原文:协议实验室博客
作者:Juan Benet,Jesse Clayburgh & Matt Zumwalt
译者:外号水虎(转载请附上此信息)
IPFS和Filecoin的团队阐述了如何通过市场激励机制和提高分布式存储技术来搭建更安全高效的网络。
不到三十年互联网已经成为人类历史上最伟大的成就之一,使得科学研究、技术和商业在这段时间获得了前所未有的丰硕成果。这种惊人的成长速度很大一部分归功于技术人员将互联网的大部分复杂内容进行了封装处理(使得大家易于使用)。集中式“云存储”是封装处理中最大的一部分,在云存储中数据被存储在由盈利性机构持有的一个大型的、中心化的仓库中。这种架构使得网络变得脆弱且没有隐私权,存储价格被人为抬高且这样的方式阻碍了对数据使用方式的创新。
网络不需要这种架构,新的技术允许我们通过内容寻址而不是基于位置寻址来改善网络的底层协议提高网络的安全性和健壮性。我们将大大减少对特定的实体的依赖来向我们提供我们所要求的数据。现在,我们不再依靠昂贵的企业来存储和传输人类的知识库,而是通过大规模点对点网络来分发数据,这些节点被付费来存储他人的数据。
分散式存储使网络更健壮和有弹性
今天互联网上的信息按照地址来索引:一段特有的内容有一个URL(统一资源定位符),它关联在特定位置托管内容的服务器的IP地址。例如向URL地址 https://facebook.com/mypicture.jpg请求内容,我们将域名facebook.com转换成为IP地址(假如为31.13.70.36),URL告诉我们要转到31.13.70.36去请求路径中的内容/mypicture.jpg。网址指向的位置是固定的,如果相同的图片托管在另外一个网站上或者你已经存储在本地,你通过这个链接访问图片还是要连接到该URL对应的IP去下载内容。
在日常的人类语境中思考这个问题是很有用的。想象一下我们只能通过书籍和其副本的物理位置来引用书籍,而不是通过作者或ISBN(国际标准书号)。因此如果某人告诉你去阅读一本书他得这么说:“嗨,这本书真棒!你真该读读,就是纽约公共图书馆第九区第三个书柜最顶层的那个书架从左数第一本。”现在你需要去那儿检查一下,然后才可以得到一份拷贝。在你去那里之前,你不知道它实际上是什么,你只知道它的位置。这显然是非常低效的。这也是一种不稳定的情况——如果有人移动了这本书怎么办?如果那天图书馆闭馆怎么办?或者图书馆彻底停业了怎么办?或者假使你到了第三个书柜,最顶层的那个书架,拿到了从左边数第一本书,而就在这时你意识到其实你的背包里就有一本同样的书,那又怎么办?
这不仅仅是一个理论情景问题,哈佛最近的一项研究发现,在美国最高法院意见书中有49%引用的超链接不在有效。法院意见书指向的地址在过去的一段时间内有正确的内容,但是现在那个位置的内容已经失效了。用这种方式索引书籍是脆弱、低效、不必要的,这太疯狂了。
相反,我们应该考虑一种不同的方式,考虑“是什么”来定位信息,而不是“在哪里”。要做到这一点,我们需要使用一种不同的网络链接。我们不需要使用指向位置的链接,而是需要可以唯一描述内容本身的链接,就想指纹一样。这种内容寻址方式将“什么”和“哪里”分隔开,这样数据就能通过网络进行传输,因此就可以在任何地方为任何人所存储和服务。为了创建这些内容寻址链接,我们使用内容的加密哈希作为唯一的标识符或指纹。
星际域名文件系统是一种协议,它允许我们使用内容寻址的链接来交换数据。在IPFS中,文件或数据的哈希指纹就是它的地址,我们使用这些指纹来识别内容而不是使用服务器的物理位置。这样,当你试图加载一个文件时,你可以从任何位置检索它。如果文件已经在你的计算机上,你可以从那里检索它。如果你在网络中的直接邻居有这个文件,你可以从他们那里检索到。你可能从原始服务器,从网络中的其他人,或者任何人那里获取它。IPFS可以使用高效路由选择算法来搜索网络,并且它可以为隐私进行调整:例如只向你信任的节点请求数据。这类似于其他P2P系统所做的事,但却被极大地拓展了。你可以使用它来与任意数量的节点交换任何类型的文件或数据,并直接构建到网络中。
IPFS通过基于“是什么”而不是“在哪里”来寻址信息,使得网络去中心化。这种去中心化的模式运行在本地网络工作的网络应用程序脱离原始来源,它可以是一个失去上行链路的办公室的聊天室,一本在各种图书馆都保存的科学期刊,一个网络较差的偏远村庄的维基百科,或者是一场危机中的家庭对话短信。它加强了我们的数字信息,使得数据能够适应底层互联网的故障,并以密码学来保护它,让它永久存在。你,或是那些分享你的数据的人可以保存信息的副本,并且数年都在相同的链接上,IPFS允许网络上的文件存储去中心化,但是第二个问题仍然存在:我们如才能创建一个开放而有竞争力的市场来提供存储?
