Spark 学习笔记
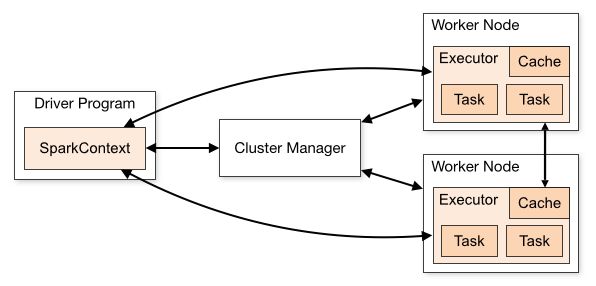
Spark 架构及组件
image
image
- client:客户端进程,负责提交job到master
- Driver:运行Application,主要是做一些job的初始化工作,包括job的解析,DAG的构建和划分并提交和监控task
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker,在YARN模式中为资源管理器ResourceManager
- Worker:负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver。Executor,即真正执行作业的地方,一个Executor可以执行一到多个Task
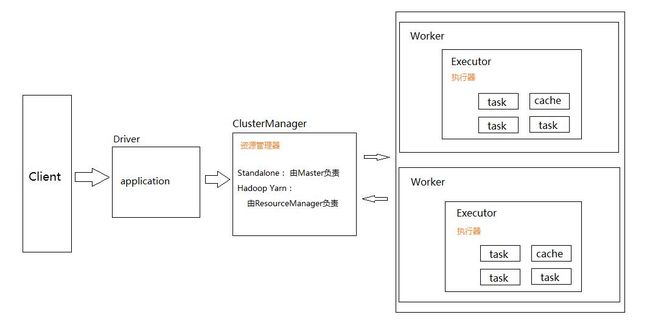
Spark 执行流程

image
- 通过SparkSubmit提交job后,Client就开始构建 spark context,即 application 的运行环境(使用本地的Client类的main函数来创建spark context并初始化它)
- yarn client提交任务,Driver在客户端本地运行;yarn cluster提交任务的时候,Driver是运行在集群上
- SparkContext连接到ClusterManager(Master),向资源管理器注册并申请运行Executor的资源(内核和内存)
- Master根据SparkContext提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动executor
- Worker节点收到请求后会启动executor
- executor向SparkContext注册,这样driver就知道哪些executor运行该应用
- SparkContext将Application代码发送给executor(如果是standalone模式就是StandaloneExecutorBackend)
- 同时SparkContext解析Application代码,构建DAG图,提交给DAGScheduler进行分解成stage,stage被发送到TaskScheduler。
- TaskScheduler负责将Task分配到相应的worker上,最后提交给executor执行
- executor会建立Executor线程池,开始执行Task,并向SparkContext汇报,直到所有的task执行完成
- 所有Task完成后,SparkContext向Master注销
Spark HelloWord
Java 版本
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("wordcount");
JavaRDD rdd = new JavaSparkContext(conf).textFile("file:///Users/garen/demo/wordcount.txt");
rdd.flatMap(line -> Arrays.asList(line.split(","))) // 将一行文本以逗号分隔成每个单词
.filter(word -> StringUtils.isNoneEmpty(word)) // 过滤空白单词
.mapToPair(word -> new Tuple2<>(word, Integer.parseInt("1"))) // 将单词转换成(word,1)的 Tuple 类型
.reduceByKey((v1, v2) -> v1 + v2) // 按 word 进行单词计数
.foreach(new VoidFunction>() { // 打印
@Override
public void call(Tuple2 t) throws Exception {
System.out.println(t._1 + " : " + t._2);
}
});
scala 版本
val conf = new SparkConf().setMaster("local[4]").setAppName("WordCount")
val sc = SparkContext.getOrCreate(conf)
sc.textFile("file:///Users/garen/demo/wordcount.txt", 2) // 读取文件生成 rdd,默认每个 HDFS 数据块为一个 rdd 分区
.flatMap(_.split(",")) // 将每行数据按逗号分隔生成新的 rdd
.filter(_ != Nil) // 去除脏数据
.map((_, 1)) // 将数据格式转换为(word,1)的 Tuple 类型
.reduceByKey(_ + _) // 按 word 分组并进行次数统计
.foreach(println)
Spark 核心编程
RDD的创建
集合创建 RDD
public class RddCreateFromArray {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("demo");
JavaSparkContext jsc = new JavaSparkContext(conf);
// 通过集合创建 RDD
JavaRDD rdd = jsc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9));
// 执行累加操作
Integer result = rdd.reduce((v1, v2) -> {
return v1 + v2;
});
// 打印执行结果
System.out.println("result: " + result);
// JavaSparkContext 建议手动关闭
jsc.close();
}
}
object RddCreateFromArray extends App {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("demo")
val context: SparkContext = SparkContext.getOrCreate(conf)
/*
* 通过集合创建 RDD
* 第二个参数代表分区数目
*/
val arrayRDD: RDD[Int] = context.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9))
// 执行累加操作
val result: Int = arrayRDD.reduce(_ + _)
// 输出累加结果
println(s"result: ${result}")
}
本地文件系统创建 RDD
/*
* java版本
*/
public class RddCreateFromLocalFile {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("demo");
JavaSparkContext sc = new JavaSparkContext(conf);
// 使用本地文件创建 RDD
