一、预备知识
1.1 卷积操作
卷积的基本操作就是这样的:这仅是单通道的计算,多通道类似。
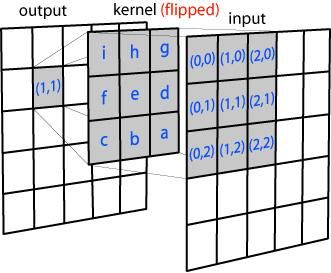
1.2 img2col
思路:
- 首先,为啥要有这玩意?
- 其次,这玩意是怎么做的?
- 最后,这玩意有啥优缺点?边界在哪?
1.2.1 为什么要造出img2col来? 或者说造这玩意的目的是啥?
这个概念是在卷积的实现很粗糙的背景下提出来的,不信你看这个链接,里面是关于caffe框架的作者对他们卷积实现的吐槽,说当时是在很短的时间内要做出这个框架,所以就以一个学生水平的代码来实现的,他的原始实现方式如下:
Loosely speaking, assume that we have a W*H image with depth D at each input location. For each location, we get a K*K patch, which could be considered as a K*K*D vector, and apply M filters to it. In pseudocode, this is (ignoring boundary conditions):
for w in 1..W
for h in 1..H
for x in 1..K
for y in 1..K
for m in 1..M
for d in 1..D
output(w, h, m) += input(w+x, h+y, d) * filter(m, x, y, d)
end
end
end
end
end
end
哈哈哈哈哈哈。。。。
等等。。。作者当时是博士第三年,还上了Berkeley's CS267 (parallel computers)课程,并在课程设计中针对两层做过了最优设计的男人~我哪来的自信哈哈哈?!

咳咳。。。
好,我们现在严肃回来!
你现在问我为什么么要造img2col这玩意出来?我只能告诉你:
这当然是为了优化卷积运算咯!
1.2.2 img2col的实现原理是啥?
你看我们原来的图像是这样的:
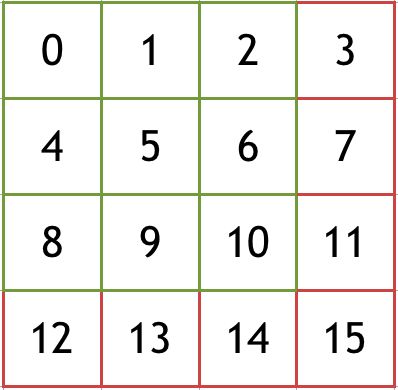