云存储和中心化的危险
云数据存储自成立以来已经发展得很实用,但留下很多经济和安全上的问题没有解决。为了理解为什么目前云存储是昂贵且不稳定的,我们从时间轴上来检查它的演变是有用的。
最早的网站和在线服务运行在他们自己的网络服务器:专门为用户提供内容的计算机和硬盘。在一个咋险业务可以注册他们的第一个客户或者销售他们的第一个产品之前,他们必须投入大量的资金和时间来建立服务器基础设施。即使他们的产品或者服务与计算和数据存储完全不相关,但实际上每个人都被迫投资和运行自己的硬件,只是为了在网络上露一面。这非常昂贵且浪费资源。
在2006年亚马逊解决了这一浪费的开销,并大胆推出了Amazon Web Services(AWS)。AWS通过把亚马逊自己的服务器和存储空间出租给其他人,从而消除了开发者创建和管理自己的服务器基础设施的需要。现在,公司可以很实惠的价格在亚马逊上存储和服务他们的文件,如此一来,这家公司就不需要再自行购买硬件,AWS很快就获得了成功,其他几家大型技术公司也纷纷效仿,创建了自己的云存储解决方案。
云存储使得新的在线业务能够在一夜之间迅速增长,并能迅速满足用户需要。不需要购置新的硬盘也不需要在自己的小型数据中心安装它们,云计算能让业务仅仅通过几次键盘敲击就立马扩大规模。在短短几年内,云计算变得如此有用和流行,以至于大多数数据都存储在这寥寥几个云数据提供商中。即使现在大多数网站都是由第三方提供的,但对于终端用户来说,这一基础设施仍然是不可见的。例如,你是否知道现在很流行的电影流媒体应用Netflix实际上是用AWS来满足他们的大部分托管需求?尽管亚马逊有自己的竞争对手电影流媒体服务(Amazon Prime),但他们还是很乐意把托管空间卖给竞争对手。
目前,构建一个成功的云数据存储时非常负载和具有挑战性的。甚至开始于现有企业竞争,新公司需要在各大洲建立一个全球性的数据中心网络(这个市场中大多数玩家在会有多个数据中心),构建满足多数用户需求的稳健的用户见面,发展全球销售和营销团队来吸引用户,并雇佣大客户售后团队。这些巨大的进入壁垒导致了极少数的大公司拥有几乎所有的全球云存储市场。这种集团化尤其令人痛苦,原因有很多:用户必须信任这些大公司会保护他们的数据,切换云存储供应商的成本特别高,数据的存储距离用户非常遥远(通常在数百到千英里之外),以及供应商被鼓励去锁定他们的客户,从此获得溢价。目前的云存储市场并不像他所能达到的那样具有竞争力和高效率,终端用户也因此收到影响。
更令人沮丧的是,世界上存在着大量未使用的“潜在”(可用的)存储。这种存储是由各种实体所拥有的:大道大型企业,小到家族生意,大到放在地下室的巨大硬盘架,小到每个人的笔记本电脑上都有的小型硬盘。然而由于前面提到的竞争壁垒,任何一家公司和个人都很难讲他们的额外空间变现,并启动云数据服务。一个更有效的市场会将原始硬盘驱动空间与其他服务支持(如客户服务、用户界面、报酬和价格协商等)分离。这将使得硬盘提供商能够多元化动态市场上专注于硬件,并在一个存储市场竞争,这将极大地降低云储存的价格,并允许现有容量广泛地变现。它将使云存储变得更像一种商品或一种工具,你依据市场价格按需购买,而不像一种服务关系(它充满了合约、谈判、交易和锁定成本)。但问题是,我们如何才能建立一个真正的去中心化存储生态系统?内容寻址可以由IPFS来解决,但我们要如何才能鼓励世界各地的人们成为存储的主干呢?Filecoin。
Filecoin:为网络付费存储你的数据
虽然IPFS让我们直接与节点交换数据,而不用依赖于集中式主机,但Filecoin又更进一步,给我们提供了一种方式来为存储数据彼此付费。Filecoin是一个分布式文件存储网络和协议代币(代币可以与APPcoin和加密货币互换)。可以把它想象成数据存储的Airbnb。在供应方面,即代币挖矿方面,拥有未使用的存储空间的个人和组织可以将他们的磁盘添加到Filecoin网络中,并接收客户订单。在需求方面,客户——个人和组织雇佣Filecoin网络来存储他们的数据,而这些数据会被发送到网络世界各地的许多不同的矿工。
Filecoin 吸收了加密货币和区块链技术的前沿进展使这个圣杯成为可能。它使用了区块链、一个原生的加密货币、公开可验证的存储证明、附加抵押品的存储合约、确保有效定价的算法市场、支持小额支付和降低交易成本的支付渠道等等。所有这些因素加载一起,形成了一个强大的、分散的自我修复网络,可以将全世界的“矿工”的大量存储集中在一起,并提供强大的可用性,弹性和价格的保证。它可以自动调整自身以满足需求,保护内容免受攻击,并从矿工的脱机状态中恢复。
