MySql学习笔记一
1.SQL 分类
- DDL(Data Definition Language)数据定义语言
- DML(Data Manipulation Language)数据操作语言
- DQL(Data Query Language)数据查询语言
- DCL(Data Control Language)数据控制语言
- TCL(Transaction Control Language)事务控制语言
2.常见指令
查看当前所有数据库: show databases
打开指定的库:use 库名
查看当前库的所有表:show tables
查看其它库的所有表:show tables from 库名
创建表:create table 表名(
列名 列类型,
列名 列类型,
......
);
查看表结构:DESC 表名
查看服务器版本:
select version()||mysql --V查看字符集:
Show variables like '%char%'查看当前用户:Select USER();
3.DQL(数据查询语言)
3.1基础查询
select 查询列表 from 表名
查询列表可以是:表中字段、常量、表达式、函数
查询的结果是一个虚拟机的表格
3.1.1.常用关键字
3.1.1.1.起别名
as 或者 空格 例如 select 字段名 as a from 表名 as b
对字段的别名最好加上双引号,可以在别名里加空格
3.1.1.2.去重
利用关键字DISTINCT
select distinct 字段名 from 表名
3.1.1.3.'+'只有计算功能
1 + 1 = 2
'1' + 1 = 2
'a' + 1 = 1
null + 1 = null
3.1.1.4.CONCAT
select 字段名 CONCAT 字段名 (AS 别名)from 表名
CONCAT相当于java中的 '+'
3.2.条件查询
select 查询列表 from 表名 where 筛选条件
3.2.1.按条件表达式筛选
条件运算符:>, < , =, !=, >=, <= ; != MySql建议写为 <>
3.2.2.按逻辑表达式筛选
and or not
3.2.3.模糊查询
like
%任意多个字符
_任意单个字符
如果查询含有转移符号的数据,要用\转义如
\%和\_ 也可以用ESCAPE 如 like '_$%' ESCAPLE '$'
between...and... 两边都包含
in
in列表中的值类型必须一致或者兼容
不支持通配符
is null
null值判断不能用 = null 要用 is null, is not null
3.2.4.安全等于
<=> 可以判断Null值,也可以判断普通数值
但是可读性较差
3.3.排序查询
示例: select 查询列表 from 表名 order by 排序列表 ASC(DESC)
ASC是升序排列,DESC是降序排列, 默认是ASC
排序列表可以是 字段名,表达式,别名,函数
支持按多个字段排序, 例 order by 排序列表1 ASC(DESC), 排序列表2 ASC(DESC)....
先按按排序列表1进行排序,然后排序列表1相同的按排序列表进行排序,以此类推。
3.4.常见函数
函数类似于java中的方法,将一组逻辑语句封装在方法体中,对外暴露方法名
好处:1.隐藏了实现细节 2.提高代码重用性
3.4.1.单行函数
如count, length, IFNULL等
3.4.1.1.字符函数
length
统计参数值的字节个数,utf-8中文占三个字节, gbk中文占两个字节
CONCAT
拼接字符串 例CONCAT(str1,str2,str3.....)
