引
最近要倒腾一下文字识别,直接上手iOS的识别遇到了一些困难,于是决定先在Mac上做一做,会比较简单。
有一个经常听到的词汇叫做OCR,OCR是什么呢?Optical Character Recognition,光学字符识别,是图片文字识别的官方学术名称。
要做这么一个听起来比较复杂的事情,如果有现成的开源框架那是最好的,如果你大致了解一下,就会发现开源界Tesseract是用的最多的,也是大多数接触这个领域的人最开始拿来练手的东西。简单介绍一下Tesseract的历史,其最早由HP实验室在1985年研发,10年后,也就是1995年已经是业内最准确的识别引擎之一了,但是HP后来放弃了OCR业务,不过好消息是后来HP决定反正不用,不如开源出来,所以2005年,又是10年后,Tesseract开源了,并且委托Google进行改进、优化的工作。
所以现在一说Tesseract往往看到的都是说Google的框架,其实还有这么一段历史在其中。
准备工作
要在Mac下用Tesseract,肯定要进行安装,安装Tesseract之前,我们需要做一些准备工作。
Xcode Command Line Tool
首先安装Xcode Command Line Tool,Command Line Tool是Xcode中的一款工具,从App Store下载Xcode之后,默认没有安装Command Line Tool,安装之后就可以在终端命令行中运行一些C程序。
安装方法很简单,打开终端输入:xcode-select --install,会弹出确认窗口:

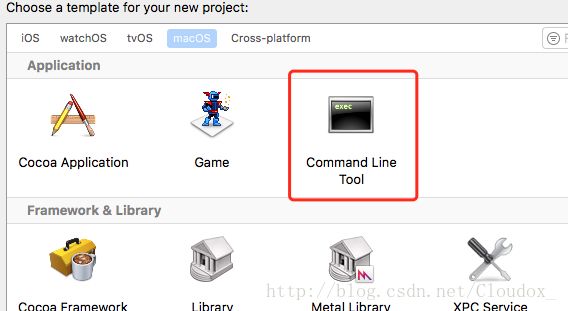
直接点击安装就可以了,一段时间之后就安装好了,有进度条显示,十几分钟吧。检查是否安装成功的方法是再次在终端输入上述命令,会提示已经安装过了,或者在Xcode新建工程,选择macOS下,会多出一个Command Line Tool:
MacPorts
平常我们安装Mac上的软件,常用的两种方式是App Store和dmg,除此之外,还可以用MacPorts来安装,它就像apt-get、yum一样,可以通过命令行快速安装一些软件,很方便,类似于我们通过命令行用cocoapods来安装第三方开发库。
进入MacPorts的官网:http://www.macports.org/

下载安装包后安装它,可能会要求重启mac。
我们主要用来安装Tesseract,其他的用法大家可以自己慢慢发掘。
安装Tesseract
准备工作完毕后,就可以安装Tesseract了。
打开终端输入:sudo port install tesseract
会要求输入电脑密码,mac终端中输入密码是看不到的,只管输入就好。
然后等待它自个去安装一大堆依赖和Tesseract。安装完后可以检查一下是否安装成功,终端输入tesseract后回车,会出来一些信息和一些配置方式,或者输入tesseract -v,会显示安装的Tesseract版本信息,目前(2017.6.1)MacPorts安装的Tesseract版本是3.04.01,不过此时github上,包括cocoapods上最新的版本已经是4.0了 。
这时候是不是可以跑Tesseract了呢?还不行,因为Tesseract是一款OCR引擎,要识别文字,一定要有语言库,Tesseract能够识别100多种语言,语言库是比较大的,它不会一开始就都帮你安装了,需要你按需安装,它甚至连英语语言包都没有默认安装,但是运行程序是必须要安装好英语语言包的,注意,是运行程序,不是识别英语,我觉得这一点特别奇怪,如果你必须要那就直接默认自带啊...所以我们还要安装语言包。
还是在终端,输入命令:sudo port install tesseract-<语言包名>,MacPorts支持的语言包名可以在MacPorts tesseract page查看。
注意上面命令中的尖括号并不需要输入,如果你在命令行中包括了尖括号,会显示:
-bash: syntax error near unexpected token `newline'
尖括号是命令行命令的一种习惯表示方法,表示这里要被替换掉。比如我们在网页中找到英语语言包的名称:

那实际上我们需要输入的命令是:sudo port install tesseract-eng
顺便我们可以把中文语言包也给装了,简体中文的名称是"chi_sim",所以命令是:sudo port install tesseract-chi_sim
至此,Tesseract安装完毕,可以开始体验神奇了。
使用Tesseract
使用Tesseract同样是通过命令行的方式。先准备一张图片,然后通过命令行进入该图片存放的位置(用cd命令)。
Tesseract的命令格式为:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
其中有几个参数:
imagename是你要识别的图片的名字,不需要打引号,直接输入即可。
outputbase是输出结果文件的名字,不需要文件类型后缀,就是txt,这个参数就是txt的文件名。
lang是要用的语言代码,默认是英语,如果你要识别中文,就写 -l chi_sim,如果你要中英都识别,用 + 号把语言代码连起来:-l chi_sim+eng。
pagesegmode是用来识别的模式,之前输入tesseract命令时应该也看到了,包含这些模式:
- 0 = Orientation and script detection (OSD) only.
- 1 = Automatic page segmentation with OSD.
- 2 = Automatic page segmentation, but no OSD, or OCR
- 3 = Fully automatic page segmentation, but no OSD. (Default)
- 4 = Assume a single column of text of variable sizes.
- 5 = Assume a single uniform block of vertically aligned text.
- 6 = Assume a single uniform block of text.
- 7 = Treat the image as a single text line.
- 8 = Treat the image as a single word.
- 9 = Treat the image as a single word in a circle.
- 10 = Treat the image as a single character.
现在可以开始演练了。
准备一张英文图片,比如:
放在下载目录,命令行 cd Downloads 进入下载目录,然后输入:
tesseract test.png out
识别完成后会在下载目录多处一个out.txt的文件,里面包含识别出的文字:
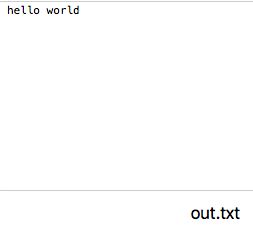
英文还是比较准的。
下面我们来识别中文,准备一张中文图片:
输入:
tesseract test.png result -l chi_sim
也可以正确识别出来(识别后的文件为result.txt):
惊不惊喜,意不意外。但是,别看这里都识别出来了,其实中文识别率并不高,越简单、间隔越大、字体越大就识别的越好,如果是:
那么识别结果就崩了:
那怎么办呢,折腾了一圈,结果识别出来是这个鬼样子,机器就是厉害,懂这么多我不认识的字。
Tesseract用来识别英语或者类似的文字比较厉害,但是识别汉字这种象形文字就比较差了,不过还有得救,我们可以训练它,这就是Tesseract训练相关的知识了,之后再讲。
结
通过这篇文章,即使一个纯新手应该也可以顺利感受到文字识别的神奇了,但是要想效果更好,路还很长,共同学习吧。
查看作者首页