在这篇中我将讲述GC Collector内部的实现, 这是CoreCLR中除了JIT以外最复杂部分,下面一些概念目前尚未有公开的文档和书籍讲到。
为了分析这部分我花了一个多月的时间,期间也多次向CoreCLR的开发组提问过,我有信心以下内容都是比较准确的,但如果你发现了错误或者有疑问的地方请指出来,
以下的内容基于CoreCLR 1.1.0的源代码分析,以后可能会有所改变。
因为内容过长,我分成了两篇,这一篇分析代码,下一篇实际使用LLDB跟踪GC收集垃圾的处理。
需要的预备知识
- 看过BOTR中GC设计的文档 原文 译文
- 看过我之前的系列文章, 碰到不明白的可以先跳过但最少需要看一遍
- 第一篇
- 第二篇
- 第三篇
- 对c中的指针有一定了解
- 对常用数据结构有一定了解, 例如链表
- 对基础c++语法有一定了解, 高级语法和STL不需要因为微软只用了低级语法
GC的触发
GC一般在已预留的内存不够用或者已经分配量超过阈值时触发,场景包括:
不能给分配上下文指定新的空间时
当调用try_allocate_more_space不能从segment结尾或自由对象列表获取新的空间时会触发GC, 详细可以看我上一篇中分析的代码。
分配的数据量达到一定阈值时
阈值储存在各个heap的dd_min_gc_size(初始值), dd_desired_allocation(动态调整值), dd_new_allocation(消耗值)中,每次给分配上下文指定空间时会减少dd_new_allocation。
如果dd_new_allocation变为负数或者与dd_desired_allocation的比例小于一定值则触发GC,
触发完GC以后会重新调整dd_new_allocation到dd_desired_allocation。
参考new_allocation_limit, new_allocation_allowed和check_for_full_gc函数。
值得一提的是可以在.Net程序中使用GC.RegisterForFullGCNotification可以设置触发GC需要的dd_new_allocation / dd_desired_allocation的比例(会储存在fgn_maxgen_percent和fgn_loh_percent中), 设置一个大于0的比例可以让GC触发的更加频繁。
StressGC
允许手动设置特殊的GC触发策略, 参考这个文档
作为例子,你可以试着在运行程序前运行export COMPlus_GCStress=1
GCStrees会通过调用GCStress触发,
如果你设置了COMPlus_GCStressStart环境变量,在调用MaybeTrigger一定次数后会强制触发GC,另外还有COMPlus_GCStressStartAtJit等参数,请参考上面的文档。
默认StressGC不会启用。
手动触发GC
在.Net程序中使用GC.Collect可以触发手动触发GC,我相信你们都知道。
调用.Net中的GC.Collect会调用CoreCLR中的GCHeap::GarbageCollect => GarbageCollectTry => GarbageCollectGeneration。
GC的处理
以下函数大部分都在gc.cpp里,在这个文件里的函数我就不一一标出文件了。
GC的入口点
GC的入口点是GCHeap::GarbageCollectGeneration函数,这个函数的主要作用是停止运行引擎和调用各个gc_heap的gc_heap::garbage_collect函数
因为这一篇重点在于GC做出的处理,我将不对如何停止运行引擎和后台GC做出详细的解释,希望以后可以再写一篇文章讲述
// 第一个参数是回收垃圾的代, 例如等于1时会回收gen 0和gen 1的垃圾
// 第二个参数是触发GC的原因
size_t
GCHeap::GarbageCollectGeneration (unsigned int gen, gc_reason reason)
{
dprintf (2, ("triggered a GC!"));
// 获取gc_heap实例,意义不大
#ifdef MULTIPLE_HEAPS
gc_heap* hpt = gc_heap::g_heaps[0];
#else
gc_heap* hpt = 0;
#endif //MULTIPLE_HEAPS
// 获取当前线程和dd数据
Thread* current_thread = GetThread();
BOOL cooperative_mode = TRUE;
dynamic_data* dd = hpt->dynamic_data_of (gen);
size_t localCount = dd_collection_count (dd);
// 获取GC锁, 防止重复触发GC
enter_spin_lock (&gc_heap::gc_lock);
dprintf (SPINLOCK_LOG, ("GC Egc"));
ASSERT_HOLDING_SPIN_LOCK(&gc_heap::gc_lock);
//don't trigger another GC if one was already in progress
//while waiting for the lock
{
size_t col_count = dd_collection_count (dd);
if (localCount != col_count)
{
#ifdef SYNCHRONIZATION_STATS
gc_lock_contended++;
#endif //SYNCHRONIZATION_STATS
dprintf (SPINLOCK_LOG, ("no need GC Lgc"));
leave_spin_lock (&gc_heap::gc_lock);
// We don't need to release msl here 'cause this means a GC
// has happened and would have release all msl's.
return col_count;
}
}
// 统计GC的开始时间(包括停止运行引擎使用的时间)
#ifdef COUNT_CYCLES
int gc_start = GetCycleCount32();
#endif //COUNT_CYCLES
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
AllocDuration += GetCycleCount32() - AllocStart;
#else
AllocDuration += clock() - AllocStart;
#endif //COUNT_CYCLES
#endif //TRACE_GC
// 设置触发GC的原因
gc_heap::g_low_memory_status = (reason == reason_lowmemory) ||
(reason == reason_lowmemory_blocking) ||
g_bLowMemoryFromHost;
if (g_bLowMemoryFromHost)
reason = reason_lowmemory_host;
gc_trigger_reason = reason;
// 重设GC结束的事件
// 以下说的"事件"的作用和"信号量", .Net中的"Monitor"一样
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap::g_heaps[i]->reset_gc_done();
}
#else
gc_heap::reset_gc_done();
#endif //MULTIPLE_HEAPS
// 标记gc已开始, 全局静态变量
gc_heap::gc_started = TRUE;
// 停止运行引擎
{
init_sync_log_stats();
#ifndef MULTIPLE_HEAPS
// 让当前线程进入preemptive模式
// 最终会调用Thread::EnablePreemptiveGC
// 设置线程的m_fPreemptiveGCDisabled等于0
cooperative_mode = gc_heap::enable_preemptive (current_thread);
dprintf (2, ("Suspending EE"));
BEGIN_TIMING(suspend_ee_during_log);
// 停止运行引擎,这里我只做简单解释
// - 调用ThreadSuspend::SuspendEE
// - 调用LockThreadStore锁住线程集合直到RestartEE
// - 设置GCHeap中全局事件WaitForGCEvent
// - 调用ThreadStore::TrapReturingThreads
// - 设置全局变量g_TrapReturningThreads,jit会生成检查这个全局变量的代码
// - 调用SuspendRuntime, 停止除了当前线程以外的线程,如果线程在cooperative模式则劫持并停止,如果线程在preemptive模式则阻止进入cooperative模式
GCToEEInterface::SuspendEE(GCToEEInterface::SUSPEND_FOR_GC);
END_TIMING(suspend_ee_during_log);
// 再次判断是否应该执行gc
// 目前如果设置了NoGCRegion(gc_heap::settings.pause_mode == pause_no_gc)则会进一步检查
// https://msdn.microsoft.com/en-us/library/system.runtime.gclatencymode(v=vs.110).aspx
gc_heap::proceed_with_gc_p = gc_heap::should_proceed_with_gc();
// 设置当前线程离开preemptive模式
gc_heap::disable_preemptive (current_thread, cooperative_mode);
if (gc_heap::proceed_with_gc_p)
pGenGCHeap->settings.init_mechanisms();
else
gc_heap::update_collection_counts_for_no_gc();
#endif //!MULTIPLE_HEAPS
}
// MAP_EVENT_MONITORS(EE_MONITOR_GARBAGE_COLLECTIONS, NotifyEvent(EE_EVENT_TYPE_GC_STARTED, 0));
// 统计GC的开始时间
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
unsigned start;
unsigned finish;
start = GetCycleCount32();
#else
clock_t start;
clock_t finish;
start = clock();
#endif //COUNT_CYCLES
PromotedObjectCount = 0;
#endif //TRACE_GC
// 当前收集代的序号
// 后面看到condemned generation时都表示"当前收集代"
unsigned int condemned_generation_number = gen;
// We want to get a stack from the user thread that triggered the GC
// instead of on the GC thread which is the case for Server GC.
// But we are doing it for Workstation GC as well to be uniform.
FireEtwGCTriggered((int) reason, GetClrInstanceId());
// 进入GC处理
// 如果有多个heap(服务器GC),可以使用各个heap的线程并行处理
// 如果只有一个heap(工作站GC),直接在当前线程处理
#ifdef MULTIPLE_HEAPS
GcCondemnedGeneration = condemned_generation_number;
// 当前线程进入preemptive模式
cooperative_mode = gc_heap::enable_preemptive (current_thread);
BEGIN_TIMING(gc_during_log);
// gc_heap::gc_thread_function在收到这个信号以后会进入GC处理
// 在里面也会判断proceed_with_gc_p
gc_heap::ee_suspend_event.Set();
// 等待所有线程处理完毕
gc_heap::wait_for_gc_done();
END_TIMING(gc_during_log);
// 当前线程离开preemptive模式
gc_heap::disable_preemptive (current_thread, cooperative_mode);
condemned_generation_number = GcCondemnedGeneration;
#else
// 在当前线程中进入GC处理
if (gc_heap::proceed_with_gc_p)
{
BEGIN_TIMING(gc_during_log);
pGenGCHeap->garbage_collect (condemned_generation_number);
END_TIMING(gc_during_log);
}
#endif //MULTIPLE_HEAPS
// 统计GC的结束时间
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
finish = GetCycleCount32();
#else
finish = clock();
#endif //COUNT_CYCLES
GcDuration += finish - start;
dprintf (3,
(" Condemned: %d, Duration: %d, total: %d Alloc Avg: %d, Small Objects:%d Large Objects:%d",
VolatileLoad(&pGenGCHeap->settings.gc_index), condemned_generation_number,
finish - start, GcDuration,
AllocCount ? (AllocDuration / AllocCount) : 0,
AllocSmallCount, AllocBigCount));
AllocCount = 0;
AllocDuration = 0;
#endif // TRACE_GC
#ifdef BACKGROUND_GC
// We are deciding whether we should fire the alloc wait end event here
// because in begin_foreground we could be calling end_foreground
// if we need to retry.
if (gc_heap::alloc_wait_event_p)
{
hpt->fire_alloc_wait_event_end (awr_fgc_wait_for_bgc);
gc_heap::alloc_wait_event_p = FALSE;
}
#endif //BACKGROUND_GC
// 重启运行引擎
#ifndef MULTIPLE_HEAPS
#ifdef BACKGROUND_GC
if (!gc_heap::dont_restart_ee_p)
{
#endif //BACKGROUND_GC
BEGIN_TIMING(restart_ee_during_log);
// 重启运行引擎,这里我只做简单解释
// - 调用SetGCDone
// - 调用ResumeRuntime
// - 调用UnlockThreadStore
GCToEEInterface::RestartEE(TRUE);
END_TIMING(restart_ee_during_log);
#ifdef BACKGROUND_GC
}
#endif //BACKGROUND_GC
#endif //!MULTIPLE_HEAPS
#ifdef COUNT_CYCLES
printf ("GC: %d Time: %d\n", GcCondemnedGeneration,
GetCycleCount32() - gc_start);
#endif //COUNT_CYCLES
// 设置gc_done_event事件和释放gc锁
// 如果有多个heap, 这里的处理会在gc_thread_function中完成
#ifndef MULTIPLE_HEAPS
process_sync_log_stats();
gc_heap::gc_started = FALSE;
gc_heap::set_gc_done();
dprintf (SPINLOCK_LOG, ("GC Lgc"));
leave_spin_lock (&gc_heap::gc_lock);
#endif //!MULTIPLE_HEAPS
#ifdef FEATURE_PREMORTEM_FINALIZATION
if ((!pGenGCHeap->settings.concurrent && pGenGCHeap->settings.found_finalizers) ||
FinalizerThread::HaveExtraWorkForFinalizer())
{
FinalizerThread::EnableFinalization();
}
#endif // FEATURE_PREMORTEM_FINALIZATION
return dd_collection_count (dd);
} 以下是gc_heap::garbage_collect函数,这个函数也是GC的入口点函数,
主要作用是针对gc_heap做gc开始前和结束后的清理工作,例如重设各个线程的分配上下文和修改gc参数
// 第一个参数是回收垃圾的代
int gc_heap::garbage_collect (int n)
{
// 枚举线程
// - 统计目前用的分配上下文数量
// - 在分配上下文的alloc_ptr和limit之间创建free object
// - 设置所有分配上下文的alloc_ptr和limit到0
//reset the number of alloc contexts
alloc_contexts_used = 0;
fix_allocation_contexts (TRUE);
// 清理在gen 0范围的brick table
// brick table将在下面解释
#ifdef MULTIPLE_HEAPS
clear_gen0_bricks();
#endif //MULTIPLE_HEAPS
// 如果开始了NoGCRegion,并且disallowFullBlockingGC等于true,则跳过这次GC
// https://msdn.microsoft.com/en-us/library/dn906204(v=vs.110).aspx
if ((settings.pause_mode == pause_no_gc) && current_no_gc_region_info.minimal_gc_p)
{
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_minimal_gc);
if (gc_t_join.joined())
{
#endif //MULTIPLE_HEAPS
#ifdef MULTIPLE_HEAPS
// this is serialized because we need to get a segment
for (int i = 0; i < n_heaps; i++)
{
if (!(g_heaps[i]->expand_soh_with_minimal_gc()))
current_no_gc_region_info.start_status = start_no_gc_no_memory;
}
#else
if (!expand_soh_with_minimal_gc())
current_no_gc_region_info.start_status = start_no_gc_no_memory;
#endif //MULTIPLE_HEAPS
update_collection_counts_for_no_gc();
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
goto done;
}
// 清空gc_data_per_heap和fgm_result
init_records();
memset (&fgm_result, 0, sizeof (fgm_result));
// 设置收集理由到settings成员中
// settings成员的类型是gc_mechanisms, 里面的值已在前面初始化过,将会贯穿整个gc过程使用
settings.reason = gc_trigger_reason;
verify_pinned_queue_p = FALSE;
#if defined(ENABLE_PERF_COUNTERS) || defined(FEATURE_EVENT_TRACE)
num_pinned_objects = 0;
#endif //ENABLE_PERF_COUNTERS || FEATURE_EVENT_TRACE
#ifdef STRESS_HEAP
if (settings.reason == reason_gcstress)
{
settings.reason = reason_induced;
settings.stress_induced = TRUE;
}
#endif // STRESS_HEAP
#ifdef MULTIPLE_HEAPS
// 根据环境重新决定应该收集的代
// 这里的处理比较杂,大概包括了以下的处理
// - 备份dd_new_allocation到dd_gc_new_allocation
// - 必要时修改收集的代, 例如最大代的阈值用完或者需要低延迟的时候
// - 必要时设置settings.promotion = true (启用对象升代, 例如代0对象gc后变代1)
// - 算法是 通过卡片标记的对象 / 通过卡片扫描的对象 < 30% 则启用对象升代(dt_low_card_table_efficiency_p)
// - 这个比例储存在`generation_skip_ratio`中
// - Card Table将在下面解释,意义是如果前一代的对象不够多则需要把后一代的对象升代
//align all heaps on the max generation to condemn
dprintf (3, ("Joining for max generation to condemn"));
condemned_generation_num = generation_to_condemn (n,
&blocking_collection,
&elevation_requested,
FALSE);
gc_t_join.join(this, gc_join_generation_determined);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
// 判断是否要打印更多的除错信息,除错用
#ifdef TRACE_GC
int gc_count = (int)dd_collection_count (dynamic_data_of (0));
if (gc_count >= g_pConfig->GetGCtraceStart())
trace_gc = 1;
if (gc_count >= g_pConfig->GetGCtraceEnd())
trace_gc = 0;
#endif //TRACE_GC
// 复制(合并)各个heap的card table和brick table到全局
#ifdef MULTIPLE_HEAPS
#if !defined(SEG_MAPPING_TABLE) && !defined(FEATURE_BASICFREEZE)
// 释放已删除的segment索引的节点
//delete old slots from the segment table
seg_table->delete_old_slots();
#endif //!SEG_MAPPING_TABLE && !FEATURE_BASICFREEZE
for (int i = 0; i < n_heaps; i++)
{
//copy the card and brick tables
if (g_card_table != g_heaps[i]->card_table)
{
g_heaps[i]->copy_brick_card_table();
}
g_heaps[i]->rearrange_large_heap_segments();
if (!recursive_gc_sync::background_running_p())
{
g_heaps[i]->rearrange_small_heap_segments();
}
}
#else //MULTIPLE_HEAPS
#ifdef BACKGROUND_GC
//delete old slots from the segment table
#if !defined(SEG_MAPPING_TABLE) && !defined(FEATURE_BASICFREEZE)
// 释放已删除的segment索引的节点
seg_table->delete_old_slots();
#endif //!SEG_MAPPING_TABLE && !FEATURE_BASICFREEZE
// 删除空segment
rearrange_large_heap_segments();
if (!recursive_gc_sync::background_running_p())
{
rearrange_small_heap_segments();
}
#endif //BACKGROUND_GC
// check for card table growth
if (g_card_table != card_table)
copy_brick_card_table();
#endif //MULTIPLE_HEAPS
// 合并各个heap的elevation_requested和blocking_collection选项
BOOL should_evaluate_elevation = FALSE;
BOOL should_do_blocking_collection = FALSE;
#ifdef MULTIPLE_HEAPS
int gen_max = condemned_generation_num;
for (int i = 0; i < n_heaps; i++)
{
if (gen_max < g_heaps[i]->condemned_generation_num)
gen_max = g_heaps[i]->condemned_generation_num;
if ((!should_evaluate_elevation) && (g_heaps[i]->elevation_requested))
should_evaluate_elevation = TRUE;
if ((!should_do_blocking_collection) && (g_heaps[i]->blocking_collection))
should_do_blocking_collection = TRUE;
}
settings.condemned_generation = gen_max;
//logically continues after GC_PROFILING.
#else //MULTIPLE_HEAPS
// 单gc_heap(工作站GC)时的处理
// 根据环境重新决定应该收集的代,解释看上面
settings.condemned_generation = generation_to_condemn (n,
&blocking_collection,
&elevation_requested,
FALSE);
should_evaluate_elevation = elevation_requested;
should_do_blocking_collection = blocking_collection;
#endif //MULTIPLE_HEAPS
settings.condemned_generation = joined_generation_to_condemn (
should_evaluate_elevation,
settings.condemned_generation,
&should_do_blocking_collection
STRESS_HEAP_ARG(n)
);
STRESS_LOG1(LF_GCROOTS|LF_GC|LF_GCALLOC, LL_INFO10,
"condemned generation num: %d\n", settings.condemned_generation);
record_gcs_during_no_gc();
// 如果收集代大于1(目前只有2,也就是full gc)则启用对象升代
if (settings.condemned_generation > 1)
settings.promotion = TRUE;
#ifdef HEAP_ANALYZE
// At this point we've decided what generation is condemned
// See if we've been requested to analyze survivors after the mark phase
if (AnalyzeSurvivorsRequested(settings.condemned_generation))
{
heap_analyze_enabled = TRUE;
}
#endif // HEAP_ANALYZE
// 统计GC性能的处理,这里不分析
#ifdef GC_PROFILING
// If we're tracking GCs, then we need to walk the first generation
// before collection to track how many items of each class has been
// allocated.
UpdateGenerationBounds();
GarbageCollectionStartedCallback(settings.condemned_generation, settings.reason == reason_induced);
{
BEGIN_PIN_PROFILER(CORProfilerTrackGC());
size_t profiling_context = 0;
#ifdef MULTIPLE_HEAPS
int hn = 0;
for (hn = 0; hn < gc_heap::n_heaps; hn++)
{
gc_heap* hp = gc_heap::g_heaps [hn];
// When we're walking objects allocated by class, then we don't want to walk the large
// object heap because then it would count things that may have been around for a while.
hp->walk_heap (&AllocByClassHelper, (void *)&profiling_context, 0, FALSE);
}
#else
// When we're walking objects allocated by class, then we don't want to walk the large
// object heap because then it would count things that may have been around for a while.
gc_heap::walk_heap (&AllocByClassHelper, (void *)&profiling_context, 0, FALSE);
#endif //MULTIPLE_HEAPS
// Notify that we've reached the end of the Gen 0 scan
g_profControlBlock.pProfInterface->EndAllocByClass(&profiling_context);
END_PIN_PROFILER();
}
#endif // GC_PROFILING
// 后台GC的处理,这里不分析
#ifdef BACKGROUND_GC
if ((settings.condemned_generation == max_generation) &&
(recursive_gc_sync::background_running_p()))
{
//TODO BACKGROUND_GC If we just wait for the end of gc, it won't woork
// because we have to collect 0 and 1 properly
// in particular, the allocation contexts are gone.
// For now, it is simpler to collect max_generation-1
settings.condemned_generation = max_generation - 1;
dprintf (GTC_LOG, ("bgc - 1 instead of 2"));
}
if ((settings.condemned_generation == max_generation) &&
(should_do_blocking_collection == FALSE) &&
gc_can_use_concurrent &&
!temp_disable_concurrent_p &&
((settings.pause_mode == pause_interactive) || (settings.pause_mode == pause_sustained_low_latency)))
{
keep_bgc_threads_p = TRUE;
c_write (settings.concurrent, TRUE);
}
#endif //BACKGROUND_GC
// 当前gc的标识序号(会在gc1 => update_collection_counts函数里面更新)
settings.gc_index = (uint32_t)dd_collection_count (dynamic_data_of (0)) + 1;
// 通知运行引擎GC开始工作
// 这里会做出一些处理例如释放JIT中已删除的HostCodeHeap的内存
// Call the EE for start of GC work
// just one thread for MP GC
GCToEEInterface::GcStartWork (settings.condemned_generation,
max_generation);
// TODO: we could fire an ETW event to say this GC as a concurrent GC but later on due to not being able to
// create threads or whatever, this could be a non concurrent GC. Maybe for concurrent GC we should fire
// it in do_background_gc and if it failed to be a CGC we fire it in gc1... in other words, this should be
// fired in gc1.
// 更新一些统计用计数器和数据
do_pre_gc();
// 继续(唤醒)后台GC线程
#ifdef MULTIPLE_HEAPS
gc_start_event.Reset();
//start all threads on the roots.
dprintf(3, ("Starting all gc threads for gc"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 更新统计数据
{
int gen_num_for_data = max_generation + 1;
for (int i = 0; i <= gen_num_for_data; i++)
{
gc_data_per_heap.gen_data[i].size_before = generation_size (i);
generation* gen = generation_of (i);
gc_data_per_heap.gen_data[i].free_list_space_before = generation_free_list_space (gen);
gc_data_per_heap.gen_data[i].free_obj_space_before = generation_free_obj_space (gen);
}
}
// 打印出错信息
descr_generations (TRUE);
// descr_card_table();
// 如果不使用Write Barrier而是Write Watch时则需要更新Card Table
// 默认windows和linux编译的CoreCLR都会使用Write Barrier
// Write Barrier和Card Table将在下面解释
#ifdef NO_WRITE_BARRIER
fix_card_table();
#endif //NO_WRITE_BARRIER
// 检查gc_heap的状态,除错用
#ifdef VERIFY_HEAP
if ((g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC) &&
!(g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_POST_GC_ONLY))
{
verify_heap (TRUE);
}
if (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_BARRIERCHECK)
checkGCWriteBarrier();
#endif // VERIFY_HEAP
// 调用GC的主函数`gc1`
// 后台GC的处理我在这一篇中将不会解释,希望以后可以专门写一篇解释后台GC
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
// We need to save the settings because we'll need to restore it after each FGC.
assert (settings.condemned_generation == max_generation);
settings.compaction = FALSE;
saved_bgc_settings = settings;
#ifdef MULTIPLE_HEAPS
if (heap_number == 0)
{
for (int i = 0; i < n_heaps; i++)
{
prepare_bgc_thread (g_heaps[i]);
}
dprintf (2, ("setting bgc_threads_sync_event"));
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
prepare_bgc_thread(0);
#endif //MULTIPLE_HEAPS
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_start_bgc);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
do_concurrent_p = TRUE;
do_ephemeral_gc_p = FALSE;
#ifdef MULTIPLE_HEAPS
dprintf(2, ("Joined to perform a background GC"));
for (int i = 0; i < n_heaps; i++)
{
gc_heap* hp = g_heaps[i];
if (!(hp->bgc_thread) || !hp->commit_mark_array_bgc_init (hp->mark_array))
{
do_concurrent_p = FALSE;
break;
}
else
{
hp->background_saved_lowest_address = hp->lowest_address;
hp->background_saved_highest_address = hp->highest_address;
}
}
#else
do_concurrent_p = (!!bgc_thread && commit_mark_array_bgc_init (mark_array));
if (do_concurrent_p)
{
background_saved_lowest_address = lowest_address;
background_saved_highest_address = highest_address;
}
#endif //MULTIPLE_HEAPS
if (do_concurrent_p)
{
#ifdef FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
SoftwareWriteWatch::EnableForGCHeap();
#endif //FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
g_heaps[i]->current_bgc_state = bgc_initialized;
#else
current_bgc_state = bgc_initialized;
#endif //MULTIPLE_HEAPS
int gen = check_for_ephemeral_alloc();
// always do a gen1 GC before we start BGC.
// This is temporary for testing purpose.
//int gen = max_generation - 1;
dont_restart_ee_p = TRUE;
if (gen == -1)
{
// If we decide to not do a GC before the BGC we need to
// restore the gen0 alloc context.
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
{
generation_allocation_pointer (g_heaps[i]->generation_of (0)) = 0;
generation_allocation_limit (g_heaps[i]->generation_of (0)) = 0;
}
#else
generation_allocation_pointer (youngest_generation) = 0;
generation_allocation_limit (youngest_generation) = 0;
#endif //MULTIPLE_HEAPS
}
else
{
do_ephemeral_gc_p = TRUE;
settings.init_mechanisms();
settings.condemned_generation = gen;
settings.gc_index = (size_t)dd_collection_count (dynamic_data_of (0)) + 2;
do_pre_gc();
// TODO BACKGROUND_GC need to add the profiling stuff here.
dprintf (GTC_LOG, ("doing gen%d before doing a bgc", gen));
}
//clear the cards so they don't bleed in gen 1 during collection
// shouldn't this always be done at the beginning of any GC?
//clear_card_for_addresses (
// generation_allocation_start (generation_of (0)),
// heap_segment_allocated (ephemeral_heap_segment));
if (!do_ephemeral_gc_p)
{
do_background_gc();
}
}
else
{
settings.compaction = TRUE;
c_write (settings.concurrent, FALSE);
}
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
if (do_concurrent_p)
{
// At this point we are sure we'll be starting a BGC, so save its per heap data here.
