看到一篇不错的大数据的学习路线。记录和分享~
一、大数据相关工作介绍
大数据方向的工作目前主要分为三个主要方向:
大数据工程师
数据分析师
大数据科学家
其他(数据挖掘等)
二、大数据工程师的技能要求
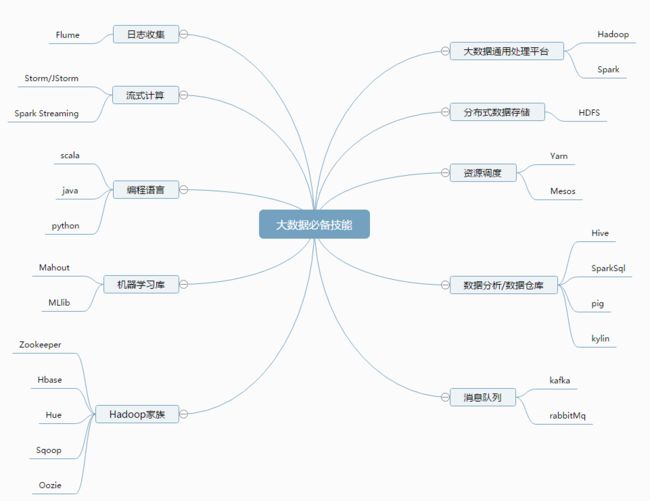
必须掌握的技能11条
Java高级(虚拟机、并发)
Linux 基本操作
Hadoop(HDFS+MapReduce+Yarn )
HBase(JavaAPI操作+Phoenix )
Hive(Hql基本操作和原理理解)
Kafka
Storm/JStorm
Scala
Python
Spark (Core+sparksql+Spark streaming )
辅助小工具(Sqoop/Flume/Oozie/Hue等)
高阶技能6条
机器学习算法以及mahout库加MLlib
R语言
Lambda 架构
Kappa架构
Kylin
Alluxio
第一阶段(基础阶段)
1)Linux学习(跟鸟哥学就ok了)—–20小时
Linux操作系统介绍与安装。
Linux常用命令。
Linux常用软件安装。
Linux网络。
防火墙。
Shell编程等。
官网:https://www.centos.org/download/
中文社区:http://www.linuxidc.com/Linux/2017-09/146919.htm
2)Java 高级学习(《深入理解Java虚拟机》、《Java高并发实战》)—30小时
掌握多线程。
掌握并发包下的队列。
了解JMS。
掌握JVM技术。
掌握反射和动态代理。
官网:https://www.java.com/zh_CN/
中文社区:http://www.java-cn.com/index.html
3)Zookeeper学习(可以参照这篇博客进行学习:http://www.cnblogs.com/wuxl360/p/5817471.html)
Zookeeper分布式协调服务介绍。
Zookeeper集群的安装部署。
Zookeeper数据结构、命令。
Zookeeper的原理以及选举机制。
官网:http://zookeeper.apache.org/
中文社区:http://www.aboutyun.com/forum-149-1.html
第二阶段(攻坚阶段)
4)Hadoop (《Hadoop 权威指南》)—80小时
HDFS
HDFS的概念和特性。
HDFS的shell操作。
HDFS的工作机制。
HDFS的Java应用开发。
MapReduce
运行WordCount示例程序。
了解MapReduce内部的运行机制。
MapReduce程序运行流程解析。
MapTask并发数的决定机制。
MapReduce中的combiner组件应用。
MapReduce中的序列化框架及应用。
MapReduce中的排序。
MapReduce中的自定义分区实现。
MapReduce的shuffle机制。
MapReduce利用数据压缩进行优化。
MapReduce程序与YARN之间的关系。
MapReduce参数优化。
MapReduce的Java应用开发
官网:http://hadoop.apache.org/
中文文档:http://hadoop.apache.org/docs/r1.0.4/cn/
中文社区:http://www.aboutyun.com/forum-143-1.html
5)Hive(《Hive开发指南》)–20小时
Hive 基本概念
Hive 应用场景。
Hive 与hadoop的关系。
Hive 与传统数据库对比。
Hive 的数据存储机制。
Hive 基本操作
Hive 中的DDL操作。
在Hive 中如何实现高效的JOIN查询。
Hive 的内置函数应用。
Hive shell的高级使用方式。
Hive 常用参数配置。
Hive 自定义函数和Transform的使用技巧。
Hive UDF/UDAF开发实例。
Hive 执行过程分析及优化策略
官网:https://hive.apache.org/
中文入门文档:http://www.aboutyun.com/thread-11873-1-1.html
中文社区:http://www.aboutyun.com/thread-7598-1-1.html
6)HBase(《HBase权威指南》)—20小时
hbase简介。
habse安装。
hbase数据模型。
hbase命令。
hbase开发。
hbase原理。
官网:http://hbase.apache.org/
中文文档:http://abloz.com/hbase/book.html
中文社区:http://www.aboutyun.com/forum-142-1.html
7)Scala(《快学Scala》)–20小时
Scala概述。
Scala编译器安装。
Scala基础。
数组、映射、元组、集合。
类、对象、继承、特质。
模式匹配和样例类。
了解Scala Actor并发编程。
理解Akka。
理解Scala高阶函数。
理解Scala隐式转换。
官网:http://www.scala-lang.org/
初级中文教程:http://www.runoob.com/scala/scala-tutorial.html
8)Spark (《Spark 权威指南》)—60小时
1.Spark core

Spark概述。
Spark集群安装。
执行第一个Spark案例程序(求PI)。
2.RDD
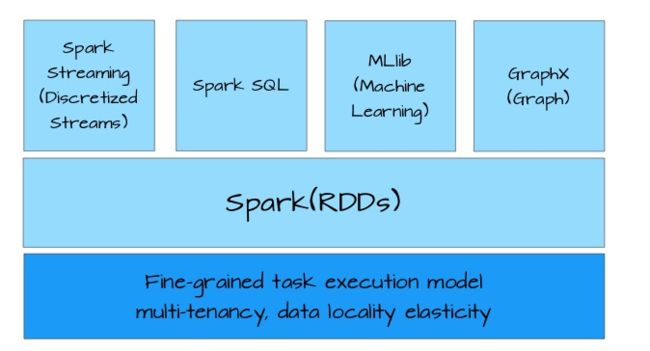
RDD概述。