世界上数千个实体和数百万人拥有大量未使用的存储空间。通过将所有潜在的供应品带入市场,Filecoin可能会导致在线存储的价格大幅下降。此外,Filecoin启动了强大的优化过程,使比特币汇聚了大量的计算能力。通过向网络添加越来越多的存储,Filecoin矿工可以赚到很多钱。
IPFS和Filecoin不需要一起使用,但两者是绝妙的组合,可以解决当前WEB的重大缺陷。目前IPFS的用户需要“钉住”他们的数据(存储和服务),这些数据可以来自他们自己的计算机也可以来自其他主动承担该内容的IPFS用户。Filecoin能为任何IPFS用户提供激励机制,以确保他们的数据存储在许多去中心化节点上。很快,任何人都可以在Filecoin中支付大量的去中心化存储提供商,以稳定地存储他们的文件,确保他们的数据能够安全快速地送达那些需要数据的人。用户在IPFS和Filecoin的文件中存储文件,将受益于优化的存储成本、多样性的存储提供商、更快捷的数据服务、自动化的自我修复以及巨大的规模经济。
在去中心化网络中保护隐私和尊严
在由IPFS和Filecoin驱动的网络上存储私有数据,这就意味着一部分数据可能分布在许多计算机上,而这些计算机可能是由完全陌生的人操作。然而,就保护隐私而言,这比现有的云系统显然更好。如今,大量的云存储服务供应商,无论大小,都是将他们用户的数据全部用普通文字未加密储存。即使是一些添加了闲时加密功能的人,也是通过控制用户加密密钥的方式来实现这一点,而不是创建真正的“遗忘”或“零知识”系统。这是一种危险的安排,因为这意味着客户的数据可能被黑客或其他攻击者窃取、泄露或出售。用户(或他们使用的应用程序)应该在把数据给这些云存储提供商之前,对数据进行端到端地加密,无论是否是集中式。
虽然将用户数据分配给不属于某个公司或服务的大批存储计算机,可能增加数据的曝光,然而,如果有价值的数据以端到端加密形式存储,那么访问加密文本的攻击者就无法了解其中的内容。无论存储网络是大型云服务提供商还是像Filecoin这样的激励市场,都是如此。这是一个不一样的安全模型,在这个模型中,我们总是被强制加密所有东西,并且只有用户才有权使用密钥,而单个云供应商的故障不会损害数据的弹性。
市场协议:利用网络和激励机制来建立更好的行业
在协议实验室,我们相信市场协议——由协议代币驱动的去中心化网络——会是下一波互联网创新浪潮。我们相信这些技术有潜力重塑我们在全球范围内组织商业和交易价值的方式。这在一定程度上是因为市场协议在激励机制、参与者和网络创造价值的能力之间呈现出一种全新的动态。在当前的互联网创新模式中,当一家公司创造网络经济时,他们就占据了大部分的网络价值。虽然数百万人在网络上创造价值,但这些参与者可能并不会从网络本身获得利益。少数富有的投资者和早期股东获取了大部分的长期价值。相比之下,市场协议是由协议代币驱动的,协议代币是网络整体价值的一个百分比。参与市场协议的补偿是网络的分红,这种补偿随着网络的价值而增大和缩小。
例如,Airbnb和Uber都是创造网络经济的企业。他们通过服务费补贴服务提供者(Airbnb的房东和Uber的司机),而不是他们网络所创造的整体财富的分红。这就保证了一小部分的股东得到了很大的回报,而那些帮助这个网络创造价值的人(司机、房东、用户)却不能公平地分享这些好处。
像Filecoin这样的网络则体现了一种替代性方案,即创建网络价值的参与者在网络中获得了利益补偿。在Filecoin网络中,存储和分发数据的矿工可获得Filecoin协议代币,他们可以选择持有或变现。由于Filecoin协议代币的目的是跟踪存储网络创造的价值的数量,因此Filecoin经济的发展将转化为代币价值的增长。那些选择持有代币的矿工和用户将分享到这一好处——因为创造价值而获得公平的回报。每个参与者赚取和持有的代币越多,他们就越有动力去支持网络并保证其成功。这种激励联盟和反馈环路会形成一个非常强大的参与者协作网络,他们将从网络的成功中获益。
市场协议目前仍然处于发展早期阶段,但它们的前景非常光明。我们很高兴能站在这些技术进展的最前沿,这些技术进展使互联网及其数据网络更加安全、稳健、快速。就像网络创造了巨大的连接和释放人类潜能一样,我们相信下一波市场协议的浪潮也会对未来产生同样的影响。
Juan、Jesse和Matt工作于协议实验室,这是一个致力于构建协议、系统和改进互联网工具的研究、开发和部署实验室。协议实验室开发了IPFS、Filecoin、CoinList和许多其他互联网技术。
感谢Peter Van Valkenburgh阅读这篇文章的草稿。
原文
The team behind IPFS and Filecoin explain how advances in distributed data storage and strong alignment of market incentives are combining to create a much more secure and efficient web.
