| 项目地址 | https://github.com/F0urty-Tw0/WordCount.git |
| 结对伙伴学号 | 201831061110 |
| 结对伙伴博客链接 | https://www.cnblogs.com/chenxiansheng/ |
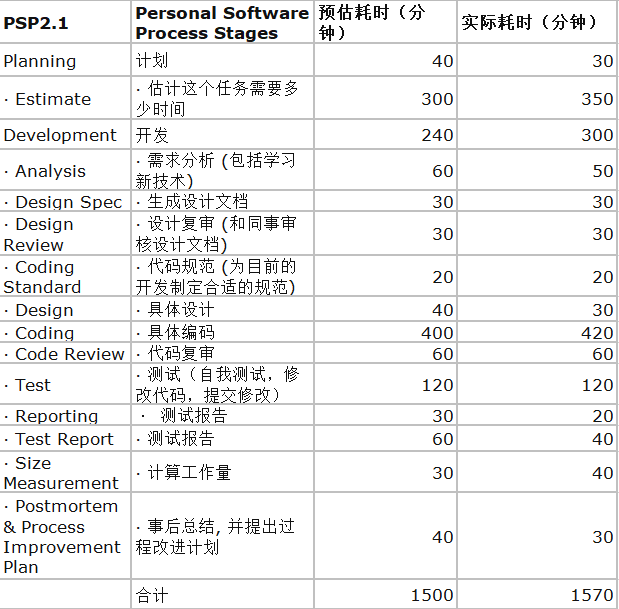
一、PSP表格
二、模块设计与实现
1.代码结构
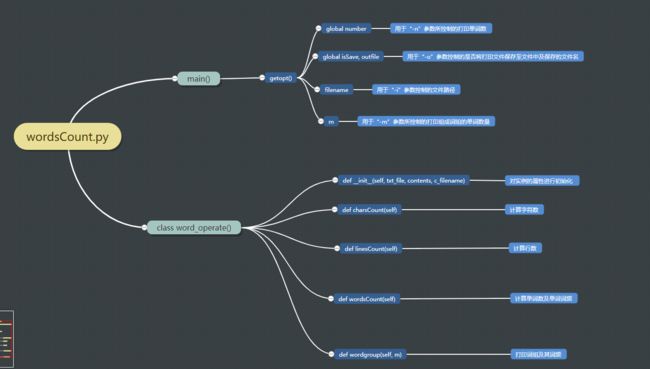
- 程序将处理单词的函数,如计算字符数
charsCount()、行数linesCount()、单词数及词频wordsCount()、打印对应词组数wordgroup()封装为一个类word_operate(),并在main()函数中使用getopt()方法来实现命令行参数"-m"、"-n"、"-i"、"-o"的获取,通过判断getopt获取的命令行参数opt来实现word_operate()类中方法的运行与用户输入不同参数值的交互。
2.关键函数实现
charsCount():
在获取用户指定的文件内容contents后,传入len()函数即可直接求出字符数,其中分隔符如空格,非字母数字符号也会计入在内。linesCount():
获取文件内容contents后使用字符串方法.readlines即可将文件中的每一行存入列表,遍历该列表并设定计数遍历count即可求出文件行数。
wordsCount():
- 计算单词数:题目要求单词至少要以4个英文字母开头,引入python的re模块,利用正则匹配re.findall(r'\w{4}',contents)来将四个字母以上的单词存入列表,在通过len()求出列表长度即为单词数。
计算单词出现词频:先定义一个字典counts,将单词作为键,并通过字典特有的get()方法来判断字典中是否已有对应键,若作为键的单词第一次出现,则直接将值赋值为0,否则沿用键值。
对应代码:counts = {} for word in txtArr: counts[word] = counts.get(word, 0) + 1
wordgroup():