按照二维存储的话,假如我们是3X3的卷积核同时图像比较大的时候(内存地址的stride > cache line size),那么我们的小cache哟,那可是受不了的!
什么?你问为什么cache受不了?
嗯。。。。简单来说就是不满足cache空间局部性原理,更细致的原因可以去找一个cpu的新片手册,读一下cache那章,在cache line那个地方就有讲。
于是很自然的,我们想可不可以直接把这些跨度很大的内存单元提前放到一个连续的内存单元里来,这样子的话我们的cache hit rate会大大提高。
于是img2col就是干这个活的。
这里得说明一下: col并不一定是表示列哟,不同平台下实现方式不一样的额,如matlab是按列来的,但是caffe却是按照行来存的,其目的都是一样的,都是为了加速内存访问。
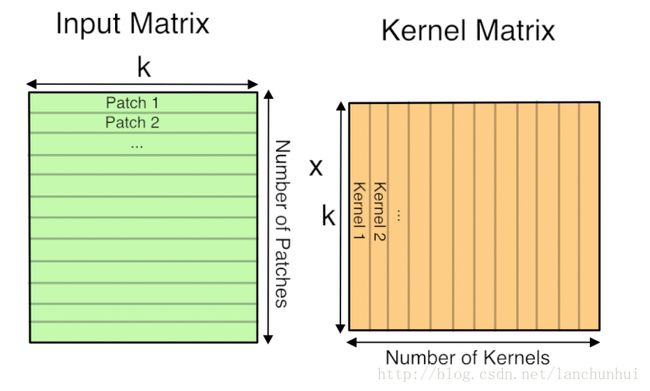
这里懒得画了,借用图片一下(图片来源自这):
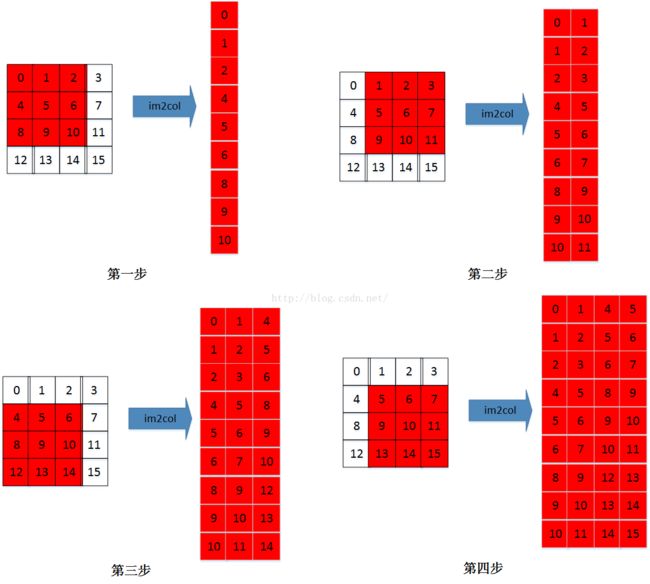
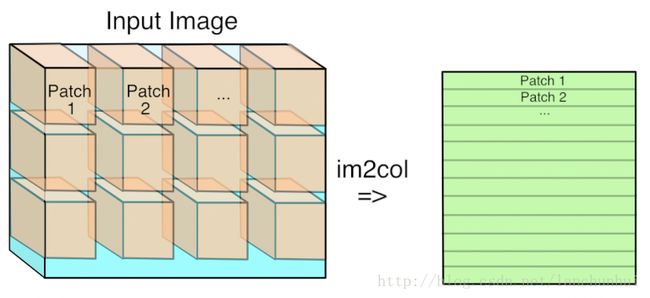
你看,每一步的卷积都提前给转换好,放到连续的内存中来。
点评:你看吧,瞎子都看出来了,有大量的冗余内存单元被放进来了,这就是典型的空间换时间的例子。
再捋一下:
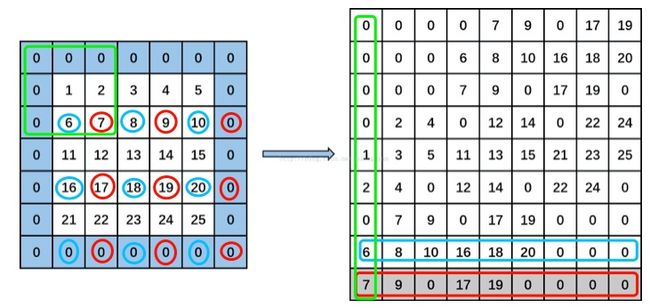
你看下图示一张图,在卷积前先给加一层padding,然后开始卷积;
正常情况下左上角的绿色框就是要被卷积的,但是由于cache特性不好,所以我们给转一下,把这这三组(每组3个内存)不连续内存转成右图绿色框中那种形式,成为一列,这样在内存中就有办法搞成连续的内存地址了。
好了,目标定好了,那么我们怎么设计转换算法?
其实我也不会设计,就是看caffe的源码实现是按行来的,如图中的红色蓝色框所示,以这种间隔的方式按行存储原始数据,最终得到的就是每个卷积区域都转换成一列了,也就是线性的了。
1.2.3 img2col的优缺点
优点
cache性能好很多了哟~缺点
很明显啊,内存占用大大增加了啊,上图中原始图大小是7x7,转换后为9x9,也就是说内存占用多了65%啊!