In the span of less than three decades the web has become one of the greatest achievements in human history, responsible for never before seen gains in science, technology, and commerce. This amazing growth has been driven in large part by technologists abstracting away much of the underlying complexity of the internet. One of the biggest of these abstractions has been centralized ‘cloud storage’ where data is stored in large, centralized silos owned and run largely by for-profit corporations. This architecture makes the web brittle, undermines privacy, allows the price of storage to remain artificially high, and creates bottlenecks that prevent innovative new uses of data.
The web need not be structured this way. Emerging new technologies are allowing us to improve the web’s underlying protocols by addressing content by what it is rather than addressing it by where it is. This makes the web a much safer and robust place, where we’re far less reliant on any one particular entity to give us the data we request. Now instead of relying on expensive businesses to store and transmit humanity’s trove of knowledge we can distribute data across a vast network of peers who are paid to store each other’s data.
Decentralized Storage makes the web robust and resilient
Today, information on the internet is addressed by location: a particular piece of content has a URL—a Universal Resource Locator—that involves the IP Address of a web server that hosts the content at a specific location. For example, to go to a URL like https://facebook.com/mypicture.jpg, we resolve the domain name (facebook.com) into an IP Address (eg 31.13.70.36) and look up the picture there. The URL is saying “go to 31.13.70.36 and request the content at the path “/mypicture.jpg”. The URL always points to that location. If the same picture was hosted on another site, or even your own computer, you would still have to connect to that IP Address and download the content.
