关于 TensorFlow
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
Tensorflow是谷歌公司在2015年9月开源的一个深度学习框架。
什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
TensorFlow的特征
高度的灵活性
TensorFlow 不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用Tensorflow。你来构建图,描写驱动计算的内部循环。我们提供了有用的工具来帮助你组装“子图”(常用于神经网络),当然用户也可以自己在Tensorflow基础上写自己的“上层库”。定义顺手好用的新复合操作和写一个python函数一样容易,而且也不用担心性能损耗。当然万一你发现找不到想要的底层数据操作,你也可以自己写一点c++代码来丰富底层的操作。
真正的可移植性(Portability)
Tensorflow 在CPU和GPU上运行,比如说可以运行在台式机、服务器、手机移动设备等等。想要在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习的新想法?Tensorflow可以办到这点。准备将你的训练模型在多个CPU上规模化运算,又不想修改代码?Tensorflow可以办到这点。想要将你的训练好的模型作为产品的一部分用到手机app里?Tensorflow可以办到这点。你改变主意了,想要将你的模型作为云端服务运行在自己的服务器上,或者运行在Docker容器里?Tensorfow也能办到。Tensorflow就是这么拽 :)
将科研和产品联系在一起
过去如果要将科研中的机器学习想法用到产品中,需要大量的代码重写工作。那样的日子一去不复返了!在Google,科学家用Tensorflow尝试新的算法,产品团队则用Tensorflow来训练和使用计算模型,并直接提供给在线用户。使用Tensorflow可以让应用型研究者将想法迅速运用到产品中,也可以让学术性研究者更直接地彼此分享代码,从而提高科研产出率。
自动求微分
基于梯度的机器学习算法会受益于Tensorflow自动求微分的能力。作为Tensorflow用户,你只需要定义预测模型的结构,将这个结构和目标函数(objective function)结合在一起,并添加数据,Tensorflow将自动为你计算相关的微分导数。计算某个变量相对于其他变量的导数仅仅是通过扩展你的图来完成的,所以你能一直清楚看到究竟在发生什么。
多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的ipython界面来用Tensorflow尝试些想法,它可以帮你将笔记、代码、可视化等有条理地归置好。当然这仅仅是个起点——我们希望能鼓励你创造自己最喜欢的语言界面,比如Go,Java,Lua,Javascript,或者是R。
性能最优化
比如说你又一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来?由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计算元素分配到不同设备上,Tensorflow可以帮你管理好这些不同副本。
谁可以用 TensorFlow?
任何人都可以用Tensorflow。学生、研究员、爱好者、极客、工程师、开发者、发明家、创业者等等都可以在Apache 2.0 开源协议下使用Tensorflow。
Tensorflow 还没竣工,它需要被进一步扩展和上层建构。我们刚发布了源代码的最初版本,并且将持续完善它。我们希望大家通过直接向源代码贡献,或者提供反馈,来建立一个活跃的开源社区,以推动这个代码库的未来发展。
为啥Google要开源这个神器?
如果Tensorflow这么好,为啥不藏起来而是要开源呢?答案或许比你想象的简单:我们认为机器学习是未来新产品和新技术的一个关键部分。在这一个领域的研究是全球性的,并且发展很快,却缺少一个标准化的工具。通过分享这个我们认为是世界上最好的机器学习工具库之一的东东,我们希望能够创造一个开放的标准,来促进交流研究想法和将机器学习算法产品化。Google的工程师们确实在用它来提供用户直接在用的产品和服务,而Google的研究团队也将在他们的许多科研文章中分享他们对Tensorflow的使用。
