情景描述
我的毕设其中一个模块需要实现多线程爬虫,爬虫模块中的url容器打算使用mysql的一张表(表名叫
url_catcher)来实现,里面涉及到url防重,子线程监控,url提取,路径计算方案等不是重点,不细讲。重点来了,在这个并发环境下,最关键的一步自然就是多线程对同一条url的抢锁的实现,先说明我的原先的思路:通过对
url_catcher中的一行status字段状态位进行CAS操作实现抢锁,贴代码:
- Mybatis映射文件
update url_catcher set status= #{newStatus},err_msg=#{errMsg} where id = #{id} and status= #{oldStatus}
- Dao只是个接口:
public interface UrlCatcherDao {
UrlCatcher getTop1(@Param("status") Integer status);
int setStatus(@Param("id") Integer id,
@Param("oldStatus") Integer oldStatus,
@Param("newStatus") Integer newStatus,
@Param("errMsg") String errMsg);
}
- url状态枚举:
public enum CatcherStatus {
NO_CATCH(0, "还没爬取"),
CATCHING(1, "正在爬取"),
CATCHED(2, "爬取过了"),
FAILED(3, "爬取失败");
private int code;
private String description;
}
- 抢锁关键Service
@Transactional(isolation = Isolation.REPEATABLE_READ)
public UrlCatcher findTopAndLock() {
UrlCatcher catcher = null;
int count = 0;
while (count <= 0) {
//(1)获取表中status为NO_CATCH的第一条记录,sql语句见上面的Mybatis映射文件
catcher = urlCatcherDao.getTop1(CatcherStatus.NO_CATCH.getCode());
System.out.println("catcher = " + catcher + ",count = " + count);
//(2)爬虫停止
if (catcher == null) {
break;//容器中没url了
}
//(3) 修改状态,确认锁定:将对应id的记录,如果状态为NO_CATCH就修改为CATCHING,否则不修改,返回值count为这条sql执行后对表中影响的行数
count = urlCatcherDao.setStatus(catcher.getId(), CatcherStatus.NO_CATCH.getCode(), CatcherStatus.CATCHING.getCode(), "");
//count小于等于0表示没抢到,接着循环抢下一个,抢到了就返回
}
logger.info("抢锁成功:catcher = {}", catcher);
return catcher;
}
- 说明:
- 第一步:获取表中status为
NO_CATCH的第一条记录,sql语句见上面的Mybatis映射文件,很好理解- 第二步:获取的第一条记录catcher为空,表示表中没有可用url,退出循环返回,这不是重点,这是爬虫停止条件
- 第三步:对第一步获取的catcher对象id进行
CAS抢锁(如果状态为NO_CATCH就修改为CATCHING,否则不修改,返回值count为这条sql执行后对表中影响的行数),这样的结果就是如果该线程抢到了,状态修改成功(即加锁),count>0退出循环返回,否则就是被其他线程抢了,count=0继续外层while循环@Transactional(isolation = Isolation.REPEATABLE_READ)设定该操作的事务隔离级别
-
这样看似没什么问题啊,运行起来却是偶尔正常,偶尔不正常。。。如下:
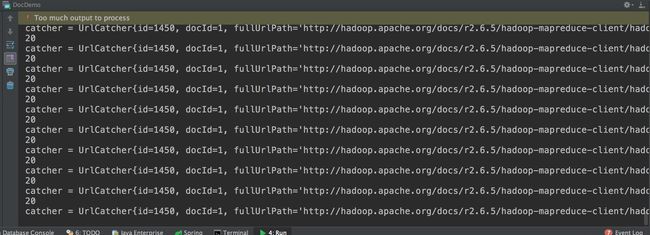 running-not-exist.png
running-not-exist.png
死循环了吧~
看见id为1450了吗?我让这个死循环接着运行着,然后控制台sql查一下这条记录的status:
select id,status from url_catcher WHERE id=1450
结果如下:
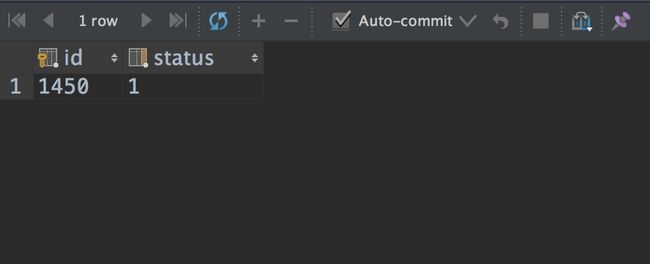
