词法分析器
词法分析器又称扫描器。词法分析是指将我们编写的文本代码流解析为一个一个的记号,分析得到的记号(Token)以供后续语法分析使用。
-
输出分析
关键字表:program begin end var while do repeat until for to if then else ; : ( ) , := + - * / > >= == < <= Token序列:(4,0)(13,0)(1,0)(26,0)(1,1)(1,2)(0,0)(2,0)(5,0) 符号表:a b c 常数表:33- 关键字表是固定的,是你设置的关键字
- Token是输出的记号
- 符号表是读取的输入中有哪些英文字母
- 常数表是读取的输入中有哪些数字
-
变量分析
-
char keywords[30][12]:所存储的所有界符,就是特殊标识符和符号 -
int aut[11][8]:有限状态机转移形成的矩阵 -
char ID[50][12]:存储字符的数组,用来避免重复记录 -
int C[20]:存储数字的数组,用来避免重复记录 -
struct token:生成的记号 -
int n,p,m,e,t:尾数值,指数值,小数位数,指数符号,类型 -
char w[50]:读入缓冲区 -
struct map:用来识别你的输入字符
-
-
方法分析
-
void act(int s):读取一个状态,选择case执行 -
find(int s,char ch):输入一个状态和一个读取的字符,返回对应有限状态自动机对应表中的值 -
int InsertConst(double num):将一个数字添加到C[]集合中,返回该值在C集合中的位置 -
int Reserve(char *str):读入一个字符判断是不是界符,如果是界符,则返回符合界符数组的下标+3,否则返回0<不知道这里的+3是不是错误,我原来以为是为了区分code=1和2的情况,后来发现添加数字的时候又不加3了> -
int InsertID(char *str):将一个字符串插入到ID[]数组中
-
-
简易分析图
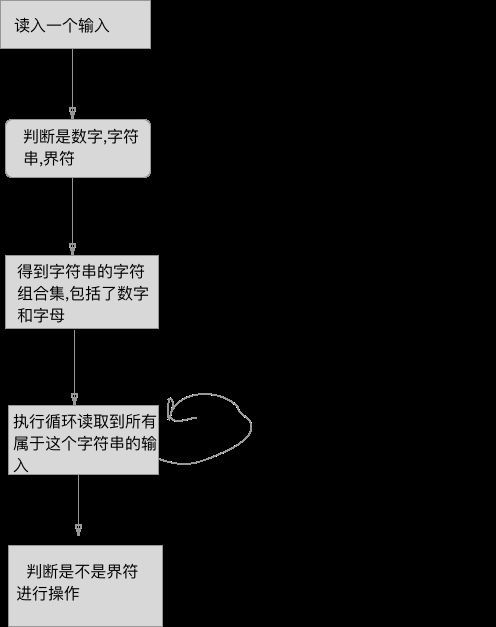
词法分析器.png
-
代码分析
/*
code表:
0 :
1 : 标识符
2 : 常数
3-33 : 对应的是界符中元素的位置
*/#include "string.h" #include "math.h" #include "stdio.h" char keywords[30][12]={ "program","begin","end","var","while","do","repeat", "until","for","to","if","then","else",";", ":", "(", ")", ",", ":=", "+", "-", "*", "/", ">", ">=", "==", "<", "<="}; int num_key=28; /* d · E|e +|- l b -1 1 2 8 9 15 2 2 3 5 11 11 3 4 4 4 5 11 11 5 7 6 6 7 7 7 11 11 8 8 8 12 9 10 14 10 13 d为数字,l为字母,b为界符,-1代表其它符号(如在状态8处遇到了非字母或数字的其它符号,会变换到状态12)。 */ int aut[11][8]={ 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 8, 9,15, 0, 2, 3, 5,11, 0, 0,11, 0, 4, 0, 0, 0, 0, 0, 0, 0, 4, 0, 5,11, 0, 0,11, 0, 7, 0, 0, 6, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 7, 0, 0,11, 0, 0,11, 0, 8, 0, 0, 0, 8, 0,12, 0, 0, 0, 0, 0, 0,10,14, 0, 0, 0, 0, 0, 0, 0,13 }; char ID[50][12]; int C[20]; int num_ID=0,num_C=0; struct token{ int code; int value; }; //Token结构 struct token tok[100]; //Token数组 int i_token=0,num_token=0; //Token计数器和Token个数 char strTOKEN[15]; //当前单词 int i_str; //当前单词指针 int n,p,m,e,t; //尾数值,指数值,小数位数,指数符号,类型 double num;//常数值 char w[50]; //源程序缓冲区 int i; //源程序缓冲区指针,当前字符为w[i] struct map{ //当前字符到状态转换矩阵列标记的映射 char str[50]; int col; }; struct map col1[4]={{"0123456789",1},{".",2},{"Ee",3},{"+-",4}}; //数字 struct map col2[2]={{"abcdefghijklmnopqrstuvwxyz",5},{"0123456789",1}}; //关键字或标识符 struct map col3[1]={{";:(),+-*/=><",6}}; //界符 struct map *ptr; int num_map; void act(int s); int find(int s,char ch); int InsertConst(double num); int Reserve(char *str); int InsertID(char *str); int main(int argc, char* argv[]){ FILE *fp; int s;//当前状态 fp=fopen("/Users/za/Desktop/doc/编译原理/code/Compliers/Compliers/exa.txt","r"); while (fgets(w,50,fp)!=NULL){ //读取文件中的50个字符 printf("1"); i=0; do{ //w[50] = begin /n end while (w[i]==' '){//滤空格 i++; }if (w[i]>='a' && w[i]<='z'){//读取的首个字符是字母 ptr=col2; num_map=2; }else if (w[i]>='0' && w[i]<='9'){//读取的首个字符是数字 ptr=col1; num_map=4; }else if (strchr(col3[0].str,w[i])==NULL){ printf("非法字符%c\n",w[i]); i++; continue; }else{ ptr=col3; num_map=1; } i--; s=1;//开始处理一个单词 //当s不为0时执行循环,s代表的是有限状态自动机中的状态集 while (s!=0){ act(s);//s=1时,strTOKEN[0]='\0' if (s>=11 && s<=14){ break; } /* getchar() i= (-1)=>{0} */ i++; /* s=1 w[0]='b' */ s=find(s,w[i]); } //如果s是等于0跳出的循环 if (s==0){ strTOKEN[i_str]='\0';//代表字符串的结尾 printf("词法错误:%s\n",strTOKEN); } }while (w[i]!=10); } printf("关键字表:");//输出结果 for (i=0;i<30;i++){ printf("%s ",keywords[i]); } printf("\n"); printf("Token序列:"); for (i=0;i