这里整理下,pandas中数据加载的几个方法,前面,我们也有用过,read_csv,下面,我们整理下
1.pandas读取数据方法
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
我们可以看到这个参数非常多,基本上可以解决我们文件读取时的常见问题。
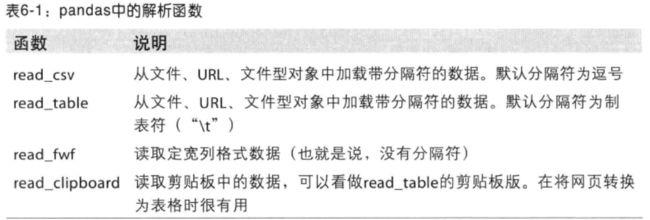
下面就是小例子
csv文件内容是这样的:数据以逗号分隔,没有其他特殊的情况

import pandas as pd
df = pd.read_csv(r'D:\document\python_demo\pydata-book-master\ch06\ex1.csv')
#使用read_table需要,手动指定下分隔符
#df = pd.read_table(r'D:\document\python_demo\pydata-book-master\ch06\ex1.csv',sep=',')
print(df)
print(df.index)
print(df.columns)
runfile('D:/document/python_demo/pandas_csv.py', wdir='D:/document/python_demo')
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
RangeIndex(start=0, stop=3, step=1)
Index(['a', 'b', 'c', 'd', 'message'], dtype='object')
我们可以看到,这里默认把第一行当做columns了,我们可以通过header=None,来自动指定标题
df = pd.read_csv(r'D:\document\python_demo\pydata-book-master\ch06\ex1.csv',header=None)
0 1 2 3 4
0 a b c d message
1 1 2 3 4 hello
2 5 6 7 8 world
3 9 10 11 12 foo
RangeIndex(start=0, stop=4, step=1)
Int64Index([0, 1, 2, 3, 4], dtype='int64')
#通过names,来自定义columns
df = pd.read_csv(r'D:\document\python_demo\pydata-book-master\ch06\ex1.csv',header=None,names=list('opqrxy'))
o p q r x y
0 a b c d message NaN
1 1 2 3 4 hello NaN
2 5 6 7 8 world NaN
3 9 10 11 12 foo NaN
RangeIndex(start=0, stop=4, step=1)
Index(['o', 'p', 'q', 'r', 'x', 'y'], dtype='object')
现在的行索引是自动初始化的,我们可以指定存在的列为索引
path = r'D:\document\python_demo\pydata-book-master\ch06\ex1.csv'
df = pd.read_csv(path,header=None,
names=list('opqrxy'),
index_col='x')
o p q r y
x
message a b c d NaN
hello 1 2 3 4 NaN
world 5 6 7 8 NaN
foo 9 10 11 12 NaN
Index(['message', 'hello', 'world', 'foo'], dtype='object', name='x')
Index(['o', 'p', 'q', 'r', 'y'], dtype='object')
比如,有这样一份数据,字段间是通过一个或多个空格来分隔的
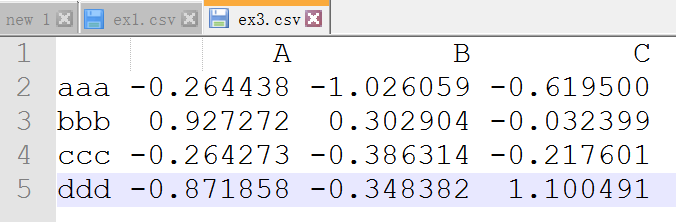
我们直接使用read_csv去读取,会发现,列索引有些不友好,我们可以使用正则表达式去分隔
df = pd.read_csv(path)
A B C
0 aaa -0.264438 -1.026059 -0.619500
1 bbb 0.927272 0.302904 -0.032399
2 ccc -0.264273 -0.386314 -0.217601
3 ddd -0.871858 -0.348382 1.100491
RangeIndex(start=0, stop=4, step=1)
Index([' A B C'], dtype='object')
#\s表示空格,+表示1个或多个,就是说分隔符是1个或多个空格
df = pd.read_table(path,sep='\s+')
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
Index(['aaa', 'bbb', 'ccc', 'ddd'], dtype='object')
Index(['A', 'B', 'C'], dtype='object')
还有很多其他常用的参数,比如skiprows,可以跳过指定行
下面,再说个填充缺失值的方法,na_values可以将其他我们指定的值也当成NaN处理
na_values : scalar, str, list-like, or dict, default None
Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘nan’`.
#原始数据是这样的,
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
#这里,我们将1,2,4也当成NaN值处理
df = pd.read_csv(path,na_values=[1,2,4])
#加载后,数据就会变成这样
something a b c d message
0 one NaN NaN 3.0 NaN NaN
1 two 5.0 6.0 NaN 8.0 world
2 three 9.0 10.0 11.0 12.0 foo
#我们还可以用一个dict来对不同的列指定NaN值
df = pd.read_csv(path,na_values={'something':['one','three'],'d':[8,12]})
something a b c d message
0 NaN 1 2 3.0 4.0 NaN
1 two 5 6 NaN NaN world
2 NaN 9 10 11.0 NaN foo
2.pandas导出数据
我们使用read_csv读取数据,处理完之后,我们可能还需要将数据存储起来,还有一个to_csv的函数
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=False, date_format=None, doublequote=True, escapechar=None, decimal='.')
##我们就使用这份数据,先读取后,再保存
something,a,b,c,d,message
one,1,2,3,4,NA
two,5,6,,8,world
three,9,10,11,12,foo
df.to_csv(sys.stdout,sep='^')
^something^a^b^c^d^message
0^one^1^2^3.0^4^
1^two^5^6^^8^world
2^three^9^10^11.0^12^foo
#我们看到这个输出,发现,NaN值,导出时,转为了空字符串,这里呢,我们可以手工指定
na_rep : string, default ‘’
df.to_csv(sys.stdout,sep='^',na_rep='NaN')
^something^a^b^c^d^message
0^one^1^2^3.0^4^NaN
1^two^5^6^NaN^8^world
2^three^9^10^11.0^12^foo
#有时候,行列标签可能也不需要,我们也可以禁用
df.to_csv(sys.stdout,sep='^',na_rep='NaN',index=False,header=False)
one^1^2^3.0^4^NaN
two^5^6^NaN^8^world
three^9^10^11.0^12^foo
3.附录
pandas中还有其他的加载数据方式,像读取HTML,JSON,xml等等,常用的可能还是和数据库取连接,这块后面会再补充,这里就先到这里。