It’s useful to think about this in everyday human context. Imagine that we could only reference books by the physical location of a copy, not by title, or author, or ISBN – only the location of the physical object. So if someone told you to read a book, they’d say something like “Hey, you should read this great book, it’s at the New York Public Library, section 9, bookcase 3, top shelf, first from the left”. And now you have to check there, and get that one physical copy. Until you do, you don’t know what book it actually is; you only have the location. This is obviously terribly inefficient. It’s also a precarious situation—what if someone moved the book? What if the library is closed that day? Or totally shut down? Or, what if you get there, you get to Bookcase 3, top shelf, first from the left, and you realize, this whole time, you had another copy of that same book in your backpack.
This isn’t just a theoretical concern. A recent Harvard-led study found that 49% of all hyperlinks cited in US Supreme Court opinions are no longer working. The opinions point to locations that held the correct content at some time in the past, but the content is no longer available at that location. This is brittle, inefficient, and unnecessary. This is madness.
Instead, consider a different way. Consider addressing information by what it is, not where it is. To do this we need to use a different kind of web link. Instead of using links that point to locations, we need links that uniquely describe the content itself, like a fingerprint. This content-addressed approach separates “what” from “where”, so data can flow through the network, so it can be stored and served from anywhere by anyone. To create these content-addressed links, we use the content’s cryptographic hash as the unique identifier or fingerprint.
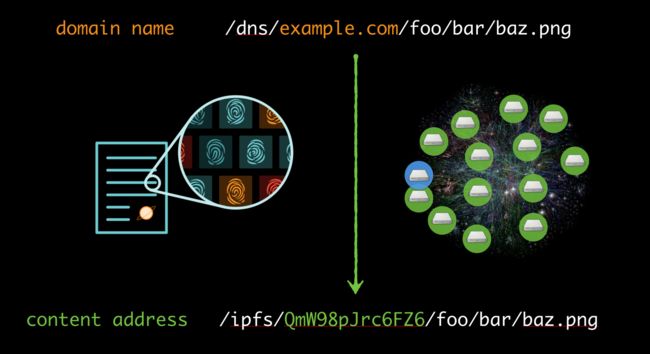
IPFS, the InterPlanetary File System, is a protocol that lets us use those content-addressed links to exchange data. In IPFS, the hash fingerprint of a file or a piece of data is its address. We use these fingerprints to identify the content instead of using the physical location of the server. This way, when you are trying to load a file, you retrieve it from any place you can. If the file is already on your own computer you could retrieve it from there. If your direct neighbors in the network have the file you could retrieve it from them. You might get it from the original server, from others in the network, whomever. IPFS handles this all for you using efficient routing algorithms to search the network, and it can be tuned for privacy: e.g. only request data from peers you trust. This is similar to what other peer-to-peer systems do, but greatly amplified. You can use it to exchange any kind of files or data with any number of peers and it’s built directly into the web.
IPFS decentralizes the web by addressing information based on what it is, not where it is. This decentralized pattern lets web applications work in local networks disconnected from the original source, whether it is a chat room in an office that lost its uplink, a scientific paper hosted in a variety of libraries, Wikipedia in a remote village with poor connectivity, or a family’s chat messenger during a crisis. It strengthens our digital information, making the data resilient to failures in the underlying internet, securing it cryptographically, and giving it permanence through time. You or the people whom you’ve shared your data with can save copies of information and count on the same links for years. IPFS allows file storage on the web to be decentralized, but a second question remains: how can we create an open, competitive market for providing that storage?
Cloud Storage and the dangers of centralization
Since its inception cloud data storage has evolved to be functional, but leaves many economic and security concerns unaddressed. In order to understand why cloud storage is currently expensive and precarious it’s useful to examine its evolution over time.
The earliest websites and online services ran their own web servers: computers and hard-drives dedicated to serving content to their users. Before an online business could sign-up their first customer or sell their first product, they’d have to invest formidable sums of money and time in setting up server infrastructure. Even if the product or service was completely unrelated to computing and data storage virtually everyone was forced to invest and run their own hardware just to have a web-presence. This was expensive, wasteful, and time-consuming.
