MySQL密码
1.Mysql 5.6初次安装完的默认密码存放于 /root/.mysql_secret
2.SET PASSWORD = PASSWORD('XXXXXX');
3.将root对应的密码全部修改为新密码:
use mysql
update user set password = password('XXXXXX') where User='root';
4.更改mysql用户密码
set password for 'root'@'localhost'=password('新密码');
5.忘记root密码:
vim /etc/my.cnf
添加skip-grant-tables
重启mysql新建数据库
create database quants_db default character set utf8 collate utf8_general_ci;
查看数据库信息
show create database quants_db\G
导入数据库
mysql -uroot -p --default-character-set=utf8 quants_db < quants_db.sql
删除数据库
drop database database_name;
查看当前系统数据库
mysql --version-
数据库存储引擎
1.show engines;
查看系统所支持的引擎类型。
show variables like 'storage_engine';
修改默认存储引擎:
[mysqld]
default_storage_engine=InnoDB/MyISAM
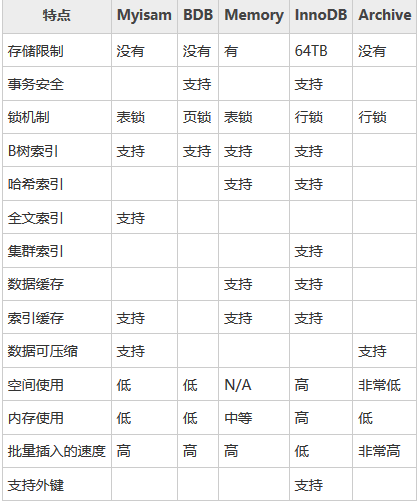 存储引擎比较.png
存储引擎比较.png Myisam是Mysql的默认存储引擎。当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。每个MyISAM在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是.frm(存储表定义)、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。数据文件和索引文件可以放置在不同的目录,平均分布io,获得更快的速度。
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比Myisam的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
常用存储引擎的适用环境:
MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一;如果数据表主要用来插入和查询记录,则myisam引擎能提供较高的处理效率。
InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务兼容支持;需要具有提交、回滚和崩溃恢复能力的事务安全的功能,并要求实现并发控制。
Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问;如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性可以选择将数据保存在内存中,mysql使用该引擎作为临时表,存放查询的中间结果。
Archive:如果只有INSERT和SELECT操作,可以选择Archive存储引擎支持高并发的插入操作,但是本身并不是事务安全的;非常适合存储归档数据,如记录日志信息可以使用Archive引擎。创建表的语法形式
use database_name;
create table table_name(字段名1 数据类型 [列级别约束条件] [默认值], 字段名2 数据类型 [列级别约束条件] [默认值], .....);
create tabletb_emp3(idint(11),namevarchar(25),salaryfloat);
show tables;
show create tables\G使用主键约束
主键约束(Primary Key Constraint)要求主键列数据唯一,并且不允许为空。
主键能够唯一的标识表中的一条记录,可以结合外键来定义不同数据表之间的关系,并且加快数据库查询的速度。
主键和记录之间的关系如同身份证和人之间的关系,一一对应。
主键分为两种类型:单字段主键和多字段联合主键。1.单字段主键
(1)在定义列的同时指定主键:
字段名 数据类型 PRIMARY KEY [默认值]
create table tb_emp2(id int(11) PRIMARY KEY, name varchar(25),salary float);
int后面的数值定义数值的显示宽度
(2)在定义完所有列之后指定主键:
[CONSTARINT <约束名>] PRIMARY KEY [字段名]
