapping组别
Split预设是用来切割主键,所以预设切割字串是Id,假如当表格结构PK名称为Id可以省略参数,举例
![]()
var result = cn.Query(@"
select * from [order] T1
left join [User] T2 on T1.UserId = T2.ID
", (order, user) => {
order.User = user;
return order;
}
); 假如主键名称是其他名称,请指定splitOn字串名称,并且对应多个可以使用,做区隔,举例,添加商品表格做Join :
var result = cn.Query(@"
select * from [order] T1
left join [User] T2 on T1.UserId = T2.ID
left join [Item] T3 on T1.ItemId = T3.ID
"
,map : (order, user,item) => {
order.User = user;
order.Item = item;
return order;
}
,splitOn : "Id,Id"
);
14.Query Multi Mapping 底层原理
Multiple Mapping 底层原理
这边先以一个简单Demo带读者了解Dapper Multi Mapping 概念
- 按照泛型类别参数数量建立对应数量的Mapping Func集合
- Mapping Func建立逻辑跟Query Emit IL一样
- 呼叫使用者的Custom Mapping Func,其中参数由前面动态生成的Mapping Func而来
public static class MutipleMappingDemo
{
public static IEnumerable Query(this IDbConnection connection, string sql, Func map)
where T1 : Order, new()
where T2 : User, new() //这两段where单纯为了Demo方便
{
//1. 按照泛型类别参数数量建立对应数量的Mapping Func集合
var deserializers = new List>();
{
//2. Mapping Func建立逻辑跟Query Emit IL一样
deserializers.Add((reader) =>
{
var newObj = new T1();
var value = default(object);
value = reader[0];
newObj.ID = value is DBNull ? 0 : (int)value;
value = reader[1];
newObj.OrderNo = value is DBNull ? null : (string)value;
return newObj;
});
deserializers.Add((reader) =>
{
var newObj = new T2();
var value = default(object);
value = reader[2];
newObj.ID = value is DBNull ? 0 : (int)value;
value = reader[4];
newObj.Name = value is DBNull ? null : (string)value;
return newObj;
});
}
using (var command = connection.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
//3. 呼叫使用者的Custom Mapping Func,其中参数由前面动态生成的Mapping Func而来
yield return map(deserializers[0](reader) as T1, deserializers[1](reader) as T2);
}
}
}
}
} 以上概念就是此方法的主要逻辑,接着讲其他细节部分
支持多组类别 + 强型别返回值
Dapper为了强型别多类别Mapping使用多组泛型参数方法方式,这方式有个小缺点就是没办法动态调整,需要以写死方式来处理。
举例,可以看到图片GenerateMapper方法,依照泛型参数数量,写死强转型逻辑,这也是为何Multiple Query有最大组数限制,只能支持最多6组的原因。
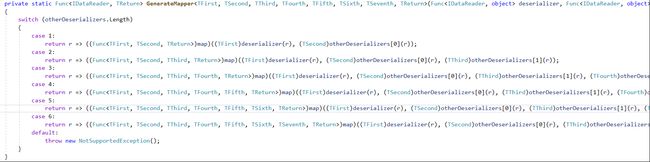
多类别泛型缓存算法
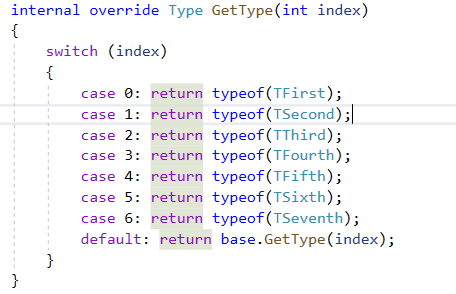
- 这边Dapper使用
泛型类别来强型别保存多类别的资料

- 并配合继承共用Identity大部分身分验证逻辑
- 提供可
override的GetType方法,来客制泛型比较逻辑,避免造成跟Non Multi Query缓存冲突。
Dapper Query Multi Mapping的Select顺序很重要
因为SplitOn分组基础依赖于Select的顺序,所以顺序一错就有可能属性值错乱情况。
举例 : 假如上面例子的SQL改成以下,会发生User的ID变成Order的ID;Order的ID会变成User的ID。
select T2.[ID],T1.[OrderNo],T1.[UserID],T1.[ID],T2.[Name] from [order] T1
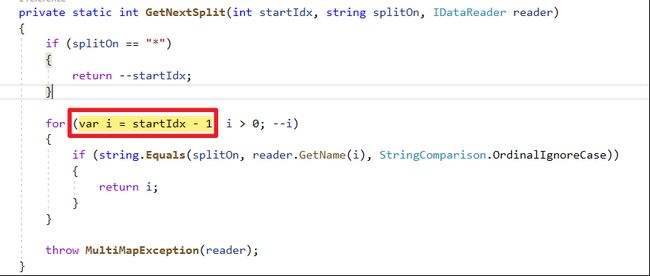
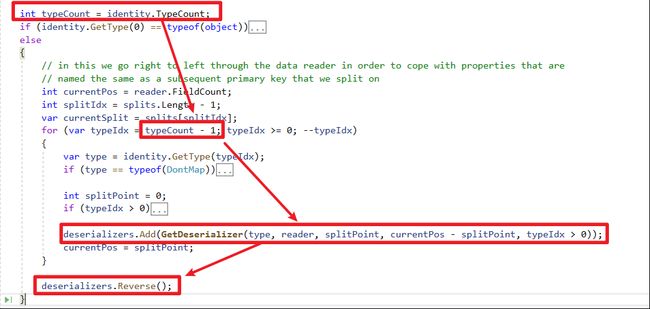
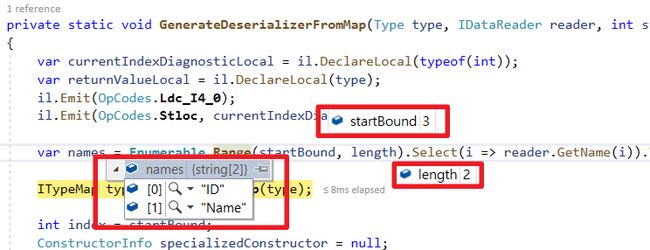
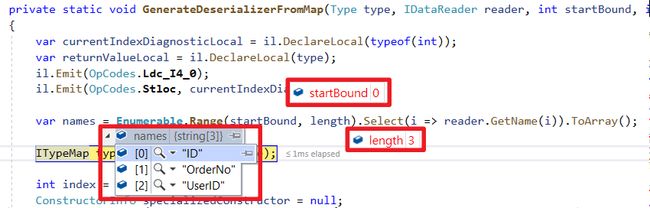
left join [User] T2 on T1.UserId = T2.ID 原因可以追究到Dapper的切割算法
- 首先
倒序方式处理栏位分组(GetNextSplit方法可以看到从DataReader Index大到小查询)
- 接着
倒序方式处理类别的Mapping Emit IL Func - 最后反转为
正序,方便后面Call Func对应泛型使用
15.QueryMultiple 底层原理
使用方式例子 :
using (var cn = Connection)
{
using (var gridReader = cn.QueryMultiple("select 1; select 2;"))
{
Console.WriteLine(gridReader.Read()); //result : 1
Console.WriteLine(gridReader.Read()); //result : 2
}
} 使用QueryMultiple优点 :
- 主要
减少Reqeust次数 - 可以将多个查询
共用同一组Parameter参数
QueryMultiple的底层实作逻辑 :
- 底层技术是ADO.NET - DataReader - MultipleResult
- QueryMultiple取得DataReader并封装进GridReader
- 呼叫Read方法时才会建立Mapping动态方法,Emit IL动作跟Query方法一样
- 接着使用ADO.NET技术呼叫
DataReader NextResult取得下一组查询结果 - 假如
没有下一组查询结果才会将DataReader释放
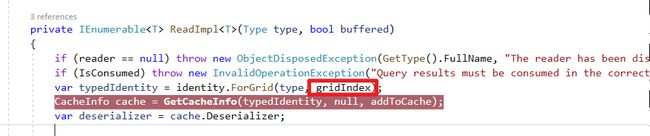
缓存算法
缓存的算法多增加gridIndex判断,主要对每个result mapping动作做一个缓存,Emit IL的逻辑跟Query一样。
没有延迟查询特性
注意Read方法使用的是buffer = true = 返回结果直接ToList保存在内存,所以没有延迟查询特性。

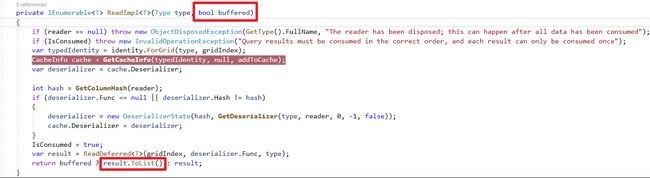
记得管理DataReader的释放