JavaRDD initRDD = sc.textFile("file:///Users/garen/demo/wordcount.txt", 2);
// 将每行文本按逗号分隔形成新的 RDD
JavaRDD flatMapRDD = initRDD.flatMap(line -> Arrays.asList(line.split(",")));
// 过滤无效的单词
JavaRDD filterRDD = flatMapRDD.filter(word -> StringUtils.isNotEmpty(word));
// 将单词组成(word,1)类型的 tuple
JavaRDD> mapRDD = filterRDD.map(word -> new Tuple2(word, Integer.parseInt("1")));
// 相同的单词进行分组操作
JavaPairRDD>> groupByRDD = mapRDD.groupBy(t -> t._1());
// 将结果转换为(word,count)的 tuple 类型
JavaRDD resultRDD = groupByRDD.map(t -> {
Iterator> iterator = t._2().iterator();
int size = 0;
while (iterator.hasNext()) {
iterator.next();
size++;
}
return new Tuple2(t._1(), size);
});
// 循环打印结果
resultRDD.foreach(t -> System.out.println(t._1() + " : " + t._2()));
}
}
/*
*scala 版本
*/
object RddCreateFromLocalFile extends App {
val conf = new SparkConf().setMaster("local[4]").setAppName("demo")
val sc = SparkContext.getOrCreate(conf)
// 使用本地文件创建 RDD
val initRdd = sc.textFile("file:///Users/garen/demo/wordcount.txt")
// 将每行文本按逗号分隔形成新的 RDD
val flatMapRdd = initRdd.flatMap(_.split(","))
// 过滤无效的单词
val filterRdd = flatMapRdd.filter(_ != Nil)
// 将单词组成(word,1)类型的 tuple
val mapRdd = filterRdd.map((_, 1))
// 相同的单词进行分组操作
val reduceRdd = mapRdd.reduceByKey(_ + _)
// 循环打印结果
reduceRdd.foreach(println)
}
HDFS 文件创建 RDD
HDFS文件创建 RDD 跟从本地文件创建 RDD 是一样的,只不过需要事先将文件传到 HDFS,同时 URL 要替换为:hdfs://hadoop-cdh:8020/User/hadoop/wordcount.txt
KEY-VAlUE类型操作(统计相同行行数为例)
@SuppressWarnings("all")
public class LineCount {
public static void main(String[] args) {
// 初始化 SparkConf 和 JavaSparkContext
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName(LineCount.class.getSimpleName());
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文件生成 RDD
JavaRDD initRDD = sc.textFile(LineCount.class.getClassLoader().getResource("demo.txt").getPath());
// 过滤空行
JavaRDD filterRDD = initRDD.filter(line -> StringUtils.isNotEmpty(line));
// 修改数据格式为 Tuple2 类型
JavaPairRDD mapToPairRDD = filterRDD
.mapToPair(line -> new Tuple2(line, new Integer(1)));
// 计算内容相同的行有多少
JavaPairRDD reduceByKeyRDD = mapToPairRDD
.reduceByKey((v1, v2) -> Integer.valueOf(v1.toString()) + Integer.valueOf(v2.toString()));
// 过滤有多行的数据
JavaPairRDD filterRDD2 = reduceByKeyRDD.filter(t -> t._2 > 0);
// 打印
filterRDD2.foreach(t -> System.out.println(t._1 + " : " + t._2));
}
}
object LineCount extends App {
// 初始化 SparkConf 和 SparkContext
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("LineCount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
// 读取文件生成 RDD
val rdd: RDD[String] = sc.textFile(Thread.currentThread().getContextClassLoader.getResource("demo.txt").getPath)
// 过滤空行
val filterRDD = rdd.filter(_ != Nil)
// 修改数据格式为 (line,1) 类型
val mapRDD = filterRDD.map((_, 1))
// 计算内容相同的行有多少
val reduceByKeyRDD = mapRDD.reduceByKey(_ + _)
// 过滤有多行的数据
val filterRDD2 = reduceByKeyRDD.filter(_._2 > 1)
// 打印
val collectRDD = filterRDD2.collect()
collectRDD.foreach(println)
Thread.sleep(1000000)
}
常用的 Transformation
| 操作 | 介绍 |
|---|---|
| map | 将 RDD 中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的 RDD |
| filter | 对 RDD 中每个元素进行判断,如果返回 true 则保留,如果返回false 则剔除 |
| flatMap | 与 map 类似,但是对每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据 key 进行分组,每个 key 对应一个Iterable |