// global data is only calculated at the end of the GC so we don't need to worry about
// FGCs overwriting it.
memset (&bgc_data_per_heap, 0, sizeof (bgc_data_per_heap));
memcpy (&bgc_data_per_heap, &gc_data_per_heap, sizeof(gc_data_per_heap));
if (do_ephemeral_gc_p)
{
dprintf (2, ("GC threads running, doing gen%d GC", settings.condemned_generation));
gen_to_condemn_reasons.init();
gen_to_condemn_reasons.set_condition (gen_before_bgc);
gc_data_per_heap.gen_to_condemn_reasons.init (&gen_to_condemn_reasons);
gc1();
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_bgc_after_ephemeral);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
do_post_gc();
#endif //MULTIPLE_HEAPS
settings = saved_bgc_settings;
assert (settings.concurrent);
do_background_gc();
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
}
}
else
{
dprintf (2, ("couldn't create BGC threads, reverting to doing a blocking GC"));
gc1();
}
}
else
#endif //BACKGROUND_GC
{
gc1();
}
#ifndef MULTIPLE_HEAPS
allocation_running_time = (size_t)GCToOSInterface::GetLowPrecisionTimeStamp();
allocation_running_amount = dd_new_allocation (dynamic_data_of (0));
fgn_last_alloc = dd_new_allocation (dynamic_data_of (0));
#endif //MULTIPLE_HEAPS
done:
if (settings.pause_mode == pause_no_gc)
allocate_for_no_gc_after_gc();
int gn = settings.condemned_generation;
return gn;
}GC的主函数
GC的主函数是gc1,包含了GC中最关键的处理,也是这一篇中需要重点讲解的部分。
gc1中的总体流程在BOTR文档已经有初步的介绍:
- 首先是
mark phase,标记存活的对象 - 然后是
plan phase,决定要压缩还是要清扫 - 如果要压缩则进入
relocate phase和compact phase - 如果要清扫则进入
sweep phase
在看具体的代码之前让我们一起复习之前讲到的Object的结构

GC使用其中的2个bit来保存标记(marked)和固定(pinned)
标记(marked)表示对象是存活的,不应该被收集,储存在MethodTable指针 & 1中固定(pinned)表示对象不能被移动(压缩时不要移动这个对象), 储存在对象头 & 0x20000000中
这两个bit会在mark_phase中被标记,在plan_phase中被清除,不会残留到GC结束后
再复习堆段(heap segment)的结构
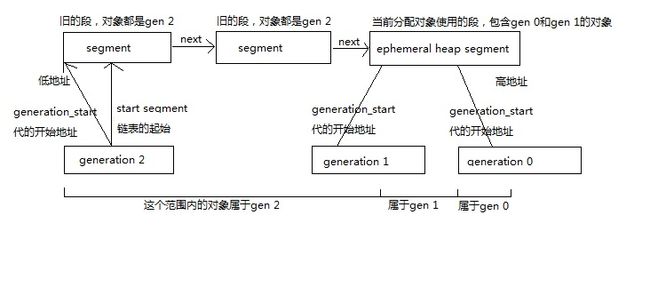
一个gc_heap中有两个segment链表,一个是小对象(gen 0~gen 2)用的链表,一个是大对象(gen 3)用的链表,
其中链表的最后一个节点是ephemeral heap segment,只用来保存gen 0和gen 1的对象,各个代都有一个开始地址,在开始地址之后的对象属于这个代或更年轻的代。
gc_heap::gc1函数的代码如下
//internal part of gc used by the serial and concurrent version
void gc_heap::gc1()
{
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#endif //BACKGROUND_GC
// 开始统计各个阶段的时间,这些是全局变量
#ifdef TIME_GC
mark_time = plan_time = reloc_time = compact_time = sweep_time = 0;
#endif //TIME_GC
// 验证小对象的segment列表(gen0~2的segment),除错用
verify_soh_segment_list();
int n = settings.condemned_generation;
// gc的标识序号+1
update_collection_counts ();
// 调用mark_phase和plan_phase(包括relocate, compact, sweep)
// 后台GC这一篇不解释,请跳到#endif //BACKGROUND_GC
#ifdef BACKGROUND_GC
bgc_alloc_lock->check();
#endif //BACKGROUND_GC
// 打印除错信息
free_list_info (max_generation, "beginning");
// 设置当前收集代
vm_heap->GcCondemnedGeneration = settings.condemned_generation;
assert (g_card_table == card_table);
{
// 设置收集范围
// 如果收集gen 2则从最小的地址一直到最大的地址
// 否则从收集代的开始地址一直到短暂的堆段(ephemeral heap segment)的预留地址
if (n == max_generation)
{
gc_low = lowest_address;
gc_high = highest_address;
}
else
{
gc_low = generation_allocation_start (generation_of (n));
gc_high = heap_segment_reserved (ephemeral_heap_segment);
}
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
#ifdef TRACE_GC
time_bgc_last = GetHighPrecisionTimeStamp();
#endif //TRACE_GC
fire_bgc_event (BGCBegin);
concurrent_print_time_delta ("BGC");
//#ifdef WRITE_WATCH
//reset_write_watch (FALSE);
//#endif //WRITE_WATCH
concurrent_print_time_delta ("RW");
background_mark_phase();
free_list_info (max_generation, "after mark phase");
background_sweep();
free_list_info (max_generation, "after sweep phase");
}
else
#endif //BACKGROUND_GC
{
// 调用mark_phase标记存活的对象
// 请看下面的详解
mark_phase (n, FALSE);
// 设置对象结构有可能不合法,因为plan_phase中可能会对对象做出临时性的破坏
GCScan::GcRuntimeStructuresValid (FALSE);
// 调用plan_phase计划是否要压缩还是清扫
// 这个函数内部会完成压缩或者清扫,请看下面的详解
plan_phase (n);
// 重新设置对象结构合法
GCScan::GcRuntimeStructuresValid (TRUE);
}
}
// 记录gc结束时间
size_t end_gc_time = GetHighPrecisionTimeStamp();
// printf ("generation: %d, elapsed time: %Id\n", n, end_gc_time - dd_time_clock (dynamic_data_of (0)));
// 调整generation_pinned_allocated(固定对象的大小)和generation_allocation_size(分配的大小)
//adjust the allocation size from the pinned quantities.
for (int gen_number = 0; gen_number <= min (max_generation,n+1); gen_number++)
{
generation* gn = generation_of (gen_number);
if (settings.compactin)
{
generation_pinned_allocated (gn) += generation_pinned_allocation_compact_size (gn);
generation_allocation_size (generation_of (gen_number)) += generation_pinned_allocation_compact_size (gn);
}
else
{
generation_pinned_allocated (gn) += generation_pinned_allocation_sweep_size (gn);
generation_allocation_size (generation_of (gen_number)) += generation_pinned_allocation_sweep_size (gn);
}
generation_pinned_allocation_sweep_size (gn) = 0;
generation_pinned_allocation_compact_size (gn) = 0;
}
// 更新gc_data_per_heap, 和打印除错信息
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
dynamic_data* dd = dynamic_data_of (n);
dd_gc_elapsed_time (dd) = end_gc_time - dd_time_clock (dd);
free_list_info (max_generation, "after computing new dynamic data");
gc_history_per_heap* current_gc_data_per_heap = get_gc_data_per_heap();
for (int gen_number = 0; gen_number < max_generation; gen_number++)
{
dprintf (2, ("end of BGC: gen%d new_alloc: %Id",
gen_number, dd_desired_allocation (dynamic_data_of (gen_number))));
current_gc_data_per_heap->gen_data[gen_number].size_after = generation_size (gen_number);
current_gc_data_per_heap->gen_data[gen_number].free_list_space_after = generation_free_list_space (generation_of (gen_number));
current_gc_data_per_heap->gen_data[gen_number].free_obj_space_after = generation_free_obj_space (generation_of (gen_number));
}
}
else
#endif //BACKGROUND_GC
{
free_list_info (max_generation, "end");
for (int gen_number = 0; gen_number <= n; gen_number++)
{
dynamic_data* dd = dynamic_data_of (gen_number);
dd_gc_elapsed_time (dd) = end_gc_time - dd_time_clock (dd);
compute_new_dynamic_data (gen_number);
}
if (n != max_generation)
{
int gen_num_for_data = ((n < (max_generation - 1)) ? (n + 1) : (max_generation + 1));
for (int gen_number = (n + 1); gen_number <= gen_num_for_data; gen_number++)
{
get_gc_data_per_heap()->gen_data[gen_number].size_after = generation_size (gen_number);
get_gc_data_per_heap()->gen_data[gen_number].free_list_space_after = generation_free_list_space (generation_of (gen_number));
get_gc_data_per_heap()->gen_data[gen_number].free_obj_space_after = generation_free_obj_space (generation_of (gen_number));
}
}
get_gc_data_per_heap()->maxgen_size_info.running_free_list_efficiency = (uint32_t)(generation_allocator_efficiency (generation_of (max_generation)) * 100);
free_list_info (max_generation, "after computing new dynamic data");
if (heap_number == 0)
{
dprintf (GTC_LOG, ("GC#%d(gen%d) took %Idms",
dd_collection_count (dynamic_data_of (0)),
settings.condemned_generation,
dd_gc_elapsed_time (dynamic_data_of (0))));
}
for (int gen_number = 0; gen_number <= (max_generation + 1); gen_number++)
{
dprintf (2, ("end of FGC/NGC: gen%d new_alloc: %Id",
gen_number, dd_desired_allocation (dynamic_data_of (gen_number))));
}
}
// 更新收集代+1代的动态数据(dd)
if (n < max_generation)
{
compute_promoted_allocation (1 + n);
dynamic_data* dd = dynamic_data_of (1 + n);
size_t new_fragmentation = generation_free_list_space (generation_of (1 + n)) +
generation_free_obj_space (generation_of (1 + n));
#ifdef BACKGROUND_GC
if (current_c_gc_state != c_gc_state_planning)
#endif //BACKGROUND_GC
{
if (settings.promotion)
{
dd_fragmentation (dd) = new_fragmentation;
}
else
{
//assert (dd_fragmentation (dd) == new_fragmentation);
}
}
}
// 更新ephemeral_low(gen 1的开始的地址)和ephemeral_high(ephemeral_heap_segment的预留地址)
#ifdef BACKGROUND_GC
if (!settings.concurrent)
#endif //BACKGROUND_GC
{
adjust_ephemeral_limits(!!IsGCThread());
}
#ifdef BACKGROUND_GC
assert (ephemeral_low == generation_allocation_start (generation_of ( max_generation -1)));
assert (ephemeral_high == heap_segment_reserved (ephemeral_heap_segment));
#endif //BACKGROUND_GC
// 如果fgn_maxgen_percent有设置并且收集的是代1则检查是否要收集代2, 否则通知full_gc_end_event事件
if (fgn_maxgen_percent)
{
if (settings.condemned_generation == (max_generation - 1))
{
check_for_full_gc (max_generation - 1, 0);
}
else if (settings.condemned_generation == max_generation)
{
if (full_gc_approach_event_set
#ifdef MULTIPLE_HEAPS
&& (heap_number == 0)
#endif //MULTIPLE_HEAPS
)
{
dprintf (2, ("FGN-GC: setting gen2 end event"));
full_gc_approach_event.Reset();
#ifdef BACKGROUND_GC
// By definition WaitForFullGCComplete only succeeds if it's full, *blocking* GC, otherwise need to return N/A
fgn_last_gc_was_concurrent = settings.concurrent ? TRUE : FALSE;
#endif //BACKGROUND_GC
full_gc_end_event.Set();
full_gc_approach_event_set = false;
}
}
}
// 重新决定分配量(allocation_quantum)
// 这里的 dd_new_allocation 已经重新设置过
// 分配量 = 离下次启动gc需要分配的大小 / (2 * 已用的分配上下文数量), 最小1K, 最大8K
// 如果很快就要重新启动gc, 或者用的分配上下文较多(浪费较多), 则需要减少分配量
// 大部分情况下这里的分配量都会设置为默认的8K
#ifdef BACKGROUND_GC
if (!settings.concurrent)
#endif //BACKGROUND_GC
{
//decide on the next allocation quantum
if (alloc_contexts_used >= 1)
{
allocation_quantum = Align (min ((size_t)CLR_SIZE,
(size_t)max (1024, get_new_allocation (0) / (2 * alloc_contexts_used))),
get_alignment_constant(FALSE));
dprintf (3, ("New allocation quantum: %d(0x%Ix)", allocation_quantum, allocation_quantum));
}
}
// 重设Write Watch,默认会用Write barrier所以这里不会被调用
#ifdef NO_WRITE_BARRIER
reset_write_watch(FALSE);
#endif //NO_WRITE_BARRIER
// 打印出错信息
descr_generations (FALSE);
descr_card_table();
// 验证小对象的segment列表(gen0~2的segment),除错用
verify_soh_segment_list();
#ifdef BACKGROUND_GC
add_to_history_per_heap();
if (heap_number == 0)
{
add_to_history();
}
#endif // BACKGROUND_GC
#ifdef GC_STATS
if (GCStatistics::Enabled() && heap_number == 0)
g_GCStatistics.AddGCStats(settings,
dd_gc_elapsed_time(dynamic_data_of(settings.condemned_generation)));
#endif // GC_STATS
#ifdef TIME_GC
fprintf (stdout, "%d,%d,%d,%d,%d,%d\n",
n, mark_time, plan_time, reloc_time, compact_time, sweep_time);
#endif //TIME_GC
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#endif //BACKGROUND_GC
// 检查heap状态,除错用
// 如果是后台gc还需要停止运行引擎,验证完以后再重启
#if defined(VERIFY_HEAP) || (defined (FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC))
if (FALSE
#ifdef VERIFY_HEAP
// Note that right now g_pConfig->GetHeapVerifyLevel always returns the same
// value. If we ever allow randomly adjusting this as the process runs,
// we cannot call it this way as joins need to match - we must have the same
// value for all heaps like we do with bgc_heap_walk_for_etw_p.
|| (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC)
#endif
#if defined(FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC)
|| (bgc_heap_walk_for_etw_p && settings.concurrent)
#endif
)
{
#ifdef BACKGROUND_GC
Thread* current_thread = GetThread();
BOOL cooperative_mode = TRUE;
if (settings.concurrent)
{
cooperative_mode = enable_preemptive (current_thread);
#ifdef MULTIPLE_HEAPS
bgc_t_join.join(this, gc_join_suspend_ee_verify);
if (bgc_t_join.joined())
{
bgc_threads_sync_event.Reset();
dprintf(2, ("Joining BGC threads to suspend EE for verify heap"));
bgc_t_join.restart();
}
if (heap_number == 0)
{
suspend_EE();
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
suspend_EE();
#endif //MULTIPLE_HEAPS
//fix the allocation area so verify_heap can proceed.
fix_allocation_contexts (FALSE);
}
#endif //BACKGROUND_GC
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#ifdef FEATURE_EVENT_TRACE
if (bgc_heap_walk_for_etw_p && settings.concurrent)
{
make_free_lists_for_profiler_for_bgc();
}
#endif // FEATURE_EVENT_TRACE
#endif //BACKGROUND_GC
#ifdef VERIFY_HEAP
if (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC)
verify_heap (FALSE);
#endif // VERIFY_HEAP
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
repair_allocation_contexts (TRUE);
#ifdef MULTIPLE_HEAPS
bgc_t_join.join(this, gc_join_restart_ee_verify);
if (bgc_t_join.joined())
{
bgc_threads_sync_event.Reset();
dprintf(2, ("Joining BGC threads to restart EE after verify heap"));
bgc_t_join.restart();
}
if (heap_number == 0)
{
restart_EE();
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
restart_EE();
#endif //MULTIPLE_HEAPS
disable_preemptive (current_thread, cooperative_mode);
}
#endif //BACKGROUND_GC
}
#endif // defined(VERIFY_HEAP) || (defined(FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC))
// 如果有多个heap(服务器GC),平均各个heap的阈值(dd_gc_new_allocation, dd_new_allocation, dd_desired_allocation)
// 其他服务器GC和工作站GC的共通处理请跳到#else看
#ifdef MULTIPLE_HEAPS
if (!settings.concurrent)
{
gc_t_join.join(this, gc_join_done);
if (gc_t_join.joined ())
{
gc_heap::internal_gc_done = false;
//equalize the new desired size of the generations
int limit = settings.condemned_generation;
if (limit == max_generation)
{
limit = max_generation+1;
}
for (int gen = 0; gen <= limit; gen++)
{
size_t total_desired = 0;
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
dynamic_data* dd = hp->dynamic_data_of (gen);
size_t temp_total_desired = total_desired + dd_desired_allocation (dd);
if (temp_total_desired < total_desired)
{
// we overflowed.
total_desired = (size_t)MAX_PTR;
break;
}
total_desired = temp_total_desired;
}
size_t desired_per_heap = Align (total_desired/gc_heap::n_heaps,
get_alignment_constant ((gen != (max_generation+1))));
if (gen == 0)
{
#if 1 //subsumed by the linear allocation model
// to avoid spikes in mem usage due to short terms fluctuations in survivorship,
// apply some smoothing.
static size_t smoothed_desired_per_heap = 0;
size_t smoothing = 3; // exponential smoothing factor
if (smoothing > VolatileLoad(&settings.gc_index))
smoothing = VolatileLoad(&settings.gc_index);
smoothed_desired_per_heap = desired_per_heap / smoothing + ((smoothed_desired_per_heap / smoothing) * (smoothing-1));
dprintf (1, ("sn = %Id n = %Id", smoothed_desired_per_heap, desired_per_heap));
desired_per_heap = Align(smoothed_desired_per_heap, get_alignment_constant (true));
#endif //0
// if desired_per_heap is close to min_gc_size, trim it
// down to min_gc_size to stay in the cache
gc_heap* hp = gc_heap::g_heaps[0];
dynamic_data* dd = hp->dynamic_data_of (gen);
size_t min_gc_size = dd_min_gc_size(dd);
// if min GC size larger than true on die cache, then don't bother
// limiting the desired size
if ((min_gc_size <= GCToOSInterface::GetLargestOnDieCacheSize(TRUE) / GCToOSInterface::GetLogicalCpuCount()) &&
desired_per_heap <= 2*min_gc_size)
{
desired_per_heap = min_gc_size;
}
#ifdef BIT64
desired_per_heap = joined_youngest_desired (desired_per_heap);
dprintf (2, ("final gen0 new_alloc: %Id", desired_per_heap));
#endif // BIT64
gc_data_global.final_youngest_desired = desired_per_heap;
}
#if 1 //subsumed by the linear allocation model
if (gen == (max_generation + 1))
{
// to avoid spikes in mem usage due to short terms fluctuations in survivorship,
// apply some smoothing.
static size_t smoothed_desired_per_heap_loh = 0;
size_t smoothing = 3; // exponential smoothing factor
size_t loh_count = dd_collection_count (dynamic_data_of (max_generation));
if (smoothing > loh_count)
smoothing = loh_count;
smoothed_desired_per_heap_loh = desired_per_heap / smoothing + ((smoothed_desired_per_heap_loh / smoothing) * (smoothing-1));
dprintf( 2, ("smoothed_desired_per_heap_loh = %Id desired_per_heap = %Id", smoothed_desired_per_heap_loh, desired_per_heap));
desired_per_heap = Align(smoothed_desired_per_heap_loh, get_alignment_constant (false));
}
#endif //0
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
dynamic_data* dd = hp->dynamic_data_of (gen);
dd_desired_allocation (dd) = desired_per_heap;
dd_gc_new_allocation (dd) = desired_per_heap;
dd_new_allocation (dd) = desired_per_heap;
if (gen == 0)
{
hp->fgn_last_alloc = desired_per_heap;
}
}
}
#ifdef FEATURE_LOH_COMPACTION
BOOL all_heaps_compacted_p = TRUE;
#endif //FEATURE_LOH_COMPACTION
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
hp->decommit_ephemeral_segment_pages();
hp->rearrange_large_heap_segments();
#ifdef FEATURE_LOH_COMPACTION
all_heaps_compacted_p &= hp->loh_compacted_p;
#endif //FEATURE_LOH_COMPACTION
}
#ifdef FEATURE_LOH_COMPACTION
check_loh_compact_mode (all_heaps_compacted_p);
#endif //FEATURE_LOH_COMPACTION
fire_pevents();
gc_t_join.restart();
}
alloc_context_count = 0;
heap_select::mark_heap (heap_number);
}
#else
// 以下处理服务器GC和工作站共通,你可以在#else上面找到对应的代码
// 设置统计数据(最年轻代的gc阈值)
gc_data_global.final_youngest_desired =
dd_desired_allocation (dynamic_data_of (0));
// 如果大对象的堆(loh)压缩模式是仅1次(once)且所有heap的loh都压缩过则重置loh的压缩模式
check_loh_compact_mode (loh_compacted_p);
// 释放ephemeral segment中未用到的内存(页)
decommit_ephemeral_segment_pages();
// 触发etw事件,统计用
fire_pevents();
if (!(settings.concurrent))
{
// 删除空的大对象segment
rearrange_large_heap_segments();
// 通知运行引擎GC已完成(GcDone, 目前不会做出实质的处理)并且更新一些统计数据
do_post_gc();
}
#ifdef BACKGROUND_GC
recover_bgc_settings();
#endif //BACKGROUND_GC
#endif //MULTIPLE_HEAPS
}接下来我们将分别分析GC中的五个阶段(mark_phase, plan_phase, relocate_phase, compact_phase, sweep_phase)的内部处理
标记阶段(mark_phase)
这个阶段的作用是找出收集垃圾的范围(gc_low ~ gc_high)中有哪些对象是存活的,如果存活则标记(m_pMethTab |= 1),
另外还会根据GC Handle查找有哪些对象是固定的(pinned),如果对象固定则标记(m_uSyncBlockValue |= 0x20000000)。
简单解释下GC Handle和Pinned Object,GC Handle用于在托管代码中调用非托管代码时可以决定传递的指针的处理,
一个类型是Pinned的GC Handle可以防止GC在压缩时移动对象,这样非托管代码中保存的指针地址不会失效,详细可以看微软的文档。
在继续看代码之前我们先来了解Card Table的概念:
Card Table
如果你之前已经了解过GC,可能知道有的语言实现GC会有一个根对象,从根对象一直扫描下去可以找到所有存活的对象。
但这样有一个缺陷,如果对象很多,扫描的时间也会相应的变长,为了提高效率,CoreCLR使用了分代GC(包括之前的.Net Framework都是分代GC),
分代GC可以只选择扫描一部分的对象(年轻的对象更有可能被回收)而不是全部对象,那么分代GC的扫描是如何实现的?
在CoreCLR中对象之间的引用(例如B是A的成员或者B在数组A中,可以称作A引用B)一般包含以下情况
- 各个线程栈(stack)和寄存器(register)中的对象引用堆段(heap segment)中的对象
- CoreCLR有办法可以检测到Managed Thread中在栈和寄存器中的对象
- 这些对象是根对象(GC Root)的一种
- GC Handle表中的句柄引用堆段(heap segment)中的对象
- 这些对象也是根对象的一种
- 析构队列中的对象引用堆段(heap segment)中的对象
- 这些对象也是根对象的一种
- 同代对象之间的引用
- 隔代对象之间的引用
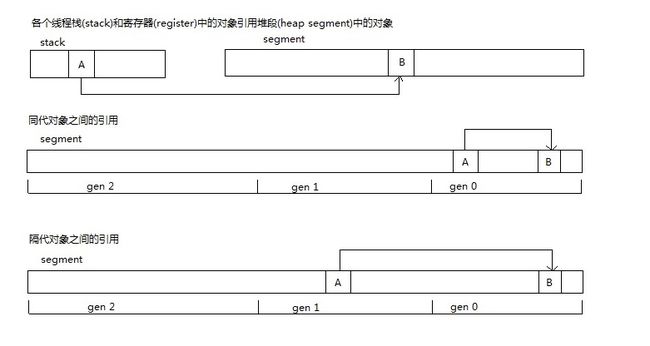
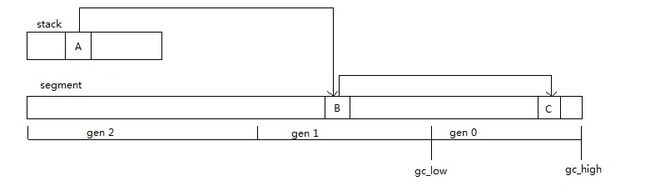
请考虑下图的情况,我们这次只想扫描gen 0,栈中的对象A引用了gen 1的对象B,对象B引用了gen 0的对象C,
在扫描的时候因为B不在扫描范围(gc_low ~ gc_high)中,CoreCLR不会去继续跟踪B的引用,
如果这时候gen 0中无其他对象引用对象C,是否会导致对象C被误回收?
为了解决这种情况导致的问题,CoreCLR使用了Card Table,所谓Card Table就是专门记录跨代引用的一个数组
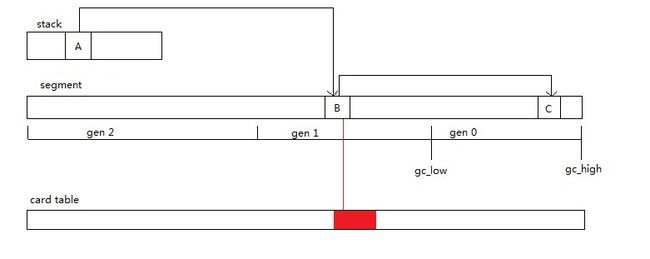
当我们设置B.member = C的时候,JIT会把赋值替换为JIT_WriteBarrier(&B.member, C)(或同等的其他函数)
JIT_WriteBarrier函数中会设置*dst = ref,并且如果ref在ephemeral heap segment中(ref可能是gen 0或gen 1的对象)时,
设置dst在Card Table中所属的字节为0xff,Card Table中一个字节默认涵盖的范围在32位下是1024字节,在64位下是2048字节。
需要注意的是这里的dst是B.member的地址而不是B的地址,B.member的地址会是B的地址加一定的偏移值,
而B自身的地址不一定会在Card Table中得到标记,我们之后可以根据B.member的地址得到B的地址(可以看find_first_object函数)。
有了Card Table以后,只回收年轻代(非Full GC)时除了扫描根对象以外我们还需要扫描Card Table中标记的范围来防止误回收对象。
JIT_WriteBarrier函数的代码如下
// This function is a JIT helper, but it must NOT use HCIMPL2 because it
// modifies Thread state that will not be restored if an exception occurs
// inside of memset. A normal EH unwind will not occur.
extern "C" HCIMPL2_RAW(VOID, JIT_WriteBarrier, Object **dst, Object *ref)
{
// Must use static contract here, because if an AV occurs, a normal EH
// unwind will not occur, and destructors will not run.
STATIC_CONTRACT_MODE_COOPERATIVE;
STATIC_CONTRACT_THROWS;
STATIC_CONTRACT_GC_NOTRIGGER;
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
IncUncheckedBarrierCount();
#endif
// no HELPER_METHOD_FRAME because we are MODE_COOPERATIVE, GC_NOTRIGGER
*dst = ref;
// If the store above succeeded, "dst" should be in the heap.
assert(GCHeap::GetGCHeap()->IsHeapPointer((void*)dst));
#ifdef WRITE_BARRIER_CHECK
updateGCShadow(dst, ref); // support debugging write barrier
#endif
#ifdef FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
if (SoftwareWriteWatch::IsEnabledForGCHeap())
{
SoftwareWriteWatch::SetDirty(dst, sizeof(*dst));
}
#endif // FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
if((BYTE*) dst >= g_ephemeral_low && (BYTE*) dst < g_ephemeral_high)
{
UncheckedDestInEphem++;
}
#endif
if((BYTE*) ref >= g_ephemeral_low && (BYTE*) ref < g_ephemeral_high)
{
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
UncheckedAfterRefInEphemFilter++;
#endif
BYTE* pCardByte = (BYTE *)VolatileLoadWithoutBarrier(&g_card_table) + card_byte((BYTE *)dst);
if(*pCardByte != 0xFF)
{
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
UncheckedAfterAlreadyDirtyFilter++;
#endif
*pCardByte = 0xFF;
}
}
}
HCIMPLEND_RAWcard_byte macro的代码如下
#if defined(_WIN64)
// Card byte shift is different on 64bit.