create table tb_emp3(id int(11), name varchar(25),salary float, PRIMARY KEY(id));2.多字段联合主键
(1)表中没有主键id,确定一个员工:
create table tb_emp4(name varchar(25), salary float, age int, PRIMARY KEY(name,age));使用外键约束
外键用来在两个表的数据之间建立连接,它可以是一列或者多列;一个表可以有一个或者多个外键;外键对应的是参照完整性,一个表的外键可以为控制,若不为控制,则每一个外键值必须等于另一个表中主键的某个值。
外键: 首先它是表中的一个字段,它可以不是本表的主键,但对应另外一个表的主键。 外键重要作用是保持数据的一致性、完整性。
主表(附表):相关联字段中主键所在的表为主表。
从表(子表):相关联字段中外键所在的表为从表。创建外键的语法:
[CONSTRAINT <外键名>] FOREIGN KEY 字段名1 [,字段名2,...] REFERENCES <主表名> 主键列1 [,主键列2,...]
定义数据表tb_emp5,让他的键deptld作为外键关联到tb_dept1的主键id:
create table tb_dept1(id INT(11) PRIMARY KEY, name VARCHAR(22) NOT NULL, location VARCHAR(50));
create table tb_emp5(id INT(11) PRIMARY KEY, name VARCHAR(25), deptld INT(11), salary float, CONSTRAINT fk_emp_dept1 FOREIGN KEY(deptld) REFERENCES tb_dept1(id));
在表中添加名称为fk_emp_dept1的外键约束,外键名称为deptld,其依赖于表tb_dept1的主键id。 关联字段的数据类型必须匹配。
使用非空约束 NOT NULL
非空约束指字段的值不能为空。
定义tb_emp6,指定员工的名称不能为空:
create table tb_emp6(id int(11) PRIMARY KEY, name varchar(25) NOT NULL, deptld int(11), salary float, CONSTRAINT fk_emp_dept2 FOREIGN KEY(deptld) REFERENCES tb_dept(id));使用唯一性约束 UNIQUE
唯一性约束要求该列唯一,允许且只能出现一个空值;可以确保一列或几列不出现重复值。
1.在定义完列之后直接指定唯一约束,语法:
字段名 数据类型 UNIQUE
定义数据表tb_dept2,指定部门的名称唯一:
create table tb_dept2(id int(11) PRIMARY KEY, name varchar(22) UNIQUE, location varchar(50));
2.在定义完所有列之后指定唯一约束,语法:
[CONSTRAINT <约束名>] UNIQUE(<字段名>)
create table tb_dept3(id int(11) PRIMARY KEY , name varchar(22), location varchar(50), CONSTRAINT fk_name UNIQUE(name));
UNIQUE和PRIMARY KEY的区别:一个表中可以有多个字段声明为UNIQUE,但只能有一个PRIMARY KEY声明;声明为PRIMARY KEY的列不允许为空值。
使用默认约束 DEFAULT
默认约束 指定某列的默认值,若记录该字段没有赋值,则会自动被赋值为默认值。
create table tb_emp7(id int(11) PRIMARY KEY, name varchar(22) NOT NULL, deptld INT(11) default 1234, salary float);设置表的属性值自动增加 AUTO_INCREMENT
通过为表主键添加AUTO_INCREMENT关键字来实现。默认的在MySQL中AUTO_INCREMENT的初始值是1,增加一条记录字段值加1。一个表只有一个字段可用该关键字。AUTO_INCREMENT约束的字段可以是任何整数类型。
语法:
字段名 数据类型 AUTO_INCREMENT
定义tb_emp8,指定员工编号自动递增:
create table tb_emp8(id int(11) PRIMARY KEY AUTO_INCREMENT, name varchar(25) NOT NULL, deptld int(11), CONSTRAINT fk_emp_dept5 FOREIGN KEY (deptld) REFERENCES tb_dept(id));
insert into tb_emp8(name, salary) values('lucy',100), ('lura',200), ('kevin',300);