Dapper 呼叫QueryMultiple方法时会将DataReader封装在GridReader物件内,只有当最后一次Read动作后才会回收DataReader
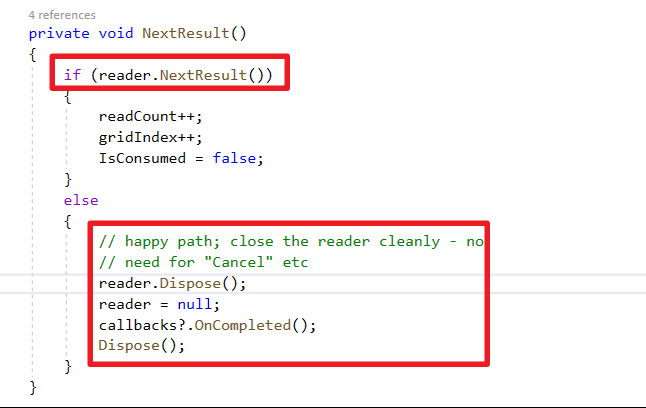
所以没有读取完再开一个GridReader > Read会出现错误:已经开启一个与这个 Command 相关的 DataReader,必须先将它关闭。
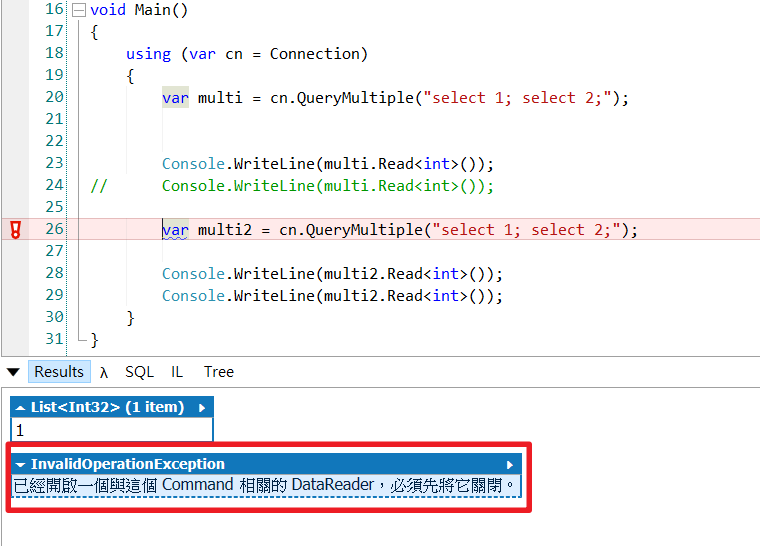
要避免以上情况,可以改成using区块方式,运行完区块代码后就会自动释放DataReader
using (var gridReader = cn.QueryMultiple("select 1; select 2;"))
{
//略..
}闲话 :
感觉Dapper GridReader好像有机会可以实作是否有NextResult方法,这样就可以配合while方法一次读取完多组查询资料,等之后有空来想想有没有机会做成。
概念代码 :
public static class DbExtension
{
public static IEnumerable> GetMultipleResult(this IDbConnection cn,string sql, object paramters)
{
using (var reader = cn.QueryMultiple(sql,paramters))
{
while(reader.NextResult())
{
yield return reader.Read();
}
}
}
}
16.TypeHandler 自订Mapping逻辑使用、底层逻辑
遇到想要客制某些属性Mapping逻辑时,在Dapper可以使用TypeHandler
使用方式 :
- 建立类别继承
SqlMapper.TypeHandler - 将要客制的类别指定给
泛型,e.g :JsonTypeHandler<客制类别> : SqlMapper.TypeHandler<客制类别> 查询的逻辑使用override实作Parse方法,增删改逻辑实作SetValue方法- 假如多个类别Parse、SetValue共用同样逻辑,可以将实作类别改为
泛型方式,客制类别在AddTypeHandler时指定就可以,可以避免建立一堆类别,e.g :JsonTypeHandler: SqlMapper.TypeHandler where T : class
举例 :
想要特定属性成员在数据库保存Json,在AP端自动转成对应Class类别,这时候可以使用SqlMapper.AddTypeHandler<继承实作TypeHandler的类别>。
以下例子是User资料变更时会自动在Log栏位纪录变更动作。
public class JsonTypeHandler : SqlMapper.TypeHandler
where T : class
{
public override T Parse(object value)
{
return JsonConvert.DeserializeObject((string)value);
}
public override void SetValue(IDbDataParameter parameter, T value)
{
parameter.Value = JsonConvert.SerializeObject(value);
}
}
public void Main()
{
SqlMapper.AddTypeHandler(new JsonTypeHandler>());
using (var ts = new TransactionScope())
using (var cn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Integrated Security=SSPI;Initial Catalog=master;"))
{
cn.Execute("create table [User] (Name nvarchar(200),Age int,Level int,Logs nvarchar(max))");
var user = new User()
{
Name = "暐翰",
Age = 26,
Level = 1,
Logs = new List() {
new Log(){Time=DateTime.Now,Remark="CreateUser"}
}
};
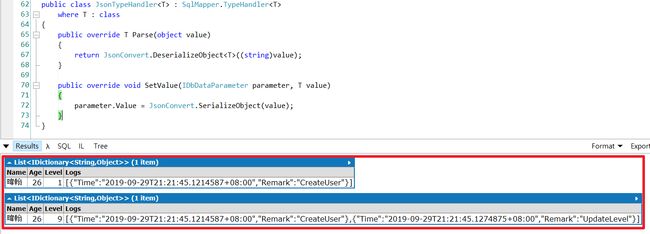
//新增资料
{
cn.Execute("insert into [User] (Name,Age,Level,Logs) values (@Name,@Age,@Level,@Logs);", user);
var result = cn.Query("select * from [User]");
Console.WriteLine(result);
}
//升级Level动作
{
user.Level = 9;
user.Logs.Add(new Log() {Remark="UpdateLevel"});
cn.Execute("update [User] set Level = @Level,Logs = @Logs where Name = @Name", user);
var result = cn.Query("select * from [User]");
Console.WriteLine(result);
}
ts.Dispose();
}
}
public class User
{
public string Name { get; set; }
public int Age { get; set; }
public int Level { get; set; }
public List Logs { get; set; }
}
public class Log
{
public DateTime Time { get; set; } = DateTime.Now;
public string Remark { get; set; }
} 效果图 :
接着追踪TypeHandler源码逻辑,需要分两个部份来追踪 : SetValue,Parse
SetValue底层原理
- AddTypeHandlerImpl方法管理缓存的添加
- 在CreateParamInfoGenerator方法Emit建立动态AddParameter方法时,假如该Mapping类别TypeHandler缓存内有资料,Emit添加呼叫SetValue方法动作。
if (handler != null)
{
il.Emit(OpCodes.Call, typeof(TypeHandlerCache<>).MakeGenericType(prop.PropertyType).GetMethod(nameof(TypeHandlerCache.SetValue))); // stack is now [parameters] [[parameters]] [parameter]
} - 在Runtime呼叫AddParameters方法时会使用LookupDbType,判断是否有自订TypeHandler
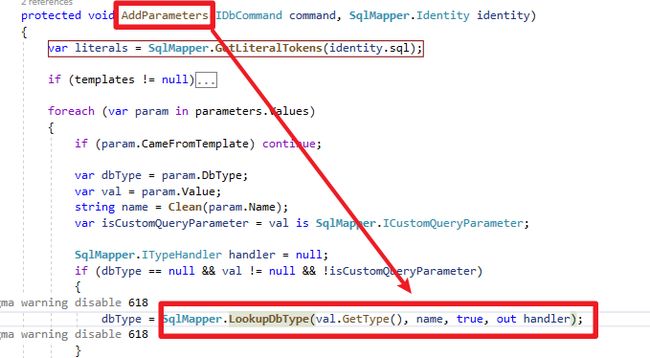
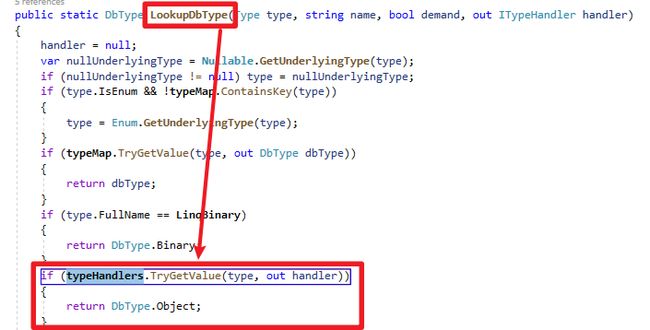
- 接着将建立好的Parameter传给自订TypeHandler.SetValue方法
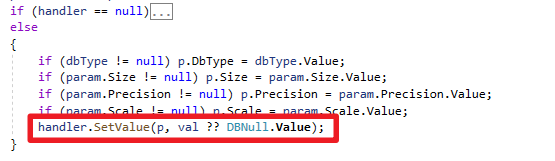
最后查看IL转成的C#代码
public static void TestMeThod(IDbCommand P_0, object P_1)
{
User user = (User)P_1;
IDataParameterCollection parameters = P_0.Parameters;
//略...