创建RDD。
RDD编程API(Transformation 和 Action Operations)。
RDD的依赖关系
RDD的缓存
DAG(有向无环图)
3.Spark SQL and DataFrame/DataSet
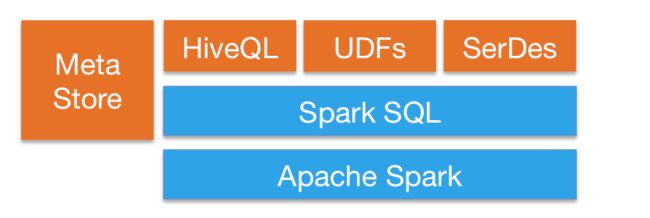
Spark SQL概述。
DataFrames。
DataFrame常用操作。
编写Spark SQL查询程序。
4.Spark Streaming

spark Streaming概述。
理解DStream。
DStream相关操作(Transformations 和 Output Operations)。
5.Structured Streaming
6.其他(MLlib and GraphX )
这个部分一般工作中如果不是数据挖掘,机器学习一般用不到,可以等到需要用到的时候再深入学习。
官网:http://spark.apache.org
中文文档(但是版本有点老):https://www.gitbook.com/book/aiyanbo/spark-programming-guide-zh-cn/details
中文社区:http://www.aboutyun.com/forum-146-1.html
9)Python (推荐廖雪峰的博客)
博客网站: https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
第三阶段(辅助工具工学习阶段)
11)Sqoop(CSDN,51CTO ,以及官网)
数据导出概念介绍
Sqoop基础知识
Sqoop原理及配置说明
Sqoop数据导入实战
Sqoop数据导出实战、
Sqoop批量作业操作
推荐学习博客:http://student-lp.iteye.com/blog/2157983
官网:http://sqoop.apache.org/
12)Flume(CSDN,51CTO ,以及官网)
FLUME日志采集框架介绍。
FLUME工作机制。
FLUME核心组件。
FLUME参数配置说明。
FLUME采集nginx日志案例(案例一定要实践一下)
推荐学习博客:http://www.aboutyun.com/thread-8917-1-1.html
官网:http://flume.apache.org
13)Oozie(CSDN,51CTO ,以及官网)–20小时
任务调度系统概念介绍。
常用任务调度工具比较。
Oozie介绍。
Oozie核心概念。
Oozie的配置说明。
Oozie实现mapreduce/hive等任务调度实战案例。
推荐学习博客:http://www.infoq.com/cn/articles/introductionOozie
官网:http://oozie.apache.org/
14)Hue(CSDN,51CTO ,以及官网)
推荐学习博客:http://ju.outofmemory.cn/entry/105162
官网:http://gethue.com/
第四阶段(不断学习阶段)
每天都会有新的东西出现,需要关注最新技术动态,不断学习。任何一般技术都是先学习理论,然后在实践中不断完善理论的过程。
备注
1)如果你觉得自己看书效率太慢,你可以网上搜集一些课程,跟着课程走也OK 。如果看书效率不高就很网课,相反的话就自己看书。
2)企业目前更倾向于使用Spark进行微批处理,Storm只有在对时效性要求极高的情况下,才会使用,所以可以做了解。重点学习Spark Streaming。
3)快速学习的能力、解决问题的能力、沟通能力**真的很重要。
4)要善于使用StackOverFlow和Google(遇到解决不了的问题,先Google,如果Google找不到解决方能就去StackOverFlow提问,一般印度三哥都会在2小时内回答你的问题)。
5)视频课程推荐:
可以去万能的淘宝购买一些视频课程,你输入“大数据视频课程”,会出现很多,多购买几份(100块以内可以搞定),然后选择一个适合自己的。个人认为小象学院的董西成和陈超的课程含金量会比较高。
四、持续学习资源推荐
Apache 官网(http://apache.org/)
Stackoverflow(https://stackoverflow.com/)
Github(https://github.com/)
Cloudra官网(https://www.cloudera.com/)
Databrick官网(https://databricks.com/)
About 云 :http://www.aboutyun.com/
CSDN,51CTO (http://www.csdn.net/,http://www.51cto.com/)
至于书籍当当一搜会有很多,其实内容都差不多。
五、项目案例分析
1)点击流日志项目分析(此处借鉴CSDN博主的文章,由于没有授权,所以就没有贴过来,下面附上链接)—-批处理
http://blog.csdn.net/u014033218/article/details/76847263
2)Spark Streaming在京东的项目实战(京东的实战案例值得好好研究一下,由于没有授权,所以就没有贴过来,下面附上链接)—实时处理
http://download.csdn.net/download/csdndataid_123/8079233
最后但却很重要一点:每天都会有新的技术出现,要多关注技术动向,持续学习。
原文地址:https://blog.csdn.net/gitchat/article/details/78341484