- 4.2查看数据表结构
(1)DESCRIBE/DESC 表名;


NULL:表示该列是否可以存储NULL值;
KEY:表示该列是否已编制索引。PRI表示该列是表主键一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次;
Default:表示该列是否有默认值,如果有的话值是多少;
Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT;
(2)查看表详细结果语句 SHOW CREATE TABLE 表名\G;

- 4.3 修改数据表 ALTER TABLE
修改表指的是修改数据库中已经存在的数据表的结构。 - 4.3.1 修改表名
ALTER TABLE <旧表名> RENAME [TO] <新表名>;
其中TO为可选参数,使用与否均不影响结果。
ALTER TABLE tb_dept3 RENAME tb_deptment3;
修改表名称前后表结构不变。 - 4.3.2 修改字段的数据类型
ALTER TABLE <表名> MODIFY <字段名> <数据类型>;
ALTER TABLE tb_dept1 MODIFY name VARCHAR(30);

4.3.3 修改字段名
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型>;
如果不需要修改字段的数据类型,可以将新数据类型设置成与原来一样,但数据类型不能为空。
ALTER TABLE te_dept1 CHANGE location loc VARCHAR(50);
技巧:CHANGE也可以只修改数据类型。
提示:当数据表中已有数据记录时,不要轻易修改数据类型。由于不同类型的数据在机器中存储的方式及长度并不相同,修改数据类型可能会影响到数据表中已有的数据记录。4.3.4 添加字段
ALTER TBALE <表名> ADD <新字段名> <数据类型> [约束条件] [FIRST | AFTER 已存在字段名];
"FIRST" 可选参数,将新添加的字段设置为表的第一个字段;"AFTER" 可选参数,将新添加的字段添加到指定的"已存在字段名"后面。
默认将新添加列设置为数据表的最后列。
(1) 添加无完整性约束条件的字段
在tb_dept1中添加一个没有完整性约束的INT类型的字段managerId:
ALTER TBALE tb_dept1 ADD managerId INT(10);
(2) 添加有完整性约束条件的字段
在tb_dept1中添加一个不能为空的VARCHAR(12)类型的字段column1:
ALTER TABLE tb_dept1 ADD column1 VARCHAR(12) NOT NULL;
(3) 在表中的第一列添加一个字段
ALTER TABLE tb_dept1 ADD column2 INT(11) FIRST;
(4) 在表的指定列之后添加一个字段
在tb_dept1的name列后添加一个INT的column3:
ALTER TABLE tb_dept1 ADD column3 INT(11) AFTER name;4.3.5 删除字段
ALTER TABLE <表名> DROP <字段名>
ALTER TABLE tb_dept1 DROP column2;4.3.6 修改字段的排列位置
ALTER TABLE <表名> MODIFY <字段1> <数据类型> FIRST | AFTER <字段2>;
ALTER TABLE tb_dept1 MODIFY column1 VARCHAR(12) FIRST;
ALTER TABLE tb_dept1 MODIFY column1 VARCHAR(12) AFTER location;4.3.7 更改表的存储引擎
ALTER TABLE <表名> ENGINE=<更改后的存储引擎名>;
ALTER TABLE tb_deptment3 ENGINE=MyISAM;4.3.8 删除表的外键约束
外键一旦删除,就会解除主表和从表间的关联关系。
ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>;
ALTER TABLE tb_emp9 DROP FOREIGN KEY fk_emp_dept;4.4 删除数据表
删除操作前,最好想好是否需要对表做个备份。修改表之前也要做备份。4.4.1 删除没有被关联的表
DROP TBALE [IF EXISTS] 表1, 表2,...;
DROP TABLE IF EXISTS tb_dept2;
参数if exists,用于再删除表前判断表是否存在,加上该参数,如果表不存在,sql语句可以顺利执行,但会发出warning。

4.4.2 删除被其他表关联的主表
将关联的表的外键约束条件取消,再删除父表。
ALTER TABLE tb_emp DROP PRIMARY KEY fk_emp_dept;
DROP TABLE tb_dept2;4.5 综合
create database company;
create table offices2(officeCode INT(10) NOT NULL UNIQUE, city INT(11) NOT NULL, address VARCHAR(50), country VARCHAR(50) NOT NULL, postalCode VARCHAR(25) UNIQUE, PRIMARY KEY(officeCode));
create table employees(employeeNumber INT(11) NOT NULL PRIMARY KEY AUTO_INCREMENT, lastName VARCHAR(50) NOT NULL, officeCode INT(10) NOT NULL, CONSTRAINT fk_offices FOREIGN KEY(officeCode) REFERENCES offices2(officeCode));5 数据类型和运算符
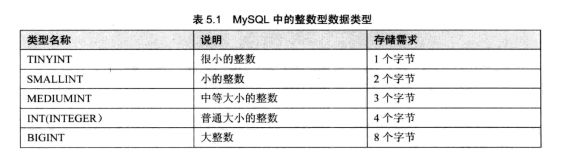
显示宽度只用于显示,并不能限制取值范围和占用空间。
- 5.1.2 浮点数类型FLOAT/DOUBLE和定点数DECIMAL类型