IDbDataParameter dbDataParameter3 = P_0.CreateParameter();
dbDataParameter3.ParameterName = "Logs";
dbDataParameter3.Direction = ParameterDirection.Input;
SqlMapper.TypeHandlerCache>.SetValue(dbDataParameter3, ((object)user.Logs) ?? ((object)DBNull.Value));
parameters.Add(dbDataParameter3);
//略...
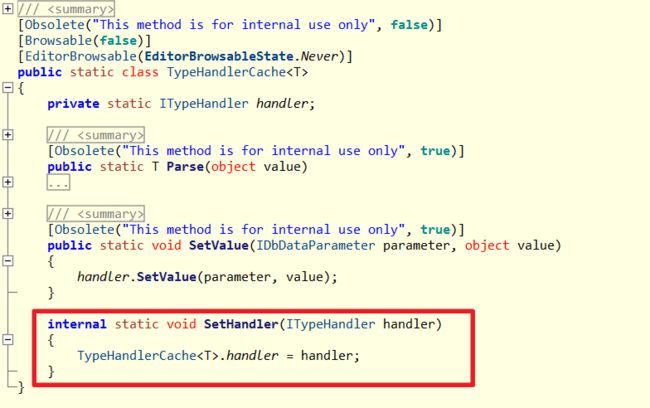
} 可以发现生成的Emit IL会去从TypeHandlerCache取得我们实作的TypeHandler,接着呼叫实作SetValue方法运行设定的逻辑,并且TypeHandlerCache特别使用泛型类别依照不同泛型以Singleton方式保存不同handler,这样有以下优点 :
- 只要传递泛型类别参数就可以取得同一个handler
避免重复建立物件 - 因为是泛型类别,取handler时可以避免了反射动作,
提升效率


Parse对应底层原理
主要逻辑是在GenerateDeserializerFromMap方法Emit建立动态Mapping方法时,假如判断TypeHandler缓存有资料,以Parse方法取代原本的Set属性动作。
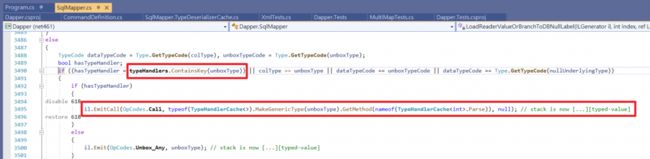
查看动态Mapping方法生成的IL代码 :
IL_0000: ldc.i4.0
IL_0001: stloc.0
IL_0002: newobj Void .ctor()/Demo.User
IL_0007: stloc.1
IL_0008: ldloc.1
IL_0009: dup
IL_000a: ldc.i4.0
IL_000b: stloc.0
IL_000c: ldarg.0
IL_000d: ldc.i4.0
IL_000e: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0013: dup
IL_0014: stloc.2
IL_0015: dup
IL_0016: isinst System.DBNull
IL_001b: brtrue.s IL_0029
IL_001d: unbox.any System.String
IL_0022: callvirt Void set_Name(System.String)/Demo.User
IL_0027: br.s IL_002b
IL_0029: pop
IL_002a: pop
IL_002b: dup
IL_002c: ldc.i4.1
IL_002d: stloc.0
IL_002e: ldarg.0
IL_002f: ldc.i4.1
IL_0030: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0035: dup
IL_0036: stloc.2
IL_0037: dup
IL_0038: isinst System.DBNull
IL_003d: brtrue.s IL_004b
IL_003f: unbox.any System.Int32
IL_0044: callvirt Void set_Age(Int32)/Demo.User
IL_0049: br.s IL_004d
IL_004b: pop
IL_004c: pop
IL_004d: dup
IL_004e: ldc.i4.2
IL_004f: stloc.0
IL_0050: ldarg.0
IL_0051: ldc.i4.2
IL_0052: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0057: dup
IL_0058: stloc.2
IL_0059: dup
IL_005a: isinst System.DBNull
IL_005f: brtrue.s IL_006d
IL_0061: unbox.any System.Int32
IL_0066: callvirt Void set_Level(Int32)/Demo.User
IL_006b: br.s IL_006f
IL_006d: pop
IL_006e: pop
IL_006f: dup
IL_0070: ldc.i4.3
IL_0071: stloc.0
IL_0072: ldarg.0
IL_0073: ldc.i4.3
IL_0074: callvirt System.Object get_Item(Int32)/System.Data.IDataRecord
IL_0079: dup
IL_007a: stloc.2
IL_007b: dup
IL_007c: isinst System.DBNull
IL_0081: brtrue.s IL_008f
IL_0083: call System.Collections.Generic.List`1[Demo.Log] Parse(System.Object)/Dapper.SqlMapper+TypeHandlerCache`1[System.Collections.Generic.List`1[Demo.Log]]
IL_0088: callvirt Void set_Logs(System.Collections.Generic.List`1[Demo.Log])/Demo.User
IL_008d: br.s IL_0091
IL_008f: pop
IL_0090: pop
IL_0091: stloc.1
IL_0092: leave IL_00a4
IL_0097: ldloc.0
IL_0098: ldarg.0
IL_0099: ldloc.2
IL_009a: call Void ThrowDataException(System.Exception, Int32, System.Data.IDataReader, System.Object)/Dapper.SqlMapper
IL_009f: leave IL_00a4
IL_00a4: ldloc.1
IL_00a5: ret 转成C#代码来验证 :
public static User TestMeThod(IDataReader P_0)
{
int index = 0;
User user = new User();
object value = default(object);
try
{
User user2 = user;
index = 0;
object obj = value = P_0[0];
//..略
index = 3;
object obj4 = value = P_0[3];
if (!(obj4 is DBNull))
{
user2.Logs = SqlMapper.TypeHandlerCache>.Parse(obj4);
}
user = user2;
return user;
}
catch (Exception ex)
{
SqlMapper.ThrowDataException(ex, index, P_0, value);
return user;
}
}
17. CommandBehavior的细节处理
这篇将带读者了解Dapper如何在底层利用CommandBehavior优化查询效率,如何选择正确Behavior在特定时机。
我这边整理了各方法对应的Behavior表格 :
| 方法 | Behavior |
|---|---|
| Query | CommandBehavior.SequentialAccess & CommandBehavior.SingleResult |
| QueryFirst | CommandBehavior.SequentialAccess & CommandBehavior.SingleResult & CommandBehavior.SingleRow |