TensorflowSharp中的概念
TensorflowSharp / Tensorflow中最重要的几个概念:
图(Graph):它包含了一个计算任务中的所有变量和计算方式。可以将它和C#中的表达式树进行类比。例如,一个1+2可以被看作为两个常量表达式,以一个二元运算表达式连接起来。在Tensorflow的世界中,则可以看成是两个tensor和一个op(operation的缩写,即操作)。简单来说,做一个机器学习的任务就是计算一张图。
在计算图之前,当然要把图建立好。例如,计算(1+2)*3再开根号,是一个包括了3个tensor和3个Op的图。
不过,Tensorflow的图和常规的表达式还有所不同,Tensorflow中的节点变量是可以被递归的更新的。我们所说的“训练”,也就是不停的计算一个图,获得图的计算结果,再根据结果的值调整节点变量的值,然后根据新的变量的值再重新计算图,如此重复,直到结果令人满意(小于某个阈值),或跑到了一个无穷大/小(这说明图的变量初始值设置的有问题),或者结果基本不变了为止。
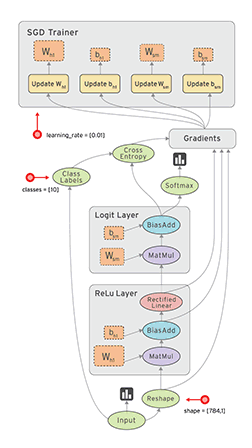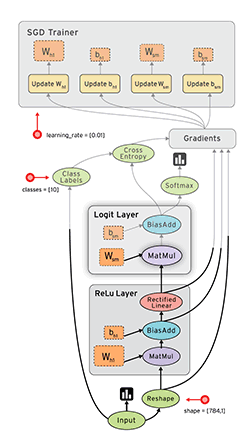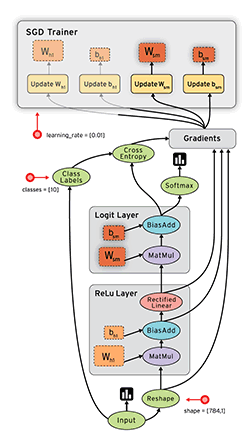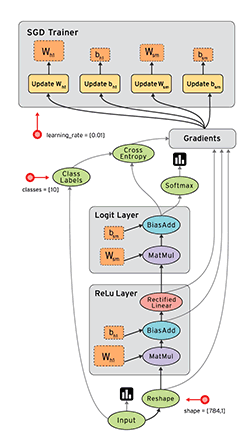
前面说过,从内部机制上来说,TF就是建立数据流图来进行数值计算。所以,当你使用TF来搭建模型时,其实主要涉及两个方面:根据模型建立计算图,然后送入数据运行计算图得到结果。计算图computational graph是TF中很重要的一个概念,其是由一系列节点(nodes)组成的图模型,每个节点对应的是TF的一个算子(operation)。每个算子会有输入与输出,并且输入和输出都是张量。所以我们使用TF的算子可以构建自己的深度学习模型,其背后的就是一个计算图。还有一点这个计算图是静态的,意思是这个计算图每个节点接收什么样的张量和输出什么样的张量已经固定下来。要运行这个计算图,你需要开启一个会话(session),在session中这个计算图才可以真正运行。
我们用一个简单的例子来说明图模型的机理,首先定义一个计算图:
public static void BasicOperation2()
{
using (var s = new TFSession())
{
var g = s.Graph;
var a = g.Const(5);
var b = g.Const(3);
var c = g.Mul(a, b);
var d = g.Add(a, b);
var e = g.Add(c, d);
var runner = s.GetRunner();
var result = runner.Run(e);
Console.WriteLine($"相加的结果:{result.GetValue()}");
// 相加的结果:23
}
}
代码很简单,我们引入TF库,然后利用TF的基本算术算子(和Numpy接口一致)创建了一个简单的计算图如下图所示。其中每个圆圈代表的是每个算子定义的节点。节点之间的边就是张量,这里其实都是标量(scalers)。
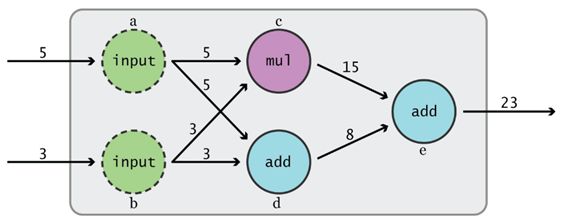
当我们想得到e的值时,TF会根据创建好的计算图查找e节点所有的依赖节点,这可以看成一个抽取子计算图的过程。得到这个子计算图就可以从a和b节点开始计算最终得到e的值。还有一点TF会对这个计算过程做并行化优化,不过这都是底层的事了。TF更灵活的一点你可以指定各个节点在哪个具体的设备上运行,如CPU和GPU。理解好计算图,就掌握了TF的基本运作原理。
会话(Session):为了获得图的计算结果,图必须在会话中被启动。图是会话类型的一个成员,会话类型还包括一个runner,负责执行这张图。会话的主要任务是在图运算时分配CPU或GPU。