MySQL中使用浮点数和定点数来表示小数。
浮点类型:单精度浮点类型(FLOAT)、双精度浮点类型(DOUBLE)。
定点类型只有一种:DECIMAL,以字符串形式存储,在对精度要求比较高的时候(货币,科学数据)使用DECIMAL较好。
浮点、定点类型都可以用(M,N)来表示,其中M称为精度,表示总共的位数;N成为标度,是表示小数的位数。
FLOAT/DOUBLE 在不指定精度时,默认会按照实际的精度(由计算机硬件和操作系统决定),DECIMAL如不指定精度默认为(10,0)。
另外两个浮点数进行比较运算时也容易出问题,所以使用浮点型时要注意,避免做浮点数比较。
- 5.1.3 日期与时间类型
UTC就是格林尼治,也就是伦敦本地时间。
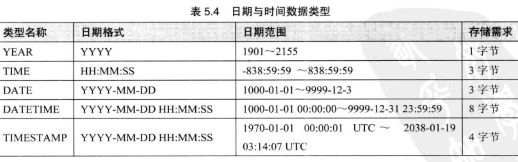
- 1.YEAR
create table tmp3(y YEAR);
insert into tmp3 values(2010),('2010'),('2166');
2166超出2155,出入结果发生变化,最总结果存储了数据0000;
删除表中的数据:
delete from tmp3;
insert into tmp3 values('0'),('00'),('77'),('10');
结果:2000,2000,1977,2010('0'与'00'作用一样)

- 2.TIME

在使用 'D HH' 小时一定要使用双位数值,如果小于10,应在前面加0。
不合法的被转换为00:00:00 存储。
没有某号('1112'和1112表示 00:11:12),
使用某号('11:12'表示 11:12:00)

- 3.DATE



- 4.DATETIME



- 5.TIMESTAMP

'97@03@0303@03@03@03'转换成'1997-03-03 03:03:03'
TIMESTAMP存储时对当前时区进行转换,检索时在转换为当前时区。即查询时,更具当前时区的不同,显示的时间值是不同的。

设置当前时区为东10区:
set time_zone='+10:00';
- 5.1.4 字符串类型

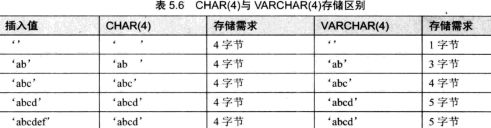
- 1.CHAR/VARCHAR类型
create table tmp8(ch CHAR(4), vch VARCHAR(4));
INSERT INTO tmp8 values('ab ','ab ');
concat拼接字符串:
select concat('(',ch,')'), concat('(',vch,')') from tmp8;
- 2.TEXT类型

- 3.ENUM类型
语法:
字段名 ENUM('值1','值2',...)
create table tmp9(enm ENUM('first','second','third'));
insert into tmp9 values('first'),('second'),('third');
insert into tmp9 values(1),(2),(3);