| QueryFirstOrDefault | CommandBehavior.SequentialAccess & CommandBehavior.SingleResult & CommandBehavior.SingleRow |
| QuerySingle | CommandBehavior.SingleResult & CommandBehavior.SequentialAccess |
| QuerySingleOrDefault | CommandBehavior.SingleResult & CommandBehavior.SequentialAccess |
| QueryMultiple | CommandBehavior.SequentialAccess |
SequentialAccess、SingleResult优化逻辑
首先可以看到每个方法都使用CommandBehavior.SequentialAccess,该标签主要功能 使DataReader顺序读取行和列,行和列不缓冲,读取一列后,它会从内存中删除。,有以下优点 :
- 可按顺序分次读取资源,
避免二进制大资源一次性读取到内存,尤其是Blob或是Clob会配合GetBytes 或 GetChars 方法限制缓冲区大小,微软官方也特别标注注意 :

- 实际环境测试,可以
加快查询效率
但它却不是DataReader的预设行为,系统预设是CommandBehavior.Default
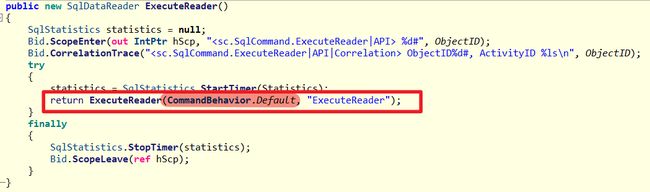
CommandBehavior.Default有着以下特性 :
- 可传回
多个结果集(Multi Result) - 一次性读取行资料到内存
这两个特性跟生产环境情况差满多,毕竟大多时刻是只需要一组结果集配合有限的内存,所以除了SequentialAccess外Dapper还特别在大多方法使用了CommandBehavior.SingleResult,满足只需一组结果就好避免浪费资源。
这段还有一段细节的处理,查看源码可以发现除了标记SingleResult外,Dapper还特别加上一段代码在结尾while (reader.NextResult()){},而不是直接Return(如图片)
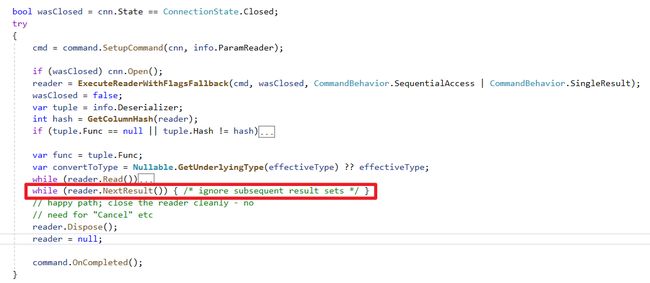
早些前我有特别发Issue(连结#1210)询问过作者,这边是回答 : 主要避免忽略错误,像是在DataReader提早关闭情况
QueryFirst搭配SingleRow,
有时候我们会遇到select top 1知道只会读取一行资料的情况,这时候可以使用QueryFirst。它使用CommandBehavior.SingleRow可以避免浪费资源只读取一行资料。
另外可以发现此段除了while (reader.NextResult()){}外还有while (reader.Read()) {},同样是避免忽略错误,这是一些公司自行土炮ORM会忽略的地方。
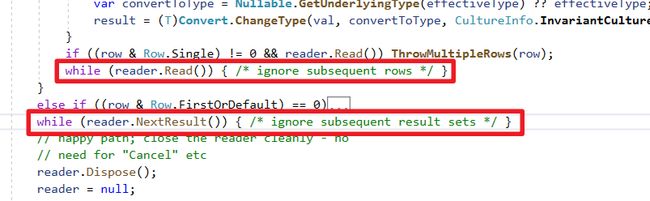
与QuerySingle之间的差别
两者差别在QuerySingle没有使用CommandBehavior.SingleRow,至于为何没有使用,是因为需要有多行资料才能判断是否不符合条件并抛出Exception告知使用者。
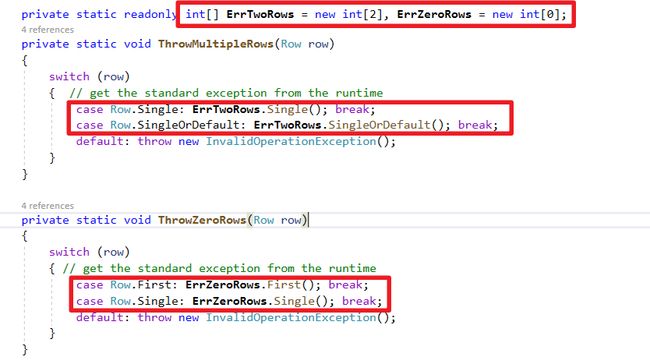
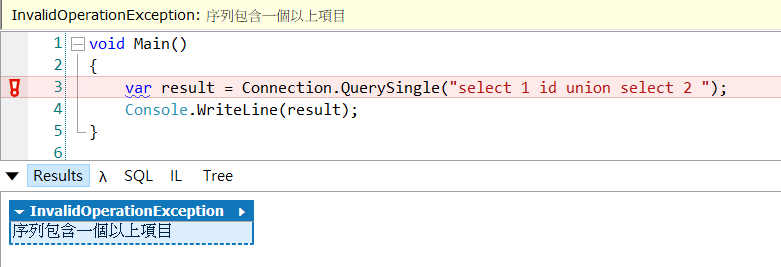
这段有一个特别好玩小技巧可以学,错误处理直接沿用对应LINQ的Exception,举例:超过一行资料错误,使用new int[2].Single(),这样不用另外维护Exceptiono类别,还可以拥有i18N多国语言化。
18.Parameter 参数化底层原理
接着进到Dapper的另一个关键功能 : 「Parameter 参数化」
主要逻辑 :
GetCacheInfo检查是否缓存内有动态方法 > 假如没有缓存,使用CreateParamInfoGenerator方法Emit IL建立AddParameter动态方法 > 建立完后保存在缓存内
接着重点来看CreateParamInfoGenerator方法内的底成逻辑跟「精美细节处理」,使用了结果反推代码方法,忽略「没使用的栏位」不生成对应IL代码,避免资源浪费情况。这也是前面缓存算法要去判断不同SQL字串的原因。
以下是我挑出的源码重点部分 :
internal static Action CreateParamInfoGenerator(Identity identity, bool checkForDuplicates, bool removeUnused, IList literals)
{
//...略
if (filterParams)
{
props = FilterParameters(props, identity.sql);
}
var callOpCode = isStruct ? OpCodes.Call : OpCodes.Callvirt;
foreach (var prop in props)
{
//Emit IL动作
}
//...略
}
private static IEnumerable FilterParameters(IEnumerable parameters, string sql)
{
var list = new List(16);
foreach (var p in parameters)
{
if (Regex.IsMatch(sql, @"[?@:]" + p.Name + @"([^\p{L}\p{N}_]+|$)", RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant))
list.Add(p);
}
return list;
} 接着查看IL来验证,查询代码如下
var result = connection.Query("select @Name name ", new { Name = "暐翰", Age = 26}).First();CreateParamInfoGenerator AddParameter 动态方法IL代码如下 :
IL_0000: ldarg.1
IL_0001: castclass <>f__AnonymousType1`2[System.String,System.Int32]
IL_0006: stloc.0
IL_0007: ldarg.0
IL_0008: callvirt System.Data.IDataParameterCollection get_Parameters()/System.Data.IDbCommand
IL_000d: dup
IL_000e: ldarg.0
IL_000f: callvirt System.Data.IDbDataParameter CreateParameter()/System.Data.IDbCommand
IL_0014: dup
IL_0015: ldstr "Name"
IL_001a: callvirt Void set_ParameterName(System.String)/System.Data.IDataParameter
IL_001f: dup
IL_0020: ldc.i4.s 16
IL_0022: callvirt Void set_DbType(System.Data.DbType)/System.Data.IDataParameter
IL_0027: dup
IL_0028: ldc.i4.1
IL_0029: callvirt Void set_Direction(System.Data.ParameterDirection)/System.Data.IDataParameter
IL_002e: dup
IL_002f: ldloc.0