| reduceByKey | 对相同key 的 value 进行 reduce 操作 |
| sortByKey | 对相同 key 的 value 值进行排序 |
| join | 对两个包含 |
| cogroup | 同 join,但是是每个 key对应的Iterable |
map -- 将集合的所有元素都乘以二
// java 语言描述
public static void map() {
SparkConf conf = new SparkConf().setAppName("Map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 通过集合创建 RDD
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9));
// RDD 的 map 操作
JavaRDD mapRDD = rdd.map(t -> t * 2);
// 打印 RDD 执行结果
System.out.println(mapRDD.collect());
}
// scala 语言描述
def map(): Unit = {
println("---------- Map:")
val conf = new SparkConf().setMaster("local[4]").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8))
println(rdd.map(_ * 2).collect.toBuffer)
}
filter -- 过滤偶数元素
// java 语言描述
public static void filter() {
SparkConf conf = new SparkConf().setAppName("Filter").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 通过集合创建 RDD
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9));
// filter 操作
JavaRDD filterRDD = rdd.filter(v -> v % 2 == 0);
// 打印 RDD 执行结果
System.out.println(filterRDD.collect());
}
// scala 语言描述
def filter(): Unit = {
println("---------- Filter:")
val conf = new SparkConf().setMaster("local[4]").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8))
println(rdd.filter(_ % 2 == 0).collect.toBuffer)
}
flatMap -- 单词拆分
public static void flatMap() {
SparkConf conf = new SparkConf().setAppName("FlatMap").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建 RDD
JavaRDD rdd = sc.parallelize(Arrays.asList("hadoop,hive,spark","spark,hbase,impala"));
// 将每个元素的值使用逗号分隔,产生的新元素重新组成新的 RDD
JavaRDD flatMapRDD = rdd.flatMap(v -> Arrays.asList(v.split(",")));
// 打印结果
System.out.println(flatMapRDD.collect());
}
def flatMap(): Unit = {
println("---------- FlatMap:")
val conf = new SparkConf().setMaster("local[4]").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Array("hadoop,hive,spark", "hive,spark,hbase"))
println(rdd.flatMap(_.split(",")).collect.toBuffer)
}
groupByKey -- 成绩按班级分组
public static void groupByKey() {
SparkConf conf = new SparkConf().setAppName("GroupByKey").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List> list = Arrays.asList(
new Tuple2("class1", 70), new Tuple2("class2", 80),
new Tuple2("class1", 80), new Tuple2("class2", 70));
JavaPairRDD rdd = sc.parallelizePairs(list);
JavaPairRDD> groupByKeyRDD = rdd.groupByKey();
groupByKeyRDD.foreach(t -> {
System.out.println(t._1 + " : " + t._2);
});
}
def groupByKey(): Unit = {
println("---------- GroupByKey:")
val conf = new SparkConf().setMaster("local").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Array(("class1", 11), ("class2", 21), ("class1", 10), ("class2", 20)))
rdd.groupByKey().foreach(t => {
println(s"${t._1} -- ${t._2}")
})
}
reduceByKey -- 计算每个班的成绩总和
public static void reduceByKey() {
SparkConf conf = new SparkConf().setAppName("ReduceByKey").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List> list = Arrays.asList(new Tuple2("class1", 70), new Tuple2("class2", 80),
new Tuple2("class1", 80), new Tuple2("class2", 70));
JavaPairRDD rdd = sc.parallelizePairs(list);
JavaPairRDD reduceByKeyRDD = rdd.reduceByKey((v1, v2) -> v1 + v2);