对比上面的枚举类,可以知道该url当前的状态为CATCHING,被哪个线程抢了我不管,但是已经被抢了,这样在抢锁逻辑中urlCatcherDao.getTop1(CatcherStatus.NO_CATCH.getCode());这句肯定不应该获取这条记录的,我们把死循环的程序停了,看看打的日志:
不在公司,屏幕比较小,没法完成截图,复制其中一行看看:
catcher = UrlCatcher{id=1450, docId=1, fullUrlPath='http://hadoop.apache.org/docs/r2.6.5/hadoop-mapreduce-client/hadoop-mapreduce-client-hs/images/logos/', rootUrlPath='http://hadoop.apache.org/docs/r2.6.5/hadoop-mapreduce-client/hadoop-mapreduce-client-hs', rootFilePath='/Users/coselding/test1', parentPath='/images/logos', filename='', createTime=1491723334618, status=0, errMsg='null'},count = 0
20
看重点!!!id=1450,status=0(对应枚举NO_CATCH)
这尼玛,同样在运行中,死循环中查询出的1450记录status=0,而我用控制台sql得到的status=1,心中千万只草泥马奔腾而过!!!
解决过程
- 首先想到的自然是事务隔离级别,我就在草稿纸上画两个事务线程的可能的执行轨迹,不论怎么画,都想不到有怎样的轨迹能够达到这种执行结果!!!这些不是重点,不贴图了,然后我就不想理论的了,直接把
@Transactional(isolation = Isolation.REPEATABLE_READ)换着测试,一开始还挺顺利,换成SERIALIZABLE就不死循环了,但是因为没有理论支撑,我多执行了几次,然后死循环依然出现了,看来是锁粒度变大导致了死循环发生频率降低了,但是至少说明了我对这些事务隔离级别的理解还是对的,世界观没崩塌,还好还好~ - 然后还是查资料:mysql缓存?就算是缓存也有有效时间,不可能死循环
- 先查查事务隔离级别,找思路,直到找到了这几篇博客:
- Innodb事务隔离级别
- InnoDB中事务隔离级别和锁的关系
- Innodb中的事务隔离级别和锁的关系
- 重新回顾了一下
二段锁协议,也了解了InnoDB的行级锁是基于索引的,没建立索引的字段无法触发行级锁,还有间隙锁,感觉自己了解的还是不够,之后还是得花时间好好补补 - 重点来了:InnoDB的乐观锁实现
MVCC,规则如下:
 innoDB-MVCC.png
innoDB-MVCC.png
InnoDB基于事务版本号对select实现了快照读,insert、delete、update是当前读,简单说呢,就是select在并发环境下可能读取到的就是历史纪录(和死循环的现象吻合),具体详解可以参照Innodb中的事务隔离级别和锁的关系,有了这个思路,我们来分析一下上面的死循环原因~
原因过程分析
还是id=1450作为例子,初始创建版本号createVersion为0,删除版本号deleteVersion为null
| 过程 | 事务线程1 | 事务线程2 |
|---|---|---|
| 事务开始 | createVersion=0,deleteVersion=null | createVersion=0,deleteVersion=null |
| 事务版本号 | version=1 | version=2 |
| 1 | getTop1执行:createVersion|
| |
| 2 | 获取status=0 | |
| 3 | getTop1执行:createVersion | |
| 4 | 获取status=0 | |
| 5 | setStatus执行,update规则:新纪录(status=1,createVersion=2,deleteVersion=null),原记录快照(status=0,createVersion=0,deleteVersion=2) |
|
| 6 | 抢锁成功,commit | |
| 7 | 返回,该事务线程结束 | |
| 8 | setStatus抢锁失败 | |
| 9 | 下次循环:getTop1执行:createVersion原记录快照(status=0) |
|
| 10 | setStatus抢锁失败,接着循环 | |
| 11 | 该事务线程永远无法commit,version版本号永远不变,永远查找到原记录快照,status永远为0,陷入死循环 |
- 分析:由于两个事务线程需要按照上表的顺序交错进行才能出现死循环,因此和之前的结论:死循环偶尔出现是相吻合的