利用列表可以连续读取的特性,利用循环将每次读取的区间进行更新。在利用join函数将列表读取出来的词组转化为字符串做为关键字。再利用字典的get方法获取词组出现的频率
main():
main()函数主要用于获取命令行参数,python中提供了getopt模块来实现按输入不同的命令行选项来实现不同功能,本程序通过定义若干个全局变量来作为getopt()方法返回的opts列表对中的value,通过判断用户输入的不同option来控制函数不同的输出结果。
3.编程思想体现
- Interface Design:
程序在命令行中运行时,若用户未输入任何参数则会打印输入参数示例,提示用户添加参数以正确运行程序:
![]()
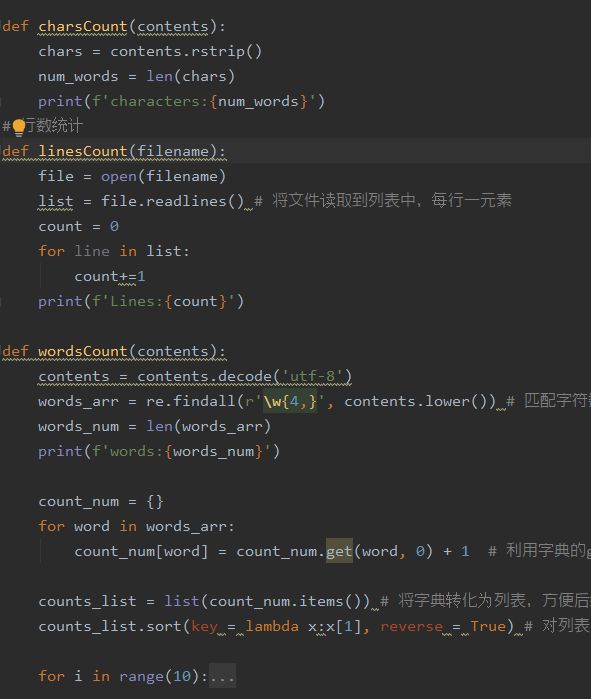
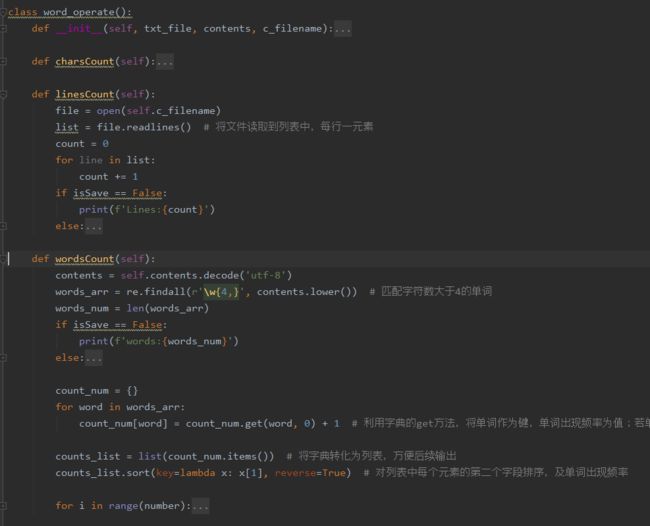
- Loose Coupling:
在一开始写这个程序的时候,我与结对伙伴也只是将实现程序的函数单独实现并且函数与函数之间相互独立,并没有将其封装为一个类,后续通过查阅资料得知将其封装为类后可以保证内部的内聚性与外部的低耦合性。
封装前:
封装后:
4.程序运行结果
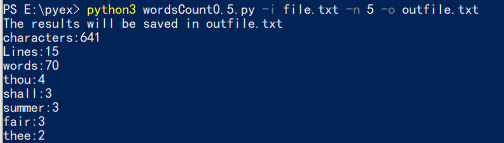
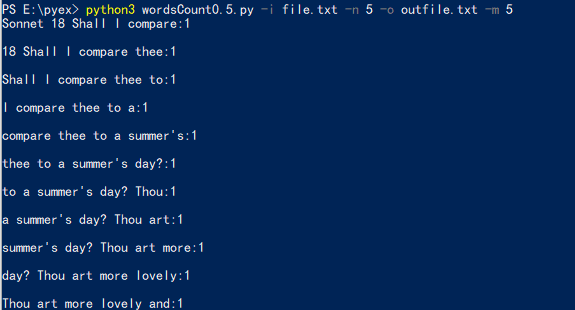

三、代码复审
1.编码规范制定
我与结对伙伴决定采用《Google Python Style Guide》中的编码规范:
中文链接
官方原版
2.复审过程
一开始我与结对伙伴都只进行了自我复审,由于自我感觉良好,也都未发现需要改善的地方,但在后续的同伴复审过程中才开始发现代码编写中不规范的情况,由此,代码复审首先便要端正态度,要以一个旁观者的心态去发现错误,改正错误,让自我复审流程真正行之有效。
同伴复审过程运用pycharm便可便捷地进行,在源代码界面中,编码不规范地情况会被直接标注并提示,如:

提示该行过长,解决这一问题可以运用圆括号实现行的隐式连接:

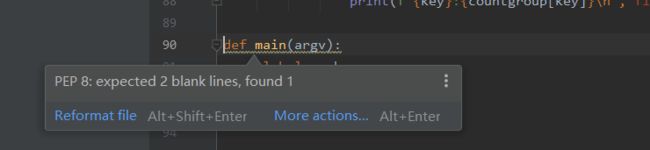
提示函数与函数之间的空行不足,添加至少两个空行即可
四、性能分析及改进
1.性能分析