MySQL的ENUM中从1开始,不是从0开始。
4.SET类型
语法:
SET('值1', '值2', ...)
create table tmp11 (s SET('a','b','c','d'));
insert into tmp11 values('a'),('c,a,d'),('a,x,b,y');
查看警告信息:
show warnings;5.1.5 二进制类型
5.2 选择数据类型
- CHAR与 VARCHAR
CHAR 是固定长度字符,VARCHAR是可变长度字符;CHAR会自动删除插入数据为部的空格,VARCHAR不会。
CHAR是固定长度,所以处理速度比VARCHAR的速度要快,但是缺点就是浪费存储空间。
对于MyISAM,最好使用固定长度的数据列代替可变长度的数据列,这样可以使整个表静态化,从而使数据检索更快,用空间换时间。
对弈InnoDB,使用varchar,因为InnoDB数据表的存储格式不分固定长度和可变长度,所以char不一定比varchar更好,用varchar更节省空间。
2.ENUM和SET
ENUM只能取单值。在多个值中选取一个时,可以使用ENUM,比如性别。
SET可取多指。最多允许有64个成员。空字符串也是合法的SET值。需要取多个值的时候,适合使用SET,比如兴趣爱好。
ENUM和SET的值是以字符串形式出现的,但在内部,MySQL以数值的形式存储它们。
3.BLOB和TEXT
BLOB:二进制字符串;TEXT:非二进制字符串。两者均可存放大容量的信息。BLOB主要存储图片、音频信息;而TEXT只能存储纯文本文件。
- 5.3常见运算符
- 5.3.1




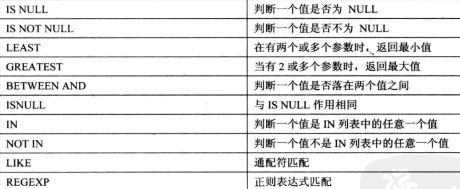
安全等于运算符:<=>
<=> / = 区别:<=> 可以用来对NULL进行判断,两者都为NULL返回值为1.
不等于运算符<> / !=



当参数为字符串时,返回字母表中顺序最靠前的字符(不区分大小写);当比较值列表中有NULL时,不能判断大小,返回值为NULL.
lower_case_name_tables=1 让mysql不区分大小写。

- REGEXP 正则表达式语法:expr REGEXP 匹配条件

- 5.3.4 逻辑运算符


a XOR b 等同于 (a AND (NOT B)) 或者 ((NOT a) AND b)

-
- MySQL函数
- 6.2.1 绝对值函数ABS(x) 和 返回圆周率的函数PI()


- 6.2.2 平方根函数 SQRT(x) 和 求余函数 MOD(x, y)


- 6.2.3 获取整数的函数CEIL(x)、CEILING(X)和FLOOR(x)
CEIL(x)和CEILING(x)意义相同,返回不小于x的最小整数值,返回值转化为一个BIGINT。

FLOOR(x) 返回不大于x的最大整数值,返回值转化为一个BIGINT。

-
6.2.4 获取随机数函数RAND() 和 RAND(x)
RAND(x)返回一个随机浮点值,范围[0,1];
不带参数的RAND()每次产生的随机数是不同的:
 RAND()
RAND()
当RAND(x)的参数相同时,将产生相同的随机数,不同的x产生的随机数不同。
6.2.5 四舍五入函数ROUND(x)/ROUND(x,y)和TRUCATE(x,y)
ROUND(x)返回最接近于参数x的整数,对x值进行四舍五入。

ROUND(x,y)返回四舍五入后最接近参数x的数,值保留到小数点后面y位;若y为负值,则四舍五入后将保留x值到小数点左边y位。


- 6.2.6 符号函数 SIGN(x)
SIGN(x)返回参数的符号,x的值为负、零或正时返回结果:-1、 0 或1.

- 6.2.7 幂运算函数POW(x,y)、 POWER(x,y) 和EXP(x)


......
- 6.3 字符串函数
- 6.3.1 计算字符串字符数的函数和字符串长度的函数


- 6.3.2 合并字符串函数CONCAT(s1,s2,...)/CONCAT_WS(x,s1,s2,...)


- 6.3.3 替换字符串函数 INSERT(s1,x,len,s2)
用s2在s1的第x位置替换len长度的字符,如果x超过字符串长度,则返回s1,len大于其他字符串长度,则从x开始替换,任何一个参数为NULL,返回值就为NULL.

- 6.3.4 字母大小写转换函数LOWER(str)、LCASE(str)/UPPER(x)、UCASE(str)


- 6.3.5 获取指定长度的字符串的函数LEFT(s,n)和RIGHT(s,n)


- 6.3.6 填充字符串的函数LPAD(s1,len,s2)和RPAD(s1,len,s2)


- 6.3.7 删除空格的函数LTRIM(s)、RTRIM(s)和TRIM(s)



- 6.3.8 删除指定字符串的函数TRIM(s1 FROM s)
TRIM(s1 FROM s)删除s中两端所有的子字符串s1,s1在未指定情况下,默认删除空格。

- 6.3.11 比较字符串大小的函数 STRCMP(s1,s2)
s1,s2相同则返回0,s1小于s2则返回-1,其他情况返回1.