- 根本原因:外层循环中多次的getTop1执行时由于在同一个事务中,
事务版本号始终不变,导致始终获取快照记录,导致死循环 - 解决方案:让getTop1和setStatus分离在不同事务中执行,即去掉
@Transactional(isolation = Isolation.REPEATABLE_READ)
最终代码
- 就去掉了个注解
public UrlCatcher findTopAndLock() {
UrlCatcher catcher = null;
int count = 0;
while (count <= 0) {
catcher = urlCatcherDao.getTop1(CatcherStatus.NO_CATCH.getCode());
System.out.println("catcher = " + catcher + ",count = " + count);
if (catcher == null) {
break;//容器中没url了
}
//抢分布式锁:开始抢锁
//修改状态,确认锁定
count = urlCatcherDao.setStatus(catcher.getId(), CatcherStatus.NO_CATCH.getCode(), CatcherStatus.CATCHING.getCode(), "");
//count小于等于0表示没抢到,接着循环抢下一个,抢到了就返回
}
logger.info("抢锁成功:catcher = {}", catcher);
return catcher;
}
- 由于我这个爬虫所处理的业务规模不会无限膨胀,再进行了优化,将抢锁操作转移到内存中执行,降低mysql压力,如下:
public class UrlCatcherServiceImpl implements UrlCatcherService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private UrlCatcherDao urlCatcherDao;
private static ConcurrentHashMap urlLockMap = new ConcurrentHashMap();
public void prepareLockMap() {
urlLockMap.clear();
}
public UrlCatcher findTopAndLock() {
UrlCatcher catcher = null;
int count = 0;
Long currentThreadId = Thread.currentThread().getId();
while (count <= 0) {
catcher = urlCatcherDao.getTop1(CatcherStatus.NO_CATCH.getCode());
logger.info("catcher = " + catcher + ",count = " + count);
if (catcher == null) {
break;//容器中没url了
}
//抢分布式锁:开始抢锁
Long beforeThreadId = urlLockMap.putIfAbsent(catcher.getId(), currentThreadId);
if (beforeThreadId == null) {
//抢到了:之前该id为key没有映射关系
//修改状态,确认锁定
count = urlCatcherDao.setStatus(catcher.getId(), CatcherStatus.NO_CATCH.getCode(), CatcherStatus.CATCHING.getCode(), "");
} else {
//没抢到:之前已经有映射关系了
count = 0;
}
//count小于等于0表示没抢到,接着循环抢下一个,抢到了就返回
}
logger.info("抢锁成功:catcher = {}", catcher);
return catcher;
}
}
- 改成这样之后,我前前后后重新执行了不下几十遍,再也没有出现死循环,算是解决了,如果后期还出现问题的话我再来更新博客哈哈哈,在此只是提供一个解决问题的思路~
总结
- 虽然最终解决方案只是去掉一个注解,但是这其中蕴含的原理却颇为深刻,专门花了时间记录一下,也让我意识到对MySQL的理解还远远不够,之后还是得重新把
《高性能MySQL》重新拿来好好啃啃。 - 之前由于接触不多,总感觉数据库InnoDB、高并发对于自己比较遥远,或者说是没有丰富的实战经验,导致对其中可能出现的问题、如何排查、如何解决问题等有种恐惧加拖延症,这次花了半天时间排查这个问题,时间上算是损失惨重,但是也让我对自己更加自信,算是第一次在我手中解决了一个高并发环境下的问题哈哈哈哈