前面的文章中我们讲道,像趣头条类的APP对于收徒和阅读行为给予用户现金奖励的方式势必会受到大量羊毛党黑产的注意,其实单个用户能薅到的钱是没有多少的,为了达到利益最大化,黑产肯定会利用各种手段构建大量账号来薅APP运营企业的羊毛,因为收徒的奖励远高于阅读,所以赚取收徒奖励就成了最严重的薅羊毛手段。前文提到为了更好的识别出这些异常用户,我们利用用户的师徒关系构建连通图,把同一个连通图上的用户视为一个社群,利用Spark Grahpx实现了一个简单高效的社群发现功能。具体内容可以查看上一篇文章《基于Spark Grahpx+Neo4j 实现用户社群发现》,但生成社群不是目的,我们的目标是能够对社群用户进行分析,根据规则和算法的方法找出社群内的异常用户及异常社群,从而达到风控的目的。
规则的方法主要是,我们在设备,IP,用户基础信息,用户行为信息等维度组合构建用户的风控画像,然后开发规则引擎,制定阈值,过滤出超过阈值的异常用户。但只通过规则的方法往往是不够的,大量的用户单从个体上看看不出多少异常,但如果上升一个层次,从社群的整体角度去分析,就会发现用户的很多相似之处。
就像我们之前文章说的坏人往往是扎堆的,物以类聚,人以群分,而且黑产想达到一定规模,肯定会借助作弊设备,脚本,机器等手段,机器的行为一般都有一些相似性,我们就可以利用这些相似性对用户进行聚类分析,所以除了规则的方法外,我们还可以用机器学习的方法将具有相似行为的用户进行聚类,然后求出类簇的TOP N相似特征,查看是否可疑,比如设备是否相似,行为是否相似,基本信息,账号等是否相似,通过机器学习的方法,我们能找出很多规则没法判定的异常用户。
聚类就是把相似的用户聚在一起,一般的方法就是计算两个用户特征向量的相似度,这就遇到了第一个问题,对于大量用户来说,两两用户计算相似度计算量是非常可怕的,比如50万用户两两计算相似度,总共要计算50w * 50w =2500亿次,这计算量就太大了,如果用户量再大点根本无法计算。对于这种情况,人们一般会利用局部敏感哈希等优化算法将数据进行降维,然后通过哈希把相似的用户尽可能的放到同一个桶里,最后再对同一个桶里的数据进行两两计算,这样计算量就小很多了。
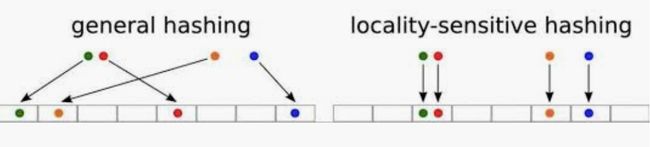
下图是局部敏感哈希算法的一个示意图,普通的哈希算法是尽量将数据打散到不同的桶里,达到减少碰撞的目的,但局部敏感哈希旨在将相似的用户放到相同的桶里。Spark的Mllib库里也提供了LSH局部敏感哈希算法的实现,有兴趣的朋友可以自行查看。
不过我们在用Spark LSH跑数据的过程中,遇到了每次都是最后几个task特别缓慢的情况,可能跟数据倾斜或CPU计算能力不足有关,多次调试都没有太好的效果,又限于资源有限,只能另想别的方法,忽然想到我们之前已经按师徒关系生成的社群,本身就是一种把相似用户放到同一个桶里的操作,而且我们根据师徒关系构建连通图得到的社群应该是已经很好的把有可能是一个团伙的人聚到了一起,这样的话,只需对每个社群进行相似度计算就可以了。
计算相似度的方法有多种,像欧氏距离,汉明距离,余弦相似度,Jaccard 系数等都是常用的度量方法,但鉴于我们提取的用户特征既有数值型,又有字符型,而且用户特征维度一样,我们想通过定义用户有多少个共同特征就判为相似的逻辑,所以我们选择了一个比较简单的f,即对比两用户特征数组相同特征数,满足阈值即为相似。

不同社群用户数
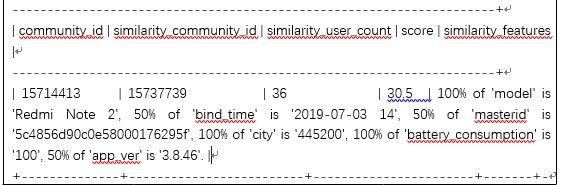
上图是我们根据师徒关系生成的不同社群及社群人数,下图为我们基于这些社群,分别计算出的社群内相似用户及用户的相似特征。

从上图可以看出这些相似用户,有些社群全部是同一个手机型号,并且开机时间相同,手机一直处于充电状态,师徒高度集中等等,这些都是比较可疑的用户,需要风控人员重点分析。
至此,我们通过社群相似度计算实现了一个简单的风控聚类模型,基于这个模型找出了一些相似用户,而且我们可以增加更多的用户特征,调节模型阈值来达到更好的风控效果。后面我们还计划给每个特征定义权重,这样就可以对社群进行打分,进而可以更直观的判断社群的优劣与否。
定义特征权重如下

打分规则
目前相似社群风控分数打分规则为:
- 特征占比大于等于50%的特征为该相似社群的相似特征;
- 相似社群风控分数 = 相似特征占比乘以特征权重的累加和
- 如果存在权重大于等于10的相似特征,相似社群风控分数要再加上用户数mod 100,即每100用户加1分
比如下面为相似社群的用户数和相似特征占比
778 //相似社群用户数
97% of 'app_ver' is '3.9.1', //权重为2
72% of 'masterid' is '599aa668c0d9db00014239e7', //权重为5
53% of 'battery_consumption' is '100' //权重为10
//计算相似社群风控分数如下
Score = 0.972 + 0.725 + 0.5310 + (778 mod 100) 1 = 17.84
查询结果表如下