- 6.3.12 获取子串的函数SUBSTRING(s,n,len) 和 MID(s,n,len)作用相同

- 6.4.1 CURDATE() 和 CURRENT_DATE()作用相同,将当前日期按照'YYYY-MM-DD'/YYYYMMDD格式的值返回。

- 6.4.1 CURTIME() 和 CURRENT_TIME()作用相同,将当前时间以'HH:MM:SS'/HHMMSS格式返回。
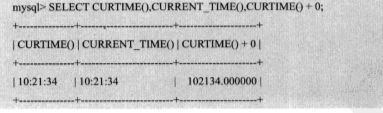
- 获取当前日期和时间函数
CURRENT_TIMESTAMP()/LOCALTIME()/NOW()/SYSDATE()作用相同,格式'YYYY-MM-DD HH:MM:SS' / YYYYMMDDHHMMSS

- UNIX 时间戳函数











- 将日期和时间格式化函数 DATE_FORMAT(date,format)
-
SELECT DATE_FORMAT('1997-10-20 22:22:22','%Y %b %d %T');
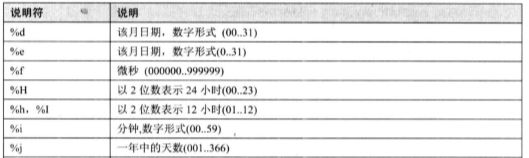
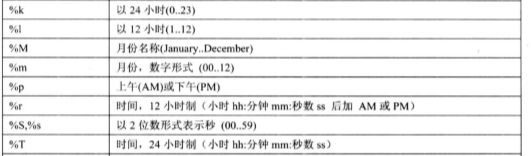
 时间日期格式
时间日期格式



SEC_TO_TIME(time)秒钟转为时间
- 条件判断函数
- 6.5.1 IF(expr,v1,v2)

-IFNULL(v1,v2)






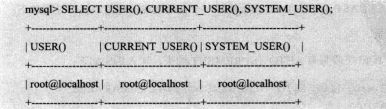
- 6.7加密函数
PASSWORD(str)


- 6.7.3加密函数ENCODE(str,pswd_str) 解密函数DECODE(crypt_str,pswd_str)





- 加锁解锁函数



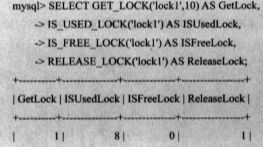

BENCHMARK报告的时间是客户端经过的时间,而不是在服务器端的cpu时间,每次执行后报告的时间并不一定是相同的。


提示:
查看字符集:show variables like 'character_set_%';
character_set_client、character_set_connection和character_set_results的字符集修改:my.cnf:
[mysqld]
init_connect='SET NAMES gbk'
character_set_client=gbk
7 查询数据
7.2.6 带LIKE的字符匹配查询
'%' '' : % 是能匹配多个字符; 只能匹配任意一个字符。
SELECT id,name from fruits where name like '__y';
一个字符一个(下划线)7.2.7 查询空值
SELECT id,name from customers where name IS NULL;
查询非空记录:NOT IS NULLIN / NOT IN
查询结果不重复
SELECT DISTINCT 字段名 FROM 表名;ORDER BY 字段名 ASC(默认升序) DESC(降序)
-
多列排序
SELECT name,price FROM fruits ORDER BY name,price;
先按price降序,再按name升序:
SELECT name,price FROM fruits ORDER BY price DESC,name;
 提示:多列排序时,若第一列无不同的值,该列值都为唯一时,将不再对第二列进行排序
提示:多列排序时,若第一列无不同的值,该列值都为唯一时,将不再对第二列进行排序 7.2.12 分组查询
语法:
[GROUP BY 字段名] [HAVING<条件表达式>]
GROUP BY 关键字通常和集合函数一起使用(MAX()/MIN()/COUNT()/SUM()/AVG())