IL_0030: callvirt System.String get_Name()/<>f__AnonymousType1`2[System.String,System.Int32]
IL_0035: dup
IL_0036: brtrue.s IL_0042
IL_0038: pop
IL_0039: ldsfld System.DBNull Value/System.DBNull
IL_003e: ldc.i4.0
IL_003f: stloc.1
IL_0040: br.s IL_005a
IL_0042: dup
IL_0043: callvirt Int32 get_Length()/System.String
IL_0048: ldc.i4 4000
IL_004d: cgt
IL_004f: brtrue.s IL_0058
IL_0051: ldc.i4 4000
IL_0056: br.s IL_0059
IL_0058: ldc.i4.m1
IL_0059: stloc.1
IL_005a: callvirt Void set_Value(System.Object)/System.Data.IDataParameter
IL_005f: ldloc.1
IL_0060: brfalse.s IL_0069
IL_0062: dup
IL_0063: ldloc.1
IL_0064: callvirt Void set_Size(Int32)/System.Data.IDbDataParameter
IL_0069: callvirt Int32 Add(System.Object)/System.Collections.IList
IL_006e: pop
IL_006f: pop
IL_0070: ret IL转成对应C#代码:
public class TestType
{
public static void TestMeThod(IDataReader P_0, object P_1)
{
var anon = (<>f__AnonymousType1)P_1;
IDataParameterCollection parameters = ((IDbCommand)P_0).Parameters;
IDbDataParameter dbDataParameter = ((IDbCommand)P_0).CreateParameter();
dbDataParameter.ParameterName = "Name";
dbDataParameter.DbType = DbType.String;
dbDataParameter.Direction = ParameterDirection.Input;
object obj = anon.Name;
int num;
if (obj == null)
{
obj = DBNull.Value;
num = 0;
}
else
{
num = ((((string)obj).Length > 4000) ? (-1) : 4000);
}
dbDataParameter.Value = obj;
if (num != 0)
{
dbDataParameter.Size = num;
}
parameters.Add(dbDataParameter);
}
} 可以发现虽然传递Age参数,但是SQL字串没有用到,Dapper不会去生成该栏位的SetParameter动作IL。这个细节处理真的要给Dapper一个赞!
19. IN 多集合参数化底层原理
为何ADO.NET不支援IN 参数化,Dapper支援 ?
原理
- 判断参数的属性是否为IEnumerable类别子类别
- 假如是,以该参数名称为主 + Parameter正则格式找寻SQL内的参数字串 (正则格式 :
([?@:]参数名)(?!\w)(\s+(?i)unknown(?-i))?) - 将找到的字串以
()+ 多个属性名称+流水号方式替换 - 依照流水号顺序依序CreateParameter > SetValue
关键程式部分
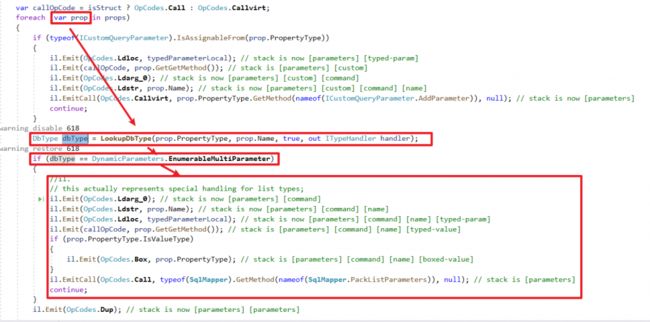
以下用sys.objects来查SQL Server的表格跟视图当追踪例子 :
var result = cn.Query(@"select * from sys.objects where type_desc In @type_descs", new { type_descs = new[] { "USER_TABLE", "VIEW" } });Dapper会将SQL字串改成以下方式执行
select * from sys.objects where type_desc In (@type_descs1,@type_descs2)
-- @type_descs1 = nvarchar(4000) - 'USER_TABLE'
-- @type_descs2 = nvarchar(4000) - 'VIEW'查看Emit IL可以发现跟之前的参数化IL很不一样,非常的简短
IL_0000: ldarg.1
IL_0001: castclass <>f__AnonymousType0`1[System.String[]]
IL_0006: stloc.0
IL_0007: ldarg.0
IL_0008: callvirt System.Data.IDataParameterCollection get_Parameters()/System.Data.IDbCommand
IL_000d: ldarg.0
IL_000e: ldstr "type_descs"
IL_0013: ldloc.0
IL_0014: callvirt System.String[] get_type_descs()/<>f__AnonymousType0`1[System.String[]]
IL_0019: call Void PackListParameters(System.Data.IDbCommand, System.String, System.Object)/Dapper.SqlMapper
IL_001e: pop
IL_001f: ret 转成C#代码来看,会很惊讶地发现:「这段根本不需要使用Emit IL简直多此一举」
public static void TestMeThod(IDbCommand P_0, object P_1)
{
var anon = (<>f__AnonymousType0)P_1;
IDataParameterCollection parameter = P_0.Parameters;
SqlMapper.PackListParameters(P_0, "type_descs", anon.type_descs);
} 没错,是多此一举,甚至IDataParameterCollection parameter = P_0.Parameters;这段代码根本不会用到。
Dapper这边做法是有原因的,因为要能跟非集合参数配合使用,像是前面例子加上找出订单Orders名称的资料逻辑
var result = cn.Query(@"select * from sys.objects where type_desc In @type_descs and name like @name"
, new { type_descs = new[] { "USER_TABLE", "VIEW" }, @name = "order%" });对应生成的IL转换C#代码就会是以下代码,达到能搭配使用目的 :
public static void TestMeThod(IDbCommand P_0, object P_1)
{
<>f__AnonymousType0 val = P_1;
IDataParameterCollection parameters = P_0.Parameters;
SqlMapper.PackListParameters(P_0, "type_descs", val.get_type_descs());