In 2006, Amazon.com addressed this wasteful overhead, and boldly launched Amazon Web Services (AWS). AWS removed the need for developers to create and manage their own server infrastructure by renting out Amazon’s own servers and storage space to others. Now for a modest fee a company could easily store and serve their files from Amazon, negating the need for that company to buy their own hardware. AWS became a quick hit and several other large technology firms followed suit in creating their own ‘cloud’ based storage solutions.
Cloud storage allowed new online businesses to spring up overnight and grow to match user demand quickly. Instead of ordering new hard-drives and installing them in their own small data-centers, cloud computing allowed businesses to scale up at a moment’s notice with a few keyboard strokes. In just a few years cloud computing became so useful and popular that the majority of all data became stored in just a few of these cloud data-providers. This infrastructure is still largely invisible to the end-user, even though most websites today are hosted by these 3rd party providers. For example, did you know that Netflix, the popular movie streaming app, actually uses AWS for much of their hosting needs? Even though Amazon has its own rival movie streaming service (Amazon Prime) they’re also happy to sell hosting space to a competitor.
Currently, building a successful cloud data storage business is extraordinarily complex and challenging. Even to begin to be competitive with incumbents a company would need to build a global network of data-centers in every continent (most players in this market have multiple datacenters per continent), build out robust user interfaces that satisfy many user demands, grow global sales and marketing teams to attract customers, and hire large customer support teams. These tremendous barriers to entry have resulted in just a few massive corporations owning nearly all of the global cloud data storage market. This consolidation is especially painful for a number of reasons: users must trust these large corporate actors to protect their data from exposure, the cost of switching cloud providers is especially high, data is stored very far from the end-user (usually hundreds to thousands of miles away), and providers are incentivized to lock in their customers and extract a premium. The current market for cloud storage is not nearly as competitive or efficient as it could be and end-users suffer because of it.
Even more frustrating, there exists a significant amount of ‘latent’ (available) storage throughout the world that sits unused. This storage is owned by all kinds of entities: large corporations down to small family businesses, individuals with huge hard-drive racks in their basements to small drives in everyone’s laptop. However, due to the aforementioned barriers to entry it would be difficult for any one particular company or individual to monetize their extra space and start a cloud data service. A much more efficient market would decouple raw hard-drive space, e.g. the storage, from all the services and support on-top, e.g. the customer service, user interface, payments and price negotiation, etc.. This would allow for a diverse and dynamic market of hard-drive providers to focus only on hardware and compete in a proper market for storage itself, which would greatly reduce the price of cloud storage and allow vast monetization of existing capacity. It would make cloud storage more like a commodity or a utility that you buy as you need at the going market rate and less like a service relationship fraught with contracting, negotiation, transaction, and lock-in costs. But the question remains, how can we build a true decentralized storage ecosystem? Content addressing is solved by IPFS, but how can we encourage people all over the world to become the backbone of storage itself? Enter Filecoin.

Filecoin: Paying the network to store your data
While IPFS lets us exchange data directly with our peers instead of relying on centralized hosts, Filecoin takes it a step further by giving us a way to pay each other for storing data. Filecoin is a decentralized file storage network and protocol token (‘token’ is used interchangeably with ‘appcoin’ and ‘cryptocurrency’). Think of it like the AirBnB data storage. On the supply side — the mining side of the token — individuals and organizations with unused storage space can add their disks to the Filecoin Network and receive client orders. On the demand side — the clients — individuals and organizations hire the Filecoin Network to store their data, which gets routed to many different miners worldwide.
Filecoin draws from cutting-edge advances in cryptography and blockchain technologies to make this holy grail a reality. It uses: a blockchain, a native cryptocurrency, publicly verifiable proofs-of-storage, storage contracts with collaterals, algorithmic markets to ensure efficient pricing, payment channels to enable micropayments and reduce transaction costs, and more. All this adds up to a powerful, decentralized, self-healing network that can bring together massive amounts of storage from “miners” all over the world, and provide a great service with strong guarantees of availability, resilience, and great price. It can automatically rebalance itself to meet demand, protects content from attack, and recovers from miners going offline.