- 使用HAVING过滤分组
GROUP BY 可以和HAVING 一起限定显示记录所需满足的条件,只有满足条件的分组才会被显示。
SELECT id,GROUP_CONCAT(name) AS Names FROM fruits GROUP BY id HAVING COUNT(name) > 1;

提示:HAVING与WHERE区别:HAVING在数据分组之后进行过滤来分组,而WHERE在分组之前用来选择记录,另外WHERE排除的记录不再包括在分组中。
- 在GROUP BY字句中使用WITH ROLLUP

多字段分组:
SELECT * FROM fruits GROUP BY name,id;
进行从左到右的层次分组,在第一个字段值相同的记录中,再根据第2个字段的值进行分组,依次类推。


- 7.2.13 使用LIMIT限制查询结果的数量


- 7.3 使用集合函数查询
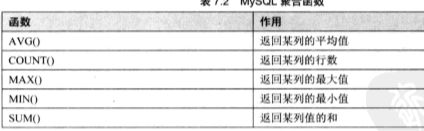

计算每个分组中的最大(最小)的值:MAX()/MIN()
SELECT id,MAX(price) FROM fruits GROUP BY id;
- 7.4 连接查询

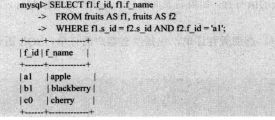
- 7.4.1内连接(INNER JOIN)
自连接---特殊的内连接:
- 7.4.2 外连接查询
外连接包含左外连接LEFT JOIN:返回左表的所有数据和右表的连接字段相等的记录。
右外连接RIGHT JOIN:返回右表的所有数据和右表的连接字段相等的记录。


- 7.4.3 复合条件连接查询


- 7.5 子查询
子查询中常用的操作符:ANY(SOME)/ALL/IN/EXISTS - 7.5.1 带ANY/SOME 关键字的子查询

- 7.5.2 带ALL关键字的子查询

- 7.5.3 带EXISTS关键字的子查询



- 7.6 合并查询结果
UNION(返回的结果是唯一的,去重的) / UNION ALL(返回所有记录,不去重)


- 7.7 区别名 AS
- 7.8 使用正则表达式查询:字段名 REGEXP '';
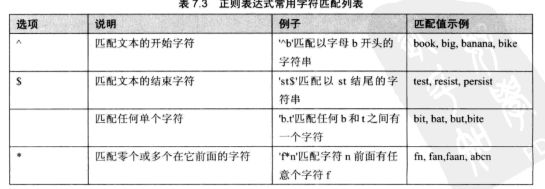












7.10 专家点拨
1.distinct不可一次应用于所有的列。
2.order by与limit混合使用:limit一定要位于 order by之后
3.子查询带上圆括号,养成好习惯。
4.通配符格式正确,但没有查出记录:可能原因数据存储的字符串数据时包含了空格。-
- 插入、更新与删除数据
insert into table_name () values();
insert into tbl_name set col_name=col_value;

- 8.1.4 将查询结果插入到表中
INSERT INTO table_name () SELECT () FROM table_name2 WHERE(); - 8.2 更新数据
UPDATE table_name SET name1=value1,... WHERE ();

8.3 删除数据
DELETE:运行WHERE子句指定删除条件。没有where就删除所有的记录。
删除所有记录还可以:TRUNCATE TABLE table_name;
语法:
DELETE FROM table_name WHERE ();9.索引
9.1.1 索引是一个单独的、储存在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。

1.索引是在存储引擎中实现的,因此,每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型。
2.根据存储引擎定义每个表的最大索引数和最大索引长度;所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。
3.MySQL中索引的存储类型有2种:BTREE和HASH,具体的还和表的存储引擎相关:MyISAM和InnoDB存储引擎只支持BTREE索引;MEMORY、HEAP引擎支持HASH和BTREE索引。
索引优点:1 可以保证数据库表中每一行数据的唯一性。
2 大大加快数据的查询速度,这也是创建索引的最主要原因。
3 在实现数据的参考完整性方面,可以加速表和表之间的连接。
4 在使用分组和排序子句进行数据查询时,也可以显著减少查询中分组和排序的时间。
索引缺点:1 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
2 索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。
3 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度和增加了维护成本。
9.1.2 索引的分类
- 普通索引和唯一索引