这部分最后加上作者在Berkeley演讲时的ppt作为小结:

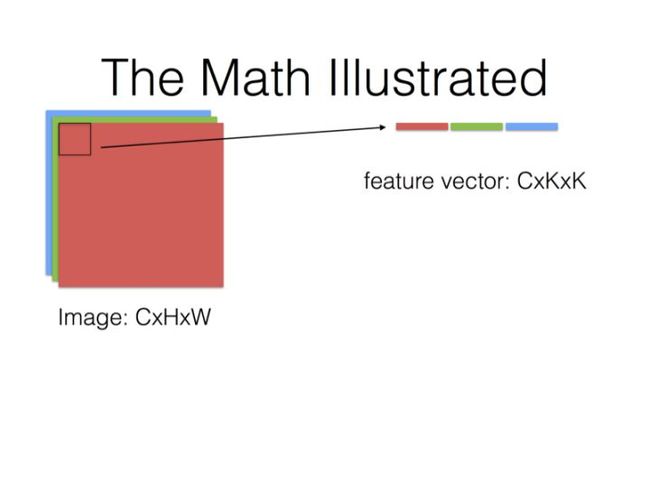
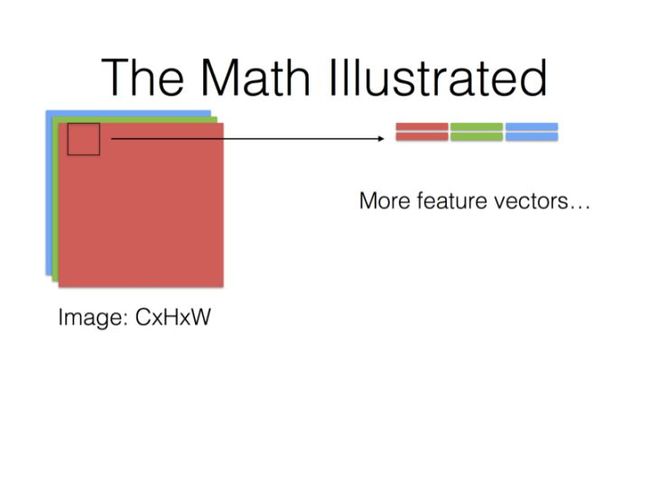
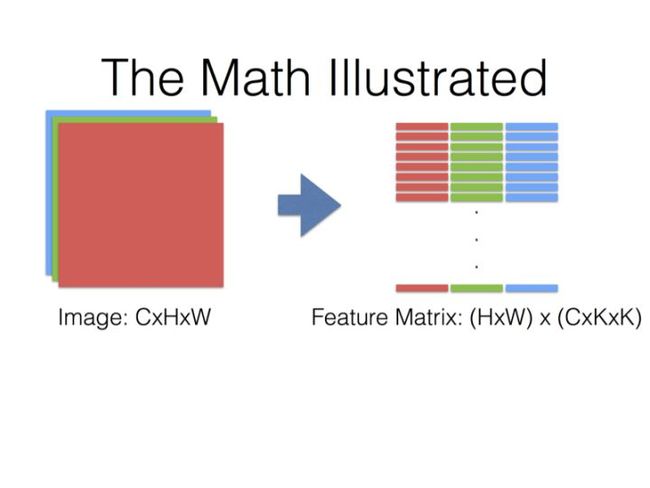
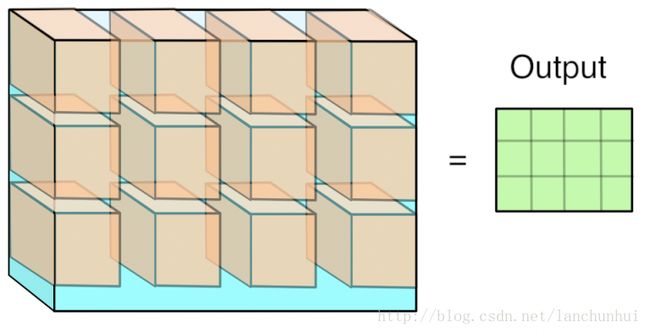
下面表示整个输入的feature map的卷积区域给连续展开了,转换成一个(HxW)x(CxKxK)的矩阵;
这里需要理解的是KxK:
- 我们之前是CxHxW视角,也就是先看一整个面HxW,然后再看深度C,也就是 C个HxW平面。
- 后面是以HxW面中的一小块区域(KxK)为坐标,然后加上深度信息,这样才构成一个基本的步进单元。解读为 HxW个CxKxK立方体
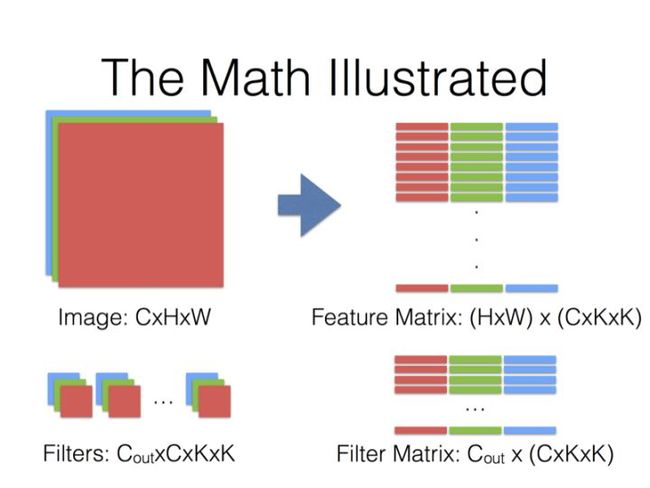
最后一页没画,但是基本上就是Filter Matrix乘以Feature Matrix的转置,得到输出矩阵Cout x (H x W),就可以解释为输出的三维Blob(Cout x H x W)。
第一部分附录:
图片来源:https://blog.csdn.net/lanchunhui/article/details/74838635
二、winograd原理
2.1 先·宏观来看
Strassen算法仅仅比通用矩阵相乘算法好一点,因为通用矩阵相乘算法时间复杂度是:
而Strassen算法复杂度只是:
但随着n的变大,比如当n >> 100时,Strassen算法是比通用矩阵相乘算法变得更有效率。