#define card_byte_shift 11
#else
#define card_byte_shift 10
#endif
#define card_byte(addr) (((size_t)(addr)) >> card_byte_shift)
#define card_bit(addr) (1 << ((((size_t)(addr)) >> (card_byte_shift - 3)) & 7))标记阶段(mark_phase)的代码
gc_heap::mark_phase函数的代码如下:
void gc_heap::mark_phase (int condemned_gen_number, BOOL mark_only_p)
{
assert (settings.concurrent == FALSE);
// 扫描上下文
ScanContext sc;
sc.thread_number = heap_number;
sc.promotion = TRUE;
sc.concurrent = FALSE;
dprintf(2,("---- Mark Phase condemning %d ----", condemned_gen_number));
// 是否Full GC
BOOL full_p = (condemned_gen_number == max_generation);
// 统计标记阶段的开始时间
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
// 重置动态数据(dd)
int gen_to_init = condemned_gen_number;
if (condemned_gen_number == max_generation)
{
gen_to_init = max_generation + 1;
}
for (int gen_idx = 0; gen_idx <= gen_to_init; gen_idx++)
{
dynamic_data* dd = dynamic_data_of (gen_idx);
dd_begin_data_size (dd) = generation_size (gen_idx) -
dd_fragmentation (dd) -
Align (size (generation_allocation_start (generation_of (gen_idx))));
dprintf (2, ("begin data size for gen%d is %Id", gen_idx, dd_begin_data_size (dd)));
dd_survived_size (dd) = 0;
dd_pinned_survived_size (dd) = 0;
dd_artificial_pinned_survived_size (dd) = 0;
dd_added_pinned_size (dd) = 0;
#ifdef SHORT_PLUGS
dd_padding_size (dd) = 0;
#endif //SHORT_PLUGS
#if defined (RESPECT_LARGE_ALIGNMENT) || defined (FEATURE_STRUCTALIGN)
dd_num_npinned_plugs (dd) = 0;
#endif //RESPECT_LARGE_ALIGNMENT || FEATURE_STRUCTALIGN
}
#ifdef FFIND_OBJECT
if (gen0_must_clear_bricks > 0)
gen0_must_clear_bricks--;
#endif //FFIND_OBJECT
size_t last_promoted_bytes = 0;
// 重设mark stack
// mark_stack_array在GC各个阶段有不同的用途,在mark phase中的用途是用来标记对象时代替递归防止爆栈
promoted_bytes (heap_number) = 0;
reset_mark_stack();
#ifdef SNOOP_STATS
memset (&snoop_stat, 0, sizeof(snoop_stat));
snoop_stat.heap_index = heap_number;
#endif //SNOOP_STATS
// 启用scable marking时
// 服务器GC上会启用,工作站GC上不会启用
// scable marking这篇中不会分析
#ifdef MH_SC_MARK
if (full_p)
{
//initialize the mark stack
for (int i = 0; i < max_snoop_level; i++)
{
((uint8_t**)(mark_stack_array))[i] = 0;
}
mark_stack_busy() = 1;
}
#endif //MH_SC_MARK
static uint32_t num_sizedrefs = 0;
// scable marking的处理
#ifdef MH_SC_MARK
static BOOL do_mark_steal_p = FALSE;
#endif //MH_SC_MARK
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_begin_mark_phase);
if (gc_t_join.joined())
{
#endif //MULTIPLE_HEAPS
num_sizedrefs = SystemDomain::System()->GetTotalNumSizedRefHandles();
#ifdef MULTIPLE_HEAPS
// scable marking的处理
#ifdef MH_SC_MARK
if (full_p)
{
size_t total_heap_size = get_total_heap_size();
if (total_heap_size > (100 * 1024 * 1024))
{
do_mark_steal_p = TRUE;
}
else
{
do_mark_steal_p = FALSE;
}
}
else
{
do_mark_steal_p = FALSE;
}
#endif //MH_SC_MARK
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
{
// 初始化mark list, full gc时不会使用
#ifdef MARK_LIST
//set up the mark lists from g_mark_list
assert (g_mark_list);
#ifdef MULTIPLE_HEAPS
mark_list = &g_mark_list [heap_number*mark_list_size];
#else
mark_list = g_mark_list;
#endif //MULTIPLE_HEAPS
//dont use the mark list for full gc
//because multiple segments are more complex to handle and the list
//is likely to overflow
if (condemned_gen_number != max_generation)
mark_list_end = &mark_list [mark_list_size-1];
else
mark_list_end = &mark_list [0];
mark_list_index = &mark_list [0];
#endif //MARK_LIST
shigh = (uint8_t*) 0;
slow = MAX_PTR;
//%type% category = quote (mark);
// 如果当前是Full GC并且有类型是SizedRef的GC Handle时把它们作为根对象扫描
// 参考https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/objecthandle.h#L177
// SizedRef是一个非公开类型的GC Handle(其他还有RefCounted),目前还看不到有代码使用
if ((condemned_gen_number == max_generation) && (num_sizedrefs > 0))
{
GCScan::GcScanSizedRefs(GCHeap::Promote, condemned_gen_number, max_generation, &sc);
fire_mark_event (heap_number, ETW::GC_ROOT_SIZEDREF, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_scan_sizedref_done);
if (gc_t_join.joined())
{
dprintf(3, ("Done with marking all sized refs. Starting all gc thread for marking other strong roots"));
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
}
dprintf(3,("Marking Roots"));
// 扫描根对象(各个线程中栈和寄存器中的对象)
// 这里的GcScanRoots是一个高阶函数,会扫描根对象和根对象引用的对象,并对它们调用传入的`GCHeap::Promote`函数
// 在下面的relocate phase还会传入`GCHeap::Relocate`给`GcScanRoots`
// BOTR中有一份专门的文档介绍了如何实现栈扫描,地址是
// https://github.com/dotnet/coreclr/blob/master/Documentation/botr/stackwalking.md
// 这个函数的内部处理要贴代码的话会非常的长,这里我只贴调用流程
// GcScanRoots的处理
// 枚举线程
// 调用 ScanStackRoots(pThread, fn, sc);
// 调用 pThread->StackWalkFrames
// 调用 StackWalkFramesEx
// 使用 StackFrameIterator 枚举栈中的所有帧
// 调用 StackFrameIterator::Next
// 调用 StackFrameIterator::Filter
// 调用 MakeStackwalkerCallback 处理单帧
// 调用 GcStackCrawlCallBack
// 如果 IsFrameless 则调用 EECodeManager::EnumGcRefs
// 调用 GcInfoDecoder::EnumerateLiveSlots
// 调用 GcInfoDecoder::ReportSlotToGC
// 如果是寄存器中的对象则调用 GcInfoDecoder::ReportRegisterToGC
// 如果是栈上的对象则调用 GcInfoDecoder::ReportStackSlotToGC
// 调用 GcEnumObject
// 调用 GCHeap::Promote, 接下来和下面的一样
// 如果 !IsFrameless 则调用 FrameBase::GcScanRoots
// 继承函数的处理 GCFrame::GcScanRoots
// 调用 GCHeap::Promote
// 调用 gc_heap::mark_object_simple
// 调用 gc_mark1, 第一次标记时会返回true
// 调用 CObjectHeader::IsMarked !!(((size_t)RawGetMethodTable()) & GC_MARKED)
// 调用 CObjectHeader::SetMarked RawSetMethodTable((MethodTable *) (((size_t) RawGetMethodTable()) | GC_MARKED));
// 如果对象未被标记过,调用 go_through_object_cl (macro) 枚举对象的所有成员
// 对成员对象调用mark_object_simple1,和mark_object_simple的区别是,mark_object_simple1使用mark_stack_array来循环标记对象
// 使用mark_stack_array代替递归可以防止爆栈
// 注意mark_stack_array也有大小限制,如果超过了(overflow)不会扩展(grow),而是记录并交给下面的GcDhInitialScan处理
GCScan::GcScanRoots(GCHeap::Promote,
condemned_gen_number, max_generation,
&sc);
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_STACK, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
#ifdef BACKGROUND_GC
if (recursive_gc_sync::background_running_p())
{
scan_background_roots (GCHeap::Promote, heap_number, &sc);
}
#endif //BACKGROUND_GC
// 扫描当前关键析构(Critical Finalizer)队列中对象的引用
// 非关键析构队列中的对象会在下面的ScanForFinalization中扫描
// 关于析构队列可以参考这些URL
// https://github.com/dotnet/coreclr/blob/master/Documentation/botr/threading.md
// http://stackoverflow.com/questions/1268525/what-are-the-finalizer-queue-and-controlthreadmethodentry
// http://stackoverflow.com/questions/9030126/why-classes-with-finalizers-need-more-than-one-garbage-collection-cycle
// https://msdn.microsoft.com/en-us/library/system.runtime.constrainedexecution.criticalfinalizerobject(v=vs.110).aspx
// https://msdn.microsoft.com/en-us/library/system.runtime.constrainedexecution(v=vs.110).aspx
#ifdef FEATURE_PREMORTEM_FINALIZATION
dprintf(3, ("Marking finalization data"));
finalize_queue->GcScanRoots(GCHeap::Promote, heap_number, 0);
#endif // FEATURE_PREMORTEM_FINALIZATION
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_FQ, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
// MTHTS
{
// 扫描GC Handle引用的对象
// 如果GC Handle的类型是Pinned同时会设置对象为pinned
// 设置对象为pinned的流程如下
// GCScan::GcScanHandles
// Ref_TracePinningRoots
// HndScanHandlersForGC
// TableScanHandles
// SegmentScanByTypeMap
// BlockScanBlocksEphemeral
// BlockScanBlocksEphemeralWorker
// ScanConsecutiveHandlesWithoutUserData
// PinObject
// GCHeap::Promote(pRef, (ScanContext *)lpl, GC_CALL_PINNED)
// 判断flags包含GC_CALL_PINNED时调用 gc_heap::pin_object
// 如果对象在扫描范围(gc_low ~ gc_high)时调用set_pinned(o)
// GetHeader()->SetGCBit()
// m_uSyncBlockValue |= BIT_SBLK_GC_RESERVE
// 这里会标记包括来源于静态字段的引用
dprintf(3,("Marking handle table"));
GCScan::GcScanHandles(GCHeap::Promote,
condemned_gen_number, max_generation,
&sc);
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_HANDLES, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
}
// 扫描根对象完成了,如果不是Full GC接下来还需要扫描Card Table
// 记录扫描Card Table之前标记的字节数量(存活的字节数量)
#ifdef TRACE_GC
size_t promoted_before_cards = promoted_bytes (heap_number);
#endif //TRACE_GC
// Full GC不需要扫Card Table
dprintf (3, ("before cards: %Id", promoted_before_cards));
if (!full_p)
{
#ifdef CARD_BUNDLE
#ifdef MULTIPLE_HEAPS
if (gc_t_join.r_join(this, gc_r_join_update_card_bundle))
{
#endif //MULTIPLE_HEAPS
// 从Write Watch更新Card Table的索引(Card Bundles)
// 当内存空间过大时,扫描Card Table的效率会变低,使用Card Bundle可以标记Card Table中的哪些区域需要扫描
// 在作者环境的下Card Bundle不启用
update_card_table_bundle ();
#ifdef MULTIPLE_HEAPS
gc_t_join.r_restart();
}
#endif //MULTIPLE_HEAPS
#endif //CARD_BUNDLE
// 标记对象的函数,需要分析时使用特殊的函数
card_fn mark_object_fn = &gc_heap::mark_object_simple;
#ifdef HEAP_ANALYZE
heap_analyze_success = TRUE;
if (heap_analyze_enabled)
{
internal_root_array_index = 0;
current_obj = 0;
current_obj_size = 0;
mark_object_fn = &gc_heap::ha_mark_object_simple;
}
#endif //HEAP_ANALYZE
// 遍历Card Table标记小对象
// 像之前所说的Card Table中对应的区域包含的是成员的地址,不一定包含来源对象的开始地址,find_first_object函数可以支持找到来源对象的开始地址
// 这个函数除了调用mark_object_simple标记找到的对象以外,还会更新`generation_skip_ratio`这个成员,算法如下
// n_gen 通过卡片标记的对象数量, gc_low ~ gc_high
// n_eph 通过卡片扫描的对象数量, 上一代的开始地址 ~ gc_high (cg_pointers_found的累加)
// 表示扫描的对象中有多少%的对象被标记了
// generation_skip_ratio = (n_eph > 400) ? (n_gen * 1.0 / n_eph * 100) : 100
// `generation_skip_ratio`会影响到对象是否升代,请搜索上面关于`generation_skip_ratio`的注释
dprintf(3,("Marking cross generation pointers"));
mark_through_cards_for_segments (mark_object_fn, FALSE);
// 遍历Card Table标记大对象
// 处理和前面一样,只是扫描的范围是大对象的segment
// 这里也会算出generation_skip_ratio,如果算出的generation_skip_ratio比原来的generation_skip_ratio要小则使用算出的值
dprintf(3,("Marking cross generation pointers for large objects"));
mark_through_cards_for_large_objects (mark_object_fn, FALSE);
// 调用通知事件通知有多少字节在这一次被标记
dprintf (3, ("marked by cards: %Id",
(promoted_bytes (heap_number) - promoted_before_cards)));
fire_mark_event (heap_number, ETW::GC_ROOT_OLDER, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
}
}
// scable marking的处理
#ifdef MH_SC_MARK
if (do_mark_steal_p)
{
mark_steal();
}
#endif //MH_SC_MARK
// 处理HNDTYPE_DEPENDENT类型的GC Handle
// 这个GC Handle的意义是保存两个对象primary和secondary,告诉primary引用了secondary
// 如果primary已标记则secondary也会被标记
// 这里还会处理之前发生的mark_stack_array溢出(循环标记对象时子对象过多导致mark_stack_array容不下)
// 这次不一定会完成,下面还会等待线程同步后(服务器GC下)再扫一遍
// Dependent handles need to be scanned with a special algorithm (see the header comment on
// scan_dependent_handles for more detail). We perform an initial scan without synchronizing with other
// worker threads or processing any mark stack overflow. This is not guaranteed to complete the operation
// but in a common case (where there are no dependent handles that are due to be collected) it allows us
// to optimize away further scans. The call to scan_dependent_handles is what will cycle through more
// iterations if required and will also perform processing of any mark stack overflow once the dependent
// handle table has been fully promoted.
GCScan::GcDhInitialScan(GCHeap::Promote, condemned_gen_number, max_generation, &sc);
scan_dependent_handles(condemned_gen_number, &sc, true);
// 通知标记阶段完成扫描根对象(和Card Table)
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for short weak handle scan"));
gc_t_join.join(this, gc_join_null_dead_short_weak);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef HEAP_ANALYZE
heap_analyze_enabled = FALSE;
DACNotifyGcMarkEnd(condemned_gen_number);
#endif // HEAP_ANALYZE
GCToEEInterface::AfterGcScanRoots (condemned_gen_number, max_generation, &sc);
#ifdef MULTIPLE_HEAPS
if (!full_p)
{
// we used r_join and need to reinitialize states for it here.
gc_t_join.r_init();
}
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for short weak handle scan"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 处理HNDTYPE_WEAK_SHORT类型的GC Handle
// 设置未被标记的对象的弱引用(Weak Reference)为null
// 这里传的GCHeap::Promote参数不会被用到
// 下面扫描完非关键析构队列还会扫描HNDTYPE_WEAK_LONG类型的GC Handle,请看下面的注释
// null out the target of short weakref that were not promoted.
GCScan::GcShortWeakPtrScan(GCHeap::Promote, condemned_gen_number, max_generation,&sc);
// MTHTS: keep by single thread
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for finalization"));
gc_t_join.join(this, gc_join_scan_finalization);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for Finalization"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
//Handle finalization.
size_t promoted_bytes_live = promoted_bytes (heap_number);
// 扫描当前非关键析构队列中对象的引用
#ifdef FEATURE_PREMORTEM_FINALIZATION
dprintf (3, ("Finalize marking"));
finalize_queue->ScanForFinalization (GCHeap::Promote, condemned_gen_number, mark_only_p, __this);
#ifdef GC_PROFILING
if (CORProfilerTrackGC())
{
finalize_queue->WalkFReachableObjects (__this);
}
#endif //GC_PROFILING
#endif // FEATURE_PREMORTEM_FINALIZATION
// 再扫一遍HNDTYPE_DEPENDENT类型的GC Handle
// Scan dependent handles again to promote any secondaries associated with primaries that were promoted
// for finalization. As before scan_dependent_handles will also process any mark stack overflow.
scan_dependent_handles(condemned_gen_number, &sc, false);
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for weak pointer deletion"));
gc_t_join.join(this, gc_join_null_dead_long_weak);
if (gc_t_join.joined())
{
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for weak pointer deletion"));
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
// 处理HNDTYPE_WEAK_LONG或HNDTYPE_REFCOUNTED类型的GC Handle
// 设置未被标记的对象的弱引用(Weak Reference)为null
// 这里传的GCHeap::Promote参数不会被用到
// HNDTYPE_WEAK_LONG和HNDTYPE_WEAK_SHORT的区别是,HNDTYPE_WEAK_SHORT会忽略从非关键析构队列的引用而HNDTYPE_WEAK_LONG不会
// null out the target of long weakref that were not promoted.
GCScan::GcWeakPtrScan (GCHeap::Promote, condemned_gen_number, max_generation, &sc);
// 如果使用了mark list并且并行化(服务器GC下)这里会进行排序(如果定义了PARALLEL_MARK_LIST_SORT)
// MTHTS: keep by single thread
#ifdef MULTIPLE_HEAPS
#ifdef MARK_LIST
#ifdef PARALLEL_MARK_LIST_SORT
// unsigned long start = GetCycleCount32();
sort_mark_list();
// printf("sort_mark_list took %u cycles\n", GetCycleCount32() - start);
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
dprintf (3, ("Joining for sync block cache entry scanning"));
gc_t_join.join(this, gc_join_null_dead_syncblk);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
// 删除不再使用的同步索引块,并且设置对应对象的索引值为0
// scan for deleted entries in the syncblk cache
GCScan::GcWeakPtrScanBySingleThread (condemned_gen_number, max_generation, &sc);
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
if (g_fEnableARM)
{
size_t promoted_all_heaps = 0;
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
{
promoted_all_heaps += promoted_bytes (i);
}
#else
promoted_all_heaps = promoted_bytes (heap_number);
#endif //MULTIPLE_HEAPS
// 记录这次标记(存活)的字节数
SystemDomain::RecordTotalSurvivedBytes (promoted_all_heaps);
}
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
#ifdef MULTIPLE_HEAPS
// 以下是服务器GC下的处理
// 如果使用了mark list并且并行化(服务器GC下)这里会进行压缩并排序(如果不定义PARALLEL_MARK_LIST_SORT)
#ifdef MARK_LIST
#ifndef PARALLEL_MARK_LIST_SORT
//compact g_mark_list and sort it.
combine_mark_lists();
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
// 如果之前未决定要升代,这里再给一次机会判断是否要升代
// 算法分析
// dd_min_gc_size是每分配多少byte的对象就触发gc的阈值
// 第0代1倍, 第1代2倍, 再乘以0.1合计
// dd = 上一代的动态数据
// older_gen_size = 上次gc后的对象大小合计 + 从上次gc以来一共新分配了多少byte
// 如果m > 上一代的大小, 或者本次标记的对象大小 > m则启用升代
// 意义是如果上一代过小,或者这次标记(存活)的对象过多则需要升代
//decide on promotion
if (!settings.promotion)
{
size_t m = 0;
for (int n = 0; n <= condemned_gen_number;n++)
{
m += (size_t)(dd_min_gc_size (dynamic_data_of (n))*(n+1)*0.1);
}
for (int i = 0; i < n_heaps; i++)
{
dynamic_data* dd = g_heaps[i]->dynamic_data_of (min (condemned_gen_number +1,
max_generation));
size_t older_gen_size = (dd_current_size (dd) +
(dd_desired_allocation (dd) -
dd_new_allocation (dd)));
if ((m > (older_gen_size)) ||
(promoted_bytes (i) > m))
{
settings.promotion = TRUE;
}
}
}
// scable marking的处理
#ifdef SNOOP_STATS
if (do_mark_steal_p)
{
size_t objects_checked_count = 0;
size_t zero_ref_count = 0;
size_t objects_marked_count = 0;
size_t check_level_count = 0;
size_t busy_count = 0;
size_t interlocked_count = 0;
size_t partial_mark_parent_count = 0;
size_t stolen_or_pm_count = 0;
size_t stolen_entry_count = 0;
size_t pm_not_ready_count = 0;
size_t normal_count = 0;
size_t stack_bottom_clear_count = 0;
for (int i = 0; i < n_heaps; i++)
{
gc_heap* hp = g_heaps[i];
hp->print_snoop_stat();
objects_checked_count += hp->snoop_stat.objects_checked_count;
zero_ref_count += hp->snoop_stat.zero_ref_count;
objects_marked_count += hp->snoop_stat.objects_marked_count;
check_level_count += hp->snoop_stat.check_level_count;
busy_count += hp->snoop_stat.busy_count;
interlocked_count += hp->snoop_stat.interlocked_count;
partial_mark_parent_count += hp->snoop_stat.partial_mark_parent_count;
stolen_or_pm_count += hp->snoop_stat.stolen_or_pm_count;
stolen_entry_count += hp->snoop_stat.stolen_entry_count;
pm_not_ready_count += hp->snoop_stat.pm_not_ready_count;
normal_count += hp->snoop_stat.normal_count;
stack_bottom_clear_count += hp->snoop_stat.stack_bottom_clear_count;
}
fflush (stdout);
printf ("-------total stats-------\n");
printf ("%8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s\n",
"checked", "zero", "marked", "level", "busy", "xchg", "pmparent", "s_pm", "stolen", "nready", "normal", "clear");
printf ("%8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d\n",
objects_checked_count,
zero_ref_count,
objects_marked_count,
check_level_count,
busy_count,
interlocked_count,
partial_mark_parent_count,
stolen_or_pm_count,
stolen_entry_count,
pm_not_ready_count,
normal_count,
stack_bottom_clear_count);
}
#endif //SNOOP_STATS
//start all threads.
dprintf(3, ("Starting all threads for end of mark phase"));
gc_t_join.restart();
#else //MULTIPLE_HEAPS
// 以下是工作站GC下的处理
// 如果之前未决定要升代,这里再给一次机会判断是否要升代
// 算法和前面一样,但是不是乘以0.1而是乘以0.06
//decide on promotion
if (!settings.promotion)
{
size_t m = 0;
for (int n = 0; n <= condemned_gen_number;n++)
{
m += (size_t)(dd_min_gc_size (dynamic_data_of (n))*(n+1)*0.06);
}
dynamic_data* dd = dynamic_data_of (min (condemned_gen_number +1,
max_generation));
size_t older_gen_size = (dd_current_size (dd) +
(dd_desired_allocation (dd) -
dd_new_allocation (dd)));
dprintf (2, ("promotion threshold: %Id, promoted bytes: %Id size n+1: %Id",
m, promoted_bytes (heap_number), older_gen_size));
if ((m > older_gen_size) ||
(promoted_bytes (heap_number) > m))
{
settings.promotion = TRUE;
}
}
#endif //MULTIPLE_HEAPS
}
// 如果使用了mark list并且并行化(服务器GC下)这里会进行归并(如果定义了PARALLEL_MARK_LIST_SORT)
#ifdef MULTIPLE_HEAPS
#ifdef MARK_LIST
#ifdef PARALLEL_MARK_LIST_SORT
// start = GetCycleCount32();
merge_mark_lists();
// printf("merge_mark_lists took %u cycles\n", GetCycleCount32() - start);
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
#endif //MULTIPLE_HEAPS
// 统计标记的对象大小
#ifdef BACKGROUND_GC
total_promoted_bytes = promoted_bytes (heap_number);
#endif //BACKGROUND_GC
promoted_bytes (heap_number) -= promoted_bytes_live;
// 统计标记阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
mark_time = finish - start;
#endif //TIME_GC
dprintf(2,("---- End of mark phase ----"));
}接下来我们看下GCHeap::Promote函数,在plan_phase中扫描到的对象都会调用这个函数进行标记,
这个函数名称虽然叫Promote但是里面只负责对对象进行标记,被标记的对象不一定会升代
void GCHeap::Promote(Object** ppObject, ScanContext* sc, uint32_t flags)
{
THREAD_NUMBER_FROM_CONTEXT;
#ifndef MULTIPLE_HEAPS
const int thread = 0;
#endif //!MULTIPLE_HEAPS
uint8_t* o = (uint8_t*)*ppObject;
if (o == 0)
return;
#ifdef DEBUG_DestroyedHandleValue
// we can race with destroy handle during concurrent scan
if (o == (uint8_t*)DEBUG_DestroyedHandleValue)
return;
#endif //DEBUG_DestroyedHandleValue
HEAP_FROM_THREAD;
gc_heap* hp = gc_heap::heap_of (o);
dprintf (3, ("Promote %Ix", (size_t)o));
// 如果传入的o不一定是对象的开始地址,则需要重新找到o属于的对象
#ifdef INTERIOR_POINTERS
if (flags & GC_CALL_INTERIOR)
{
if ((o < hp->gc_low) || (o >= hp->gc_high))
{
return;
}
if ( (o = hp->find_object (o, hp->gc_low)) == 0)
{
return;
}
}
#endif //INTERIOR_POINTERS
// 启用conservative GC时有可能会对自由对象调用这个函数,这里需要额外判断
#ifdef FEATURE_CONSERVATIVE_GC
// For conservative GC, a value on stack may point to middle of a free object.
// In this case, we don't need to promote the pointer.
if (g_pConfig->GetGCConservative()
&& ((CObjectHeader*)o)->IsFree())
{
return;
}
#endif
// 验证对象是否可以标记,除错用
#ifdef _DEBUG
((CObjectHeader*)o)->ValidatePromote(sc, flags);
#else
UNREFERENCED_PARAMETER(sc);
#endif //_DEBUG
// 如果需要标记对象固定(pinned)则调用`pin_object`
// 请看上面对`PinObject`函数的描述
// `pin_object`函数会设置对象的同步索引块 |= 0x20000000
if (flags & GC_CALL_PINNED)
hp->pin_object (o, (uint8_t**) ppObject, hp->gc_low, hp->gc_high);
// 如果有特殊的设置则20次固定一次对象
#ifdef STRESS_PINNING
if ((++n_promote % 20) == 1)
hp->pin_object (o, (uint8_t**) ppObject, hp->gc_low, hp->gc_high);
#endif //STRESS_PINNING
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
size_t promoted_size_begin = hp->promoted_bytes (thread);
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
// 如果对象在gc范围中则调用`mark_object_simple`
// 如果对象不在gc范围则会跳过,这也是前面提到的需要Card Table的原因
if ((o >= hp->gc_low) && (o < hp->gc_high))
{
hpt->mark_object_simple (&o THREAD_NUMBER_ARG);
}
// 记录标记的大小
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
size_t promoted_size_end = hp->promoted_bytes (thread);
if (g_fEnableARM)
{
if (sc->pCurrentDomain)
{
sc->pCurrentDomain->RecordSurvivedBytes ((promoted_size_end - promoted_size_begin), thread);
}
}
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
STRESS_LOG_ROOT_PROMOTE(ppObject, o, o ? header(o)->GetMethodTable() : NULL);
}再看下mark_object_simple函数
//this method assumes that *po is in the [low. high[ range
void
gc_heap::mark_object_simple (uint8_t** po THREAD_NUMBER_DCL)
{
uint8_t* o = *po;
#ifdef MULTIPLE_HEAPS
#else //MULTIPLE_HEAPS
const int thread = 0;
#endif //MULTIPLE_HEAPS
{
#ifdef SNOOP_STATS
snoop_stat.objects_checked_count++;
#endif //SNOOP_STATS
// gc_mark1会设置对象中指向Method Table的指针 |= 1
// 如果对象是第一次标记会返回true
if (gc_mark1 (o))
{
// 更新gc_heap的成员slow和shigh(已标记对象的最小和最大地址)
// 如果使用了mark list则把对象加到mark list中
m_boundary (o);
// 记录已标记的对象大小
size_t s = size (o);
promoted_bytes (thread) += s;
{
// 枚举对象o的所有成员,包括o自己
go_through_object_cl (method_table(o), o, s, poo,
{
uint8_t* oo = *poo;
// 如果成员在gc扫描范围中则标记该成员
if (gc_mark (oo, gc_low, gc_high))
{
// 如果使用了mark list则把对象加到mark list中
m_boundary (oo);
// 记录已标记的对象大小
size_t obj_size = size (oo);
promoted_bytes (thread) += obj_size;
// 如果成员下还包含其他可以收集的成员,需要进一步标记
// 因为引用的层数可能很多导致爆栈,mark_object_simple1会使用mark_stack_array循环标记对象而不是用递归
if (contain_pointers_or_collectible (oo))
mark_object_simple1 (oo, oo THREAD_NUMBER_ARG);
}
}
);
}
}
}
}经过标记阶段以后,在堆中存活的对象都被设置了marked标记,如果对象是固定的还会被设置pinned标记
接下来是计划阶段plan_phase:
计划阶段(plan_phase)
在这个阶段首先会模拟压缩和构建Brick Table,在模拟完成后判断是否应该进行实际的压缩,
如果进行实际的压缩则进入重定位阶段(relocate_phase)和压缩阶段(compact_phase),否则进入清扫阶段(sweep_phase),
在继续看代码之前我们需要先了解计划阶段如何模拟压缩和什么是Brick Table。
计划阶段如何模拟压缩
计划阶段首先会根据相邻的已标记的对象创建plug,用于加快处理速度和减少需要的内存空间,我们假定一段内存中的对象如下图

计划阶段会为这一段对象创建2个unpinned plug和一个pinned plug:

第一个plug是unpinned plug,包含了对象B, C,不固定地址
第二个plug是pinned plug,包含了对象E, F, G,固定地址
第三个plug是unpinned plug,包含了对象H,不固定地址
各个plug的信息保存在开始地址之前的一段内存中,结构如下
struct plug_and_gap
{
// 在这个plug之前有多少空间是未被标记(可回收)的
ptrdiff_t gap;
// 压缩这个plug中的对象时需要移动的偏移值,一般是负数
ptrdiff_t reloc;
union
{
// 左边节点和右边节点
pair m_pair;
int lr; //for clearing the entire pair in one instruction
};
// 填充对象(防止覆盖同步索引块)
plug m_plug;
};眼尖的会发现上面的图有两个问题
- 对象G不是pinned但是也被归到pinned plug里了
- 这是因为pinned plug会把下一个对象也拉进来防止pinned object的末尾被覆盖,具体请看下面的代码
- 第三个plug把对象G的结尾给覆盖(破坏)了
- 对于这种情况原来的内容会备份到
saved_post_plug中,具体请看下面的代码
- 对于这种情况原来的内容会备份到
多个plug会构建成一棵树,例如上面的三个plug会构建成这样的树:
第一个plug: { gap: 24, reloc: 未定义, m_pair: { left: 0, right: 0 } }
第二个plug: { gap: 132, reloc: 0, m_pair: { left: -356, right: 206 } }
第三个plug: { gap: 24, reloc: 未定义, m_pair: { left: 0, right 0 } }第二个plug的left和right保存的是离子节点plug的偏移值,
第三个plug的gap比较特殊,可能你们会觉得应该是0但是会被设置为24(sizeof(gap_reloc_pair)),这个大小在实际复制第二个plug(compact_plug)的时候会加回来。
当计划阶段找到一个plug的开始时,
如果这个plug是pinned plug则加到mark_stack_array队列中。
当计划阶段找到一个plug的结尾时,
如果这个plug是pinned plug则设置这个plug的大小并移动队列顶部(mark_stack_tos),
否则使用使用函数allocate_in_condemned_generations计算把这个plug移动到前面(压缩)时的偏移值,
allocate_in_condemned_generations的原理请看下图
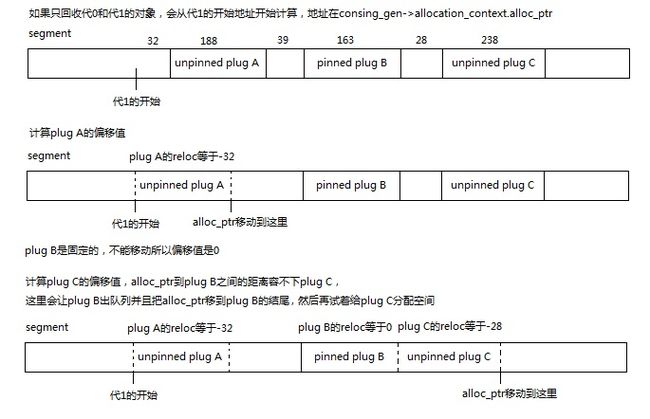
函数allocate_in_condemned_generations不会实际的移动内存和修改指针,它只设置了plug的reloc成员,
这里需要注意的是如果有pinned plug并且前面的空间不够,会从pinned plug的结尾开始计算,
同时出队列以后的plug B在mark_stack_array中的len会被设置为前面一段空间的大小,也就是32+39=71。
现在让我们思考一个问题,如果我们遇到一个对象x,如何求出对象x应该移动到的位置?