reduceByKeyRDD.foreach(t -> System.out.println(t._1 + " : " + t._2));
}
def reduceByKey(): Unit = {
println("---------- ReduceByKey:")
val conf = new SparkConf().setMaster("local").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Array(("class1", 11), ("class2", 21), ("class1", 10), ("class2", 20)))
rdd.reduceByKey(_ + _).foreach(t => println(s"${t._1} : ${t._2}"))
}
sortByKey -- 根据 key 排序
public static void sortByKey() {
SparkConf conf = new SparkConf().setAppName("SortByKey").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List> list = Arrays.asList(new Tuple2(60, "tom"), new Tuple2(70, "peter"),
new Tuple2(80, "marry"));
JavaPairRDD rdd = sc.parallelizePairs(list);
JavaPairRDD sortByKeyRDD = rdd.sortByKey(false);
sortByKeyRDD.foreach(t -> System.out.println(t._1 + " : " + t._2));
}
def sortByKey(): Unit = {
println("---------- SortByKey:")
val conf = new SparkConf().setMaster("local").setAppName("Transformation")
val sc = SparkContext.getOrCreate(conf)
val array = Array((60, "peter"), (70, "tony"), (80, "marry"))
val rdd = sc.parallelize(array)
rdd.sortByKey(false).foreach(println)
}
join -- 计算每个人的成绩
public static void join() {
SparkConf conf = new SparkConf().setAppName("Join").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List> studentList = Arrays.asList(new Tuple2(1001, "tome"), new Tuple2(1002, "jetty"),
new Tuple2(1003, "karry"));
List> scoreList = Arrays.asList(new Tuple2(1001, 80), new Tuple2(1002, 30),
new Tuple2(1003, 70));
JavaPairRDD studentRDD = sc.parallelizePairs(studentList);
JavaPairRDD scoreRDD = sc.parallelizePairs(scoreList);
JavaPairRDD> joinRDD = studentRDD.join(scoreRDD);
joinRDD.foreach(t -> System.out.println("studentID:" + t._1 + " studentName:" + t._2._1 + " studentScore:" + t._2._2));
}
def join(): Unit = {
println("---------- Join:")
val conf = new SparkConf().setAppName("Transformation").setMaster("local")
val sc = SparkContext.getOrCreate(conf)
val studentArray = Array((1001, "tom"), (1002, "netty"), (1003, "merry"))
val scoreArray = Array((1001, 10), (1002, 20), (1003, 30))
val studentRDD = sc.parallelize(studentArray)
val scoreRDD = sc.parallelize(scoreArray)
val joinRDD = studentRDD.join(scoreRDD)
joinRDD.foreach(t => println(s"studentID:${t._1} studentName:${t._2._1} studentScore:${t._2._2}"))
}
cogroup -- 查看每个学生的姓名和成绩
cogroup 和 join 的区别是:cogroup 会把合并的结果以两个 Iterable 的形式返回
public static void cogroup() {
SparkConf conf = new SparkConf().setAppName("Join").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List> studentList = Arrays.asList(new Tuple2(1001, "tome"), new Tuple2(1002, "jetty"),
new Tuple2(1003, "karry"));
List> scoreList = Arrays.asList(new Tuple2(1001, 80), new Tuple2(1002, 30),
new Tuple2(1003, 70));
JavaPairRDD studentRDD = sc.parallelizePairs(studentList);
JavaPairRDD scoreRDD = sc.parallelizePairs(scoreList);
JavaPairRDD, Iterable>> cogroupRDD = studentRDD.cogroup(scoreRDD);
cogroupRDD.foreach(t -> System.out.println(t));
}
def cogroup(): Unit = {
println("---------- cogroup:")
val conf = new SparkConf().setAppName("Transformation").setMaster("local")
val sc = SparkContext.getOrCreate(conf)
val studentArray = Array((1001, "tom"), (1002, "netty"), (1003, "merry"))