The world has a gargantuan amount of unused storage across thousands of entities and millions of people. By bringing all that latent supply into the market, Filecoin might cause the price of online storage to drop significantly. Moreover, Filecoin kicks off the powerful optimization process that made Bitcoin amass enormous quantities of computing power. Filecoin miners can make a lot of money by adding more and more storage to the network.
Users aren’t required to use Filecoin and IPFS together, but the two combined are a perfect pair that solve significant failings of the current web. Users currently using IPFS are required to ‘pin’ (store & serve) their data from either their own computer, an existing centralized cloud provider, or off the generosity of other IPFS users who actively choose to host that content. Filecoin provides the incentive for any IPFS user to assure their data is stored across a host of decentralized nodes. Soon anyone will be able to pay a large mass of decentralized storage providers in filecoin to robustly store their files, assuring their data can be securely and quickly served to those that request it. Users storing files on IPFS and Filecoin will benefit from optimized storage costs, a diversity of storage providers, much faster serving of data, automated self-healing, and tremendous economies of scale.

Protecting Privacy and Decency on the Decentralized Web
Storing private data on a network powered by IPFS and Filecoin means that parts of the data may be distributed across many computers operated by complete strangers; remarkably, however, this can be better for privacy than existing cloud systems. Today, a large variety of cloud storage providers, big and small, store their users’ data entirely in the clear—unencrypted. Even some who have added encryption-at-rest, have done so by controlling their users’ encryption keys, instead of creating truly “oblivious” or “zero-knowledge” systems. This is a dangerous arrangement because it means that customer data can be stolen and leaked or sold by hackers or other attackers. Users (or the applications they use) should encrypt their data end-to-end before giving it to these cloud storage providers, whether centralized or not.
Distributing user data to a large array of storage computers who are not owned by one company or service can increase the exposure of the data. However, if valuable data is stored end-to-end encrypted, then attackers with access to the encrypted texts cannot learn what is inside them. This is true whether the storage network is a big cloud provider or an incentive market like Filecoin. This is a different security model, where we are forced to always encrypt everything, with only user access to the keys, and where the failures of a single cloud provider cannot harm the resilience of the data.

Market Protocols: Harnessing networks and incentives to create better industries
At Protocol Labs, we believe that Market Protocols——decentralized networks that are powered by protocol tokens—are the next wave of internet innovation. We believe these technologies have the potential to reshape how we organize commerce and transact value world-wide. This is partially because Market Protocols present a completely new dynamic between incentives, participants, and a network’s ability to create value. In the current model of internet innovation, when a company creates a network economy they capture the majority of the network’s value. Though millions of people participate in creating value on the network, those participants are likely not earning a stake in the network itself. The majority of long-term value is awarded to a small number of wealthy investors and early-shareholders. By contrast, Market Protocols are fueled by protocol tokens, which are a percentage of the network’s overall value. The compensation for participating in a Market Protocol is a stake in the network, which grows and shrinks with the value of that network.
For instance, Airbnb and Uber are companies that have built network economies. They compensate service providers (Airbnb hosts and Uber drivers) with service fees, not a share of the overall wealth created by their networks. This ensures that a small number of shareholders are greatly rewarded while the people who helped the network create value (drivers, homeowners, users) may not share fairly in that upside.
Networks like Filecoin embody an alternative where participants who create the network’s value are compensated with a stake in the network. Miners who store and distribute data on the Filecoin network earn the Filecoin protocol tokens, which they can choose to hold or liquidate to cash. Since Filecoin protocol tokens are designed to track the amount of value created by the storage network, growth in the Filecoin economy will translate to growth in the value of the token. Miners and users who choose to hold the token will share in that upside, earning fair rewards for the creation of value. The more tokens any individual participant earns and holds, the more incentive they have to support the network and ensure its success. This incentive alignment and feedback loop causes an extremely strong network of collaborating participants who will all greatly benefit from the success of the network.
Market Protocols are still in their early stages of development and their promise is great. We’re excited to be on the forefront of these technological advancements that are making the internet and its web of data more secure, robust, and fast. Just as the web has created massive connectivity and unlocked human potential, we think the next wave of Market Protocols will do the same for the future.
Originally published as a Plain Language Explainer at Coin Center, June 20, 2017. Thanks to Peter Van Valkenburgh for reading drafts of this.