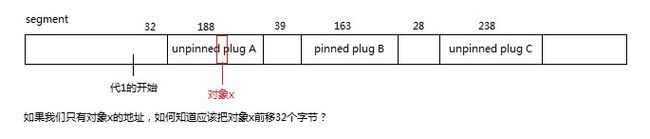
我们需要根据对象x找到它所在的plug,然后根据这个plug的reloc移动,查找plug使用的索引就是接下来要说的Brick Table。
Brick Table
brick_table是一个类型为short*的数组,用于快速索引plug,如图
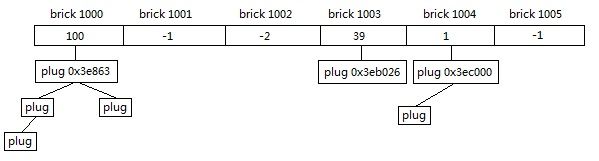
根据所属的brick不同,会构建多个plug树(避免plug树过大),然后设置根节点的信息到brick_table中,
brick中的值如果是正值则表示brick对应的开始地址离根节点plug的偏移值+1,
如果是负值则表示plug树横跨了多个brick,需要到前面的brick查找。
brick_table相关的代码如下,我们可以看到在64位下brick的大小是4096,在32位下brick的大小是2048
#if defined (_TARGET_AMD64_)
#define brick_size ((size_t)4096)
#else
#define brick_size ((size_t)2048)
#endif //_TARGET_AMD64_
inline
size_t gc_heap::brick_of (uint8_t* add)
{
return (size_t)(add - lowest_address) / brick_size;
}
inline
uint8_t* gc_heap::brick_address (size_t brick)
{
return lowest_address + (brick_size * brick);
}
void gc_heap::clear_brick_table (uint8_t* from, uint8_t* end)
{
for (size_t i = brick_of (from);i < brick_of (end); i++)
brick_table[i] = 0;
}
//codes for the brick entries:
//entry == 0 -> not assigned
//entry >0 offset is entry-1
//entry <0 jump back entry bricks
inline
void gc_heap::set_brick (size_t index, ptrdiff_t val)
{
if (val < -32767)
{
val = -32767;
}
assert (val < 32767);
if (val >= 0)
brick_table [index] = (short)val+1;
else
brick_table [index] = (short)val;
}
inline
int gc_heap::brick_entry (size_t index)
{
int val = brick_table [index];
if (val == 0)
{
return -32768;
}
else if (val < 0)
{
return val;
}
else
return val-1;
}brick_table中出现负值的情况是因为plug横跨幅度比较大,超过了单个brick的时候后面的brick就会设为负值,
如果对象地址在上图的1001或1002,查找这个对象对应的plug会从1000的plug树开始。
另外1002中的值不一定需要是-2,-1也是有效的,如果是-1会一直向前查找直到找到正值的brick。
在上面我们提到的问题可以通过brick_table解决,可以看下面relocate_address函数的代码。
brick_table在gc过程中会储存plug树,但是在gc完成后(gc不执行时)会储存各个brick中地址最大的plug,用于给find_first_object等函数定位对象的开始地址使用。
对于Pinned Plug的特殊处理
pinned plug除了会在plug树和brick table中,还会保存在mark_stack_array队列中,类型是mark。
因为unpinned plug和pinned plug相邻会导致原来的内容被plug信息覆盖,mark中还会保存以下的特殊信息
- saved_pre_plug
- 如果这个pinned plug覆盖了上一个unpinned plug的结尾,这里会保存覆盖前的原始内容
- saved_pre_plug_reloc
- 同上,但是这个值用于重定位和压缩阶段(中间会交换)
- saved_post_plug
- 如果这个pinned plug被下一个unpinned plug覆盖了结尾,这里会保存覆盖前的原始内容
- saved_post_plug_reloc
- 同上,但是这个值用于重定位和压缩阶段(中间会交换)
- saved_pre_plug_info_reloc_start
- 被覆盖的saved_pre_plug内容在重定位后的地址,如果重定位未发生则可以直接用(first - sizeof (plug_and_gap))
- saved_post_plug_info_start
- 被覆盖的saved_post_plug内容的地址,注意pinned plug不会被重定位
- saved_pre_p
- 是否保存了saved_pre_plug
- 如果覆盖的内容包含了对象的开头(对象比较小,整个都被覆盖了)
- 这里还会保存对象离各个引用成员的偏移值的bitmap (enque_pinned_plug)
- saved_post_p
- 是否保存了saved_post_p
- 如果覆盖的内容包含了对象的开头(对象比较小,整个都被覆盖了)
- 这里还会保存对象离各个引用成员的偏移值的bitmap (save_post_plug_info)
mark_stack_array中的len意义会在入队和出队时有所改变,
入队时len代表pinned plug的大小,
出队后len代表pinned plug离最后的模拟压缩分配地址的空间(这个空间可以变成free object)。
mark_stack_array
mark_stack_array的结构如下图:
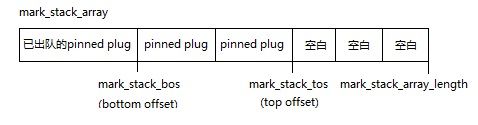
入队时mark_stack_tos增加,出队时mark_stack_bos增加,空间不够时会扩展然后mark_stack_array_length会增加。
计划阶段判断使用压缩(compact)还是清扫(sweep)的依据是什么
计划阶段模拟压缩的时候创建plug,设置reloc等等只是为了接下来的压缩做准备,既不会修改指针地址也不会移动内存。
在做完这些工作之后计划阶段会首先判断应不应该进行压缩,如果不进行压缩而是进行清扫,这些计算结果都会浪费掉。
判断是否使用压缩的根据主要有
- 系统空余空闲是否过少,如果过少触发swap可能会明显的拖低性能,这时候应该尝试压缩
- 碎片空间大小(fragmentation) >= 阈值(dd_fragmentation_limit)
- 碎片空间大小(fragmentation) / 收集代的大小(包括更年轻的代) >= 阈值(dd_fragmentation_burden_limit)
其他还有一些零碎的判断,将在下面的decide_on_compacting函数的代码中讲解。
对象的升代与降代
在很多介绍.Net GC的书籍中都有提到过,经过GC以后对象会升代,例如gen 0中的对象在一次GC后如果存活下来会变为gen 1。
在CoreCLR中,对象的升代需要满足一定条件,某些特殊情况下不会升代,甚至会降代(gen1变为gen0)。
对象升代的条件如下:
- 计划阶段(plan_phase)选择清扫(sweep)时会启用升代
- 入口点(garbage_collect)判断当前是Full GC时会启用升代
dt_low_card_table_efficiency_p成立时会启用升代- 请在前面查找
dt_low_card_table_efficiency_p查看该处的解释
- 请在前面查找
- 计划阶段(plan_phase)判断上一代过小,或者这次标记(存活)的对象过多时启用升代
- 请在后面查找
promoted_bytes (i) > m查看该处的解释
- 请在后面查找
如果升代的条件不满足,则原来在gen 0的对象GC后仍然会在gen 0,
某些特殊条件下还会发生降代,如下图:
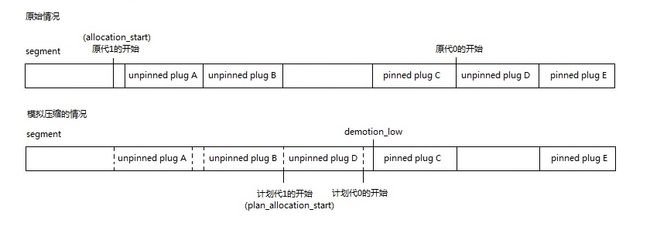
在模拟压缩时,原来在gen 1的对象会归到gen 2(pinned object不一定),原来在gen 0的对象会归到gen 1,
但是如果所有unpinned plug都已经压缩到前面,后面还有残留的pinned plug时,后面残留的pinned plug中的对象则会不升代或者降代,
当这种情况发生时计划阶段会设置demotion_low来标记被降代的范围。
如果最终选择了清扫(sweep)则上图中的情况不会发生。
计划代边界
计划阶段在模拟压缩的时候还会计划代边界(generation::plan_allocation_start),
计划代边界的工作主要在process_ephemeral_boundaries, plan_generation_start, plan_generation_starts函数中完成。
大部分情况下函数process_ephemeral_boundaries会用来计划gen 1的边界,如果不升代这个函数还会计划gen 0的边界,
当判断当前计划的plug大于或等于下一代的边界时,例如大于等于gen 0的边界时则会设置gen 1的边界在这个plug的前面。
最终选择压缩(compact)时,会把新的代边界设置成计划代边界(请看fix_generation_bounds函数),
最终选择清扫(sweep)时,计划代边界不会被使用(请看make_free_lists函数和make_free_list_in_brick函数)。
计划阶段(plan_phase)的代码
gc_heap::plan_phase函数的代码如下
void gc_heap::plan_phase (int condemned_gen_number)
{
// 如果收集代是gen 1则记录原来gen 2的大小
size_t old_gen2_allocated = 0;
size_t old_gen2_size = 0;
if (condemned_gen_number == (max_generation - 1))
{
old_gen2_allocated = generation_free_list_allocated (generation_of (max_generation));
old_gen2_size = generation_size (max_generation);
}
assert (settings.concurrent == FALSE);
// 统计计划阶段的开始时间
// %type% category = quote (plan);
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
dprintf (2,("---- Plan Phase ---- Condemned generation %d, promotion: %d",
condemned_gen_number, settings.promotion ? 1 : 0));
// 收集代的对象
generation* condemned_gen1 = generation_of (condemned_gen_number);
// 判断之前是否使用了mark list
// 标记对象较少时用mark list可以提升速度
#ifdef MARK_LIST
BOOL use_mark_list = FALSE;
uint8_t** mark_list_next = &mark_list[0];
#ifdef GC_CONFIG_DRIVEN
dprintf (3, ("total number of marked objects: %Id (%Id)",
(mark_list_index - &mark_list[0]), ((mark_list_end - &mark_list[0]))));
#else
dprintf (3, ("mark_list length: %Id",
(mark_list_index - &mark_list[0])));
#endif //GC_CONFIG_DRIVEN
if ((condemned_gen_number < max_generation) &&
(mark_list_index <= mark_list_end)
#ifdef BACKGROUND_GC
&& (!recursive_gc_sync::background_running_p())
#endif //BACKGROUND_GC
)
{
#ifndef MULTIPLE_HEAPS
_sort (&mark_list[0], mark_list_index-1, 0);
//printf ("using mark list at GC #%d", dd_collection_count (dynamic_data_of (0)));
//verify_qsort_array (&mark_list[0], mark_list_index-1);
#endif //!MULTIPLE_HEAPS
use_mark_list = TRUE;
get_gc_data_per_heap()->set_mechanism_bit (gc_mark_list_bit);
}
else
{
dprintf (3, ("mark_list not used"));
}
#endif //MARK_LIST
// 清除read only segment中的marked bit
#ifdef FEATURE_BASICFREEZE
if ((generation_start_segment (condemned_gen1) != ephemeral_heap_segment) &&
ro_segments_in_range)
{
sweep_ro_segments (generation_start_segment (condemned_gen1));
}
#endif // FEATURE_BASICFREEZE
// 根据之前使用m_boundary记录的slow和shigh快速清扫slow前面和shigh后面的垃圾对象
// shigh等于0表示无对象存活
// if (shigh != (uint8_t*)0)
// 对于slow, 调用make_unused_array
// 对于shigh, 设置heap_segment_allocated
// 对于范围外的segment, heap_segment_allocated (seg) = heap_segment_mem (seg); // 整个segment都被清空,后面可删除
// else
// 第一个segment, heap_segment_allocated (seg) = generation_allocation_start (condemned_gen1);
// 后面的segment, heap_segment_allocated (seg) = heap_segment_mem (seg); // 整个segment都被清空,后面可删除
#ifndef MULTIPLE_HEAPS
if (shigh != (uint8_t*)0)
{
heap_segment* seg = heap_segment_rw (generation_start_segment (condemned_gen1));
PREFIX_ASSUME(seg != NULL);
heap_segment* fseg = seg;
do
{
if (slow > heap_segment_mem (seg) &&
slow < heap_segment_reserved (seg))
{
if (seg == fseg)
{
uint8_t* o = generation_allocation_start (condemned_gen1) +
Align (size (generation_allocation_start (condemned_gen1)));
if (slow > o)
{
assert ((slow - o) >= (int)Align (min_obj_size));
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
bgc_clear_batch_mark_array_bits (o, slow);
}
#endif //BACKGROUND_GC
make_unused_array (o, slow - o);
}
}
else
{
assert (condemned_gen_number == max_generation);
make_unused_array (heap_segment_mem (seg),
slow - heap_segment_mem (seg));
}
}
if (in_range_for_segment (shigh, seg))
{
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
bgc_clear_batch_mark_array_bits ((shigh + Align (size (shigh))), heap_segment_allocated (seg));
}
#endif //BACKGROUND_GC
heap_segment_allocated (seg) = shigh + Align (size (shigh));
}
// test if the segment is in the range of [slow, shigh]
if (!((heap_segment_reserved (seg) >= slow) &&
(heap_segment_mem (seg) <= shigh)))
{
// shorten it to minimum
heap_segment_allocated (seg) = heap_segment_mem (seg);
}
seg = heap_segment_next_rw (seg);
} while (seg);
}
else
{
heap_segment* seg = heap_segment_rw (generation_start_segment (condemned_gen1));
PREFIX_ASSUME(seg != NULL);
heap_segment* sseg = seg;
do
{
// shorten it to minimum
if (seg == sseg)
{
// no survivors make all generations look empty
uint8_t* o = generation_allocation_start (condemned_gen1) +
Align (size (generation_allocation_start (condemned_gen1)));
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
bgc_clear_batch_mark_array_bits (o, heap_segment_allocated (seg));
}
#endif //BACKGROUND_GC
heap_segment_allocated (seg) = o;
}
else
{
assert (condemned_gen_number == max_generation);
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
bgc_clear_batch_mark_array_bits (heap_segment_mem (seg), heap_segment_allocated (seg));
}
#endif //BACKGROUND_GC
heap_segment_allocated (seg) = heap_segment_mem (seg);
}
seg = heap_segment_next_rw (seg);
} while (seg);
}
#endif //MULTIPLE_HEAPS
// 当前计划的segment,会随着计划向后移动
heap_segment* seg1 = heap_segment_rw (generation_start_segment (condemned_gen1));
PREFIX_ASSUME(seg1 != NULL);
// 当前计划的segment的结束地址
uint8_t* end = heap_segment_allocated (seg1);
// 收集代的第一个对象(地址)
uint8_t* first_condemned_address = generation_allocation_start (condemned_gen1);
// 当前计划的对象
uint8_t* x = first_condemned_address;
assert (!marked (x));
// 当前plug的结束地址
uint8_t* plug_end = x;
// 当前plug树的根节点
uint8_t* tree = 0;
// 构建plug树使用的序列
size_t sequence_number = 0;
// 上一次的plug节点
uint8_t* last_node = 0;
// 当前计划的brick
size_t current_brick = brick_of (x);
// 是否从计划代开始模拟分配(这个变量后面还会设为true)
BOOL allocate_in_condemned = ((condemned_gen_number == max_generation)||
(settings.promotion == FALSE));
// 当前计划的旧代和新代,这两个变量用于重新决定代边界(generation_allocation_start)
int active_old_gen_number = condemned_gen_number;
int active_new_gen_number = (allocate_in_condemned ? condemned_gen_number:
(1 + condemned_gen_number));
// 收集代的上一代(如果收集代是gen 2这里会设为gen 2)
generation* older_gen = 0;
// 模拟分配的代
generation* consing_gen = condemned_gen1;
// older_gen的原始数据备份
alloc_list r_free_list [MAX_BUCKET_COUNT];
size_t r_free_list_space = 0;
size_t r_free_obj_space = 0;
size_t r_older_gen_free_list_allocated = 0;
size_t r_older_gen_condemned_allocated = 0;
size_t r_older_gen_end_seg_allocated = 0;
uint8_t* r_allocation_pointer = 0;
uint8_t* r_allocation_limit = 0;
uint8_t* r_allocation_start_region = 0;
heap_segment* r_allocation_segment = 0;
#ifdef FREE_USAGE_STATS
size_t r_older_gen_free_space[NUM_GEN_POWER2];
#endif //FREE_USAGE_STATS
// 在计划之前备份older_gen的数据
if ((condemned_gen_number < max_generation))
{
older_gen = generation_of (min (max_generation, 1 + condemned_gen_number));
generation_allocator (older_gen)->copy_to_alloc_list (r_free_list);
r_free_list_space = generation_free_list_space (older_gen);
r_free_obj_space = generation_free_obj_space (older_gen);
#ifdef FREE_USAGE_STATS
memcpy (r_older_gen_free_space, older_gen->gen_free_spaces, sizeof (r_older_gen_free_space));
#endif //FREE_USAGE_STATS
generation_allocate_end_seg_p (older_gen) = FALSE;
r_older_gen_free_list_allocated = generation_free_list_allocated (older_gen);
r_older_gen_condemned_allocated = generation_condemned_allocated (older_gen);
r_older_gen_end_seg_allocated = generation_end_seg_allocated (older_gen);
r_allocation_limit = generation_allocation_limit (older_gen);
r_allocation_pointer = generation_allocation_pointer (older_gen);
r_allocation_start_region = generation_allocation_context_start_region (older_gen);
r_allocation_segment = generation_allocation_segment (older_gen);
heap_segment* start_seg = heap_segment_rw (generation_start_segment (older_gen));
PREFIX_ASSUME(start_seg != NULL);
if (start_seg != ephemeral_heap_segment)
{
assert (condemned_gen_number == (max_generation - 1));
while (start_seg && (start_seg != ephemeral_heap_segment))
{
assert (heap_segment_allocated (start_seg) >=
heap_segment_mem (start_seg));
assert (heap_segment_allocated (start_seg) <=
heap_segment_reserved (start_seg));
heap_segment_plan_allocated (start_seg) =
heap_segment_allocated (start_seg);
start_seg = heap_segment_next_rw (start_seg);
}
}
}
// 重设收集代以后的的所有segment的plan_allocated(计划分配的对象大小合计)
//reset all of the segment allocated sizes
{
heap_segment* seg2 = heap_segment_rw (generation_start_segment (condemned_gen1));
PREFIX_ASSUME(seg2 != NULL);
while (seg2)
{
heap_segment_plan_allocated (seg2) =
heap_segment_mem (seg2);
seg2 = heap_segment_next_rw (seg2);
}
}
// 重设gen 0 ~ 收集代的数据
int condemned_gn = condemned_gen_number;
int bottom_gen = 0;
init_free_and_plug();
while (condemned_gn >= bottom_gen)
{
generation* condemned_gen2 = generation_of (condemned_gn);
generation_allocator (condemned_gen2)->clear();
generation_free_list_space (condemned_gen2) = 0;
generation_free_obj_space (condemned_gen2) = 0;
generation_allocation_size (condemned_gen2) = 0;
generation_condemned_allocated (condemned_gen2) = 0;
generation_pinned_allocated (condemned_gen2) = 0;
generation_free_list_allocated(condemned_gen2) = 0;
generation_end_seg_allocated (condemned_gen2) = 0;
// 执行清扫(sweep)时对应代增加的固定对象(pinned object)大小
generation_pinned_allocation_sweep_size (condemned_gen2) = 0;
// 执行压缩(compact)时对应代增加的固定对象(pinned object)大小
generation_pinned_allocation_compact_size (condemned_gen2) = 0;
#ifdef FREE_USAGE_STATS
generation_pinned_free_obj_space (condemned_gen2) = 0;
generation_allocated_in_pinned_free (condemned_gen2) = 0;
generation_allocated_since_last_pin (condemned_gen2) = 0;
#endif //FREE_USAGE_STATS
// 计划的代边界
generation_plan_allocation_start (condemned_gen2) = 0;
generation_allocation_segment (condemned_gen2) =
heap_segment_rw (generation_start_segment (condemned_gen2));
PREFIX_ASSUME(generation_allocation_segment(condemned_gen2) != NULL);
// 设置分配上下文地址,模拟压缩时使用
if (generation_start_segment (condemned_gen2) != ephemeral_heap_segment)
{
generation_allocation_pointer (condemned_gen2) =
heap_segment_mem (generation_allocation_segment (condemned_gen2));
}
else
{
generation_allocation_pointer (condemned_gen2) = generation_allocation_start (condemned_gen2);
}
generation_allocation_limit (condemned_gen2) = generation_allocation_pointer (condemned_gen2);
generation_allocation_context_start_region (condemned_gen2) = generation_allocation_pointer (condemned_gen2);
condemned_gn--;
}
// 在处理所有对象之前是否要先决定一个代的边界
// 不升代或者收集代是gen 2(Full GC)时需要
BOOL allocate_first_generation_start = FALSE;
if (allocate_in_condemned)
{
allocate_first_generation_start = TRUE;
}
dprintf(3,( " From %Ix to %Ix", (size_t)x, (size_t)end));
// 记录对象降代(原来gen 1的对象变为gen 0)的情况
// 关于不升代和降代的条件和处理将在下面解释
demotion_low = MAX_PTR;
demotion_high = heap_segment_allocated (ephemeral_heap_segment);
// 判断是否应该阻止gen 1中的固定对象降代
// 如果只是收集原因只是因为dt_low_card_table_efficiency_p则需要阻止降代
// demote_gen1_p = false时会在下面调用advance_pins_for_demotion函数
// If we are doing a gen1 only because of cards, it means we should not demote any pinned plugs
// from gen1. They should get promoted to gen2.
demote_gen1_p = !(settings.promotion &&
(settings.condemned_generation == (max_generation - 1)) &&
gen_to_condemn_reasons.is_only_condition (gen_low_card_p));
total_ephemeral_size = 0;
// 打印除错信息
print_free_and_plug ("BP");
// 打印除错信息
for (int gen_idx = 0; gen_idx <= max_generation; gen_idx++)
{
generation* temp_gen = generation_of (gen_idx);
dprintf (2, ("gen%d start %Ix, plan start %Ix",
gen_idx,
generation_allocation_start (temp_gen),
generation_plan_allocation_start (temp_gen)));
}
// 触发etw时间
BOOL fire_pinned_plug_events_p = ETW_EVENT_ENABLED(MICROSOFT_WINDOWS_DOTNETRUNTIME_PRIVATE_PROVIDER_Context, PinPlugAtGCTime);
size_t last_plug_len = 0;
// 开始模拟压缩
// 会创建plug,设置brick table和模拟plug的移动
while (1)
{
// 应该处理下个segment
if (x >= end)
{
assert (x == end);
assert (heap_segment_allocated (seg1) == end);
heap_segment_allocated (seg1) = plug_end;
// 设置brick table
current_brick = update_brick_table (tree, current_brick, x, plug_end);
dprintf (3, ("end of seg: new tree, sequence# 0"));
sequence_number = 0;
tree = 0;
// 有下一个segment,继续处理
if (heap_segment_next_rw (seg1))
{
seg1 = heap_segment_next_rw (seg1);
end = heap_segment_allocated (seg1);
plug_end = x = heap_segment_mem (seg1);
current_brick = brick_of (x);
dprintf(3,( " From %Ix to %Ix", (size_t)x, (size_t)end));
continue;
}
// 无下一个segment,跳出模拟压缩的循环
else
{
break;
}
}
// 上一个plug是否unpinned plug
BOOL last_npinned_plug_p = FALSE;
// 上一个plug是否pinned plug
BOOL last_pinned_plug_p = FALSE;
// 上一个pinned plug的地址,合并pinned plug时使用
// last_pinned_plug is the beginning of the last pinned plug. If we merge a plug into a pinned
// plug we do not change the value of last_pinned_plug. This happens with artificially pinned plugs -
// it can be merged with a previous pinned plug and a pinned plug after it can be merged with it.
uint8_t* last_pinned_plug = 0;
size_t num_pinned_plugs_in_plug = 0;
// 当前plug的最后一个对象的地址
uint8_t* last_object_in_plug = 0;
// 枚举segment中的对象,如果第一个对象未被标记不会进入以下的处理
while ((x < end) && marked (x))
{
// 记录plug的开始
uint8_t* plug_start = x;
uint8_t* saved_plug_end = plug_end;
// 当前plug中的对象是否pinned object
// 会轮流切换
BOOL pinned_plug_p = FALSE;
BOOL npin_before_pin_p = FALSE;
BOOL saved_last_npinned_plug_p = last_npinned_plug_p;
uint8_t* saved_last_object_in_plug = last_object_in_plug;
BOOL merge_with_last_pin_p = FALSE;
size_t added_pinning_size = 0;
size_t artificial_pinned_size = 0;
// 预先保存一部分plug信息
// 设置这个plug和上一个plug的结尾之间的gap
// 如果当前plug是pinned plug
// - 调用enque_pinned_plug把plug信息保存到mark_stack_array队列
// - enque_pinned_plug不会设置长度(len)和移动队列顶部(mark_stack_tos),这部分工作会在set_pinned_info完成
// - 检测当前pinned plug是否覆盖了前一个unpinned plug的结尾
// - 如果覆盖了需要把原来的内容复制到saved_pre_plug和saved_pre_plug_reloc (函数enque_pinned_plug)
// 如果当前plug是unpinned plug
// - 检测当前unpinned plug是否覆盖了前一个pinned plug的结尾
// - 如果覆盖了需要把原来的内容复制到saved_post_plug和saved_post_plug_reloc (函数save_post_plug_info)
store_plug_gap_info (plug_start, plug_end, last_npinned_plug_p, last_pinned_plug_p,
last_pinned_plug, pinned_plug_p, last_object_in_plug,
merge_with_last_pin_p, last_plug_len);
#ifdef FEATURE_STRUCTALIGN
int requiredAlignment = ((CObjectHeader*)plug_start)->GetRequiredAlignment();
size_t alignmentOffset = OBJECT_ALIGNMENT_OFFSET;
#endif // FEATURE_STRUCTALIGN
{
// 枚举接下来的对象,如果对象未被标记,或者对象是否固定和pinned_plug_p不一致则中断
// 这里枚举到的对象都会归到同一个plug里面
uint8_t* xl = x;
while ((xl < end) && marked (xl) && (pinned (xl) == pinned_plug_p))
{
assert (xl < end);
// 清除pinned bit
// 像前面所说的,GC里面marked和pinned标记都是临时使用的,在计划阶段会被清除
if (pinned(xl))
{
clear_pinned (xl);
}
#ifdef FEATURE_STRUCTALIGN
else
{
int obj_requiredAlignment = ((CObjectHeader*)xl)->GetRequiredAlignment();
if (obj_requiredAlignment > requiredAlignment)
{
requiredAlignment = obj_requiredAlignment;
alignmentOffset = xl - plug_start + OBJECT_ALIGNMENT_OFFSET;
}
}
#endif // FEATURE_STRUCTALIGN
// 清除marked bit
clear_marked (xl);
dprintf(4, ("+%Ix+", (size_t)xl));
assert ((size (xl) > 0));
assert ((size (xl) <= LARGE_OBJECT_SIZE));
// 记录当前plug的最后一个对象
last_object_in_plug = xl;
// 下一个对象
xl = xl + Align (size (xl));
Prefetch (xl);
}
BOOL next_object_marked_p = ((xl < end) && marked (xl));
// 如果当前plug是pinned plug但下一个不是,代表当前plug的结尾需要被覆盖掉做下一个plug的信息
// 我们不想动pinned plug的内容,所以这里需要牺牲下一个对象,把下一个对象拉到这个plug里面
if (pinned_plug_p)
{
// If it is pinned we need to extend to the next marked object as we can't use part of
// a pinned object to make the artificial gap (unless the last 3 ptr sized words are all
// references but for now I am just using the next non pinned object for that).
if (next_object_marked_p)
{
clear_marked (xl);
last_object_in_plug = xl;
size_t extra_size = Align (size (xl));
xl = xl + extra_size;
added_pinning_size = extra_size;
}
}
else
{
// 当前plug是unpinned plug,下一个plug是pinned plug
if (next_object_marked_p)
npin_before_pin_p = TRUE;
}
assert (xl <= end);
x = xl;
}
dprintf (3, ( "%Ix[", (size_t)x));
// 设置plug的结尾
plug_end = x;
// plug大小 = 结尾 - 开头
size_t ps = plug_end - plug_start;
last_plug_len = ps;
dprintf (3, ( "%Ix[(%Ix)", (size_t)x, ps));
uint8_t* new_address = 0;
// 有时候如果一个unpinned plug很大,我们想人工固定它(artificially pinned plug)
// 如果前一个plug也是pinned plug则和前一个plug整合到一个,否则进入mark_stack_array队列中
if (!pinned_plug_p)
{
if (allocate_in_condemned &&
(settings.condemned_generation == max_generation) &&
(ps > (OS_PAGE_SIZE)))
{
ptrdiff_t reloc = plug_start - generation_allocation_pointer (consing_gen);
//reloc should >=0 except when we relocate
//across segments and the dest seg is higher then the src
if ((ps > (8*OS_PAGE_SIZE)) &&
(reloc > 0) &&
((size_t)reloc < (ps/16)))
{
dprintf (3, ("Pinning %Ix; reloc would have been: %Ix",
(size_t)plug_start, reloc));
// The last plug couldn't have been a npinned plug or it would have
// included this plug.