张量(tensor): Tensorflow中所有的输入输出变量都是张量,而不是基本的int,double这样的类型,即使是一个整数1,也必须被包装成一个0维的,长度为1的张量【1】。一个张量和一个矩阵差不多,可以被看成是一个多维的数组,从最基本的一维到N维都可以。张量拥有阶(rank),形状(shape),和数据类型。其中,形状可以被理解为长度,例如,一个形状为2的张量就是一个长度为2的一维数组。而阶可以被理解为维数。
| 阶 | 数学实例 | Python 例子 |
|---|---|---|
| 0 | 纯量 (只有大小) | s = 483 |
| 1 | 向量(大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵(数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
对于任何深度学习框架,你都要先了解张量(Tensor)的概念,张量可以看成是向量和矩阵的衍生。向量是一维的,而矩阵是二维的,对于张量其可以是任何维度的。一般情况下,你要懂得张量的两个属性:形状(shape)和秩(rank)。秩很好理解,就是有多少个维度;而形状是指的每个维度的大小。下面是常见的张量的形象图表示:
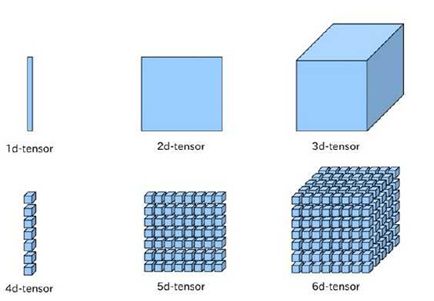
名字就是TensorFlow,直观来看,就是张量的流动。张量(tensor),即任意维度的数据,一维、二维、三维、四维等数据统称为张量。而张量的流动则是指保持计算节点不变,让数据进行流动。这样的设计是针对连接式的机器学习算法,比如逻辑斯底回归,神经网络等。连接式的机器学习算法可以把算法表达成一张图,张量从图中从前到后走一遍就完成了前向运算;而残差从后往前走一遍,就完成了后向传播。
Tensorflow中的运算(op)有很多很多种,最简单的当然就是加减乘除,它们的输入和输出都是tensor。
Runner:在建立图之后,必须使用会话中的Runner来运行图,才能得到结果。在运行图时,需要为所有的变量和占位符赋值,否则就会报错。
TensorflowSharp中的几类主要变量
- Const:常量,这很好理解。它们在定义时就必须被赋值,而且值永远无法被改变。
- Placeholder:占位符。这是一个在定义时不需要赋值,但在使用之前必须赋值(feed)的变量,通常用作训练数据。
- Variable:变量,它和占位符的不同是它在定义时需要赋值,而且它的数值是可以在图的计算过程中随时改变的。因此,占位符通常用作图的输入(即训练数据),而变量用作图中可以被“训练”或“学习”的那些tensor,例如y=ax+b中的a和b。
Cloud Machine Learning
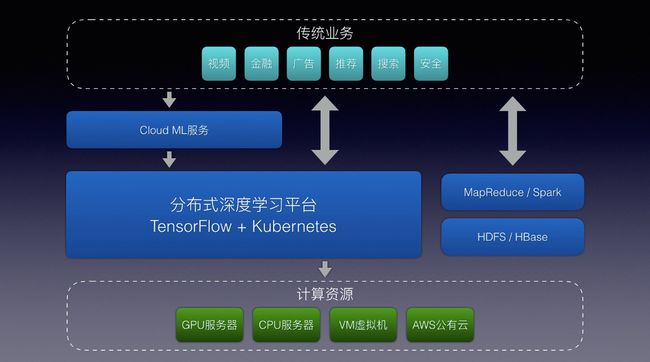
前面已经介绍了TensorFlow相关的全部内容,细心的网友可能已经发现,TensorFlow功能强大,但究其本质还是一个library,用户除了编写TensorFlow应用代码还需要在物理机上起服务,并且手动指定训练数据和模型文件的目录,维护成本比较大,而且机器之间不可共享。
纵观大数据处理和资源调度行业,Hadoop生态俨然成为了业界的标准,通过MapReduce或Spark接口来处理数据,用户通过API提交任务后由Yarn进行统一的资源分配和调度,不仅让分布式计算成为可能,也通过资源共享和统一调度平的台极大地提高了服务器的利用率。很遗憾TensorFlow定义是深度学习框架,并不包含集群资源管理等功能,但开源TensorFlow以后,Google很快公布了Google Cloud ML服务,我们从Alpha版本开始已经是Cloud ML的早期用户,深深体会到云端训练深度学习的便利性。通过Google Cloud ML服务,我们可以把TensorFlow应用代码直接提交到云端运行,甚至可以把训练好的模型直接部署在云上,通过API就可以直接访问,也得益于TensorFlow良好的设计,我们基于Kubernetes和TensorFlow serving实现了Cloud Machine Learning服务,架构设计和使用接口都与Google Cloud ML类似。
总结
一篇短而精悍的小文肯定不能把TF所有的方面展示出来,但是这是一个起点,尽情地使用Tensorflow吧!