val scoreArray = Array((1001, 10), (1002, 20), (1003, 30), (1003, 40))
val studentRDD = sc.parallelize(studentArray)
val scoreRDD = sc.parallelize(scoreArray)
studentRDD.cogroup(scoreRDD).foreach(println)
}
常用的 Action 操作
| 操作 | 介绍 |
|---|---|
| reduce | 将 RDD 中所有元素进行聚合操作,第一个元素和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推 |
| collect | 将 RDD 中所有元素获取到本地客户端 |
| count | 获取RDD 元素总数 |
| take(n) | 获取 RDD前 N 个元素 |
| saveAsTextFile | 将 RDD 元素保存到文件中,对每个元素调用 toString 方法 |
| countByKey | 对每个 key 的值进行 count 计数 |
| foreach | 遍历 RDD 中的所有元素 |
reduce -- 计算集合的总和
public static void reduce() {
SparkConf conf = new SparkConf().setAppName("foreach").setMaster("local[4]");
JavaSparkContext sc = new JavaSparkContext(conf);
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD numberRDD = sc.parallelize(numberList);
Integer reduceResult = numberRDD.reduce((v1, v2) -> v1 + v2);
System.out.println("result:" + reduceResult);
}
def reduce(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("reduce").setMaster("local[4]")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val numberArray: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
val numberRDD: RDD[Int] = sc.parallelize(numberArray)
val result: Int = numberRDD.reduce(_+_)
println(s"result:${result}")
}
collect -- 将所有 RDD 数据获取到本地
public static void collect() {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("collect");
JavaSparkContext sc = new JavaSparkContext(conf);
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD numberRDD = sc.parallelize(numberList, 4);
numberRDD.collect().forEach(System.out::println);
}
def collect(): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("collect")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val numbers: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
val numbersRDD: RDD[Int] = sc.parallelize(numbers, 4)
val array: Array[Int] = numbersRDD.collect()
for (t <- array) {
println(s"RDD item : ${t}")
}
}
count -- 计算 RDD 中元素的个数
public static void count() {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("collect");
JavaSparkContext sc = new JavaSparkContext(conf);
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD numberRDD = sc.parallelize(numberList, 4);
long count = numberRDD.count();
System.out.println("count:" + count);
}
def count(): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("collect")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val numbers: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
val numbersRDD: RDD[Int] = sc.parallelize(numbers, 4)
val count = numbersRDD.count()
println(s"count:${count}")
}
RDD持久化
cache 方法和 persist 方法,其实 cache 方法底层调用的是 persist 方法
- Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中。当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些 数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互使用来说,缓存是一个关键的工具。
- 你能通过
persist()或者cache()方法持久化一个rdd。首先,在action中计算得到rdd;然后,将其保存在每个节点的内存中。Spark的缓存是一个容错的技术-如果RDD的任何一个分区丢失,它 可以通过原有的转换(transformations)操作自动的重复计算并且创建出这个分区。 - 此外,我们可以利用不同的存储级别存储每一个被持久化的RDD。例如,它允许我们持久化集合到磁盘上、将集合作为序列化的Java对象持久化到内存中、在节点间复制集合或者存储集合到 Tachyon中。我们可以通过传递一个StorageLevel对象给persist()方法设置这些存储级别。cache()方法使用了默认的存储级别