assert (!saved_last_npinned_plug_p);
if (last_pinned_plug)
{
dprintf (3, ("artificially pinned plug merged with last pinned plug"));
merge_with_last_pin_p = TRUE;
}
else
{
enque_pinned_plug (plug_start, FALSE, 0);
last_pinned_plug = plug_start;
}
convert_to_pinned_plug (last_npinned_plug_p, last_pinned_plug_p, pinned_plug_p,
ps, artificial_pinned_size);
}
}
}
// 如果在做Full GC或者不升代,决定第一个代的边界
// plan_generation_start用于计划代的边界(generation_plan_generation_start)
// Full GC时gen 2的边界会在这里决定
if (allocate_first_generation_start)
{
allocate_first_generation_start = FALSE;
plan_generation_start (condemned_gen1, consing_gen, plug_start);
assert (generation_plan_allocation_start (condemned_gen1));
}
// 如果模拟的segment是ephemeral heap segment
// 在这里决定gen 1的边界
// 如果不升代这里也会决定gen 0的边界
if (seg1 == ephemeral_heap_segment)
{
process_ephemeral_boundaries (plug_start, active_new_gen_number,
active_old_gen_number,
consing_gen,
allocate_in_condemned);
}
dprintf (3, ("adding %Id to gen%d surv", ps, active_old_gen_number));
// 统计存活的对象大小
dynamic_data* dd_active_old = dynamic_data_of (active_old_gen_number);
dd_survived_size (dd_active_old) += ps;
// 模拟压缩的时候有可能会要求把当前unpinned plug转换为pinned plug
BOOL convert_to_pinned_p = FALSE;
// 如果plug是unpinned plug,模拟压缩
if (!pinned_plug_p)
{
#if defined (RESPECT_LARGE_ALIGNMENT) || defined (FEATURE_STRUCTALIGN)
dd_num_npinned_plugs (dd_active_old)++;
#endif //RESPECT_LARGE_ALIGNMENT || FEATURE_STRUCTALIGN
// 更新统计信息
add_gen_plug (active_old_gen_number, ps);
if (allocate_in_condemned)
{
verify_pins_with_post_plug_info("before aic");
// 在收集代分配,必要时跳过pinned plug,返回新的地址
new_address =
allocate_in_condemned_generations (consing_gen,
ps,
active_old_gen_number,
#ifdef SHORT_PLUGS
&convert_to_pinned_p,
(npin_before_pin_p ? plug_end : 0),
seg1,
#endif //SHORT_PLUGS
plug_start REQD_ALIGN_AND_OFFSET_ARG);
verify_pins_with_post_plug_info("after aic");
}
else
{
// 在上一代分配,必要时跳过pinned plug,返回新的地址
new_address = allocate_in_older_generation (older_gen, ps, active_old_gen_number, plug_start REQD_ALIGN_AND_OFFSET_ARG);
if (new_address != 0)
{
if (settings.condemned_generation == (max_generation - 1))
{
dprintf (3, (" NA: %Ix-%Ix -> %Ix, %Ix (%Ix)",
plug_start, plug_end,
(size_t)new_address, (size_t)new_address + (plug_end - plug_start),
(size_t)(plug_end - plug_start)));
}
}
else
{
// 失败时(空间不足)改为在收集代分配
allocate_in_condemned = TRUE;
new_address = allocate_in_condemned_generations (consing_gen, ps, active_old_gen_number,
#ifdef SHORT_PLUGS
&convert_to_pinned_p,
(npin_before_pin_p ? plug_end : 0),
seg1,
#endif //SHORT_PLUGS
plug_start REQD_ALIGN_AND_OFFSET_ARG);
}
}
// 如果要求把当前unpinned plug转换为pinned plug
if (convert_to_pinned_p)
{
assert (last_npinned_plug_p != FALSE);
assert (last_pinned_plug_p == FALSE);
convert_to_pinned_plug (last_npinned_plug_p, last_pinned_plug_p, pinned_plug_p,
ps, artificial_pinned_size);
enque_pinned_plug (plug_start, FALSE, 0);
last_pinned_plug = plug_start;
}
else
{
// 找不到空间(不移动这个plug)时验证是在ephemeral heap segment的末尾
// 这里还不会设置reloc,到下面的set_node_relocation_distance才会设
if (!new_address)
{
//verify that we are at then end of the ephemeral segment
assert (generation_allocation_segment (consing_gen) ==
ephemeral_heap_segment);
//verify that we are near the end
assert ((generation_allocation_pointer (consing_gen) + Align (ps)) <
heap_segment_allocated (ephemeral_heap_segment));
assert ((generation_allocation_pointer (consing_gen) + Align (ps)) >
(heap_segment_allocated (ephemeral_heap_segment) + Align (min_obj_size)));
}
else
{
#ifdef SIMPLE_DPRINTF
dprintf (3, ("(%Ix)[%Ix->%Ix, NA: [%Ix(%Id), %Ix[: %Ix(%d)",
(size_t)(node_gap_size (plug_start)),
plug_start, plug_end, (size_t)new_address, (size_t)(plug_start - new_address),
(size_t)new_address + ps, ps,
(is_plug_padded (plug_start) ? 1 : 0)));
#endif //SIMPLE_DPRINTF
#ifdef SHORT_PLUGS
if (is_plug_padded (plug_start))
{
dprintf (3, ("%Ix was padded", plug_start));
dd_padding_size (dd_active_old) += Align (min_obj_size);
}
#endif //SHORT_PLUGS
}
}
}
// 如果当前plug是pinned plug
if (pinned_plug_p)
{
if (fire_pinned_plug_events_p)
FireEtwPinPlugAtGCTime(plug_start, plug_end,
(merge_with_last_pin_p ? 0 : (uint8_t*)node_gap_size (plug_start)),
GetClrInstanceId());
// 和上一个pinned plug合并
if (merge_with_last_pin_p)
{
merge_with_last_pinned_plug (last_pinned_plug, ps);
}
// 设置队列中的pinned plug大小(len)并移动队列顶部(mark_stack_tos++)
else
{
assert (last_pinned_plug == plug_start);
set_pinned_info (plug_start, ps, consing_gen);
}
// pinned plug不能移动,新地址和原地址一样
new_address = plug_start;
dprintf (3, ( "(%Ix)PP: [%Ix, %Ix[%Ix](m:%d)",
(size_t)(node_gap_size (plug_start)), (size_t)plug_start,
(size_t)plug_end, ps,
(merge_with_last_pin_p ? 1 : 0)));
// 统计存活对象的大小,固定对象的大小和人工固定对象的大小
dprintf (3, ("adding %Id to gen%d pinned surv", plug_end - plug_start, active_old_gen_number));
dd_pinned_survived_size (dd_active_old) += plug_end - plug_start;
dd_added_pinned_size (dd_active_old) += added_pinning_size;
dd_artificial_pinned_survived_size (dd_active_old) += artificial_pinned_size;
// 如果需要禁止降代gen 1的对象,记录在gen 1中最后一个pinned plug的结尾
if (!demote_gen1_p && (active_old_gen_number == (max_generation - 1)))
{
last_gen1_pin_end = plug_end;
}
}
#ifdef _DEBUG
// detect forward allocation in the same segment
assert (!((new_address > plug_start) &&
(new_address < heap_segment_reserved (seg1))));
#endif //_DEBUG
// 如果不合并到上一个pinned plug
// 在这里可以设置偏移值(reloc)和更新brick table了
if (!merge_with_last_pin_p)
{
// 如果已经在下一个brick
// 把之前的plug树设置到之前的brick中,并重设plug树
// 如果之前的plug跨了多个brick,update_brick_table会设置后面的brick为-1
if (current_brick != brick_of (plug_start))
{
current_brick = update_brick_table (tree, current_brick, plug_start, saved_plug_end);
sequence_number = 0;
tree = 0;
}
// 更新plug的偏移值(reloc)
// 这里的偏移值会用在后面的重定位阶段(relocate_phase)和压缩阶段(compact_phase)
set_node_relocation_distance (plug_start, (new_address - plug_start));
// 构建plug树
if (last_node && (node_relocation_distance (last_node) ==
(node_relocation_distance (plug_start) +
(int)node_gap_size (plug_start))))
{
//dprintf(3,( " Lb"));
dprintf (3, ("%Ix Lb", plug_start));
set_node_left (plug_start);
}
if (0 == sequence_number)
{
dprintf (2, ("sn: 0, tree is set to %Ix", plug_start));
tree = plug_start;
}
verify_pins_with_post_plug_info("before insert node");
tree = insert_node (plug_start, ++sequence_number, tree, last_node);
dprintf (3, ("tree is %Ix (b: %Ix) after insert_node", tree, brick_of (tree)));
last_node = plug_start;
// 这个处理只用于除错
// 如果这个plug是unpinned plug并且覆盖了上一个pinned plug的结尾
// 把覆盖的内容复制到pinned plug关联的saved_post_plug_debug
#ifdef _DEBUG
// If we detect if the last plug is pinned plug right before us, we should save this gap info
if (!pinned_plug_p)
{
if (mark_stack_tos > 0)
{
mark& m = mark_stack_array[mark_stack_tos - 1];
if (m.has_post_plug_info())
{
uint8_t* post_plug_info_start = m.saved_post_plug_info_start;
size_t* current_plug_gap_start = (size_t*)(plug_start - sizeof (plug_and_gap));
if ((uint8_t*)current_plug_gap_start == post_plug_info_start)
{
dprintf (3, ("Ginfo: %Ix, %Ix, %Ix",
*current_plug_gap_start, *(current_plug_gap_start + 1),
*(current_plug_gap_start + 2)));
memcpy (&(m.saved_post_plug_debug), current_plug_gap_start, sizeof (gap_reloc_pair));
}
}
}
}
#endif //_DEBUG
verify_pins_with_post_plug_info("after insert node");
}
}
if (num_pinned_plugs_in_plug > 1)
{
dprintf (3, ("more than %Id pinned plugs in this plug", num_pinned_plugs_in_plug));
}
// 跳过未标记的对象找到下一个已标记的对象
// 如果有mark_list可以加快找到下一个已标记对象的速度
{
#ifdef MARK_LIST
if (use_mark_list)
{
while ((mark_list_next < mark_list_index) &&
(*mark_list_next <= x))
{
mark_list_next++;
}
if ((mark_list_next < mark_list_index)
#ifdef MULTIPLE_HEAPS
&& (*mark_list_next < end) //for multiple segments
#endif //MULTIPLE_HEAPS
)
x = *mark_list_next;
else
x = end;
}
else
#endif //MARK_LIST
{
uint8_t* xl = x;
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
assert (recursive_gc_sync::background_running_p());
while ((xl < end) && !marked (xl))
{
dprintf (4, ("-%Ix-", (size_t)xl));
assert ((size (xl) > 0));
background_object_marked (xl, TRUE);
xl = xl + Align (size (xl));
Prefetch (xl);
}
}
else
#endif //BACKGROUND_GC
{
// 跳过未标记的对象
while ((xl < end) && !marked (xl))
{
dprintf (4, ("-%Ix-", (size_t)xl));
assert ((size (xl) > 0));
xl = xl + Align (size (xl));
Prefetch (xl);
}
}
assert (xl <= end);
// 找到了下一个已标记的对象,或者当前segment中的对象已经搜索完毕
x = xl;
}
}
}
// 处理mark_stack_array中尚未出队的pinned plug
// 这些plug已经在所有已压缩的unpinned plug后面,我们可以把这些pinned plug降级(降到gen 0),也可以防止它们降级
while (!pinned_plug_que_empty_p())
{
// 计算代边界和处理降代
// 不在ephemeral heap segment的pinned plug不会被降代
// 前面调用的process_ephemeral_boundaries中有相同的处理
if (settings.promotion)
{
uint8_t* pplug = pinned_plug (oldest_pin());
if (in_range_for_segment (pplug, ephemeral_heap_segment))
{
consing_gen = ensure_ephemeral_heap_segment (consing_gen);
//allocate all of the generation gaps
while (active_new_gen_number > 0)
{
active_new_gen_number--;
if (active_new_gen_number == (max_generation - 1))
{
// 如果要防止gen 1的pinned plug降代则需要调用调用advance_pins_for_demotion跳过(出队)它们
// 在原来gen 0中的pinned plug不会改变
maxgen_pinned_compact_before_advance = generation_pinned_allocation_compact_size (generation_of (max_generation));
if (!demote_gen1_p)
advance_pins_for_demotion (consing_gen);
}
// 计划剩余的代边界
generation* gen = generation_of (active_new_gen_number);
plan_generation_start (gen, consing_gen, 0);
// 代边界被设置到pinned plug之前的时候需要记录降代的范围(降代已经实际发生,设置demotion_low是记录降代的范围)
if (demotion_low == MAX_PTR)
{
demotion_low = pplug;
dprintf (3, ("end plan: dlow->%Ix", demotion_low));
}
dprintf (2, ("(%d)gen%d plan start: %Ix",
heap_number, active_new_gen_number, (size_t)generation_plan_allocation_start (gen)));
assert (generation_plan_allocation_start (gen));
}
}
}
// 所有pinned plug都已出队时跳出
if (pinned_plug_que_empty_p())
break;
// 出队一个pinned plug
size_t entry = deque_pinned_plug();
mark* m = pinned_plug_of (entry);
uint8_t* plug = pinned_plug (m);
size_t len = pinned_len (m);
// 检测这个pinned plug是否在cosing_gen的allocation segment之外
// 如果不在需要调整allocation segment,等会需要把generation_allocation_pointer设置为plug + len
// detect pinned block in different segment (later) than
// allocation segment
heap_segment* nseg = heap_segment_rw (generation_allocation_segment (consing_gen));
while ((plug < generation_allocation_pointer (consing_gen)) ||
(plug >= heap_segment_allocated (nseg)))
{
assert ((plug < heap_segment_mem (nseg)) ||
(plug > heap_segment_reserved (nseg)));
//adjust the end of the segment to be the end of the plug
assert (generation_allocation_pointer (consing_gen)>=
heap_segment_mem (nseg));
assert (generation_allocation_pointer (consing_gen)<=
heap_segment_committed (nseg));
heap_segment_plan_allocated (nseg) =
generation_allocation_pointer (consing_gen);
//switch allocation segment
nseg = heap_segment_next_rw (nseg);
generation_allocation_segment (consing_gen) = nseg;
//reset the allocation pointer and limits
generation_allocation_pointer (consing_gen) =
heap_segment_mem (nseg);
}
// 出队以后设置len = pinned plug - generation_allocation_pointer (consing_gen)
// 表示pinned plug的开始地址离最后的模拟压缩分配地址的空间,这个空间可以变成free object
set_new_pin_info (m, generation_allocation_pointer (consing_gen));
dprintf (2, ("pin %Ix b: %Ix->%Ix", plug, brick_of (plug),
(size_t)(brick_table[brick_of (plug)])));
// 设置模拟压缩分配地址到plug的结尾
generation_allocation_pointer (consing_gen) = plug + len;
generation_allocation_limit (consing_gen) =
generation_allocation_pointer (consing_gen);
//Add the size of the pinned plug to the right pinned allocations
//find out which gen this pinned plug came from
int frgn = object_gennum (plug);
// 统计清扫时会多出的pinned object大小
// 加到上一代中(pinned object升代)
if ((frgn != (int)max_generation) && settings.promotion)
{
generation_pinned_allocation_sweep_size ((generation_of (frgn +1))) += len;
}
}
// 计划剩余所有代的边界
// 大部分情况下(升代 + 无降代)这里会设置gen 0的边界,也就是在现有的所有存活对象之后
plan_generation_starts (consing_gen);
// 打印除错信息
print_free_and_plug ("AP");
// 打印除错信息
{
#ifdef SIMPLE_DPRINTF
for (int gen_idx = 0; gen_idx <= max_generation; gen_idx++)
{
generation* temp_gen = generation_of (gen_idx);
dynamic_data* temp_dd = dynamic_data_of (gen_idx);
int added_pinning_ratio = 0;
int artificial_pinned_ratio = 0;
if (dd_pinned_survived_size (temp_dd) != 0)
{
added_pinning_ratio = (int)((float)dd_added_pinned_size (temp_dd) * 100 / (float)dd_pinned_survived_size (temp_dd));
artificial_pinned_ratio = (int)((float)dd_artificial_pinned_survived_size (temp_dd) * 100 / (float)dd_pinned_survived_size (temp_dd));
}
size_t padding_size =
#ifdef SHORT_PLUGS
dd_padding_size (temp_dd);
#else
0;
#endif //SHORT_PLUGS
dprintf (1, ("gen%d: %Ix, %Ix(%Id), NON PIN alloc: %Id, pin com: %Id, sweep: %Id, surv: %Id, pinsurv: %Id(%d%% added, %d%% art), np surv: %Id, pad: %Id",
gen_idx,
generation_allocation_start (temp_gen),
generation_plan_allocation_start (temp_gen),
(size_t)(generation_plan_allocation_start (temp_gen) - generation_allocation_start (temp_gen)),
generation_allocation_size (temp_gen),
generation_pinned_allocation_compact_size (temp_gen),
generation_pinned_allocation_sweep_size (temp_gen),
dd_survived_size (temp_dd),
dd_pinned_survived_size (temp_dd),
added_pinning_ratio,
artificial_pinned_ratio,
(dd_survived_size (temp_dd) - dd_pinned_survived_size (temp_dd)),
padding_size));
}
#endif //SIMPLE_DPRINTF
}
// 继续打印除错信息,并且更新gen 2的统计信息
if (settings.condemned_generation == (max_generation - 1 ))
{
size_t plan_gen2_size = generation_plan_size (max_generation);
size_t growth = plan_gen2_size - old_gen2_size;
if (growth > 0)
{
dprintf (1, ("gen2 grew %Id (end seg alloc: %Id, gen1 c alloc: %Id",
growth, generation_end_seg_allocated (generation_of (max_generation)),
generation_condemned_allocated (generation_of (max_generation - 1))));
}
else
{
dprintf (1, ("gen2 shrank %Id (end seg alloc: %Id, gen1 c alloc: %Id",
(old_gen2_size - plan_gen2_size), generation_end_seg_allocated (generation_of (max_generation)),
generation_condemned_allocated (generation_of (max_generation - 1))));
}
generation* older_gen = generation_of (settings.condemned_generation + 1);
size_t rejected_free_space = generation_free_obj_space (older_gen) - r_free_obj_space;
size_t free_list_allocated = generation_free_list_allocated (older_gen) - r_older_gen_free_list_allocated;
size_t end_seg_allocated = generation_end_seg_allocated (older_gen) - r_older_gen_end_seg_allocated;
size_t condemned_allocated = generation_condemned_allocated (older_gen) - r_older_gen_condemned_allocated;
dprintf (1, ("older gen's free alloc: %Id->%Id, seg alloc: %Id->%Id, condemned alloc: %Id->%Id",
r_older_gen_free_list_allocated, generation_free_list_allocated (older_gen),
r_older_gen_end_seg_allocated, generation_end_seg_allocated (older_gen),
r_older_gen_condemned_allocated, generation_condemned_allocated (older_gen)));
dprintf (1, ("this GC did %Id free list alloc(%Id bytes free space rejected), %Id seg alloc and %Id condemned alloc, gen1 condemned alloc is %Id",
free_list_allocated, rejected_free_space, end_seg_allocated,
condemned_allocated, generation_condemned_allocated (generation_of (settings.condemned_generation))));
maxgen_size_increase* maxgen_size_info = &(get_gc_data_per_heap()->maxgen_size_info);
maxgen_size_info->free_list_allocated = free_list_allocated;
maxgen_size_info->free_list_rejected = rejected_free_space;
maxgen_size_info->end_seg_allocated = end_seg_allocated;
maxgen_size_info->condemned_allocated = condemned_allocated;
maxgen_size_info->pinned_allocated = maxgen_pinned_compact_before_advance;
maxgen_size_info->pinned_allocated_advance = generation_pinned_allocation_compact_size (generation_of (max_generation)) - maxgen_pinned_compact_before_advance;
#ifdef FREE_USAGE_STATS
int free_list_efficiency = 0;
if ((free_list_allocated + rejected_free_space) != 0)
free_list_efficiency = (int)(((float) (free_list_allocated) / (float)(free_list_allocated + rejected_free_space)) * (float)100);
int running_free_list_efficiency = (int)(generation_allocator_efficiency(older_gen)*100);
dprintf (1, ("gen%d free list alloc effi: %d%%, current effi: %d%%",
older_gen->gen_num,
free_list_efficiency, running_free_list_efficiency));
dprintf (1, ("gen2 free list change"));
for (int j = 0; j < NUM_GEN_POWER2; j++)
{
dprintf (1, ("[h%d][#%Id]: 2^%d: F: %Id->%Id(%Id), P: %Id",
heap_number,
settings.gc_index,
(j + 10), r_older_gen_free_space[j], older_gen->gen_free_spaces[j],
(ptrdiff_t)(r_older_gen_free_space[j] - older_gen->gen_free_spaces[j]),
(generation_of(max_generation - 1))->gen_plugs[j]));
}
#endif //FREE_USAGE_STATS
}
// 计算碎片空间大小fragmentation
// 这个是判断是否要压缩的依据之一
// 算法简略如下
// frag = (heap_segment_allocated(ephemeral_heap_segment) - generation_allocation_pointer (consing_gen))
// for segment in non_ephemeral_segments
// frag += heap_segment_allocated (seg) - heap_segment_plan_allocated (seg)
// for plug in dequed_plugs
// frag += plug.len
size_t fragmentation =
generation_fragmentation (generation_of (condemned_gen_number),
consing_gen,
heap_segment_allocated (ephemeral_heap_segment));
dprintf (2,("Fragmentation: %Id", fragmentation));
dprintf (2,("---- End of Plan phase ----"));
// 统计计划阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
plan_time = finish - start;
#endif //TIME_GC
// We may update write barrier code. We assume here EE has been suspended if we are on a GC thread.
assert(GCHeap::IsGCInProgress());
// 是否要扩展(使用新的segment heap segment)
BOOL should_expand = FALSE;
// 是否要压缩
BOOL should_compact= FALSE;
ephemeral_promotion = FALSE;
// 如果内存太小应该强制开启压缩
#ifdef BIT64
if ((!settings.concurrent) &&
((condemned_gen_number < max_generation) &&
((settings.gen0_reduction_count > 0) || (settings.entry_memory_load >= 95))))
{
dprintf (2, ("gen0 reduction count is %d, condemning %d, mem load %d",
settings.gen0_reduction_count,
condemned_gen_number,
settings.entry_memory_load));
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact,
((settings.gen0_reduction_count > 0) ? compact_fragmented_gen0 : compact_high_mem_load));
// 如果ephemeal heap segment空间较少应该换一个新的segment
if ((condemned_gen_number >= (max_generation - 1)) &&
dt_low_ephemeral_space_p (tuning_deciding_expansion))
{
dprintf (2, ("Not enough space for all ephemeral generations with compaction"));
should_expand = TRUE;
}
}
else
{
#endif // BIT64
// 判断是否要压缩
// 请看下面函数decide_on_compacting的代码解释
should_compact = decide_on_compacting (condemned_gen_number, fragmentation, should_expand);
#ifdef BIT64
}
#endif // BIT64
// 判断是否要压缩大对象的堆
#ifdef FEATURE_LOH_COMPACTION
loh_compacted_p = FALSE;
#endif //FEATURE_LOH_COMPACTION
if (condemned_gen_number == max_generation)
{
#ifdef FEATURE_LOH_COMPACTION
if (settings.loh_compaction)
{
// 针对大对象的堆模拟压缩,和前面创建plug计算reloc的处理差不多,但是一个plug中只有一个对象,也不会有plug树
// 保存plug信息使用的类型是loh_obj_and_pad
if (plan_loh())
{
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_loh_forced);
loh_compacted_p = TRUE;
}
}
else
{
// 清空loh_pinned_queue
if ((heap_number == 0) && (loh_pinned_queue))
{
loh_pinned_queue_decay--;
if (!loh_pinned_queue_decay)
{
delete loh_pinned_queue;
loh_pinned_queue = 0;
}
}
}
// 如果不需要压缩大对象的堆,在这里执行清扫
// 把未标记的对象合并到一个free object并且加到free list中
// 请参考后面sweep phase的代码解释
if (!loh_compacted_p)
#endif //FEATURE_LOH_COMPACTION
{
#if defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
if (ShouldTrackMovementForProfilerOrEtw())
notify_profiler_of_surviving_large_objects();
#endif // defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
sweep_large_objects();
}
}
else
{
settings.loh_compaction = FALSE;
}
#ifdef MULTIPLE_HEAPS
// 如果存在多个heap(服务器GC)还需要投票重新决定should_compact和should_expand
// 这里的一些处理(例如删除大对象segment和设置settings.demotion)是服务器GC和工作站GC都会做的
new_heap_segment = NULL;
if (should_compact && should_expand)
gc_policy = policy_expand;
else if (should_compact)
gc_policy = policy_compact;
else
gc_policy = policy_sweep;
//vote for result of should_compact
dprintf (3, ("Joining for compaction decision"));
gc_t_join.join(this, gc_join_decide_on_compaction);
if (gc_t_join.joined())
{
// 删除空的(无存活对象的)大对象segment
//safe place to delete large heap segments
if (condemned_gen_number == max_generation)
{
for (int i = 0; i < n_heaps; i++)
{
g_heaps [i]->rearrange_large_heap_segments ();
}
}
settings.demotion = FALSE;
int pol_max = policy_sweep;
#ifdef GC_CONFIG_DRIVEN
BOOL is_compaction_mandatory = FALSE;
#endif //GC_CONFIG_DRIVEN
int i;
for (i = 0; i < n_heaps; i++)
{
if (pol_max < g_heaps[i]->gc_policy)
pol_max = policy_compact;
// set the demotion flag is any of the heap has demotion
if (g_heaps[i]->demotion_high >= g_heaps[i]->demotion_low)
{
(g_heaps[i]->get_gc_data_per_heap())->set_mechanism_bit (gc_demotion_bit);
settings.demotion = TRUE;
}
#ifdef GC_CONFIG_DRIVEN
if (!is_compaction_mandatory)
{
int compact_reason = (g_heaps[i]->get_gc_data_per_heap())->get_mechanism (gc_heap_compact);
if (compact_reason >= 0)
{
if (gc_heap_compact_reason_mandatory_p[compact_reason])
is_compaction_mandatory = TRUE;
}
}
#endif //GC_CONFIG_DRIVEN
}
#ifdef GC_CONFIG_DRIVEN
if (!is_compaction_mandatory)
{
// If compaction is not mandatory we can feel free to change it to a sweeping GC.
// Note that we may want to change this to only checking every so often instead of every single GC.
if (should_do_sweeping_gc (pol_max >= policy_compact))
{
pol_max = policy_sweep;
}
else
{
if (pol_max == policy_sweep)
pol_max = policy_compact;
}
}
#endif //GC_CONFIG_DRIVEN
for (i = 0; i < n_heaps; i++)
{
if (pol_max > g_heaps[i]->gc_policy)
g_heaps[i]->gc_policy = pol_max;
//get the segment while we are serialized
if (g_heaps[i]->gc_policy == policy_expand)
{
g_heaps[i]->new_heap_segment =
g_heaps[i]->soh_get_segment_to_expand();
if (!g_heaps[i]->new_heap_segment)
{
set_expand_in_full_gc (condemned_gen_number);
//we are out of memory, cancel the expansion
g_heaps[i]->gc_policy = policy_compact;
}
}
}
BOOL is_full_compacting_gc = FALSE;
if ((gc_policy >= policy_compact) && (condemned_gen_number == max_generation))
{
full_gc_counts[gc_type_compacting]++;
is_full_compacting_gc = TRUE;
}
for (i = 0; i < n_heaps; i++)
{
//copy the card and brick tables
if (g_card_table!= g_heaps[i]->card_table)
{
g_heaps[i]->copy_brick_card_table();
}
if (is_full_compacting_gc)
{
g_heaps[i]->loh_alloc_since_cg = 0;
}
}
//start all threads on the roots.
dprintf(3, ("Starting all gc threads after compaction decision"));
gc_t_join.restart();
}
//reset the local variable accordingly
should_compact = (gc_policy >= policy_compact);
should_expand = (gc_policy >= policy_expand);
#else //MULTIPLE_HEAPS
// 删除空的(无存活对象的)大对象segment
//safe place to delete large heap segments
if (condemned_gen_number == max_generation)
{
rearrange_large_heap_segments ();
}
// 如果有对象被降代,则设置settings.demotion = true
settings.demotion = ((demotion_high >= demotion_low) ? TRUE : FALSE);
if (settings.demotion)
get_gc_data_per_heap()->set_mechanism_bit (gc_demotion_bit);
// 如果压缩不是必须的,根据用户提供的特殊设置重新设置should_compact
#ifdef GC_CONFIG_DRIVEN
BOOL is_compaction_mandatory = FALSE;
int compact_reason = get_gc_data_per_heap()->get_mechanism (gc_heap_compact);
if (compact_reason >= 0)
is_compaction_mandatory = gc_heap_compact_reason_mandatory_p[compact_reason];
if (!is_compaction_mandatory)
{
if (should_do_sweeping_gc (should_compact))
should_compact = FALSE;
else
should_compact = TRUE;
}
#endif //GC_CONFIG_DRIVEN
if (should_compact && (condemned_gen_number == max_generation))
{
full_gc_counts[gc_type_compacting]++;
loh_alloc_since_cg = 0;
}
#endif //MULTIPLE_HEAPS
// 进入重定位和压缩阶段
if (should_compact)
{
dprintf (2,( "**** Doing Compacting GC ****"));
// 如果应该使用新的ephemeral heap segment,调用expand_heap
// expand_heap有可能会复用前面的segment,也有可能重新生成一个segment
if (should_expand)
{
#ifndef MULTIPLE_HEAPS
heap_segment* new_heap_segment = soh_get_segment_to_expand();
#endif //!MULTIPLE_HEAPS
if (new_heap_segment)
{
consing_gen = expand_heap(condemned_gen_number,
consing_gen,
new_heap_segment);
}
// If we couldn't get a new segment, or we were able to
// reserve one but no space to commit, we couldn't
// expand heap.
if (ephemeral_heap_segment != new_heap_segment)
{
set_expand_in_full_gc (condemned_gen_number);
should_expand = FALSE;
}
}
generation_allocation_limit (condemned_gen1) =
generation_allocation_pointer (condemned_gen1);
if ((condemned_gen_number < max_generation))
{
generation_allocator (older_gen)->commit_alloc_list_changes();
// 如果 generation_allocation_limit 等于 heap_segment_plan_allocated
// 设置 heap_segment_plan_allocated 等于 generation_allocation_pointer
// 设置 generation_allocation_limit 等于 generation_allocation_pointer
// 否则
// 在alloc_ptr到limit的空间创建一个free object, 不加入free list
// Fix the allocation area of the older generation
fix_older_allocation_area (older_gen);
}
assert (generation_allocation_segment (consing_gen) ==
ephemeral_heap_segment);
#if defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
if (ShouldTrackMovementForProfilerOrEtw())
{
record_survived_for_profiler(condemned_gen_number, first_condemned_address);
}
#endif // defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
// 调用重定位阶段
// 这里会修改所有需要移动的对象的指针地址,但是不会移动它们的内容
// 具体代码请看后面
relocate_phase (condemned_gen_number, first_condemned_address);
// 调用压缩阶段
// 这里会复制对象的内容到它们移动到的地址
// 具体代码请看后面
compact_phase (condemned_gen_number, first_condemned_address,
(!settings.demotion && settings.promotion));
// fix_generation_bounds做的事情如下
// - 应用各个代的计划代边界
// - generation_allocation_start (gen) = generation_plan_allocation_start (gen)
// - generation_allocation_pointer (gen) = 0;
// - generation_allocation_limit (gen) = 0;
// - 代边界的开始会留一段min_obj_size的空间,把这段空间变为free object
// - 如果ephemeral segment已改变则设置旧ephemeral segment的start到allocated的整个范围到Card Table
// - 设置ephemeral_heap_segment的allocated到plan_allocated
fix_generation_bounds (condemned_gen_number, consing_gen);
assert (generation_allocation_limit (youngest_generation) ==
generation_allocation_pointer (youngest_generation));
// 删除空的(无存活对象的)小对象segment
// 修复segment链表,如果ephemeral heap segment因为expand_heap改变了这里会重新正确的链接各个segment
// 修复segment的处理
// - 如果segment的next是null且堆段不是ephemeral segment, 则next = ephemeral segment
// - 如果segment是ephemeral_heap_segment并且有next, 则单独把这个segment抽出来(prev.next = next)
// - 调用delete_heap_segment删除无存活对象的segment
// - 设置heap_segment_allocated (seg) = heap_segment_plan_allocated (seg)
// - 如果segment不是ephemeral segment, 则调用decommit_heap_segment_pages释放allocated到committed的内存
if (condemned_gen_number >= (max_generation -1))
{
#ifdef MULTIPLE_HEAPS
// this needs be serialized just because we have one
// segment_standby_list/seg_table for all heaps. We should make it at least
// so that when hoarding is not on we don't need this join because
// decommitting memory can take a long time.