IDbDataParameter dbDataParameter = P_0.CreateParameter();
dbDataParameter.ParameterName = "name";
dbDataParameter.DbType = DbType.String;
dbDataParameter.Direction = ParameterDirection.Input;
object obj = val.get_name();
int num;
if (obj == null)
{
obj = DBNull.Value;
num = 0;
}
else
{
num = ((((string)obj).Length > 4000) ? (-1) : 4000);
}
dbDataParameter.Value = obj;
if (num != 0)
{
dbDataParameter.Size = num;
}
parameters.Add(dbDataParameter);
} 另外为何Dapper这边Emit IL会直接呼叫工具方法PackListParameters,是因为IN的参数化数量是不固定,所以不能由固定结果反推程式码方式动态生成方法。
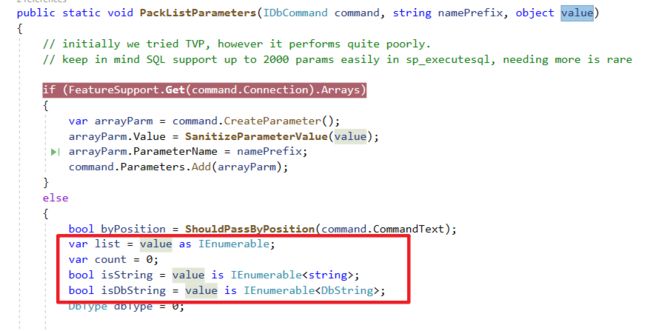
该方法里面包含的主要逻辑:
- 判断集合参数的类型是哪一种 (假如是字串预设使用4000大小)
- 正则判断SQL参数以流水号参数字串取代
- DbCommand的Paramter的创建
SQL参数字串的取代逻辑也写在这边,如图片
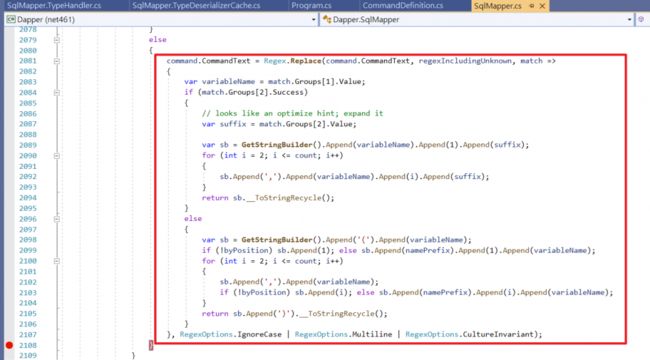
20.DynamicParameter 底层原理、自订实作
这边用个例子带读者了解DynamicParameter原理,举例现在有一段代码如下 :
using (var cn = Connection)
{
var paramter = new { Name = "John", Age = 25 };
var result = cn.Query("select @Name Name,@Age Age", paramter).First();
}前面已经知道String型态Dapper会自动将转成数据库Nvarchar并且长度为4000的参数,数据库实际执行的SQL如下 :
exec sp_executesql N'select @Name Name,@Age Age',N'@Name nvarchar(4000),@Age int',@Name=N'John',@Age=25这是一个方便快速开发的贴心设计,但假如遇到栏位是varchar型态的情况,有可能会因为隐性转型导致索引失效,导致查询效率变低。
这时解决方式可以使用Dapper DynamicParamter指定数据库型态跟大小,达到优化效能目的
using (var cn = Connection)
{
var paramters = new DynamicParameters();
paramters.Add("Name","John",DbType.AnsiString,size:4);
paramters.Add("Age",25,DbType.Int32);
var result = cn.Query("select @Name Name,@Age Age", paramters).First();
}接着往底层来看如何实现,首先关注GetCacheInfo方法,可以看到DynamicParameters建立动态方法方式代码很简单,就只是呼叫AddParameters方法
Action reader;
if (exampleParameters is IDynamicParameters)
{
reader = (cmd, obj) => ((IDynamicParameters)obj).AddParameters(cmd, identity);
} 代码可以这么简单的原因,是Dapper在这边特别使用「依赖于介面」设计,增加程式的弹性,让使用者可以客制自己想要的实作逻辑。这点下面会讲解,首先来看Dapper预设的实作类别DynamicParameters中AddParameters方法的实作逻辑
public class DynamicParameters : SqlMapper.IDynamicParameters, SqlMapper.IParameterLookup, SqlMapper.IParameterCallbacks
{
protected void AddParameters(IDbCommand command, SqlMapper.Identity identity)
{
var literals = SqlMapper.GetLiteralTokens(identity.sql);
foreach (var param in parameters.Values)
{
if (param.CameFromTemplate) continue;
var dbType = param.DbType;
var val = param.Value;
string name = Clean(param.Name);
var isCustomQueryParameter = val is SqlMapper.ICustomQueryParameter;
SqlMapper.ITypeHandler handler = null;
if (dbType == null && val != null && !isCustomQueryParameter)
{
#pragma warning disable 618
dbType = SqlMapper.LookupDbType(val.GetType(), name, true, out handler);
#pragma warning disable 618
}
if (isCustomQueryParameter)
{
((SqlMapper.ICustomQueryParameter)val).AddParameter(command, name);
}
else if (dbType == EnumerableMultiParameter)
{
#pragma warning disable 612, 618
SqlMapper.PackListParameters(command, name, val);
#pragma warning restore 612, 618
}
else
{
bool add = !command.Parameters.Contains(name);
IDbDataParameter p;
if (add)
{
p = command.CreateParameter();
p.ParameterName = name;
}
else
{
p = (IDbDataParameter)command.Parameters[name];
}
p.Direction = param.ParameterDirection;
if (handler == null)
{
#pragma warning disable 0618
p.Value = SqlMapper.SanitizeParameterValue(val);
#pragma warning restore 0618
if (dbType != null && p.DbType != dbType)
{
p.DbType = dbType.Value;
}
var s = val as string;
if (s?.Length <= DbString.DefaultLength)
{
p.Size = DbString.DefaultLength;
}
if (param.Size != null) p.Size = param.Size.Value;
if (param.Precision != null) p.Precision = param.Precision.Value;