Pycharm Professional版本中提供了Profile工具来对程序进行方便的性能分析,给出Static统计结果与GUI界面。
在编写好性能测试测程序后,点击Run==>Profile test.py即可开始进行性能测试:
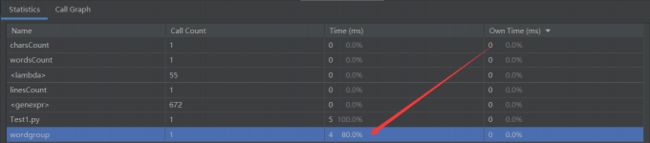
Statics统计结果:
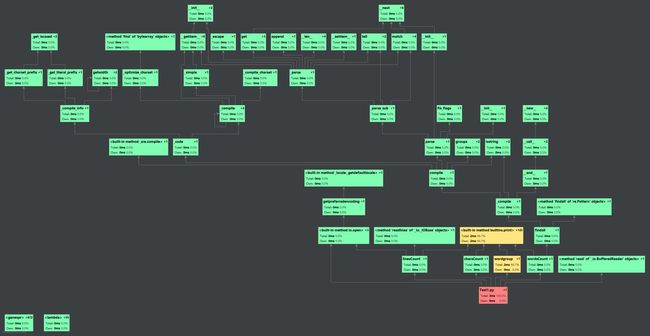
Call Graph:
2.性能改进
通过Statcis统计结果得知wordgroup()函数消耗最大,占总程序的80%,
改进前:
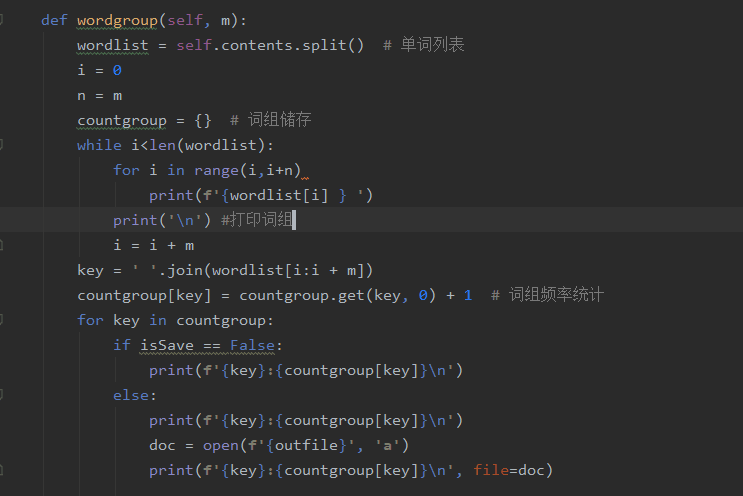
打印词组在词组频率前,不必要循环打印出来,所以改为先储存在字典里,然后直接输出词典的关键字,减少循环:
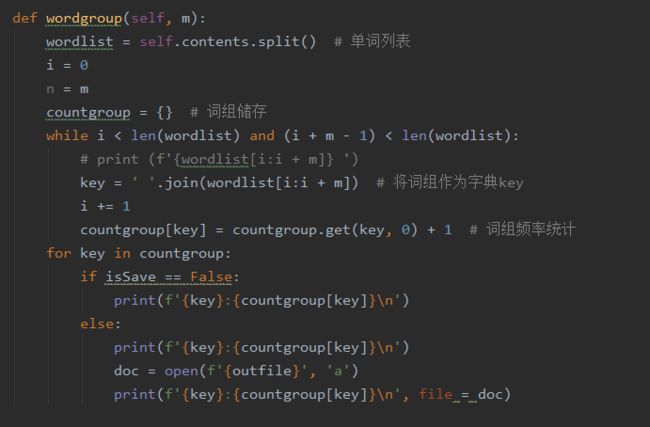
改进后wordgroup()占用:

五、单元测试
Pycharm中选中对应方法即可选择unitest进行单元测试
1.测试程序设计思路
在选择unittest后,会生成一个测试类,从unittest.TestCase中即成,分别编写函数测试word_operate()类中的方法,以test开头的就是测试方法,测试时会自动执行。
具体测试对应函数时,利用断言self.assertEqual(test_func(1), 1)来判断测试函数的返回值是否与期望值相同。
2.单元测试部分代码
from unittest import TestCase
from word_operate import word_operate
class TestWord(TestCase):
def test_charsCount(self):
filename = '111.txt'
file = open(filename, 'r')
contents = file.read()
d = word_operate(file, contents, filename)
self.assertEqual(d.charsCount(contents), 13)
file.close()
def test_linesCount(self):