//must serialize on deleting segments
gc_t_join.join(this, gc_join_rearrange_segs_compaction);
if (gc_t_join.joined())
{
for (int i = 0; i < n_heaps; i++)
{
g_heaps[i]->rearrange_heap_segments(TRUE);
}
gc_t_join.restart();
}
#else
rearrange_heap_segments(TRUE);
#endif //MULTIPLE_HEAPS
// 重新设置第0代和第1代的generation_start_segment和generation_allocation_segment到新的ephemeral_heap_segment
if (should_expand)
{
//fix the start_segment for the ephemeral generations
for (int i = 0; i < max_generation; i++)
{
generation* gen = generation_of (i);
generation_start_segment (gen) = ephemeral_heap_segment;
generation_allocation_segment (gen) = ephemeral_heap_segment;
}
}
}
{
// 因为析构队列中的对象分代储存,这里根据升代或者降代移动析构队列中的对象
#ifdef FEATURE_PREMORTEM_FINALIZATION
finalize_queue->UpdatePromotedGenerations (condemned_gen_number,
(!settings.demotion && settings.promotion));
#endif // FEATURE_PREMORTEM_FINALIZATION
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining after end of compaction"));
gc_t_join.join(this, gc_join_adjust_handle_age_compact);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
//join all threads to make sure they are synchronized
dprintf(3, ("Restarting after Promotion granted"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 更新GC Handle表中记录的代数
// GcPromotionsGranted的处理:
// 调用 Ref_AgeHandles(condemned, max_gen, (uintptr_t)sc)
// GcDemote的处理:
// 调用 Ref_RejuvenateHandles (condemned, max_gen, (uintptr_t)sc)
// Ref_AgeHandles的处理:
// 扫描g_HandleTableMap中的HandleTable, 逐个调用 BlockAgeBlocks
// BlockAgeBlocks会增加rgGeneration+uBlock~uCount中的数字
// 0x00ffffff => 0x01ffffff => 0x02ffffff
// #define COMPUTE_AGED_CLUMPS(gen, msk) APPLY_CLUMP_ADDENDS(gen, COMPUTE_CLUMP_ADDENDS(gen, msk))
// #define COMPUTE_AGED_CLUMPS(gen, msk) gen + COMPUTE_CLUMP_ADDENDS(gen, msk)
// #define COMPUTE_AGED_CLUMPS(gen, msk) gen + MAKE_CLUMP_MASK_ADDENDS(COMPUTE_CLUMP_MASK(gen, msk))
// #define COMPUTE_AGED_CLUMPS(gen, msk) gen + MAKE_CLUMP_MASK_ADDENDS((((gen & GEN_CLAMP) - msk) & GEN_MASK))
// #define COMPUTE_AGED_CLUMPS(gen, msk) gen + (((((gen & GEN_CLAMP) - msk) & GEN_MASK)) >> GEN_INC_SHIFT)
// #define COMPUTE_AGED_CLUMPS(gen, msk) gen + (((((gen & 0x3F3F3F3F) - msk) & 0x40404040)) >> 6)
// #define GEN_FULLGC PREFOLD_FILL_INTO_AGEMASK(GEN_AGE_LIMIT)
// #define GEN_FULLGC PREFOLD_FILL_INTO_AGEMASK(0x3E3E3E3E)
// #define GEN_FULLGC (1 + (0x3E3E3E3E) + (~GEN_FILL))
// #define GEN_FULLGC (1 + (0x3E3E3E3E) + (~0x80808080))
// #define GEN_FULLGC 0xbfbfbfbe
// Ref_RejuvenateHandles的处理:
// 扫描g_HandleTableMap中的HandleTable, 逐个调用 BlockResetAgeMapForBlocks
// BlockAgeBlocks会减少rgGeneration+uBlock~uCount中的数字
// 取决于该block中的handle中最年轻的代数
// rgGeneration
// 一个block对应4 byte, 第一个byte代表该block中的GCHandle的代
ScanContext sc;
sc.thread_number = heap_number;
sc.promotion = FALSE;
sc.concurrent = FALSE;
// new generations bounds are set can call this guy
if (settings.promotion && !settings.demotion)
{
dprintf (2, ("Promoting EE roots for gen %d",
condemned_gen_number));
GCScan::GcPromotionsGranted(condemned_gen_number,
max_generation, &sc);
}
else if (settings.demotion)
{
dprintf (2, ("Demoting EE roots for gen %d",
condemned_gen_number));
GCScan::GcDemote (condemned_gen_number, max_generation, &sc);
}
}
// 把各个pinned plug前面的空余空间(出队后的len)变为free object并加到free list中
{
gen0_big_free_spaces = 0;
// 队列底部等于0
reset_pinned_queue_bos();
unsigned int gen_number = min (max_generation, 1 + condemned_gen_number);
generation* gen = generation_of (gen_number);
uint8_t* low = generation_allocation_start (generation_of (gen_number-1));
uint8_t* high = heap_segment_allocated (ephemeral_heap_segment);
while (!pinned_plug_que_empty_p())
{
// 出队
mark* m = pinned_plug_of (deque_pinned_plug());
size_t len = pinned_len (m);
uint8_t* arr = (pinned_plug (m) - len);
dprintf(3,("free [%Ix %Ix[ pin",
(size_t)arr, (size_t)arr + len));
if (len != 0)
{
// 在pinned plug前的空余空间创建free object
assert (len >= Align (min_obj_size));
make_unused_array (arr, len);
// fix fully contained bricks + first one
// if the array goes beyong the first brick
size_t start_brick = brick_of (arr);
size_t end_brick = brick_of (arr + len);
// 如果free object横跨多个brick,更新brick表
if (end_brick != start_brick)
{
dprintf (3,
("Fixing bricks [%Ix, %Ix[ to point to unused array %Ix",
start_brick, end_brick, (size_t)arr));
set_brick (start_brick,
arr - brick_address (start_brick));
size_t brick = start_brick+1;
while (brick < end_brick)
{
set_brick (brick, start_brick - brick);
brick++;
}
}
// 判断要加到哪个代的free list中
//when we take an old segment to make the new
//ephemeral segment. we can have a bunch of
//pinned plugs out of order going to the new ephemeral seg
//and then the next plugs go back to max_generation
if ((heap_segment_mem (ephemeral_heap_segment) <= arr) &&
(heap_segment_reserved (ephemeral_heap_segment) > arr))
{
while ((low <= arr) && (high > arr))
{
gen_number--;
assert ((gen_number >= 1) || (demotion_low != MAX_PTR) ||
settings.demotion || !settings.promotion);
dprintf (3, ("new free list generation %d", gen_number));
gen = generation_of (gen_number);
if (gen_number >= 1)
low = generation_allocation_start (generation_of (gen_number-1));
else
low = high;
}
}
else
{
dprintf (3, ("new free list generation %d", max_generation));
gen_number = max_generation;
gen = generation_of (gen_number);
}
// 加到free list中
dprintf(3,("threading it into generation %d", gen_number));
thread_gap (arr, len, gen);
add_gen_free (gen_number, len);
}
}
}
#ifdef _DEBUG
for (int x = 0; x <= max_generation; x++)
{
assert (generation_allocation_start (generation_of (x)));
}
#endif //_DEBUG
// 如果已经升代了,原来gen 0的对象会变为gen 1
// 清理当前gen 1在Card Table中的标记
if (!settings.demotion && settings.promotion)
{
//clear card for generation 1. generation 0 is empty
clear_card_for_addresses (
generation_allocation_start (generation_of (1)),
generation_allocation_start (generation_of (0)));
}
// 如果已经升代了,确认代0的只包含一个对象(一个最小大小的free object)
if (settings.promotion && !settings.demotion)
{
uint8_t* start = generation_allocation_start (youngest_generation);
MAYBE_UNUSED_VAR(start);
assert (heap_segment_allocated (ephemeral_heap_segment) ==
(start + Align (size (start))));
}
}
// 进入清扫阶段
// 清扫阶段的关键处理在make_free_lists中,目前你看不到叫`sweep_phase`的函数,这里就是sweep phase
else
{
// 清扫阶段必须升代
//force promotion for sweep
settings.promotion = TRUE;
settings.compaction = FALSE;
ScanContext sc;
sc.thread_number = heap_number;
sc.promotion = FALSE;
sc.concurrent = FALSE;
dprintf (2, ("**** Doing Mark and Sweep GC****"));
// 恢复对旧代成员的备份
if ((condemned_gen_number < max_generation))
{
generation_allocator (older_gen)->copy_from_alloc_list (r_free_list);
generation_free_list_space (older_gen) = r_free_list_space;
generation_free_obj_space (older_gen) = r_free_obj_space;
generation_free_list_allocated (older_gen) = r_older_gen_free_list_allocated;
generation_end_seg_allocated (older_gen) = r_older_gen_end_seg_allocated;
generation_condemned_allocated (older_gen) = r_older_gen_condemned_allocated;
generation_allocation_limit (older_gen) = r_allocation_limit;
generation_allocation_pointer (older_gen) = r_allocation_pointer;
generation_allocation_context_start_region (older_gen) = r_allocation_start_region;
generation_allocation_segment (older_gen) = r_allocation_segment;
}
// 如果 generation_allocation_limit 等于 heap_segment_plan_allocated
// 设置 heap_segment_plan_allocated 等于 generation_allocation_pointer
// 设置 generation_allocation_limit 等于 generation_allocation_pointer
// 否则
// 在alloc_ptr到limit的空间创建一个free object, 不加入free list
if ((condemned_gen_number < max_generation))
{
// Fix the allocation area of the older generation
fix_older_allocation_area (older_gen);
}
#if defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
if (ShouldTrackMovementForProfilerOrEtw())
{
record_survived_for_profiler(condemned_gen_number, first_condemned_address);
}
#endif // defined(GC_PROFILING) || defined(FEATURE_EVENT_TRACE)
// 把不使用的空间变为free object并存到free list
gen0_big_free_spaces = 0;
make_free_lists (condemned_gen_number);
// 恢复在saved_pre_plug和saved_post_plug保存的原始数据
recover_saved_pinned_info();
// 因为析构队列中的对象分代储存,这里根据升代或者降代移动析构队列中的对象
#ifdef FEATURE_PREMORTEM_FINALIZATION
finalize_queue->UpdatePromotedGenerations (condemned_gen_number, TRUE);
#endif // FEATURE_PREMORTEM_FINALIZATION
// MTHTS: leave single thread for HT processing on plan_phase
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining after end of sweep"));
gc_t_join.join(this, gc_join_adjust_handle_age_sweep);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
// 更新GCHandle表中记录的代数
GCScan::GcPromotionsGranted(condemned_gen_number,
max_generation, &sc);
// 删除空的(无存活对象的)小对象segment和修复segment链表
// 上面有详细的注释
if (condemned_gen_number >= (max_generation -1))
{
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
{
g_heaps[i]->rearrange_heap_segments(FALSE);
}
#else
rearrange_heap_segments(FALSE);
#endif //MULTIPLE_HEAPS
}
#ifdef MULTIPLE_HEAPS
//join all threads to make sure they are synchronized
dprintf(3, ("Restarting after Promotion granted"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
#ifdef _DEBUG
for (int x = 0; x <= max_generation; x++)
{
assert (generation_allocation_start (generation_of (x)));
}
#endif //_DEBUG
// 因为已经升代了,原来gen 0的对象会变为gen 1
// 清理当前gen 1在Card Table中的标记
//clear card for generation 1. generation 0 is empty
clear_card_for_addresses (
generation_allocation_start (generation_of (1)),
generation_allocation_start (generation_of (0)));
assert ((heap_segment_allocated (ephemeral_heap_segment) ==
(generation_allocation_start (youngest_generation) +
Align (min_obj_size))));
}
//verify_partial();
}process_ephemeral_boundaries函数的代码:
如果当前模拟的segment是ephemeral heap segment,这个函数会在模拟当前plug的压缩前调用决定计划代边界
void gc_heap::process_ephemeral_boundaries (uint8_t* x,
int& active_new_gen_number,
int& active_old_gen_number,
generation*& consing_gen,
BOOL& allocate_in_condemned)
{
retry:
// 判断是否要设置计划代边界
// 例如当前启用升代
// - active_old_gen_number是1,active_new_gen_number是2
// - 判断plug属于gen 0的时候会计划gen 1(active_new_gen_number--)的边界
// 例如当前不启用升代
// - active_old_gen_number是1,active_new_gen_number是1
// - 判断plug属于gen 0的时候会计划gen 0(active_new_gen_number--)的边界
if ((active_old_gen_number > 0) &&
(x >= generation_allocation_start (generation_of (active_old_gen_number - 1))))
{
dprintf (1, ("crossing gen%d, x is %Ix", active_old_gen_number - 1, x));
if (!pinned_plug_que_empty_p())
{
dprintf (1, ("oldest pin: %Ix(%Id)",
pinned_plug (oldest_pin()),
(x - pinned_plug (oldest_pin()))));
}
// 如果升代
// active_old_gen_number: 2 => 1 => 0
// active_new_gen_number: 2 => 2 => 1
// 如果不升代
// active_old_gen_number: 2 => 1 => 0
// active_new_gen_number: 2 => 1 => 0
if (active_old_gen_number <= (settings.promotion ? (max_generation - 1) : max_generation))
{
active_new_gen_number--;
}
active_old_gen_number--;
assert ((!settings.promotion) || (active_new_gen_number>0));
if (active_new_gen_number == (max_generation - 1))
{
// 打印和设置统计信息
#ifdef FREE_USAGE_STATS
if (settings.condemned_generation == max_generation)
{
// We need to do this before we skip the rest of the pinned plugs.
generation* gen_2 = generation_of (max_generation);
generation* gen_1 = generation_of (max_generation - 1);
size_t total_num_pinned_free_spaces_left = 0;
// We are about to allocate gen1, check to see how efficient fitting in gen2 pinned free spaces is.
for (int j = 0; j < NUM_GEN_POWER2; j++)
{
dprintf (1, ("[h%d][#%Id]2^%d: current: %Id, S: 2: %Id, 1: %Id(%Id)",
heap_number,
settings.gc_index,
(j + 10),
gen_2->gen_current_pinned_free_spaces[j],
gen_2->gen_plugs[j], gen_1->gen_plugs[j],
(gen_2->gen_plugs[j] + gen_1->gen_plugs[j])));
total_num_pinned_free_spaces_left += gen_2->gen_current_pinned_free_spaces[j];
}
float pinned_free_list_efficiency = 0;
size_t total_pinned_free_space = generation_allocated_in_pinned_free (gen_2) + generation_pinned_free_obj_space (gen_2);
if (total_pinned_free_space != 0)
{
pinned_free_list_efficiency = (float)(generation_allocated_in_pinned_free (gen_2)) / (float)total_pinned_free_space;
}
dprintf (1, ("[h%d] gen2 allocated %Id bytes with %Id bytes pinned free spaces (effi: %d%%), %Id (%Id) left",
heap_number,
generation_allocated_in_pinned_free (gen_2),
total_pinned_free_space,
(int)(pinned_free_list_efficiency * 100),
generation_pinned_free_obj_space (gen_2),
total_num_pinned_free_spaces_left));
}
#endif //FREE_USAGE_STATS
// 出队mark_stack_array中不属于ephemeral heap segment的pinned plug,不能让它们降代
//Go past all of the pinned plugs for this generation.
while (!pinned_plug_que_empty_p() &&
(!in_range_for_segment ((pinned_plug (oldest_pin())), ephemeral_heap_segment)))
{
size_t entry = deque_pinned_plug();
mark* m = pinned_plug_of (entry);
uint8_t* plug = pinned_plug (m);
size_t len = pinned_len (m);
// detect pinned block in different segment (later) than
// allocation segment, skip those until the oldest pin is in the ephemeral seg.
// adjust the allocation segment along the way (at the end it will
// be the ephemeral segment.
heap_segment* nseg = heap_segment_in_range (generation_allocation_segment (consing_gen));
PREFIX_ASSUME(nseg != NULL);
while (!((plug >= generation_allocation_pointer (consing_gen))&&
(plug < heap_segment_allocated (nseg))))
{
//adjust the end of the segment to be the end of the plug
assert (generation_allocation_pointer (consing_gen)>=
heap_segment_mem (nseg));
assert (generation_allocation_pointer (consing_gen)<=
heap_segment_committed (nseg));
heap_segment_plan_allocated (nseg) =
generation_allocation_pointer (consing_gen);
//switch allocation segment
nseg = heap_segment_next_rw (nseg);
generation_allocation_segment (consing_gen) = nseg;
//reset the allocation pointer and limits
generation_allocation_pointer (consing_gen) =
heap_segment_mem (nseg);
}
set_new_pin_info (m, generation_allocation_pointer (consing_gen));
assert(pinned_len(m) == 0 || pinned_len(m) >= Align(min_obj_size));
generation_allocation_pointer (consing_gen) = plug + len;
generation_allocation_limit (consing_gen) =
generation_allocation_pointer (consing_gen);
}
allocate_in_condemned = TRUE;
consing_gen = ensure_ephemeral_heap_segment (consing_gen);
}
// active_new_gen_number不等于gen2的时候计划它的边界
// gen2的边界不会在这里计划,而是在前面(allocate_first_generation_start)
if (active_new_gen_number != max_generation)
{
// 防止降代的时候把所有pinned plug出队
if (active_new_gen_number == (max_generation - 1))
{
maxgen_pinned_compact_before_advance = generation_pinned_allocation_compact_size (generation_of (max_generation));
if (!demote_gen1_p)
advance_pins_for_demotion (consing_gen);
}
// 根据当前的generaion_allocation_pointer(alloc_ptr)计划代边界
plan_generation_start (generation_of (active_new_gen_number), consing_gen, x);
dprintf (1, ("process eph: allocated gen%d start at %Ix",
active_new_gen_number,
generation_plan_allocation_start (generation_of (active_new_gen_number))));
// 如果队列中仍然有pinned plug
if ((demotion_low == MAX_PTR) && !pinned_plug_que_empty_p())
{
// 并且最老(最左边)的pinned plug的代数不是0的时候
uint8_t* pplug = pinned_plug (oldest_pin());
if (object_gennum (pplug) > 0)
{
// 表示从这个pinned plug和后面的pinned plug都被降代了
// 设置降代范围
demotion_low = pplug;
dprintf (3, ("process eph: dlow->%Ix", demotion_low));
}
}
assert (generation_plan_allocation_start (generation_of (active_new_gen_number)));
}
goto retry;
}
}gc_heap::plan_generation_start函数的代码如下:
根据当前的generaion_allocation_pointer(alloc_ptr)计划代边界
void gc_heap::plan_generation_start (generation* gen, generation* consing_gen, uint8_t* next_plug_to_allocate)
{
// 特殊处理
// 如果某些pinned plug很大(大于demotion_plug_len_th(6MB)),把它们出队防止降代
#ifdef BIT64
// We should never demote big plugs to gen0.
if (gen == youngest_generation)
{
heap_segment* seg = ephemeral_heap_segment;
size_t mark_stack_large_bos = mark_stack_bos;
size_t large_plug_pos = 0;
while (mark_stack_large_bos < mark_stack_tos)
{
if (mark_stack_array[mark_stack_large_bos].len > demotion_plug_len_th)
{
while (mark_stack_bos <= mark_stack_large_bos)
{
size_t entry = deque_pinned_plug();
size_t len = pinned_len (pinned_plug_of (entry));
uint8_t* plug = pinned_plug (pinned_plug_of(entry));
if (len > demotion_plug_len_th)
{
dprintf (2, ("ps(%d): S %Ix (%Id)(%Ix)", gen->gen_num, plug, len, (plug+len)));
}
pinned_len (pinned_plug_of (entry)) = plug - generation_allocation_pointer (consing_gen);
assert(mark_stack_array[entry].len == 0 ||
mark_stack_array[entry].len >= Align(min_obj_size));
generation_allocation_pointer (consing_gen) = plug + len;
generation_allocation_limit (consing_gen) = heap_segment_plan_allocated (seg);
set_allocator_next_pin (consing_gen);
}
}
mark_stack_large_bos++;
}
}
#endif // BIT64
// 在当前consing_gen的generation_allocation_ptr创建一个最小的对象
// 以这个对象的开始地址作为计划代边界
// 这里的处理是保证代与代之间最少有一个对象(初始化代的时候也会这样保证)
generation_plan_allocation_start (gen) =
allocate_in_condemned_generations (consing_gen, Align (min_obj_size), -1);
// 压缩后会根据这个大小把这里的空间变为一个free object
generation_plan_allocation_start_size (gen) = Align (min_obj_size);
// 如果接下来的空间很小(小于min_obj_size),则把接下来的空间也加到上面的初始对象里
size_t allocation_left = (size_t)(generation_allocation_limit (consing_gen) - generation_allocation_pointer (consing_gen));
if (next_plug_to_allocate)
{
size_t dist_to_next_plug = (size_t)(next_plug_to_allocate - generation_allocation_pointer (consing_gen));
if (allocation_left > dist_to_next_plug)
{
allocation_left = dist_to_next_plug;
}
}
if (allocation_left < Align (min_obj_size))
{
generation_plan_allocation_start_size (gen) += allocation_left;
generation_allocation_pointer (consing_gen) += allocation_left;
}
dprintf (1, ("plan alloc gen%d(%Ix) start at %Ix (ptr: %Ix, limit: %Ix, next: %Ix)", gen->gen_num,
generation_plan_allocation_start (gen),
generation_plan_allocation_start_size (gen),
generation_allocation_pointer (consing_gen), generation_allocation_limit (consing_gen),
next_plug_to_allocate));
}gc_heap::plan_generation_starts函数的代码如下:
这个函数会在模拟压缩所有对象后调用,用于计划剩余的代边界,如果启用了升代这里会计划gen 0的边界
void gc_heap::plan_generation_starts (generation*& consing_gen)
{
//make sure that every generation has a planned allocation start
int gen_number = settings.condemned_generation;
while (gen_number >= 0)
{
// 因为不能把gen 1和gen 0的边界放到其他segment中
// 这里需要确保consing_gen的allocation segment是ephemeral heap segment
if (gen_number < max_generation)
{
consing_gen = ensure_ephemeral_heap_segment (consing_gen);
}
// 如果这个代的边界尚未计划,则执行计划
generation* gen = generation_of (gen_number);
if (0 == generation_plan_allocation_start (gen))
{
plan_generation_start (gen, consing_gen, 0);
assert (generation_plan_allocation_start (gen));
}
gen_number--;
}
// 设置ephemeral heap segment的计划已分配大小
// now we know the planned allocation size
heap_segment_plan_allocated (ephemeral_heap_segment) =
generation_allocation_pointer (consing_gen);
}gc_heap::generation_fragmentation函数的代码如下:
size_t gc_heap::generation_fragmentation (generation* gen,
generation* consing_gen,
uint8_t* end)
{
size_t frag;
// 判断是否所有对象都压缩到了ephemeral heap segment之前
uint8_t* alloc = generation_allocation_pointer (consing_gen);
// If the allocation pointer has reached the ephemeral segment
// fine, otherwise the whole ephemeral segment is considered
// fragmentation
if (in_range_for_segment (alloc, ephemeral_heap_segment))
{
// 原allocated - 模拟压缩的结尾allocation_pointer
if (alloc <= heap_segment_allocated(ephemeral_heap_segment))
frag = end - alloc;
else
{
// 无一个对象存活,已经把allocated设到开始地址
// case when no survivors, allocated set to beginning
frag = 0;
}
dprintf (3, ("ephemeral frag: %Id", frag));
}
else
// 所有对象都压缩到了ephemeral heap segment之前
// 添加整个范围到frag
frag = (heap_segment_allocated (ephemeral_heap_segment) -
heap_segment_mem (ephemeral_heap_segment));
heap_segment* seg = heap_segment_rw (generation_start_segment (gen));
PREFIX_ASSUME(seg != NULL);
// 添加其他segment的原allocated - 计划allcated
while (seg != ephemeral_heap_segment)
{
frag += (heap_segment_allocated (seg) -
heap_segment_plan_allocated (seg));
dprintf (3, ("seg: %Ix, frag: %Id", (size_t)seg,
(heap_segment_allocated (seg) -
heap_segment_plan_allocated (seg))));
seg = heap_segment_next_rw (seg);
assert (seg);
}
// 添加所有pinned plug前面的空余空间
dprintf (3, ("frag: %Id discounting pinned plugs", frag));
//add the length of the dequeued plug free space
size_t bos = 0;
while (bos < mark_stack_bos)
{
frag += (pinned_len (pinned_plug_of (bos)));
bos++;
}
return frag;
}gc_heap::decide_on_compacting函数的代码如下:
BOOL gc_heap::decide_on_compacting (int condemned_gen_number,
size_t fragmentation,
BOOL& should_expand)
{
BOOL should_compact = FALSE;
should_expand = FALSE;
generation* gen = generation_of (condemned_gen_number);
dynamic_data* dd = dynamic_data_of (condemned_gen_number);
size_t gen_sizes = generation_sizes(gen);
// 碎片空间大小 / 收集代的大小(包括更年轻的代)
float fragmentation_burden = ( ((0 == fragmentation) || (0 == gen_sizes)) ? (0.0f) :
(float (fragmentation) / gen_sizes) );
dprintf (GTC_LOG, ("fragmentation: %Id (%d%%)", fragmentation, (int)(fragmentation_burden * 100.0)));
// 由Stress GC决定是否压缩
#ifdef STRESS_HEAP
// for pure GC stress runs we need compaction, for GC stress "mix"
// we need to ensure a better mix of compacting and sweeping collections
if (GCStress::IsEnabled() && !settings.concurrent
&& !g_pConfig->IsGCStressMix())
should_compact = TRUE;
// 由Stress GC决定是否压缩
// 如果压缩次数不够清扫次数的十分之一则开启压缩
#ifdef GC_STATS
// in GC stress "mix" mode, for stress induced collections make sure we
// keep sweeps and compactions relatively balanced. do not (yet) force sweeps
// against the GC's determination, as it may lead to premature OOMs.
if (g_pConfig->IsGCStressMix() && settings.stress_induced)
{
int compactions = g_GCStatistics.cntCompactFGC+g_GCStatistics.cntCompactNGC;
int sweeps = g_GCStatistics.cntFGC + g_GCStatistics.cntNGC - compactions;
if (compactions < sweeps / 10)
{
should_compact = TRUE;
}
}
#endif // GC_STATS
#endif //STRESS_HEAP
// 判断是否强制压缩
if (g_pConfig->GetGCForceCompact())
should_compact = TRUE;
// 是否因为OOM(Out Of Memory)导致的GC,如果是则开启压缩
if ((condemned_gen_number == max_generation) && last_gc_before_oom)
{
should_compact = TRUE;
last_gc_before_oom = FALSE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_last_gc);
}
// gc原因中有压缩
if (settings.reason == reason_induced_compacting)
{
dprintf (2, ("induced compacting GC"));
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_induced_compacting);
}
dprintf (2, ("Fragmentation: %d Fragmentation burden %d%%",
fragmentation, (int) (100*fragmentation_burden)));
// 如果ephemeral heap segment的空间较少则开启压缩
if (!should_compact)
{
if (dt_low_ephemeral_space_p (tuning_deciding_compaction))
{
dprintf(GTC_LOG, ("compacting due to low ephemeral"));
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_low_ephemeral);
}
}
// 如果ephemeral heap segment的空间较少,并且当前不是Full GC还需要使用新的ephemeral heap segment
if (should_compact)
{
if ((condemned_gen_number >= (max_generation - 1)))
{
if (dt_low_ephemeral_space_p (tuning_deciding_expansion))
{
dprintf (GTC_LOG,("Not enough space for all ephemeral generations with compaction"));
should_expand = TRUE;
}
}
}
#ifdef BIT64
BOOL high_memory = FALSE;
#endif // BIT64
// 根据碎片空间大小判断
if (!should_compact)
{
// We are not putting this in dt_high_frag_p because it's not exactly
// high fragmentation - it's just enough planned fragmentation for us to
// want to compact. Also the "fragmentation" we are talking about here
// is different from anywhere else.
// 碎片空间大小 >= dd_fragmentation_limit 或者
// 碎片空间大小 / 收集代的大小(包括更年轻的代) >= dd_fragmentation_burden_limit 时开启压缩
// 作者机器上的dd_fragmentation_limit是200000, dd_fragmentation_burden_limit是0.25
BOOL frag_exceeded = ((fragmentation >= dd_fragmentation_limit (dd)) &&
(fragmentation_burden >= dd_fragmentation_burden_limit (dd)));
if (frag_exceeded)
{
#ifdef BACKGROUND_GC
// do not force compaction if this was a stress-induced GC
IN_STRESS_HEAP(if (!settings.stress_induced))
{
#endif // BACKGROUND_GC
assert (settings.concurrent == FALSE);
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_high_frag);
#ifdef BACKGROUND_GC
}
#endif // BACKGROUND_GC
}
// 如果占用内存过高则启用压缩
#ifdef BIT64
// check for high memory situation
if(!should_compact)
{
uint32_t num_heaps = 1;
#ifdef MULTIPLE_HEAPS
num_heaps = gc_heap::n_heaps;
#endif // MULTIPLE_HEAPS
ptrdiff_t reclaim_space = generation_size(max_generation) - generation_plan_size(max_generation);
if((settings.entry_memory_load >= high_memory_load_th) && (settings.entry_memory_load < v_high_memory_load_th))
{
if(reclaim_space > (int64_t)(min_high_fragmentation_threshold (entry_available_physical_mem, num_heaps)))
{
dprintf(GTC_LOG,("compacting due to fragmentation in high memory"));
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_high_mem_frag);
}
high_memory = TRUE;
}
else if(settings.entry_memory_load >= v_high_memory_load_th)
{
if(reclaim_space > (ptrdiff_t)(min_reclaim_fragmentation_threshold (num_heaps)))
{
dprintf(GTC_LOG,("compacting due to fragmentation in very high memory"));
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_vhigh_mem_frag);
}
high_memory = TRUE;
}
}
#endif // BIT64
}
// 测试是否可以在ephemeral_heap_segment.allocated后面提交一段内存(从系统获取一块物理内存)
// 如果失败则启用压缩
allocated (ephemeral_heap_segment);
size_t size = Align (min_obj_size)*(condemned_gen_number+1);
// The purpose of calling ensure_gap_allocation here is to make sure
// that we actually are able to commit the memory to allocate generation
// starts.
if ((should_compact == FALSE) &&
(ensure_gap_allocation (condemned_gen_number) == FALSE))
{
should_compact = TRUE;
get_gc_data_per_heap()->set_mechanism (gc_heap_compact, compact_no_gaps);
}
// 如果这次Full GC的效果比较差
// 需要减少Full GC的频率,should_lock_elevation可以把Full GC变为gen 1 GC
if (settings.condemned_generation == max_generation)
{
//check the progress
if (
#ifdef BIT64
(high_memory && !should_compact) ||
#endif // BIT64
(generation_plan_allocation_start (generation_of (max_generation - 1)) >=
generation_allocation_start (generation_of (max_generation - 1))))
{
dprintf (2, (" Elevation: gen2 size: %d, gen2 plan size: %d, no progress, elevation = locked",
generation_size (max_generation),
generation_plan_size (max_generation)));
//no progress -> lock
settings.should_lock_elevation = TRUE;
}
}
// 如果启用了NoGCRegion但是仍然启用了GC代表这是无法从SOH(Small Object Heap)或者LOH分配到内存导致的,需要启用压缩
if (settings.pause_mode == pause_no_gc)
{
should_compact = TRUE;
// 如果ephemeral heap segement压缩后的剩余空间不足还需要设置新的ephemeral heap segment
if ((size_t)(heap_segment_reserved (ephemeral_heap_segment) - heap_segment_plan_allocated (ephemeral_heap_segment))
< soh_allocation_no_gc)
{
should_expand = TRUE;
}
}
dprintf (2, ("will %s", (should_compact ? "compact" : "sweep")));
return should_compact;
} 计划阶段在模拟压缩和判断后会在内部包含重定位阶段(relocate_phase),压缩阶段(compact_phase)和清扫阶段(sweep_phase)的处理,
接下来我们仔细分析一下这三个阶段做了什么事情:
重定位阶段(relocate_phase)
重定位阶段的主要工作是修改对象的指针地址,例如A.Member的Member内存移动后,A中指向Member的指针地址也需要改变。
重定位阶段只会修改指针地址,复制内存会交给下面的压缩阶段(compact_phase)完成。
如下图:
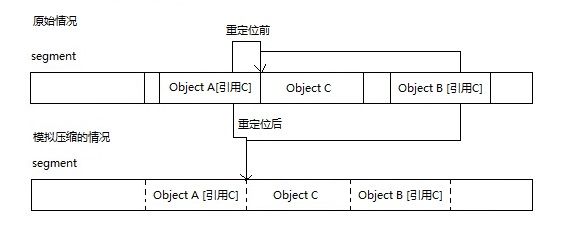
图中对象A和对象B引用了对象C,重定位后各个对象还在原来的位置,只是成员的地址(指针)变化了。
还记得之前标记阶段(mark_phase)使用的GcScanRoots等扫描函数吗?