—StorageLevel.MEMORY_ONLY。完整的存储级别介绍如下所示:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。 |
| MEMORY_AND_DISK | 将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 |
| MEMORY_ONLY_SER | 将RDD作为序列化的Java对象存储(每个分区一个byte数组)。这种方式比非序列化方式更节省空间,特别是用到快速的序列化工具时,但是会更耗费cpu资源—密集的读操作。 |
| MEMORY_AND_DISK_SER | 和MEMORY_ONLY_SER类似,但不是在每次需要时重复计算这些不适合存储到内存中的分区,而是将这些分区存储到磁盘中。 |
| DISK_ONLY | 仅仅将RDD分区存储到磁盘中 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 | 和上面的存储级别类似,但是复制每个分区到集群的两个节点上面 |
| OFF_HEAP (experimental) | 以序列化的格式存储RDD到Tachyon中。相对于MEMORY_ONLY_SER,OFF_HEAP减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中具有更强的吸引力。 |
删除持久化数据
Spark自动的监控每个节点缓存的使用情况,利用最近最少使用原则删除老旧的数据。如果你想手动的删除RDD,可以使用RDD.unpersist()方法
RDD共享变量
广播变量(BroadcastVariable)
Spark中分布式执行的代码需要传递到各个Executor的Task上运行。对于一些只读、固定的数据(比如从DB中读出的数据),每次都需要Driver广播到各个Task上,这样效率低下。广播变量允许将变量只广播(提前广播)给各个Executor。该Executor上的各个Task再从所在节点的BlockManager获取变量,而不是从Driver获取变量,从而提升了效率。
// java 语言实现广播变量(Broadcast)
public static void broadcast() {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("BroadcastVariable");
JavaSparkContext sc = new JavaSparkContext(conf);
List> smallTable = Arrays.asList(
new Tuple2(1001, 21),
new Tuple2(1002, 22),
new Tuple2(1003, 23),
new Tuple2(1004, 24),
new Tuple2(1005, 25),
new Tuple2(1006, 26)
);
Broadcast>> smallTableBroadcast = sc.broadcast(smallTable);
List> bigTable = Arrays.asList(
new Tuple2(1001, "tom1"),
new Tuple2(1002, "tom2"),
new Tuple2(1003, "tom3"),
new Tuple2(1004, "tom4"),
new Tuple2(1005, "tom5"),
new Tuple2(1006, "tom6")
);
JavaPairRDD smallRDD = sc.parallelizePairs(smallTableBroadcast.value());
JavaPairRDD bigRDD = sc.parallelizePairs(bigTable);
JavaPairRDD> joinRDD = (JavaPairRDD>) smallRDD.join(bigRDD);
joinRDD.foreach(v -> System.out.println("ID:" + v._1 + " AGE:" + v._2._1 + " NAME:" + v._2._2));
}
// scala 语言实现(Broadcast)
def broadcastVariable(): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BroadcastVariable")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val smallTableArray: Array[(Int, Int)] = Array(
(1001, 21), (1002, 22), (1003, 23), (1004, 24)
)
val smallTableBroadcast: Broadcast[Array[(Int, Int)]] = sc.broadcast(smallTableArray)
val bigTableArray: Array[(Int, String)] = Array(
(1001, "tom1"), (1002, "tom2"), (1003, "tom3"), (1004, "tom4")
)
val bigTableRDD: RDD[(Int, String)] = sc.parallelize(bigTableArray)
val smallTableRDD: RDD[(Int, Int)] = sc.parallelize(smallTableBroadcast.value)
bigTableRDD.join(smallTableRDD).foreach(v => println(s"ID:${v._1} NAME:${v._2._1} AGE:${v._2._2}"))
}
累加器(Accumulator)
Accumulator是spark提供的累加器,顾名思义,该变量只能够增加。只有driver能获取到Accumulator的值(使用value方法),Task只能对其做增加操作(使用 +=)
// java语言实现累加器(accumulator)
public static void accumulator() {
SparkConf conf = new SparkConf().setMaster("local").setAppName("Accumulator");
JavaSparkContext sc = new JavaSparkContext(conf);
org.apache.spark.Accumulator sumAccumulator = sc.accumulator(0, "SUM");
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9), 3);
rdd.foreach(v -> sumAccumulator.add(v));
System.out.println("Accumulator:" + sumAccumulator.value());
}
// scala语言实现累加器(accumulator)
def accumulator(): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("Accumulator")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val sumAccumulator: Accumulator[Int] = sc.accumulator(0, "SUM")