- 单列索引和组合索引

- 全文索引

- 空间索引

- 9.1.3 索引的设计原则

- 9.2 创建索引
- 9.2.1 创建表的时候创建索引
CREATE TABLE table_name [col_name data_type] [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [index_name] (col_name [length]) [ASC|DESC]

(1)创建普通索引 INDEX index_name(字段名)
最基本的索引类型,没有唯一性之类的限制,其作用只是加快对数据的访问速度。
create table book(bookid int not null, bookname varchar(255) not null, year_publication YEAR NOT NULL, INDEX(year_publication));
使用EXPLAIN、explain语句查看索引是否正在使用:



(2)创建唯一索引 UNIQUE INDEX index_name(字段名)
为id字段建立一个名为UniqIdx的唯一索引。
create table t1(id int not null, UNIQUE INDEX UniqIdx(id));
(3)创建单列索引 INDEX index_name(字段名)
create table t2(id int not null, INDEX SingleIdx(name(20)));
(4)创建组合索引 INDEX index_name(字段名)
在表的id/name/age字段上建立组合索引:
create table t3(id int not null, name char(30) not null, age int not null, INDEX MultiIdx(id,name,age(100)));
提示:组合索引需遵从‘最左前缀’,索引行中安id/name/age顺序存放,索引可以搜索下面字段组合:(id,name,age)(id,name)或者id;不能局部索引:(age)(name,age)
(5)创建全文索引 FULLTEXT INDEX index_name(字段名)
create table t4(id int not null, name char(33) not null, FULLTEXT INDEX FullTextIdx(name)) ENGINE=MyISAM;
(6)创建空间索引 SPATIAL INDEX index_name(字段名)
空间索引必须在MyISAM类型的表中创建,且字段必须为非空。
create table t5(id GEOMETRY NOT NULL, SPATIAL INDEX spatId(id))engine=MyISAM;
9.2.2 在已经存在的表上创建索引ALTER TABLE ADD \CREATE INDEX ON
(1)使用ALTER TABLE语句创建索引
语法:
ALTER TABLE table_name ADD [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [index_name] (dol_name[length],...) [ASC|DESC]在book表中的bookname字段上建立BkNameIdx的普通索引:
ALTER TABLE book ADD INDEX BkNmaeIdx (bookname(30));在book表的bookId字段上建立名称为UniqidIdx的唯一索引:
ALTER TABLE book ADD UNIQUE INDEX UniqidIdx(bookid);在book表的comment字段上建立单列索引:
ALTER TABLE book ADD INDEX BkcmtIdx(comment(50));在book表的authors和info字段上建立组合索引:
ALTER TABLE book ADD INDEX BkauandInfoIdx(authors(20), info(50));在t6上使用ALTER TBALE 建立全文索引(FULLTEXT:允许空值):
ALTER TABLE t6 ADD FULLTEXT INDEX infoFTIdx(info);在t7上的空间数据类型字段g上创建名称为spatidx的空间索引:
ALTER TABLE t7 ADD SPATIAL INDEX spatIdx(g);
(2)使用CREATE INDEX 创建索引
语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name ON table_name (col_name[length],...) [ASC|DESC]CREATE INDEX BkNameIdx ON book(bookname);
CREATE UNIQUE INDEX UniqidIdx ON book(bookId);
CREATE INDEX BkcmtIdx ON book(comment(50));
CREATE INDEX BkAuandinfoIdx ON book(authors(20),info(50));
CREATE FULLTEXT INDEX ON t6(info);
CREATE SPATIAL INDEX spatIdx ON t7(g);
9.3 删除索引ALTER TABLE \ DROP INDEX
- ALTER TABLE table_name DROP INDEX index_name;
- DROP INDEX index_name ON table_name;