filename = '111.txt'
file = open(filename, 'r')
contents = file.read()
d = word_operate(file, contents, filename)
self.assertEqual(d.linesCount(filename), 1)
file.close()
def test_wordsCount(self):
filename = '111.txt'
file = open(filename, 'r')
contents = file.read()
d = word_operate(file, contents, filename)
self.assertEqual(d.wordsCount(contents), 1)
file.close()
def wordgroup(self):
filename = '111.txt'
file = open(filename, 'r')
contents = file.read()
d = word_operate(file, contents, filename)
self.assertEqual(d.wordgroup(contents), 1)
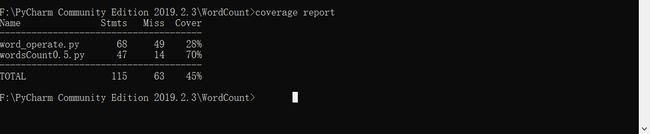
3.单元测试覆盖率
这里要用到Coverage插件,选择对应版本下载即可:
覆盖率测试结果:
六、异常处理说明
1.用户运行时未输入任何参数:
![]()
2.用户运行时“-i”参数后输入不存在的文件名:
![]()
2.用户运行时“-m”与“-n”参数后输入非数字:

七、结对过程
1.照片:

2.结对过程:
考虑到和室友结对可以方便的交流和讨论,就决定和陈俊舟同学结对,我们两个python都有些基础,但都没有面向对象编程的经历,之前虽然写过写小脚本小程序,但都是一个个独立的函数,通过这次结对完成项目,初步掌握了面向对象编程的方法;在程序编写过程中虽然有较多困难,但由于结对编程可以互相鼓励,并及时纠正对方错误,在观察伙伴编写程序时可以互相学习技巧,做到能力上的互补,由此,出现的问题被一个个顺利克服,顺利完成此次程序的编写,由衷地体会到了结对编程地“1+1>2”。