val rdd: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9))
rdd.foreach(v => sumAccumulator.add(v))
println(s"SUM:${sumAccumulator.value}")
}
Spark 应用程序打包并使用 spark-submit 提交执行
Spark 案例
带排序的WordCount
计算wordcount并按单词出现次数排序
// scala语言实现
def sortWordcount(): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("SortWordcount")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.textFile(Thread.currentThread().getContextClassLoader.getResource("wordcount.txt").getPath)
rdd.flatMap(_.split(" "))
.filter(StringUtils.isNoneBlank(_))
.map((_, 1))
.reduceByKey(_ + _)
.map(t => (t._2, t._1))
.sortByKey(false)
.map(t => (t._2, t._1))
.foreach(println)
}
public static void sortWordcount() {
SparkConf conf = new SparkConf().setMaster("local[5]").setAppName("SortWordcount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.textFile(Thread.currentThread().getContextClassLoader().getResource("wordcount.txt").getPath());
rdd.flatMap(line -> Arrays.asList(line.split(" ")))
.filter(word -> StringUtils.isNotEmpty(word))
.mapToPair(word -> new Tuple2(word, 1))
.reduceByKey((v1, v2) -> v1 + v2)
.mapToPair(t -> new Tuple2(t._2, t._1))
.sortByKey(false)
.mapToPair(t -> new Tuple2(t._2, t._1))
.foreach(t -> System.out.println("word:" + t._1 + "\t times:" + t._2));
}
二次排序
单词计数,先按次数排序,次数相同的按单词的hash码排序
// 二次排序的key
public class SecondarySortKey implements Ordered, Serializable {
private String word;
private Integer count;
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
SecondarySortKey that = (SecondarySortKey) o;
if (!word.equals(that.word)) return false;
return count.equals(that.count);
}
@Override
public int hashCode() {
int result = word.hashCode();
result = 31 * result + count.hashCode();
return result;
}
public SecondarySortKey(String word, Integer count) {
this.word = word;
this.count = count;
}
public SecondarySortKey() {
}
@Override
public int compare(SecondarySortKey that) {
return this.count - that.count != 0 ? this.count - that.count : this.word.hashCode() - that.word.hashCode();
}
@Override
public boolean $less(SecondarySortKey that) {
if (this.count != that.count) {
return this.count - that.count < 0 ? true : false;
} else if (!this.word.equals(that.word)) {
return this.word.hashCode() - that.word.hashCode() < 0 ? true : false;
} else {
return false;
}
}
@Override
public boolean $greater(SecondarySortKey that) {
if (this.count != that.count) {
return this.count - that.count > 0 ? true : false;
} else if (!this.word.equals(that.word)) {
return this.word.hashCode() - that.word.hashCode() > 0 ? true : false;
} else {
return false;
}
}
@Override
public boolean $less$eq(SecondarySortKey that) {
if (this.$less(that)) {
return true;
} else if (this.count == that.count && this.word.equals(that.word)) {
return true;
} else {
return false;
}
}
@Override
public boolean $greater$eq(SecondarySortKey that) {
if (this.$greater(that)) {
return true;
} else if (this.count == that.count && this.word.equals(that.word)) {
return true;
} else {
return false;
}
}
@Override
public int compareTo(SecondarySortKey that) {
return this.compare(that);