if (param.Scale != null) p.Scale = param.Scale.Value;
}
else
{
if (dbType != null) p.DbType = dbType.Value;
if (param.Size != null) p.Size = param.Size.Value;
if (param.Precision != null) p.Precision = param.Precision.Value;
if (param.Scale != null) p.Scale = param.Scale.Value;
handler.SetValue(p, val ?? DBNull.Value);
}
if (add)
{
command.Parameters.Add(p);
}
param.AttachedParam = p;
}
}
// note: most non-priveleged implementations would use: this.ReplaceLiterals(command);
if (literals.Count != 0) SqlMapper.ReplaceLiterals(this, command, literals);
}
}可以发现Dapper在AddParameters为了方便性跟兼容其他功能,像是Literal Replacement、EnumerableMultiParameter功能,做了许多判断跟动作,所以代码量会比以前使用ADO.NET版本多,所以效率也会比较慢。
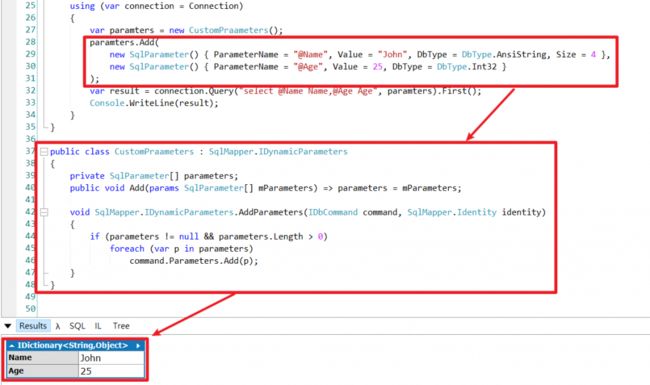
假如有效率苛求的需求,可以自己实作想要的逻辑,因为Dapper此段特别设计成「依赖于介面」,只需要实作IDynamicParameters介面就可以。
以下是我做的一个Demo,可以使用ADO.NET SqlParameter建立参数跟Dapper配合
public class CustomPraameters : SqlMapper.IDynamicParameters
{
private SqlParameter[] parameters;
public void Add(params SqlParameter[] mParameters)
{
parameters = mParameters;
}
void SqlMapper.IDynamicParameters.AddParameters(IDbCommand command, SqlMapper.Identity identity)
{
if (parameters != null && parameters.Length > 0)
foreach (var p in parameters)
command.Parameters.Add(p);
}
}
21. 单次、多次 Execute 底层原理
查询、Mapping、参数讲解完后,接着讲解在增、删、改情况Dapper我们会使用Execute方法,其中Execute Dapper分为单次执行、多次执行。
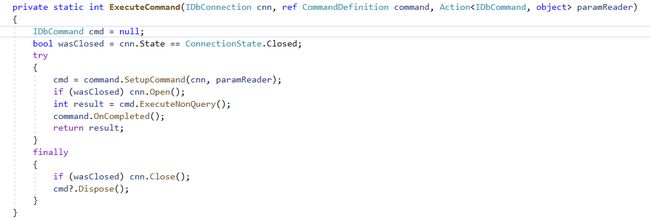
单次Execute
以单次执行来说Dapper Execute底层是ADO.NET的ExecuteNonQuery的封装,封装目的为了跟Dapper的Parameter、缓存功能搭配使用,代码逻辑简洁明了这边就不做多说明,如图片
「多次」Execute
这是Dapper一个特色功能,它简化了集合操作Execute之间的操作,简化了代码,只需要 : connection.Execute("sql",集合参数);。
至于为何可以这么方便,以下是底层的逻辑 :
- 确认是否为集合参数
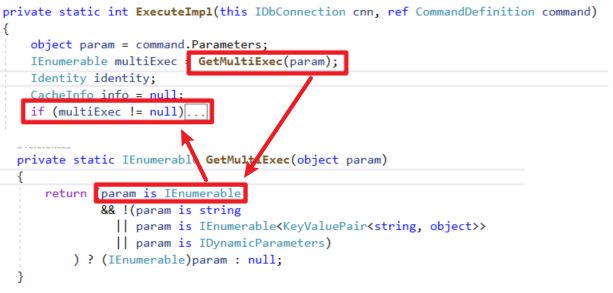
- 建立
一个共同DbCommand提供foreach迭代使用,避免重复建立浪费资源

- 假如是集合参数,建立Emit IL动态方法,并放在缓存内利用
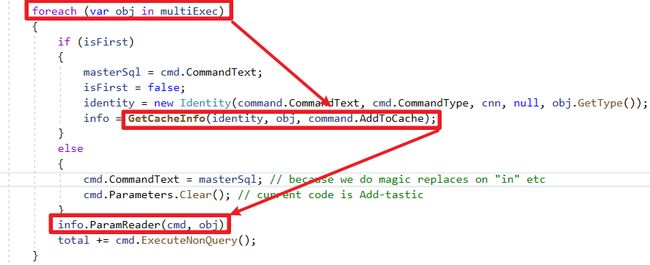
- 动态方法逻辑是
CreateParameter > 对Parameter赋值 > 使用Parameters.Add添加新建的参数,以下是Emit IL转成的C#代码 :
public static void ParamReader(IDbCommand P_0, object P_1)
{
var anon = (<>f__AnonymousType0)P_1;
IDataParameterCollection parameters = P_0.Parameters;
IDbDataParameter dbDataParameter = P_0.CreateParameter();
dbDataParameter.ParameterName = "V";
dbDataParameter.DbType = DbType.Int32;
dbDataParameter.Direction = ParameterDirection.Input;
dbDataParameter.Value = anon.V;
parameters.Add(dbDataParameter);
} foreach该集合参数 > 除了第一次外,每次迭代清空DbCommand的Parameters > 重新呼叫同一个动态方法添加Parameter > 送出SQL查询
实作方式简洁明了,并且细节考虑共用资源避免浪费(e.g共用同一个DbCommand、Func),但遇到大量执行追求效率需求情况,需要特别注意此方法每跑一次对数据库送出一次reqesut,效率会被网路传输拖慢,所以这功能被称为「多次执行」而不是「批量执行」的主要原因。
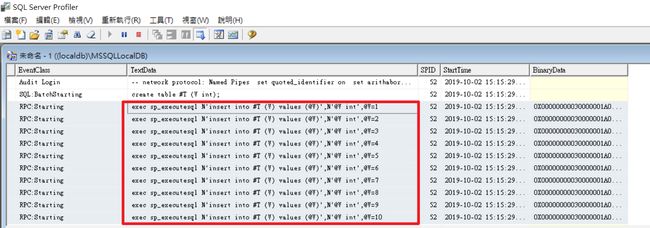
举例,简单Execute插入十笔资料,查看SQL Profiler可以看到系统接到10次Reqeust:
using (var cn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDB;Integrated Security=SSPI;Initial Catalog=Northwind;"))
{
cn.Open();
using (var tx = cn.BeginTransaction())
{
cn.Execute("create table #T (V int);", transaction: tx);
cn.Execute("insert into #T (V) values (@V)", Enumerable.Range(1, 10).Select(val => new { V = val }).ToArray() , transaction:tx);
var result = cn.Query("select * from #T", transaction: tx);
Console.WriteLine(result);
}
}
22. ExecuteScalar应用
ExecuteScalar因为其只能读取第一组结果、第一笔列、第一笔资料特性,是一个常被遗忘的功能,但它在特定需求下还是能派上用场,底下用「查询资料是否存在」例子来做说明。
首先,Entity Framwork如何高效率判断资料是否存在?
假如有EF经验的读者会答使用Any而不是Count() > 1。
使用Count系统会帮转换SQL为 :
SELECT COUNT(*) AS [value] FROM [表格] AS [t0]SQL Count 是一个汇总函数,会迭代符合条件的资料行判断每列该资料是否为null,并返回其行数。
而Any语法转换SQL使用EXISTS,它只在乎是否有没有资料,代表不用检查到每列,只需要其中一笔有资料就有结果,所以效率快。
SELECT
(CASE
WHEN EXISTS(
SELECT NULL AS [EMPTY]
FROM [表格] AS [t0]
) THEN 1
ELSE 0
END) AS [value]Dapper如何做到同样效果?