这些扫描函数同样会在重定位阶段使用,只是执行的不是GCHeap::Promote而是GCHeap::Relocate。
重定位对象会借助计划阶段(plan_phase)构建的brick table和plug树来进行快速的定位,然后对指针地址移动所属plug的reloc位置。
重定位阶段(relocate_phase)的代码
gc_heap::relocate_phase函数的代码如下:
void gc_heap::relocate_phase (int condemned_gen_number,
uint8_t* first_condemned_address)
{
// 生成扫描上下文
ScanContext sc;
sc.thread_number = heap_number;
sc.promotion = FALSE;
sc.concurrent = FALSE;
// 统计重定位阶段的开始时间
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
// %type% category = quote (relocate);
dprintf (2,("---- Relocate phase -----"));
#ifdef MULTIPLE_HEAPS
//join all threads to make sure they are synchronized
dprintf(3, ("Joining after end of plan"));
gc_t_join.join(this, gc_join_begin_relocate_phase);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
//join all threads to make sure they are synchronized
dprintf(3, ("Restarting for relocation"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 扫描根对象(各个线程中栈和寄存器中的对象)
// 对扫描到的各个对象调用`GCHeap::Relocate`函数
// 注意`GCHeap::Relocate`函数不会重定位子对象,这里只是用来重定位来源于根对象的引用
dprintf(3,("Relocating roots"));
GCScan::GcScanRoots(GCHeap::Relocate,
condemned_gen_number, max_generation, &sc);
verify_pins_with_post_plug_info("after reloc stack");
#ifdef BACKGROUND_GC
if (recursive_gc_sync::background_running_p())
{
scan_background_roots (GCHeap::Relocate, heap_number, &sc);
}
#endif //BACKGROUND_GC
// 非Full GC时,遍历Card Table重定位小对象
// 同上,`gc_heap::relocate_address`函数不会重定位子对象,这里只是用来重定位来源于旧代的引用
if (condemned_gen_number != max_generation)
{
dprintf(3,("Relocating cross generation pointers"));
mark_through_cards_for_segments (&gc_heap::relocate_address, TRUE);
verify_pins_with_post_plug_info("after reloc cards");
}
// 非Full GC时,遍历Card Table重定位大对象
// 同上,`gc_heap::relocate_address`函数不会重定位子对象,这里只是用来重定位来源于旧代的引用
if (condemned_gen_number != max_generation)
{
dprintf(3,("Relocating cross generation pointers for large objects"));
mark_through_cards_for_large_objects (&gc_heap::relocate_address, TRUE);
}
else
{
// Full GC时,如果启用了大对象压缩则压缩大对象的堆
#ifdef FEATURE_LOH_COMPACTION
if (loh_compacted_p)
{
assert (settings.condemned_generation == max_generation);
relocate_in_loh_compact();
}
else
#endif //FEATURE_LOH_COMPACTION
{
relocate_in_large_objects ();
}
}
// 重定位存活下来的对象中的引用(收集代中的对象)
// 枚举brick table对各个plug中的对象调用`relocate_obj_helper`重定位它们的成员
{
dprintf(3,("Relocating survivors"));
relocate_survivors (condemned_gen_number,
first_condemned_address);
}
// 扫描在析构队列中的对象
#ifdef FEATURE_PREMORTEM_FINALIZATION
dprintf(3,("Relocating finalization data"));
finalize_queue->RelocateFinalizationData (condemned_gen_number,
__this);
#endif // FEATURE_PREMORTEM_FINALIZATION
// 扫描在GC Handle表中的对象
// MTHTS
{
dprintf(3,("Relocating handle table"));
GCScan::GcScanHandles(GCHeap::Relocate,
condemned_gen_number, max_generation, &sc);
}
#ifdef MULTIPLE_HEAPS
//join all threads to make sure they are synchronized
dprintf(3, ("Joining after end of relocation"));
gc_t_join.join(this, gc_join_relocate_phase_done);
#endif //MULTIPLE_HEAPS
// 统计重定位阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
reloc_time = finish - start;
#endif //TIME_GC
dprintf(2,( "---- End of Relocate phase ----"));
}GCHeap::Relocate函数的代码如下:
// ppObject是保存对象地址的地址,例如&A.Member
void GCHeap::Relocate (Object** ppObject, ScanContext* sc,
uint32_t flags)
{
UNREFERENCED_PARAMETER(sc);
// 对象的地址
uint8_t* object = (uint8_t*)(Object*)(*ppObject);
THREAD_NUMBER_FROM_CONTEXT;
//dprintf (3, ("Relocate location %Ix\n", (size_t)ppObject));
dprintf (3, ("R: %Ix", (size_t)ppObject));
// 空指针不处理
if (object == 0)
return;
// 获取对象所属的gc_heap
gc_heap* hp = gc_heap::heap_of (object);
// 验证对象是否合法,除错用
// 如果object不一定是对象的开始地址,则不做验证
#ifdef _DEBUG
if (!(flags & GC_CALL_INTERIOR))
{
// We cannot validate this object if it's in the condemned gen because it could
// be one of the objects that were overwritten by an artificial gap due to a pinned plug.
if (!((object >= hp->gc_low) && (object < hp->gc_high)))
{
((CObjectHeader*)object)->Validate(FALSE);
}
}
#endif //_DEBUG
dprintf (3, ("Relocate %Ix\n", (size_t)object));
uint8_t* pheader;
// 如果object不一定是对象的开始地址,找到对象的开始地址并重定位该开始地址,然后修改ppObject
// 例如object是0x10000008,对象的开始地址是0x10000000,重定位后是0x0fff0000则*ppObject会设为0x0fff0008
if ((flags & GC_CALL_INTERIOR) && gc_heap::settings.loh_compaction)
{
if (!((object >= hp->gc_low) && (object < hp->gc_high)))
{
return;
}
if (gc_heap::loh_object_p (object))
{
pheader = hp->find_object (object, 0);
if (pheader == 0)
{
return;
}
ptrdiff_t ref_offset = object - pheader;
hp->relocate_address(&pheader THREAD_NUMBER_ARG);
*ppObject = (Object*)(pheader + ref_offset);
return;
}
}
// 如果object是对象的开始地址则重定位object
{
pheader = object;
hp->relocate_address(&pheader THREAD_NUMBER_ARG);
*ppObject = (Object*)pheader;
}
STRESS_LOG_ROOT_RELOCATE(ppObject, object, pheader, ((!(flags & GC_CALL_INTERIOR)) ? ((Object*)object)->GetGCSafeMethodTable() : 0));
}gc_heap::relocate_address函数的代码如下:
void gc_heap::relocate_address (uint8_t** pold_address THREAD_NUMBER_DCL)
{
// 不在本次gc回收范围内的对象指针不需要移动
uint8_t* old_address = *pold_address;
if (!((old_address >= gc_low) && (old_address < gc_high)))
#ifdef MULTIPLE_HEAPS
{
UNREFERENCED_PARAMETER(thread);
if (old_address == 0)
return;
gc_heap* hp = heap_of (old_address);
if ((hp == this) ||
!((old_address >= hp->gc_low) && (old_address < hp->gc_high)))
return;
}
#else //MULTIPLE_HEAPS
return ;
#endif //MULTIPLE_HEAPS
// 根据对象找到对应的brick
// delta translates old_address into address_gc (old_address);
size_t brick = brick_of (old_address);
int brick_entry = brick_table [ brick ];
uint8_t* new_address = old_address;
if (! ((brick_entry == 0)))
{
retry:
{
// 如果是负数则向前继续找
while (brick_entry < 0)
{
brick = (brick + brick_entry);
brick_entry = brick_table [ brick ];
}
uint8_t* old_loc = old_address;
// 根据plug树搜索对象所在的plug
uint8_t* node = tree_search ((brick_address (brick) + brick_entry-1),
old_loc);
// 找到时确定新的地址,找不到时继续找前面的brick(有可能在上一个brick中)
if ((node <= old_loc))
new_address = (old_address + node_relocation_distance (node));
else
{
if (node_left_p (node))
{
dprintf(3,(" L: %Ix", (size_t)node));
new_address = (old_address +
(node_relocation_distance (node) +
node_gap_size (node)));
}
else
{
brick = brick - 1;
brick_entry = brick_table [ brick ];
goto retry;
}
}
}
// 修改对象指针的地址
*pold_address = new_address;
return;
}
// 如果对象是大对象,对象本身就是一个plug所以可以直接取到reloc
#ifdef FEATURE_LOH_COMPACTION
if (loh_compacted_p
#ifdef FEATURE_BASICFREEZE
&& !frozen_object_p((Object*)old_address)
#endif // FEATURE_BASICFREEZE
)
{
*pold_address = old_address + loh_node_relocation_distance (old_address);
}
else
#endif //FEATURE_LOH_COMPACTION
{
*pold_address = new_address;
}
}gc_heap::relocate_survivors函数的代码如下:
这个函数用于重定位存活下来的对象中的引用
void gc_heap::relocate_survivors (int condemned_gen_number,
uint8_t* first_condemned_address)
{
generation* condemned_gen = generation_of (condemned_gen_number);
uint8_t* start_address = first_condemned_address;
size_t current_brick = brick_of (start_address);
heap_segment* current_heap_segment = heap_segment_rw (generation_start_segment (condemned_gen));
PREFIX_ASSUME(current_heap_segment != NULL);
uint8_t* end_address = 0;
// 重设mark_stack_array队列
reset_pinned_queue_bos();
// 更新gc_heap中的oldest_pinned_plug对象
update_oldest_pinned_plug();
end_address = heap_segment_allocated (current_heap_segment);
size_t end_brick = brick_of (end_address - 1);
// 初始化重定位参数
relocate_args args;
// 本次gc的回收范围
args.low = gc_low;
args.high = gc_high;
// 当前的plug结尾是否被下一个plug覆盖了
args.is_shortened = FALSE
// last_plug或者last_plug后面的pinned plug
// 处理plug尾部数据覆盖时需要用到它
args.pinned_plug_entry = 0;
// 上一个plug,用于遍历树时可以从小地址到大地址遍历(中序遍历)
args.last_plug = 0;
while (1)
{
// 当前segment已经处理完
if (current_brick > end_brick)
{
// 处理最后一个plug,结尾地址是heap_segment_allocated
if (args.last_plug)
{
{
assert (!(args.is_shortened));
relocate_survivors_in_plug (args.last_plug,
heap_segment_allocated (current_heap_segment),
args.is_shortened,
args.pinned_plug_entry);
}
args.last_plug = 0;
}
// 如果有下一个segment则处理下一个
if (heap_segment_next_rw (current_heap_segment))
{
current_heap_segment = heap_segment_next_rw (current_heap_segment);
current_brick = brick_of (heap_segment_mem (current_heap_segment));
end_brick = brick_of (heap_segment_allocated (current_heap_segment)-1);
continue;
}
else
{
break;
}
}
{
// 如果当前brick有对应的plug树,处理当前brick
int brick_entry = brick_table [ current_brick ];
if (brick_entry >= 0)
{
relocate_survivors_in_brick (brick_address (current_brick) +
brick_entry -1,
&args);
}
}
current_brick++;
}
}gc_heap::relocate_survivors_in_brick函数的代码如下:
void gc_heap::relocate_survivors_in_brick (uint8_t* tree, relocate_args* args)
{
// 遍历plug树
// 会从小到大调用relocate_survivors_in_plug (中序遍历, 借助args->last_plug)
// 例如有这样的plug树
// a
// b c
// d e
// 枚举顺序是a b d e c
// 调用relocate_survivors_in_plug的顺序是d b e a c
assert ((tree != NULL));
dprintf (3, ("tree: %Ix, args->last_plug: %Ix, left: %Ix, right: %Ix, gap(t): %Ix",
tree, args->last_plug,
(tree + node_left_child (tree)),
(tree + node_right_child (tree)),
node_gap_size (tree)));
// 处理左节点
if (node_left_child (tree))
{
relocate_survivors_in_brick (tree + node_left_child (tree), args);
}
// 处理last_plug
{
uint8_t* plug = tree;
BOOL has_post_plug_info_p = FALSE;
BOOL has_pre_plug_info_p = FALSE;
// 如果这个plug是pinned plug
// 获取是否有has_pre_plug_info_p (是否覆盖了last_plug的尾部)
// 获取是否有has_post_plug_info_p (是否被下一个plug覆盖了尾部)
if (tree == oldest_pinned_plug)
{
args->pinned_plug_entry = get_oldest_pinned_entry (&has_pre_plug_info_p,
&has_post_plug_info_p);
assert (tree == pinned_plug (args->pinned_plug_entry));
dprintf (3, ("tree is the oldest pin: %Ix", tree));
}
// 处理last_plug
if (args->last_plug)
{
size_t gap_size = node_gap_size (tree);
// last_plug的结尾 = 当前plug的开始地址 - gap
uint8_t* gap = (plug - gap_size);
dprintf (3, ("tree: %Ix, gap: %Ix (%Ix)", tree, gap, gap_size));
assert (gap_size >= Align (min_obj_size));
uint8_t* last_plug_end = gap;
// last_plug的尾部是否被覆盖了
// args->is_shortened代表last_plug是pinned_plug,被下一个unpinned plug覆盖了尾部
// has_pre_plug_info_p代表last_plug是unpinned plug,被下一个pinned plug覆盖了尾部
BOOL check_last_object_p = (args->is_shortened || has_pre_plug_info_p);
// 处理last_plug,结尾地址是当前plug的开始地址 - gap
{
relocate_survivors_in_plug (args->last_plug, last_plug_end, check_last_object_p, args->pinned_plug_entry);
}
}
else
{
assert (!has_pre_plug_info_p);
}
// 设置last_plug
args->last_plug = plug;
// 设置是否被覆盖了尾部
args->is_shortened = has_post_plug_info_p;
if (has_post_plug_info_p)
{
dprintf (3, ("setting %Ix as shortened", plug));
}
dprintf (3, ("last_plug: %Ix(shortened: %d)", plug, (args->is_shortened ? 1 : 0)));
}
// 处理右节点
if (node_right_child (tree))
{
relocate_survivors_in_brick (tree + node_right_child (tree), args);
}
}gc_heap::relocate_survivors_in_plug函数的代码如下:
void gc_heap::relocate_survivors_in_plug (uint8_t* plug, uint8_t* plug_end,
BOOL check_last_object_p,
mark* pinned_plug_entry)
{
//dprintf(3,("Relocating pointers in Plug [%Ix,%Ix[", (size_t)plug, (size_t)plug_end));
dprintf (3,("RP: [%Ix,%Ix[", (size_t)plug, (size_t)plug_end));
// plug的结尾被覆盖过,需要特殊的处理
if (check_last_object_p)
{
relocate_shortened_survivor_helper (plug, plug_end, pinned_plug_entry);
}
// 一般的处理
else
{
relocate_survivor_helper (plug, plug_end);
}
}gc_heap::relocate_survivor_helper函数的代码如下:
void gc_heap::relocate_survivor_helper (uint8_t* plug, uint8_t* plug_end)
{
// 枚举plug中的对象,分别调用relocate_obj_helper函数
uint8_t* x = plug;
while (x < plug_end)
{
size_t s = size (x);
uint8_t* next_obj = x + Align (s);
Prefetch (next_obj);
relocate_obj_helper (x, s);
assert (s > 0);
x = next_obj;
}
}gc_heap::relocate_obj_helper函数的代码如下:
inline void
gc_heap::relocate_obj_helper (uint8_t* x, size_t s)
{
THREAD_FROM_HEAP;
// 判断对象中是否包含了引用
if (contain_pointers (x))
{
dprintf (3, ("$%Ix$", (size_t)x));
// 重定位这个对象的所有成员
// 注意这里不会包含对象自身(nostart)
go_through_object_nostart (method_table(x), x, s, pval,
{
uint8_t* child = *pval;
reloc_survivor_helper (pval);
if (child)
{
dprintf (3, ("%Ix->%Ix->%Ix", (uint8_t*)pval, child, *pval));
}
});
}
check_class_object_demotion (x);
}gc_heap::reloc_survivor_helper函数的代码如下:
inline void
gc_heap::reloc_survivor_helper (uint8_t** pval)
{
// 执行重定位,relocate_address函数上面有解释
THREAD_FROM_HEAP;
relocate_address (pval THREAD_NUMBER_ARG);
// 如果对象在降代范围中,需要设置来源位置在Card Table中的标记
check_demotion_helper (pval, (uint8_t*)pval);
}gc_heap::relocate_shortened_survivor_helper函数的代码如下:
void gc_heap::relocate_shortened_survivor_helper (uint8_t* plug, uint8_t* plug_end, mark* pinned_plug_entry)
{
uint8_t* x = plug;
// 如果p_plug == plug表示当前plug是pinned plug,结尾被下一个plug覆盖
// 如果p_plug != plug表示当前plug是unpinned plug,结尾被p_plug覆盖
uint8_t* p_plug = pinned_plug (pinned_plug_entry);
BOOL is_pinned = (plug == p_plug);
BOOL check_short_obj_p = (is_pinned ? pinned_plug_entry->post_short_p() : pinned_plug_entry->pre_short_p());
// 因为这个plug的结尾被覆盖了,下一个plug的gap是特殊gap,这里要加回去大小
plug_end += sizeof (gap_reloc_pair);
//dprintf (3, ("%s %Ix is shortened, and last object %s overwritten", (is_pinned ? "PP" : "NP"), plug, (check_short_obj_p ? "is" : "is not")));
dprintf (3, ("%s %Ix-%Ix short, LO: %s OW", (is_pinned ? "PP" : "NP"), plug, plug_end, (check_short_obj_p ? "is" : "is not")));
verify_pins_with_post_plug_info("begin reloc short surv");
// 枚举plug中的对象
while (x < plug_end)
{
// plug的最后一个对象被完全覆盖了,需要做特殊处理
if (check_short_obj_p && ((plug_end - x) < min_pre_pin_obj_size))
{
dprintf (3, ("last obj %Ix is short", x));
// 当前plug是pinned plug,结尾被下一个unpinned plug覆盖了
// 根据最后一个对象的成员bitmap重定位
if (is_pinned)
{
#ifdef COLLECTIBLE_CLASS
if (pinned_plug_entry->post_short_collectible_p())
unconditional_set_card_collectible (x);
#endif //COLLECTIBLE_CLASS
// Relocate the saved references based on bits set.
// 成员应该存在的地址(被覆盖的数据中),设置Card Table会使用这个地址
uint8_t** saved_plug_info_start = (uint8_t**)(pinned_plug_entry->get_post_plug_info_start());
// 成员真实存在的地址(备份数据中)
uint8_t** saved_info_to_relocate = (uint8_t**)(pinned_plug_entry->get_post_plug_reloc_info());
// 枚举成员的bitmap
for (size_t i = 0; i < pinned_plug_entry->get_max_short_bits(); i++)
{
// 如果成员存在则重定位该成员
if (pinned_plug_entry->post_short_bit_p (i))
{
reloc_ref_in_shortened_obj ((saved_plug_info_start + i), (saved_info_to_relocate + i));
}
}
}
// 当前plug是unpinned plug,结尾被下一个pinned plug覆盖了
// 处理和上面一样
else
{
#ifdef COLLECTIBLE_CLASS
if (pinned_plug_entry->pre_short_collectible_p())
unconditional_set_card_collectible (x);
#endif //COLLECTIBLE_CLASS
relocate_pre_plug_info (pinned_plug_entry);
// Relocate the saved references based on bits set.
uint8_t** saved_plug_info_start = (uint8_t**)(p_plug - sizeof (plug_and_gap));
uint8_t** saved_info_to_relocate = (uint8_t**)(pinned_plug_entry->get_pre_plug_reloc_info());
for (size_t i = 0; i < pinned_plug_entry->get_max_short_bits(); i++)
{
if (pinned_plug_entry->pre_short_bit_p (i))
{
reloc_ref_in_shortened_obj ((saved_plug_info_start + i), (saved_info_to_relocate + i));
}
}
}
// 处理完最后一个对象,可以跳出了
break;
}
size_t s = size (x);
uint8_t* next_obj = x + Align (s);
Prefetch (next_obj);
// 最后一个对象被覆盖了,但是只是覆盖了后半部分,不是全部被覆盖
if (next_obj >= plug_end)
{
dprintf (3, ("object %Ix is at the end of the plug %Ix->%Ix",
next_obj, plug, plug_end));
verify_pins_with_post_plug_info("before reloc short obj");
relocate_shortened_obj_helper (x, s, (x + Align (s) - sizeof (plug_and_gap)), pinned_plug_entry, is_pinned);
}
// 对象未被覆盖,调用一般的处理
else
{
relocate_obj_helper (x, s);
}
assert (s > 0);
x = next_obj;
}
verify_pins_with_post_plug_info("end reloc short surv");
}gc_heap::reloc_ref_in_shortened_obj函数的代码如下:
inline
void gc_heap::reloc_ref_in_shortened_obj (uint8_t** address_to_set_card, uint8_t** address_to_reloc)
{
THREAD_FROM_HEAP;
// 重定位对象
// 这里的address_to_reloc会在备份数据中
uint8_t* old_val = (address_to_reloc ? *address_to_reloc : 0);
relocate_address (address_to_reloc THREAD_NUMBER_ARG);
if (address_to_reloc)
{
dprintf (3, ("SR %Ix: %Ix->%Ix", (uint8_t*)address_to_reloc, old_val, *address_to_reloc));
}
// 如果对象在降代范围中,设置Card Table
// 这里的address_to_set_card会在被覆盖的数据中
//check_demotion_helper (current_saved_info_to_relocate, (uint8_t*)pval);
uint8_t* relocated_addr = *address_to_reloc;
if ((relocated_addr < demotion_high) &&
(relocated_addr >= demotion_low))
{
dprintf (3, ("set card for location %Ix(%Ix)",
(size_t)address_to_set_card, card_of((uint8_t*)address_to_set_card)));
set_card (card_of ((uint8_t*)address_to_set_card));
}
#ifdef MULTIPLE_HEAPS
// 不在当前heap时试着找到对象所在的heap并且用该heap处理
else if (settings.demotion)
{
gc_heap* hp = heap_of (relocated_addr);
if ((relocated_addr < hp->demotion_high) &&
(relocated_addr >= hp->demotion_low))
{
dprintf (3, ("%Ix on h%d, set card for location %Ix(%Ix)",
relocated_addr, hp->heap_number, (size_t)address_to_set_card, card_of((uint8_t*)address_to_set_card)));
set_card (card_of ((uint8_t*)address_to_set_card));
}
}
#endif //MULTIPLE_HEAPS
}gc_heap::relocate_shortened_obj_helper函数的代码如下:
inline
void gc_heap::relocate_shortened_obj_helper (uint8_t* x, size_t s, uint8_t* end, mark* pinned_plug_entry, BOOL is_pinned)
{
THREAD_FROM_HEAP;
uint8_t* plug = pinned_plug (pinned_plug_entry);
// 如果当前plug是unpinned plug, 代表邻接的pinned plug中保存的pre_plug_info_reloc_start可能已经被移动了
// 这里需要重定位pinned plug中保存的pre_plug_info_reloc_start (unpinned plug被覆盖的内容的开始地址)
if (!is_pinned)
{
//// Temporary - we just wanna make sure we are doing things right when padding is needed.
//if ((x + s) < plug)
//{
// dprintf (3, ("obj %Ix needed padding: end %Ix is %d bytes from pinned obj %Ix",
// x, (x + s), (plug- (x + s)), plug));
// GCToOSInterface::DebugBreak();
//}
relocate_pre_plug_info (pinned_plug_entry);
}
verify_pins_with_post_plug_info("after relocate_pre_plug_info");
uint8_t* saved_plug_info_start = 0;
uint8_t** saved_info_to_relocate = 0;
// saved_plug_info_start等于被覆盖的地址的开始
// saved_info_to_relocate等于原始内容的开始
if (is_pinned)
{
saved_plug_info_start = (uint8_t*)(pinned_plug_entry->get_post_plug_info_start());
saved_info_to_relocate = (uint8_t**)(pinned_plug_entry->get_post_plug_reloc_info());
}
else
{
saved_plug_info_start = (plug - sizeof (plug_and_gap));
saved_info_to_relocate = (uint8_t**)(pinned_plug_entry->get_pre_plug_reloc_info());
}
uint8_t** current_saved_info_to_relocate = 0;
uint8_t* child = 0;
dprintf (3, ("x: %Ix, pp: %Ix, end: %Ix", x, plug, end));
// 判断对象中是否包含了引用
if (contain_pointers (x))
{
dprintf (3,("$%Ix$", (size_t)x));
// 重定位这个对象的所有成员
// 注意这里不会包含对象自身(nostart)
go_through_object_nostart (method_table(x), x, s, pval,
{
dprintf (3, ("obj %Ix, member: %Ix->%Ix", x, (uint8_t*)pval, *pval));
// 成员所在的部分被覆盖了,调用reloc_ref_in_shortened_obj重定位
// pval = 成员应该存在的地址(被覆盖的数据中),设置Card Table会使用这个地址
// current_saved_info_to_relocate = 成员真实存在的地址(备份数据中)
if ((uint8_t*)pval >= end)
{
current_saved_info_to_relocate = saved_info_to_relocate + ((uint8_t*)pval - saved_plug_info_start) / sizeof (uint8_t**);
child = *current_saved_info_to_relocate;
reloc_ref_in_shortened_obj (pval, current_saved_info_to_relocate);
dprintf (3, ("last part: R-%Ix(saved: %Ix)->%Ix ->%Ix",
(uint8_t*)pval, current_saved_info_to_relocate, child, *current_saved_info_to_relocate));
}
// 成员所在的部分未被覆盖,调用一般的处理
else
{
reloc_survivor_helper (pval);
}
});
}
check_class_object_demotion (x);
}重定位阶段(relocate_phase)只是修改了引用对象的地址,对象还在原来的位置,接下来进入压缩阶段(compact_phase):
压缩阶段(compact_phase)
压缩阶段负责把对象复制到之前模拟压缩到的地址上,简单点来讲就是用memcpy复制这些对象到新的地址。
压缩阶段会使用之前构建的brick table和plug树快速的枚举对象。
gc_heap::compact_phase函数的代码如下:
这个函数的代码是不是有点眼熟?它的流程和上面的relocate_survivors很像,都是枚举brick table然后中序枚举plug树
void gc_heap::compact_phase (int condemned_gen_number,
uint8_t* first_condemned_address,
BOOL clear_cards)
{
// %type% category = quote (compact);
// 统计压缩阶段的开始时间
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
generation* condemned_gen = generation_of (condemned_gen_number);
uint8_t* start_address = first_condemned_address;
size_t current_brick = brick_of (start_address);
heap_segment* current_heap_segment = heap_segment_rw (generation_start_segment (condemned_gen));
PREFIX_ASSUME(current_heap_segment != NULL);
// 重设mark_stack_array队列
reset_pinned_queue_bos();
// 更新gc_heap中的oldest_pinned_plug对象
update_oldest_pinned_plug();
// 如果should_expand的时候重用了以前的segment作为ephemeral heap segment,则需要重新计算generation_allocation_size
// reused_seg会影响压缩参数中的check_gennum_p
BOOL reused_seg = expand_reused_seg_p();
if (reused_seg)
{
for (int i = 1; i <= max_generation; i++)
{
generation_allocation_size (generation_of (i)) = 0;
}
}
uint8_t* end_address = heap_segment_allocated (current_heap_segment);
size_t end_brick = brick_of (end_address-1);
// 初始化压缩参数
compact_args args;
// 上一个plug,用于遍历树时可以从小地址到大地址遍历(中序遍历)
args.last_plug = 0;
// 当前brick的最后一个plug,更新brick table时使用
args.before_last_plug = 0;
// 最后设置的brick,用于复制plug后更新brick table
args.current_compacted_brick = ~((size_t)1);
// 当前的plug结尾是否被下一个plug覆盖了
args.is_shortened = FALSE;
// last_plug或者last_plug后面的pinned plug
// 处理plug尾部数据覆盖时需要用到它
args.pinned_plug_entry = 0;
// 是否需要在复制对象时复制相应的Card Table范围
args.copy_cards_p = (condemned_gen_number >= 1) || !clear_cards;
// 重新计算generation_allocation_size时使用的参数
args.check_gennum_p = reused_seg;
if (args.check_gennum_p)
{
args.src_gennum = ((current_heap_segment == ephemeral_heap_segment) ? -1 : 2);
}
dprintf (2,("---- Compact Phase: %Ix(%Ix)----",
first_condemned_address, brick_of (first_condemned_address)));
#ifdef MULTIPLE_HEAPS
//restart
if (gc_t_join.joined())
{
#endif //MULTIPLE_HEAPS
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Restarting for compaction"));
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
// 再次重设mark_stack_array队列
reset_pinned_queue_bos();
// 判断是否需要压缩大对象的堆
#ifdef FEATURE_LOH_COMPACTION
if (loh_compacted_p)
{
compact_loh();
}
#endif //FEATURE_LOH_COMPACTION
// 循环brick table
if ((start_address < end_address) ||
(condemned_gen_number == max_generation))
{
while (1)
{
// 当前segment已经处理完
if (current_brick > end_brick)
{
// 处理最后一个plug,大小是heap_segment_allocated - last_plug
if (args.last_plug != 0)
{
dprintf (3, ("compacting last plug: %Ix", args.last_plug))
compact_plug (args.last_plug,
(heap_segment_allocated (current_heap_segment) - args.last_plug),
args.is_shortened,
&args);
}
// 如果有下一个segment则处理下一个
if (heap_segment_next_rw (current_heap_segment))
{
current_heap_segment = heap_segment_next_rw (current_heap_segment);
current_brick = brick_of (heap_segment_mem (current_heap_segment));
end_brick = brick_of (heap_segment_allocated (current_heap_segment)-1);
args.last_plug = 0;
// 更新src_gennum (如果segment是ephemeral_heap_segment则需要进一步判断)
if (args.check_gennum_p)
{
args.src_gennum = ((current_heap_segment == ephemeral_heap_segment) ? -1 : 2);
}
continue;
}
// 设置最后一个brick的偏移值, 给compact_plug善后
else
{
if (args.before_last_plug !=0)
{
dprintf (3, ("Fixing last brick %Ix to point to plug %Ix",
args.current_compacted_brick, (size_t)args.before_last_plug));
assert (args.current_compacted_brick != ~1u);
set_brick (args.current_compacted_brick,
args.before_last_plug - brick_address (args.current_compacted_brick));
}
break;
}
}
{
// 如果当前brick有对应的plug树,处理当前brick
int brick_entry = brick_table [ current_brick ];
dprintf (3, ("B: %Ix(%Ix)->%Ix",
current_brick, (size_t)brick_entry, (brick_address (current_brick) + brick_entry - 1)));
if (brick_entry >= 0)
{
compact_in_brick ((brick_address (current_brick) + brick_entry -1),
&args);
}
}
current_brick++;
}
}
// 复制已完毕
// 恢复备份的数据到被覆盖的部分
recover_saved_pinned_info();
// 统计压缩阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
compact_time = finish - start;
#endif //TIME_GC
concurrent_print_time_delta ("compact end");
dprintf(2,("---- End of Compact phase ----"));
}gc_heap::compact_in_brick函数的代码如下:
这个函数和上面的relocate_survivors_in_brick函数很像
void gc_heap::compact_in_brick (uint8_t* tree, compact_args* args)
{
assert (tree != NULL);
int left_node = node_left_child (tree);
int right_node = node_right_child (tree);
// 需要移动的偏移值,前面计划阶段模拟压缩时设置的reloc
ptrdiff_t relocation = node_relocation_distance (tree);
args->print();
// 处理左节点
if (left_node)
{
dprintf (3, ("B: L: %d->%Ix", left_node, (tree + left_node)));
compact_in_brick ((tree + left_node), args);
}
uint8_t* plug = tree;
BOOL has_pre_plug_info_p = FALSE;
BOOL has_post_plug_info_p = FALSE;
// 如果这个plug是pinned plug
// 获取是否有has_pre_plug_info_p (是否覆盖了last_plug的尾部)
// 获取是否有has_post_plug_info_p (是否被下一个plug覆盖了尾部)
if (tree == oldest_pinned_plug)
{
args->pinned_plug_entry = get_oldest_pinned_entry (&has_pre_plug_info_p,
&has_post_plug_info_p);
assert (tree == pinned_plug (args->pinned_plug_entry));
}
// 处理last_plug
if (args->last_plug != 0)
{
size_t gap_size = node_gap_size (tree);
// last_plug的结尾 = 当前plug的开始地址 - gap
uint8_t* gap = (plug - gap_size);
uint8_t* last_plug_end = gap;
// last_plug的大小 = last_plug的结尾 - last_plug的开始
size_t last_plug_size = (last_plug_end - args->last_plug);
dprintf (3, ("tree: %Ix, last_plug: %Ix, gap: %Ix(%Ix), last_plug_end: %Ix, size: %Ix",
tree, args->last_plug, gap, gap_size, last_plug_end, last_plug_size));
// last_plug的尾部是否被覆盖了
// args->is_shortened代表last_plug是pinned_plug,被下一个unpinned plug覆盖了尾部
// has_pre_plug_info_p代表last_plug是unpinned plug,被下一个pinned plug覆盖了尾部
BOOL check_last_object_p = (args->is_shortened || has_pre_plug_info_p);
if (!check_last_object_p)
{
assert (last_plug_size >= Align (min_obj_size));
}
// 处理last_plug
compact_plug (args->last_plug, last_plug_size, check_last_object_p, args);
}
else
{
// 第一个plug不可能覆盖前面的plug的结尾
assert (!has_pre_plug_info_p);
}
dprintf (3, ("set args last plug to plug: %Ix, reloc: %Ix", plug, relocation));
// 设置last_plug
args->last_plug = plug;
// 设置last_plugd移动偏移值
args->last_plug_relocation = relocation;
// 设置是否被覆盖了尾部
args->is_shortened = has_post_plug_info_p;
// 处理右节点
if (right_node)
{
dprintf (3, ("B: R: %d->%Ix", right_node, (tree + right_node)));
compact_in_brick ((tree + right_node), args);
}
}gc_heap::compact_plug函数的代码如下:
void gc_heap::compact_plug (uint8_t* plug, size_t size, BOOL check_last_object_p, compact_args* args)
{
args->print();
// 复制到的地址,plug + reloc
uint8_t* reloc_plug = plug + args->last_plug_relocation;
// 如果plug的结尾被覆盖过
if (check_last_object_p)
{
// 添加特殊gap的大小
size += sizeof (gap_reloc_pair);
mark* entry = args->pinned_plug_entry;
// 在复制内存前把被覆盖的内容和原始内容交换一下
// 复制内存后需要交换回去
if (args->is_shortened)
{
// 当前plug是pinned plug,被下一个unpinned plug覆盖
assert (entry->has_post_plug_info());
entry->swap_post_plug_and_saved();
}
else
{
// 当前plug是unpinned plug,被下一个pinned plug覆盖
assert (entry->has_pre_plug_info());
entry->swap_pre_plug_and_saved();
}
}
// 复制之前的brick中的偏移值
int old_brick_entry = brick_table [brick_of (plug)];
assert (node_relocation_distance (plug) == args->last_plug_relocation);
// 处理对齐和pad
#ifdef FEATURE_STRUCTALIGN
ptrdiff_t alignpad = node_alignpad(plug);
if (alignpad)
{
make_unused_array (reloc_plug - alignpad, alignpad);
if (brick_of (reloc_plug - alignpad) != brick_of (reloc_plug))
{
// The alignment padding is straddling one or more bricks;
// it has to be the last "object" of its first brick.