和null拼接会编程null
upper,lower
upper变大写,lower变小写
substr, subString
截取字符串
substr(str, index) 截取从index开始后面所有的字符
substr(str, pos, len) 截取从pos到len的字符
sql中索引是从1开始的
instr
instr(str1, str2)
判断str2在str1中第一次出现的索引,如果找不到返回0
trim
trim(str)
去除str中的前后空格
trim(str1 from str2)
去除str2中开头结尾重复出现的str1
LPAD、RPAD
LPAD(STR1, LEN, STR2)
在STR1的前面重复填充STR2直到长度为LEN,如果LEN < STR1的LENGTH, 会截断STR1
RPAD同理
Replace
Replace(STR1, STR2, STR3)
将STR1中的所有的STR2都替换为STR3
3.4.1.2.数学函数
round
round(double) 四舍五入为整数
round(double, num) 四舍五入保留num位小数
ceil
ceil(double) 返回>=num的最小整数
floor
floor(double) 返回<=num的最大整数
truncate
truncate(double, num) 小数点num位以后截断舍去
mod
mod(num1, num2) 取余 相当于%
rand
获取0-1之间的随机数
3.4.1.3.日期函数
now
now() 返回当前系统日期+时间
CURDATE
CURDATE() 返回当前系统日期,不包含时间
CURTIME
CURTIME() 返回当前系统时间,不包含日期
获取日期指定部分
YEAR(date) 获取年
MONTH(date) 获取月
MONTHNAME(date) 获取月名
DAY, HOUR, MINUTE, SECOND同上
字符串与日期的相互转换
STR_TO_DATE('STRDATE', 'Format') 例STR_TO_DATE('9-13-2019', '%m-%d-%Y') m是月份,必须用m
将字符串按照format格式转换成日期
date_format(date, format) 例 date_format(now(), '%m月%d日%Y年')
将日期按照format格式转换成字符串
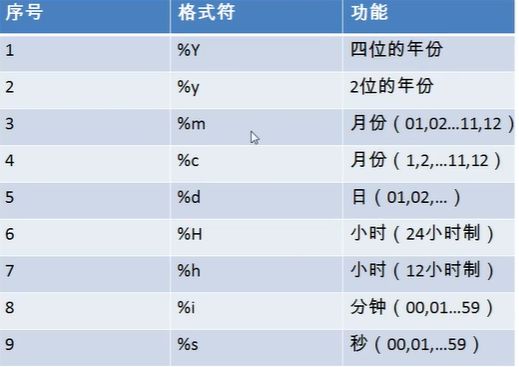
DateDiff
DateDiff(date1, date2)
返回的是date1日期减去date2日期的天数差
3.4.1.4 流程控制函数
if函数
实现类似于if else 的效果
例如 if(experssion, trueResult, falseResult)
case函数
使用1 实现类似switch case的效果
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1;
when 常量2 then 要显示的值2或语句2;
when 常量3 then 要显示的值3或语句2;
...
else 要显示的值或语句
end使用2 实现类似于if ,else if...的效果
case
when 条件1 then 要显示的值1或语句1;
when 条件2 then 要显示的值2或语句2;
when 条件3 then 要显示的值3或语句3;
...
else 要显示的值或语句
end3.4.2.分组函数
做统计使用,又称为统计函数,聚合函数,组函数
sum(): 求和
avg(): 平均值
max(): 最大值
min(): 最小值
count(): 计算个数
count(字段名) 统计字段名非空的行数
count(*) 统计总行数 等价于count(常量) 如count(1), count('a')等
效率:MYISAM引擎下:count(*)效率最高
INNODB引擎下:count(*)和count(1)效率差不多,比cout('str')高
分组函数参数支持类型:
| 字符型 | 日期型 | 数值型 | 忽略null值 | 与DISTINCT搭配 | |
|---|---|---|---|---|---|
| sum() | X | X | √ | √ | √ |
| avg() | X | X | √ | √ | √ |
| max() | √ | √ | √ | √ | √ |
| min() | √ | √ | √ | √ | √ |
| count() | √ | √ | √ | √ | √ |
与分组函数一同查询的字段有限制,一般都是group by之后的字段
3.5.分组查询
Select 分组函数, 字段(要求该字段出现在group by的后面)
from 表
(where 分组前的筛选条件)
group by 分组的字段1 (分组的字段2.....)
(having 分组后的筛选条件)
(order by 排序)where筛选的是分组前的原来的表中的数据
having筛选的是分组后的数据
分组函数的条件一定是放在having子句中
为了性能,能用分组前筛选的条件尽量放在where子句中
当group by之后有多个条件时,条件的先后顺序不影响查询结果,条目分组时必须满足每一个条件都相等