论文:Blind Image Quality Assessment via Deep Learning
作者:Weilong Hou, Xinbo Gao, Dacheng Tao, Xuelong Li
发表时间:2015
名词解析:NSS、RBM、DBN
NSS:natural scene statistics(自然场景统计)。人类可以很容易地感知自然图像中的失真或伪影,因此推断必定有特殊的结构来区分非自然和自然。 这种结构被称为NSS。同时研究人员发现,小波域中的NSS可以分成三个等级的属性:1)主要;2)次要;3)第三属性。主要属性给出了自然图像的小波系数显著性的统计结构,如局部性和多分辨率;次要属性由由非高斯性和持续性组成;研究显示,当图像受到噪声或扭曲时这些属性会改变。
同时,这些属性随着不同类型的视觉内容或失真而不规则地变化,无法评估通用图像变性。但是第三属性显示出场景的自相似性,其中指数衰减跨度是最重要的属性。它反映了真实世界图像的小波系数的大小在整个范围内呈指数衰减。此外,指数衰减对特定图像内容的依赖较小,因此适用于构建通用无参考图像质量评价方法。根据前面的工作[,本文使用指数衰减特性作为图像表示。
RBM: restricted Boltzmann machine(受限制的玻尔兹曼机)。一种深度学习方法,其原理可参考:原理及过程;相关预备知识可查阅预备知识,作者: peghoty ,写的很详细。
DBN:deep belief net(深度信念网络)。由多层的RBM组成,作为一个概率生成模型,与传统的判别模型相对。
论文内容:该论文研究,通过从语言描述学习规则,进行图像视觉质量的无参考评价。其原理在于, 作者认为,从广泛的心理证据表明,人们更喜欢定性而不是定量地进行评估。然后将定性评估转换为数值分数作为客观的图像质量评估指标。当前通过分析从图像特征到感知质量分数的特定映射提出的基于学习的模型,因为在从语言描述到数值分数的这种不可逆转换中已经失去了一些信息,不够准确。因此作者希望直接从定性评价中学习。
方法难点:主要难点是如何从人类的非数字描述中学习规则,并输出后续处理算法的数值分数。
主要贡献:针对IQA的新分类框架。这个框架与原有的方法有概念上的不同。 首先合理性,该模型更自然;有效性和高效性:通用模型, 实验结果表明其预测与人类评价高度相关。在学习阶段之后,具有非常低的时间复杂度;鲁棒性:该模型对小样本量问题具有强鲁棒性。 借助基于分类的框架,新模型只需要一个相对较小规模的训练集就可以通过与最先进的方法进行比较来实现卓越的性能。全面性:借助新设计的质量汇总,该模型可以提供三级质量说明。即定性标签、特定人群的质量分布以及数值分数,这比基于回归的IQA方法更具信息性和全面性。
输入:输入图像由NSS特征表示
输出:数值分数,其中输入层12个节点,输出层5个节点,每个隐藏层50个节点。预测质量得分最终从质量合并阶段获得。
作者将盲评估重新定义为五级分类问题,对应于五种明确的心理概念,即 excellent, good, fair, poor, and bad(优秀,良好,一般,差和糟糕),以促进学习人类定性描述。对于输入的特征,图像首先被深度分类器(深层区分模型)以概率置信度分为上述5个等级。该深度分类器用DBN预训练,并通过反向传播微调而成。标签及其相应的概率置信度在质量汇集阶段转换为数值。
分类结果中的字符分别代表t excellent, good, fair, poor, bad。在上述框架中,使用四层判别式深层模型将图像表示分配给与五个形容词标签对应的五个等级。
第一层由NSS特征X填充。
第二层和第三层分别形成简单和复杂的混合特征。
L层是具有相应概率置信度P(L | X)的分类结果。
过程说明:
图像最初使用小波变换分解为三个尺度,每个尺度三个子带。因为低—高(LH)子带具有与高—低(HL)子带非常相似的统计特性,所以我们不区分相同规模的LH和HL子带。因此,总共使用六个子带来计算特征。每个子带的大小和熵计算如下:
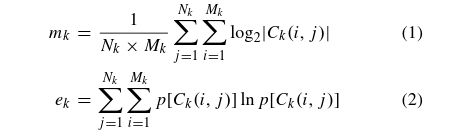
其中,N、M分别为第k个子带的长宽,C代表第k个子带(i,j)处的系数,p[.]代表概率密度函数。图像表示为六个子带组合成的单个向量。m代表了第k个子带的能量, e代表第k个子带的信息。
模型训练:阶段1:使用受限玻尔兹曼机(RBM)对两个相邻层进行参数预训练;阶段2:通过反向传播微调所有参数。
在第一阶段:DBN以无监督的贪婪逐层方式进行预训练。每层都初始化为限于一个可见层和一个隐藏层的RBM,概率分布如下:c和b分别是两层的偏差。
在第二阶段, 我们通过最大化条件分布P(L | X)来调整网络在分类之后,输入图像被分配给具有相应的概率置信度P(L | X)的五个等级。由于等级对应于包含固有语义信息的5个形容词,分类结果可直接用于定性描述图像质量。例如,对于给定的图像,如果P(L =优| | X)高于其他P(L | X),则该图像的质量可以被描述为优。
问题:形容词提供了一种描述图像质量的自然方式,与人类评估类似; 但是,它不能被其他应用程序使用,并且不能与现有的IQA方法相比较。
解决方案:为了解决这个问题,模型需要知道如何将标签与分数关联起来。在实践中,由于个人经验和背景,不同的人可能会对同一图像有不同的意见。因此,我们假设如下。
1.每张图片都具有内在质量Q
2.每个训练有素的人在评估具有相同内在质量的图像时都会给出恒定的标签
基于上述假设,对于一定的人,P(L | Q)是不变的。基于贝叶斯法则
其中P(Q)表示具有内在质量Q的图像的先验概率分布。给定输入图像表示X,内在质量的分布可以通过边缘分布表示
通过计算质量分布的均值,给出了图像质量的数值测量。为了获得先验概率P(Q)和P(L|Q)作者对LIVE II数据库进行了主观评估,9个受试者将图像分为5类,即优,良好,一般,差和糟糕。图像以随机顺序显示,并且每个受试者的随机化是不同的。受试者通过点击图形用户界面上的按钮来报告他们对质量的判断。例如,如果P(L =优秀| Q = 40)= 0.1,则意味着具有固有的图像40的质量可能有10%的机会被人口标记为优。
通过上述转换,作者再同其他的方法进行比较。除此之外,还设计了五组实验测试所提出方法的性能。
1.一致性实验用于验证客观评估的方式对应于人类评估。
2.可扩展性实验来验证所提出的方法是否可行适用于各种图像和失真,无需额外培训。
3.合理性试验证明了所提出的方法是合理的。
4.灵敏度实验以证明所提出方法的灵敏度。
5.复杂性实验测试了所提出的方法的计算效率。
实验结果验证了模型在小的训练集上有效性,有效性和鲁棒性,表明所提出的模型很好地符合人类评估。具体实验过程此次不太贴出,可查看原文。