fix_brick_to_highest (reloc_plug - alignpad, reloc_plug);
}
}
#else // FEATURE_STRUCTALIGN
size_t unused_arr_size = 0;
BOOL already_padded_p = FALSE;
#ifdef SHORT_PLUGS
if (is_plug_padded (plug))
{
already_padded_p = TRUE;
clear_plug_padded (plug);
unused_arr_size = Align (min_obj_size);
}
#endif //SHORT_PLUGS
if (node_realigned (plug))
{
unused_arr_size += switch_alignment_size (already_padded_p);
}
if (unused_arr_size != 0)
{
make_unused_array (reloc_plug - unused_arr_size, unused_arr_size);
if (brick_of (reloc_plug - unused_arr_size) != brick_of (reloc_plug))
{
dprintf (3, ("fix B for padding: %Id: %Ix->%Ix",
unused_arr_size, (reloc_plug - unused_arr_size), reloc_plug));
// The alignment padding is straddling one or more bricks;
// it has to be the last "object" of its first brick.
fix_brick_to_highest (reloc_plug - unused_arr_size, reloc_plug);
}
}
#endif // FEATURE_STRUCTALIGN
#ifdef SHORT_PLUGS
if (is_plug_padded (plug))
{
make_unused_array (reloc_plug - Align (min_obj_size), Align (min_obj_size));
if (brick_of (reloc_plug - Align (min_obj_size)) != brick_of (reloc_plug))
{
// The alignment padding is straddling one or more bricks;
// it has to be the last "object" of its first brick.
fix_brick_to_highest (reloc_plug - Align (min_obj_size), reloc_plug);
}
}
#endif //SHORT_PLUGS
// 复制plug中的所有内容和对应的Card Table中的范围(如果copy_cards_p成立)
gcmemcopy (reloc_plug, plug, size, args->copy_cards_p);
// 重新统计generation_allocation_size
if (args->check_gennum_p)
{
int src_gennum = args->src_gennum;
if (src_gennum == -1)
{
src_gennum = object_gennum (plug);
}
int dest_gennum = object_gennum_plan (reloc_plug);
if (src_gennum < dest_gennum)
{
generation_allocation_size (generation_of (dest_gennum)) += size;
}
}
// 更新brick table
// brick table中会保存brick的最后一个plug的偏移值,跨越多个brick的时候后面的brick会是-1
size_t current_reloc_brick = args->current_compacted_brick;
// 如果已经到了下一个brick
// 设置上一个brick的值 = 上一个brick中最后的plug的偏移值, 或者-1
if (brick_of (reloc_plug) != current_reloc_brick)
{
dprintf (3, ("last reloc B: %Ix, current reloc B: %Ix",
current_reloc_brick, brick_of (reloc_plug)));
if (args->before_last_plug)
{
dprintf (3,(" fixing last brick %Ix to point to last plug %Ix(%Ix)",
current_reloc_brick,
args->before_last_plug,
(args->before_last_plug - brick_address (current_reloc_brick))));
{
set_brick (current_reloc_brick,
args->before_last_plug - brick_address (current_reloc_brick));
}
}
current_reloc_brick = brick_of (reloc_plug);
}
// 如果跨越了多个brick
size_t end_brick = brick_of (reloc_plug + size-1);
if (end_brick != current_reloc_brick)
{
// The plug is straddling one or more bricks
// It has to be the last plug of its first brick
dprintf (3,("plug spanning multiple bricks, fixing first brick %Ix to %Ix(%Ix)",
current_reloc_brick, (size_t)reloc_plug,
(reloc_plug - brick_address (current_reloc_brick))));
// 设置第一个brick中的偏移值
{
set_brick (current_reloc_brick,
reloc_plug - brick_address (current_reloc_brick));
}
// 把后面的brick设为-1,除了end_brick
// update all intervening brick
size_t brick = current_reloc_brick + 1;
dprintf (3,("setting intervening bricks %Ix->%Ix to -1",
brick, (end_brick - 1)));
while (brick < end_brick)
{
set_brick (brick, -1);
brick++;
}
// 如果end_brick中无其他plug,end_brick也会被设为-1
// brick_address (end_brick) - 1 - brick_address (end_brick) = -1
// code last brick offset as a plug address
args->before_last_plug = brick_address (end_brick) -1;
current_reloc_brick = end_brick;
dprintf (3, ("setting before last to %Ix, last brick to %Ix",
args->before_last_plug, current_reloc_brick));
}
// 如果只在一个brick中
else
{
// 记录当前brick中的最后一个plug
dprintf (3, ("still in the same brick: %Ix", end_brick));
args->before_last_plug = reloc_plug;
}
// 更新最后设置的brick
args->current_compacted_brick = current_reloc_brick;
// 复制完毕以后把被覆盖的内容和原始内容交换回去
// 注意如果plug移动的距离比覆盖的大小要少,这里会把复制后的内容给破坏掉
// 后面还需要使用recover_saved_pinned_info还原
if (check_last_object_p)
{
mark* entry = args->pinned_plug_entry;
if (args->is_shortened)
{
entry->swap_post_plug_and_saved();
}
else
{
entry->swap_pre_plug_and_saved();
}
}
}gc_heap::gcmemcopy函数的代码如下:
// POPO TODO: We should actually just recover the artifically made gaps here..because when we copy
// we always copy the earlier plugs first which means we won't need the gap sizes anymore. This way
// we won't need to individually recover each overwritten part of plugs.
inline
void gc_heap::gcmemcopy (uint8_t* dest, uint8_t* src, size_t len, BOOL copy_cards_p)
{
// 如果地址一样可以跳过
if (dest != src)
{
#ifdef BACKGROUND_GC
if (current_c_gc_state == c_gc_state_marking)
{
//TODO: should look to see whether we should consider changing this
// to copy a consecutive region of the mark array instead.
copy_mark_bits_for_addresses (dest, src, len);
}
#endif //BACKGROUND_GC
// 复制plug中的所有对象到新的地址上
// memcopy做的东西和memcpy一样,微软自己写的一个函数而已
//dprintf(3,(" Memcopy [%Ix->%Ix, %Ix->%Ix[", (size_t)src, (size_t)dest, (size_t)src+len, (size_t)dest+len));
dprintf(3,(" mc: [%Ix->%Ix, %Ix->%Ix[", (size_t)src, (size_t)dest, (size_t)src+len, (size_t)dest+len));
memcopy (dest - plug_skew, src - plug_skew, (int)len);
#ifdef FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
if (SoftwareWriteWatch::IsEnabledForGCHeap())
{
// The ranges [src - plug_kew .. src[ and [src + len - plug_skew .. src + len[ are ObjHeaders, which don't have GC
// references, and are not relevant for write watch. The latter range actually corresponds to the ObjHeader for the
// object at (src + len), so it can be ignored anyway.
SoftwareWriteWatch::SetDirtyRegion(dest, len - plug_skew);
}
#endif // FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
// 复制对应的Card Table范围
// copy_cards_p成立的时候复制src ~ src+len到dest
// copy_cards_p不成立的时候清除dest ~ dest+len
copy_cards_range (dest, src, len, copy_cards_p);
}
}gc_heap::compact_loh函数的代码如下:
void gc_heap::compact_loh()
{
assert (should_compact_loh());
generation* gen = large_object_generation;
heap_segment* start_seg = heap_segment_rw (generation_start_segment (gen));
PREFIX_ASSUME(start_seg != NULL);
heap_segment* seg = start_seg;
heap_segment* prev_seg = 0;
uint8_t* o = generation_allocation_start (gen);
//Skip the generation gap object
o = o + AlignQword (size (o));
// We don't need to ever realloc gen3 start so don't touch it.
uint8_t* free_space_start = o;
uint8_t* free_space_end = o;
generation_allocator (gen)->clear();
generation_free_list_space (gen) = 0;
generation_free_obj_space (gen) = 0;
loh_pinned_queue_bos = 0;
// 枚举大对象的堆
while (1)
{
// 当前segment处理完毕,处理下一个
if (o >= heap_segment_allocated (seg))
{
heap_segment* next_seg = heap_segment_next (seg);
// 如果当前segment为空,表示可以删掉这个segment
// 修改segment链表,把空的segment放到后面
if ((heap_segment_plan_allocated (seg) == heap_segment_mem (seg)) &&
(seg != start_seg) && !heap_segment_read_only_p (seg))
{
dprintf (3, ("Preparing empty large segment %Ix", (size_t)seg));
assert (prev_seg);
heap_segment_next (prev_seg) = next_seg;
heap_segment_next (seg) = freeable_large_heap_segment;
freeable_large_heap_segment = seg;
}
else
{
// 更新heap_segment_allocated
// 释放(decommit)未使用的内存空间
if (!heap_segment_read_only_p (seg))
{
// We grew the segment to accommondate allocations.
if (heap_segment_plan_allocated (seg) > heap_segment_allocated (seg))
{
if ((heap_segment_plan_allocated (seg) - plug_skew) > heap_segment_used (seg))
{
heap_segment_used (seg) = heap_segment_plan_allocated (seg) - plug_skew;
}
}
heap_segment_allocated (seg) = heap_segment_plan_allocated (seg);
dprintf (3, ("Trimming seg to %Ix[", heap_segment_allocated (seg)));
decommit_heap_segment_pages (seg, 0);
dprintf (1236, ("CLOH: seg: %Ix, alloc: %Ix, used: %Ix, committed: %Ix",
seg,
heap_segment_allocated (seg),
heap_segment_used (seg),
heap_segment_committed (seg)));
//heap_segment_used (seg) = heap_segment_allocated (seg) - plug_skew;
dprintf (1236, ("CLOH: used is set to %Ix", heap_segment_used (seg)));
}
prev_seg = seg;
}
// 处理下一个segment,不存在时跳出
seg = next_seg;
if (seg == 0)
break;
else
{
o = heap_segment_mem (seg);
}
}
// 如果对象已标记
if (marked (o))
{
free_space_end = o;
size_t size = AlignQword (size (o));
size_t loh_pad;
uint8_t* reloc = o;
// 清除标记
clear_marked (o);
// 如果对象是固定的
if (pinned (o))
{
// We are relying on the fact the pinned objects are always looked at in the same order
// in plan phase and in compact phase.
mark* m = loh_pinned_plug_of (loh_deque_pinned_plug());
uint8_t* plug = pinned_plug (m);
assert (plug == o);
loh_pad = pinned_len (m);
// 清除固定标记
clear_pinned (o);
}
else
{
loh_pad = AlignQword (loh_padding_obj_size);
// 复制对象内存
reloc += loh_node_relocation_distance (o);
gcmemcopy (reloc, o, size, TRUE);
}
// 添加loh_pad到free list
thread_gap ((reloc - loh_pad), loh_pad, gen);
// 处理下一个对象
o = o + size;
free_space_start = o;
if (o < heap_segment_allocated (seg))
{
assert (!marked (o));
}
}
else
{
// 跳过未标记对象
while (o < heap_segment_allocated (seg) && !marked (o))
{
o = o + AlignQword (size (o));
}
}
}
assert (loh_pinned_plug_que_empty_p());
dprintf (1235, ("after GC LOH size: %Id, free list: %Id, free obj: %Id\n\n",
generation_size (max_generation + 1),
generation_free_list_space (gen),
generation_free_obj_space (gen)));
}gc_heap::recover_saved_pinned_info函数的代码如下:
void gc_heap::recover_saved_pinned_info()
{
// 重设mark_stack_array队列
reset_pinned_queue_bos();
// 恢复各个pinned plug被覆盖或者覆盖的数据
while (!(pinned_plug_que_empty_p()))
{
mark* oldest_entry = oldest_pin();
oldest_entry->recover_plug_info();
#ifdef GC_CONFIG_DRIVEN
if (oldest_entry->has_pre_plug_info() && oldest_entry->has_post_plug_info())
record_interesting_data_point (idp_pre_and_post_pin);
else if (oldest_entry->has_pre_plug_info())
record_interesting_data_point (idp_pre_pin);
else if (oldest_entry->has_post_plug_info())
record_interesting_data_point (idp_post_pin);
#endif //GC_CONFIG_DRIVEN
deque_pinned_plug();
}
}mark::recover_plug_info函数的代码如下:
函数前面的注释讲的是之前复制plug的时候已经包含了被覆盖的内容(swap_pre_plug_and_saved),
但是如果移动的位置小于3个指针的大小(注释中的< 3应该是>= 3)则复制完以后有可能再次被swap_pre_plug_and_saved破坏掉。
// We should think about whether it's really necessary to have to copy back the pre plug
// info since it was already copied during compacting plugs. But if a plug doesn't move
// by < 3 ptr size, it means we'd have to recover pre plug info.
void recover_plug_info()
{
// 如果这个pinned plug覆盖了前一个unpinned plug的结尾,把备份的数据恢复回去
if (saved_pre_p)
{
// 如果已经压缩过,需要复制到重定位后的saved_pre_plug_info_reloc_start
// 并且使用saved_pre_plug_reloc备份(这个备份里面的成员也经过了重定位)
if (gc_heap::settings.compaction)
{
dprintf (3, ("%Ix: REC Pre: %Ix-%Ix",
first,
&saved_pre_plug_reloc,
saved_pre_plug_info_reloc_start));
memcpy (saved_pre_plug_info_reloc_start, &saved_pre_plug_reloc, sizeof (saved_pre_plug_reloc));
}
// 如果未压缩过,可以复制到这个pinned plug的前面
// 并且使用saved_pre_plug备份
else
{
dprintf (3, ("%Ix: REC Pre: %Ix-%Ix",
first,
&saved_pre_plug,
(first - sizeof (plug_and_gap))));
memcpy ((first - sizeof (plug_and_gap)), &saved_pre_plug, sizeof (saved_pre_plug));
}
}
// 如果这个pinned plug被下一个unpinned plug覆盖了结尾,把备份的数据恢复回去
if (saved_post_p)
{
// 因为pinned plug不会移动
// 这里的saved_post_plug_info_start不会改变
// 使用saved_post_plug_reloc备份(这个备份里面的成员也经过了重定位)
if (gc_heap::settings.compaction)
{
dprintf (3, ("%Ix: REC Post: %Ix-%Ix",
first,
&saved_post_plug_reloc,
saved_post_plug_info_start));
memcpy (saved_post_plug_info_start, &saved_post_plug_reloc, sizeof (saved_post_plug_reloc));
}
// 使用saved_pre_plug备份
else
{
dprintf (3, ("%Ix: REC Post: %Ix-%Ix",
first,
&saved_post_plug,
saved_post_plug_info_start));
memcpy (saved_post_plug_info_start, &saved_post_plug, sizeof (saved_post_plug));
}
}
}压缩阶段结束以后还需要做一些收尾工作,请从上面plan_phase中的fix_generation_bounds (condemned_gen_number, consing_gen);继续看。
如果计划阶段不选择压缩,就会进入清扫阶段:
清扫阶段(sweep_phase)
清扫阶段负责把plug与plug之间的空间变为free object然后加到对应代的free list中,并且负责修改代边界。
加到free list中的区域会在后面供分配新的上下文使用。
清扫阶段的主要工作在函数make_free_lists中完成,名称叫sweep_phase的函数目前不存在。
扫描plug时会使用计划阶段构建好的plug信息和brick table,但模拟压缩的偏移值reloc和计划代边界plan_allocation_start不会被使用。
清扫阶段的代码
gc_heap::make_free_lists函数的代码如下:
void gc_heap::make_free_lists (int condemned_gen_number)
{
// 统计清扫阶段的开始时间
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
//Promotion has to happen in sweep case.
assert (settings.promotion);
// 从收集代的第一个segment开始处理
generation* condemned_gen = generation_of (condemned_gen_number);
uint8_t* start_address = generation_allocation_start (condemned_gen);
size_t current_brick = brick_of (start_address);
heap_segment* current_heap_segment = heap_segment_rw (generation_start_segment (condemned_gen));
PREFIX_ASSUME(current_heap_segment != NULL);
uint8_t* end_address = heap_segment_allocated (current_heap_segment);
size_t end_brick = brick_of (end_address-1);
// 清扫阶段使用的参数
make_free_args args;
// 当前生成的free object应该归到的代序号
// 更新代边界的时候也会使用
args.free_list_gen_number = min (max_generation, 1 + condemned_gen_number);
// 超过这个值就需要更新free_list_gen_number和free_list_gen
// 在清扫阶段settings.promotion == true时
// generation_limit遇到gen 0或者gen 1的时候返回heap_segment_reserved (ephemeral_heap_segment),则原代0的对象归到代1
// generation_limit遇到gen 2的时候返回generation_allocation_start (generation_of ((gen_number - 2))),则原代1的对象归到代2
// MAX_PTR只是用来检测第一次使用的,后面会更新
args.current_gen_limit = (((condemned_gen_number == max_generation)) ?
MAX_PTR :
(generation_limit (args.free_list_gen_number)));
// 当前生成的free object应该归到的代
args.free_list_gen = generation_of (args.free_list_gen_number);
// 当前brick中地址最大的plug,用于更新brick表
args.highest_plug = 0;
// 开始遍历brick
if ((start_address < end_address) ||
(condemned_gen_number == max_generation))
{
while (1)
{
// 当前segment处理完毕
if ((current_brick > end_brick))
{
// 如果第一个segment无存活的对象,则重设它的heap_segment_allocated
// 并且设置generation_allocation_start (gen)等于这个空segment的开始地址
if (args.current_gen_limit == MAX_PTR)
{
//We had an empty segment
//need to allocate the generation start
generation* gen = generation_of (max_generation);
heap_segment* start_seg = heap_segment_rw (generation_start_segment (gen));
PREFIX_ASSUME(start_seg != NULL);
uint8_t* gap = heap_segment_mem (start_seg);
generation_allocation_start (gen) = gap;
heap_segment_allocated (start_seg) = gap + Align (min_obj_size);
// 确保代最少有一个对象
make_unused_array (gap, Align (min_obj_size));
// 更新代边界
reset_allocation_pointers (gen, gap);
dprintf (3, ("Start segment empty, fixing generation start of %d to: %Ix",
max_generation, (size_t)gap));
// 更新current_gen_limit
args.current_gen_limit = generation_limit (args.free_list_gen_number);
}
// 有下一个segment的时候继续处理下一个segment, 否则跳出
if (heap_segment_next_rw (current_heap_segment))
{
current_heap_segment = heap_segment_next_rw (current_heap_segment);
current_brick = brick_of (heap_segment_mem (current_heap_segment));
end_brick = brick_of (heap_segment_allocated (current_heap_segment)-1);
continue;
}
else
{
break;
}
}
{
// 如果brick中保存了对plug树的偏移值则
// 调用make_free_list_in_brick
// 设置brick到地址最大的plug
// 否则设置设为-1 (把-2, -3等等的都改为-1)
int brick_entry = brick_table [ current_brick ];
if ((brick_entry >= 0))
{
make_free_list_in_brick (brick_address (current_brick) + brick_entry-1, &args);
dprintf(3,("Fixing brick entry %Ix to %Ix",
current_brick, (size_t)args.highest_plug));
set_brick (current_brick,
(args.highest_plug - brick_address (current_brick)));
}
else
{
if ((brick_entry > -32768))
{
#ifdef _DEBUG
ptrdiff_t offset = brick_of (args.highest_plug) - current_brick;
if ((brick_entry != -32767) && (! ((offset == brick_entry))))
{
assert ((brick_entry == -1));
}
#endif //_DEBUG
//init to -1 for faster find_first_object
set_brick (current_brick, -1);
}
}
}
current_brick++;
}
}
{
// 设置剩余的代边界
int bottom_gen = 0;
args.free_list_gen_number--;
while (args.free_list_gen_number >= bottom_gen)
{
uint8_t* gap = 0;
generation* gen2 = generation_of (args.free_list_gen_number);
// 保证代中最少有一个对象
gap = allocate_at_end (Align(min_obj_size));
generation_allocation_start (gen2) = gap;
// 设置代边界
reset_allocation_pointers (gen2, gap);
dprintf(3,("Fixing generation start of %d to: %Ix",
args.free_list_gen_number, (size_t)gap));
PREFIX_ASSUME(gap != NULL);
// 代中第一个对象应该是free object
make_unused_array (gap, Align (min_obj_size));
args.free_list_gen_number--;
}
// 更新alloc_allocated成员到gen 0的开始边界
//reset the allocated size
uint8_t* start2 = generation_allocation_start (youngest_generation);
alloc_allocated = start2 + Align (size (start2));
}
// 统计清扫阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
sweep_time = finish - start;
#endif //TIME_GC
}gc_heap::make_free_list_in_brick函数的代码如下:
void gc_heap::make_free_list_in_brick (uint8_t* tree, make_free_args* args)
{
assert ((tree != NULL));
{
int right_node = node_right_child (tree);
int left_node = node_left_child (tree);
args->highest_plug = 0;
if (! (0 == tree))
{
// 处理左边的节点
if (! (0 == left_node))
{
make_free_list_in_brick (tree + left_node, args);
}
// 处理当前节点
{
uint8_t* plug = tree;
// 当前plug前面的空余空间
size_t gap_size = node_gap_size (tree);
// 空余空间的开始
uint8_t* gap = (plug - gap_size);
dprintf (3,("Making free list %Ix len %d in %d",
//dprintf (3,("F: %Ix len %Ix in %d",
(size_t)gap, gap_size, args->free_list_gen_number));
// 记录当前brick中地址最大的plug
args->highest_plug = tree;
#ifdef SHORT_PLUGS
if (is_plug_padded (plug))
{
dprintf (3, ("%Ix padded", plug));
clear_plug_padded (plug);
}
#endif //SHORT_PLUGS
gen_crossing:
{
// 如果current_gen_limit等于MAX_PTR,表示我们需要先决定gen 2的边界
// 如果plug >= args->current_gen_limit并且plug在ephemeral heap segment,表示我们需要决定gen 1或gen 0的边界
// 决定的流程如下
// - 第一次current_gen_limit == MAX_PTR,在处理所有对象之前决定gen 2的边界
// - 第二次plug超过了generation_allocation_start (generation_of ((gen_number - 2)))并且在ephemeral heap segment中,决定gen 1的边界
// - 因为plug不会超过heap_segment_reserved (ephemeral_heap_segment),第三次会在上面的"设置剩余的代边界"中决定gen 0的边界
if ((args->current_gen_limit == MAX_PTR) ||
((plug >= args->current_gen_limit) &&
ephemeral_pointer_p (plug)))
{
dprintf(3,(" Crossing Generation boundary at %Ix",
(size_t)args->current_gen_limit));
// 在处理所有对象之前决定gen 2的边界时,不需要减1
if (!(args->current_gen_limit == MAX_PTR))
{
args->free_list_gen_number--;
args->free_list_gen = generation_of (args->free_list_gen_number);
}
dprintf(3,( " Fixing generation start of %d to: %Ix",
args->free_list_gen_number, (size_t)gap));
// 决定代边界
reset_allocation_pointers (args->free_list_gen, gap);
// 更新current_gen_limit用于决定下一个代的边界
args->current_gen_limit = generation_limit (args->free_list_gen_number);
// 保证代中最少有一个对象
// 如果这个gap比较大(大于最小对象大小 * 2),剩余的空间还可以在下面放到free list中
if ((gap_size >= (2*Align (min_obj_size))))
{
dprintf(3,(" Splitting the gap in two %Id left",
gap_size));
make_unused_array (gap, Align(min_obj_size));
gap_size = (gap_size - Align(min_obj_size));
gap = (gap + Align(min_obj_size));
}
else
{
make_unused_array (gap, gap_size);
gap_size = 0;
}
goto gen_crossing;
}
}
// 加到free list中
thread_gap (gap, gap_size, args->free_list_gen);
add_gen_free (args->free_list_gen->gen_num, gap_size);
}
// 处理右边的节点
if (! (0 == right_node))
{
make_free_list_in_brick (tree + right_node, args);
}
}
}
}压缩阶段结束以后还需要做一些收尾工作,请从上面plan_phase中的recover_saved_pinned_info();继续看。
参考链接
https://github.com/dotnet/coreclr/blob/master/Documentation/botr/garbage-collection.md
https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcimpl.h
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcpriv.h
https://github.com/dotnet/coreclr/issues/8959
https://github.com/dotnet/coreclr/issues/8995
https://github.com/dotnet/coreclr/issues/9053
https://github.com/dotnet/coreclr/issues/10137
https://github.com/dotnet/coreclr/issues/10305
https://github.com/dotnet/coreclr/issues/10141
写在最后
GC的实际处理远远比文档和书中写的要复杂,希望这一篇文章可以让你更加深入的理解CoreCLR,如果你发现了错误或者有疑问的地方请指出来,
另外这篇文章有一些部分尚未涵盖到,例如SuspendEE的原理,后台GC的处理和stackwalking等,希望以后可以再花时间去研究它们。
下一篇我将会实际使用LLDB跟踪GC收集垃圾的处理,再下一篇会写JIT相关的内容,敬请期待。