}
}
// 二次排序的Driver程序
public static void secondarySort() {
SparkConf conf = new SparkConf().setMaster("local").setAppName("SecondarySort");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.textFile(Thread.currentThread().getContextClassLoader().getResource("wordcount.txt").getPath(), 1)
.flatMap(line -> Arrays.asList(line.split(" ")))
.filter(word -> StringUtils.isNotBlank(word))
.mapToPair(word -> new Tuple2(word, 1))
.reduceByKey((v1, v2) -> v1 + v2)
.mapToPair(t -> new Tuple2(new SecondarySortKey(t._1, t._2), 1))
.sortByKey(true)
.map(t -> new Tuple2(t._1.getWord(), t._1.getCount()))
.foreach(t -> System.out.println(t._1 + " " + t._2));
}
// 二次排序的key
case class SecondarySortKey(word: String, count: Integer) extends Ordered[SecondarySortKey] with Serializable {
override def compare(that: SecondarySortKey) = {
if (this.count - that.count != 0) this.count - that.count else this.word.hashCode - that.word.hashCode
}
}
def secondarySort(): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SecondarySort")
val sc = SparkContext.getOrCreate(conf)
sc.textFile(Thread.currentThread().getContextClassLoader.getResource("wordcount.txt").getPath, 1)
.flatMap(_.split(" "))
.filter(StringUtils.isNoneBlank(_))
.map((_, 1))
.reduceByKey(_ + _)
.map(t => (new SecondarySortKey(t._1, t._2), 1))
.sortByKey(true)
.map(t => (t._1.word, t._1.count))
.foreach(t => println(s"word:${t._1} \t\t times:${t._2}"))
}
TopN
排序取TopN
public static void topN() {
SparkConf conf = new SparkConf().setMaster("local").setAppName("TopN");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.parallelize(Arrays.asList(2, 4, 1, 7, 1, 8, 9, 10));
rdd.mapToPair(t -> new Tuple2(t, 1))
.sortByKey(false)
.map(t -> t._1)
.take(3)
.forEach(System.out::println);
}
def topN(): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("TopN")
val sc = SparkContext.getOrCreate(conf)
sc.parallelize(Array(3, 1, 7, 3, 4, 9))
.map((_, 1))
.sortByKey(false)
.map(_._1)
.take(3)
.foreach(println)
}
分组TopN
对每个班级的成绩进行排序,取每个班级的前几名
public static void groupTopN() {
SparkConf conf = new SparkConf().setMaster("local").setAppName("GroupTopN");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.textFile(Thread.currentThread().getContextClassLoader().getResource("scores.txt").getPath(), 2)
.filter(line -> StringUtils.isNotBlank(line))
.mapToPair(line -> new Tuple2(line.split(" ")[0], Integer.parseInt(line.split(" ")[1])))
.groupByKey()
.map(t -> {
String className = t._1;
List scoreList = IteratorUtils.toList(t._2.iterator());
scoreList.sort((v1, v2) -> Integer.parseInt(v2.toString()) - Integer.parseInt(v1.toString()));
return new Tuple2>(className, scoreList.subList(0, 3));
})
.foreach(t -> System.out.println("班级:" + t._1 + " " + t._2));
}
def groupTopN(): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("GroupTopN")
val sc = SparkContext.getOrCreate(conf)
sc.textFile(Thread.currentThread().getContextClassLoader.getResource("scores.txt").getPath)
.filter(StringUtils.isNoneBlank(_))
.map(line => (line.split(" ")(0), Integer.parseInt(line.split(" ")(1))))
.groupByKey()
.map(t => (t._1, t._2.toList.sorted.reverse.take(3)))
.foreach(t => println(s"班级:${t._1} 分数:${t._2.toList}"))
}