SQL Server可以使用SQL格式select top 1 1 from [表格] where 条件 搭配 ExecuteScalar 方法,接着在做一个扩充方法,如下 :
public static class DemoExtension
{
public static bool Any(this IDbConnection cn,string sql,object paramter = null)
{
return cn.ExecuteScalar(sql,paramter);
}
} 效果图 :
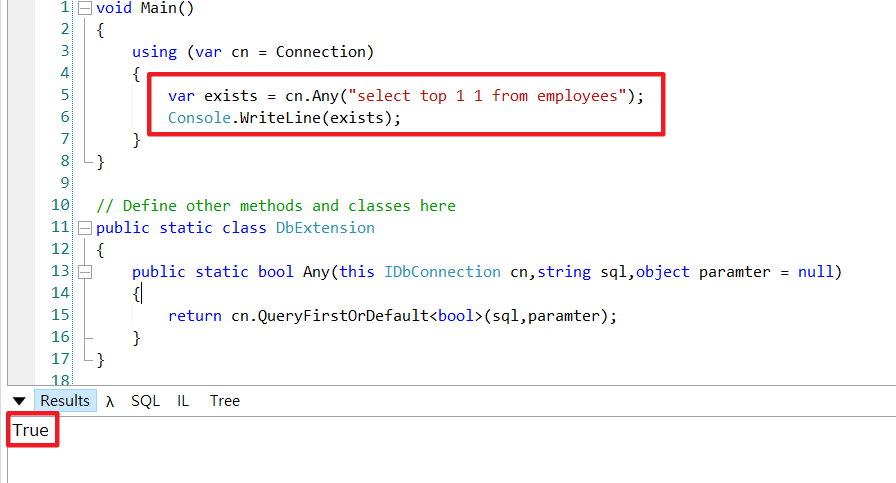
使用如此简单原因,是利用Dapper ExecuteScalar会去呼叫ExecuteScalarImpl其底层Parse逻辑
private static T ExecuteScalarImpl(IDbConnection cnn, ref CommandDefinition command)
{
//..略
object result;
//..略
result = cmd.ExecuteScalar();
//..略
return Parse(result);
}
private static T Parse(object value)
{
if (value == null || value is DBNull) return default(T);
if (value is T) return (T)value;
var type = typeof(T);
//..略
return (T)Convert.ChangeType(value, type, CultureInfo.InvariantCulture);
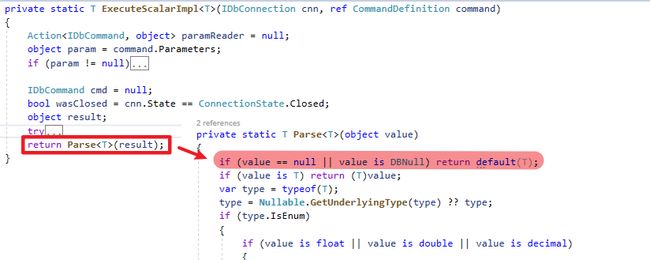
} 使用 Convert.ChangeType 转成 bool : 「0=false,非0=true」 特性,让系统可以简单转型为bool值。
注意
不要QueryFirstOrDefault代替,因为它需要在SQL额外做Null的判断,否则会出现「NullReferenceException」。
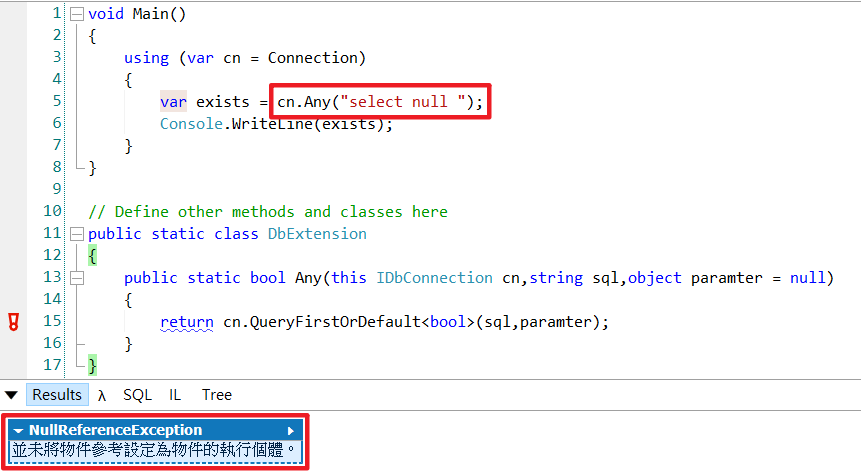
这原因是两者Parse实作方式不一样,QueryFirstOrDefault判断结果为null时直接强转型
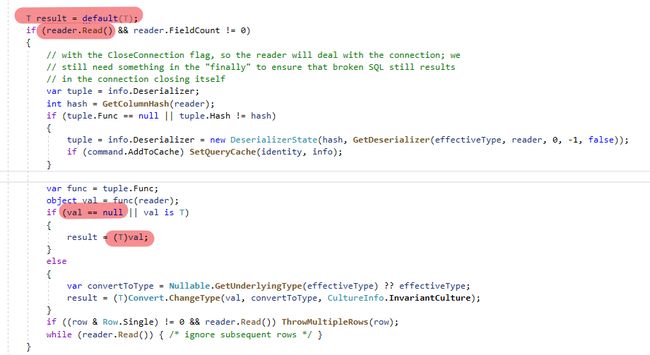
而ExecuteScalar的Parce实作多了为空时使用default值的判断
23.总结
Dapper系列到这边,重要底层原理差不多都讲完了,这系列总共花了笔者连续25天的时间,除了想帮助读者外,最大的收获就是我自己在这期间更了解Dapper底层原理,并且学习Dapper精心的细节、框架处理。
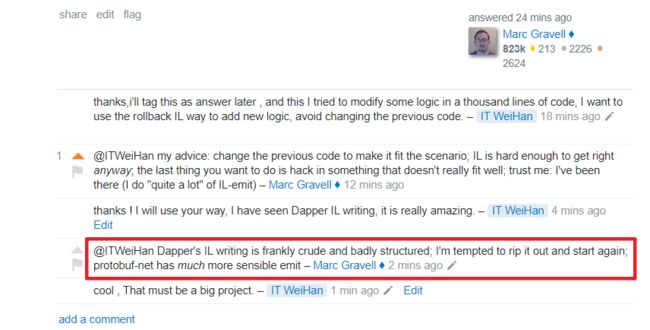
另外想提Dapper作者之一Marc Gravell,真的非常热心,在写文章的期间有几个概念疑问,发issue询问,他都会热心、详细的回覆。并且也发现他对代码的品质要求之高,举例 : 在S.O发问,遇到他在底下留言 : 「他对目前Dapper IL的架构其实是不满意的,甚至觉得粗糙,想搭配protobuf-net技术打掉重写」 (谜之声 : 真令人敬佩 )
连结 : c# - How to remove the last few segments of Emit IL at runtime - Stack Overflow
最后笔者想说 :
写这篇的初衷,是希望本系列可以帮助到读者
- 了解底层逻辑,知其所以然,避免写出吃掉效能的怪兽,更进一步完整的利用Dapper优点开发专案
- 可以轻松面对Dapper的面试,比起一般使用Dapper工程师回答出更深层的概念
- 从最简单Reflection到常用Expression到最细节Emit从头建立Mapping方法,带读者
渐进式了解Dapper底层强型别Mapping逻辑 - 了解动态建立方法的重要概念
「结果反推程式码」 - 有基本IL能力,可以利用IL反推C#代码方式看懂其他专案的底层Emit逻辑
- 了解Dapper因为缓存的算法逻辑,所以
不能使用错误字串拼接SQL
感谢大家阅读到最后,假如喜欢本系列,欢迎留言、交流 :)