根据wikipedia上的介绍,后来Coppersmith–Winograd 算法把 N* N大小的矩阵乘法的时间复杂度降低到了:
而2010年,Andrew Stothers再度把复杂度降低到了:
一年后的2011年,Virginia Williams把复杂度最终定格为:
三、winograd实现
在ncnn的convolution_3x3.h文件中conv3x3s1_winograd64_neon4(const Mat& bottom_blob, Mat& top_blob, const Mat& kernel_tm, const Mat& _bias) 实现了winograd算法。
步骤如下:
-
首先把输出通道按照6x6的大小做补齐,使得整体的大小为6x6的整数倍,填充后的输出再加一层padding。
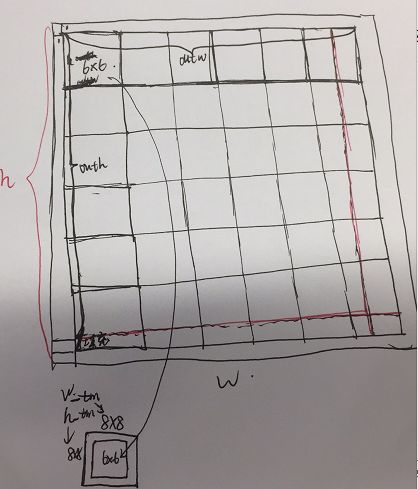
第二步就是处理底层feature map层了。
//把底层复制成扩展后的输出层+边的大小,空出来的地方填充V值。
copy_make_border(bottom_blob, bottom_blob_bordered, 0, h - bottom_blob.h, 0, w - bottom_blob.w, 0, 0.f);-
第二步就是处理底层feature map层了。
- 首先把输出做tile操作,也就是把每个6x6扩大到8x8,此时得到
w_tm = outw / 6 * 8、h_tm = outh / 6 * 8
- 首先把输出做tile操作,也就是把每个6x6扩大到8x8,此时得到
四、winograd汇编性能优化
待续。。。