论文:An Adversarial Approach to Hard Triplet Generation
1. Triplet Loss
ReID问题中都是根据图像embedding之间的特征距离来判断相似度,但是平常训练都是根据训练集的ID做监督,用softmax进行分类。而Triplet loss能够直接对图像的特征进行监督,更有利于学到好的embedding。
- 从一个minibatch中获取一个三元组
- a: anchor
- p: positive, 与 a 是同一类别的样本
- n: negative, 与 a 是不同类别的样本
损失函数:
hard triplets指的是找到minibatch中最大的一对三元组,即找到最大的和最小的。
但是这样直接的方式不一定能找出具有代表性的三元组,会对网络的收敛(convergence)造成问题。
2. Related Works
三元组损失函数对于三元组的选择非常敏感,经常会有难以收敛和局部最优的问题,为此[1]提出了Coupled Cluster Loss,使得训练阶段更加稳定,网络收敛的更加快。
3. Hard Triplet Generation
现有的mining方法都是基于已存在的sample,本文提出了一种新的方法如下图1。
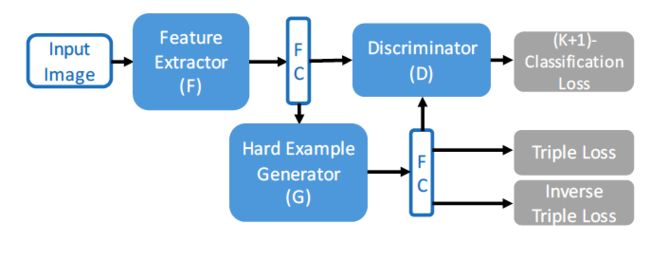
特征提取网络的输出,对于三元组 ,传统方法的损失函数是:,其中是距离。
3.1Adversarial Triplet Generator G
给出一个生成器,通过这个生成器生成一个新的sample,的目的是使得正样本之间距离增大,负样本之间距离减小,目的是为了生成更harder的sample.
通过降低以下loss来训练:
随后固定学习过的,接着训练:
3.2 Multi-category Discriminator D
但是光靠上面的方法并不够有效,因为没有限制的情况下,会任意操纵(arbitrarily manipulate)生成的特征向量。打个比方说,可能随意输出一个向量,使得非常小,但是这个对于训练来说没有意义。为了限制,需要他输出的向量不改变原本向量的标签。
给出一个判别器,对于每个特征向量,能将其分成(K+1)类,K表示真实存在的类别,+1代表fake类别。通过降低以下loss来训练:
其中前半部分让分辨生成的特征向量的标签
表示softmax loss,后半部分让分辨生成的特征向量。
表示fake类别。
之前提到应该保留住输入的特征向量的标签。因此文章中提出下面的loss:
与之前的公式(2)结合,通过降低以下loss来训练:
3.3 Summary
- 网络通过结合公式triplet(3)和classification(5)训练:
其中classification(5)确保了能够正确分类
- 公式(4)训练判别器(D)
- 公式(8)训练生成器(G)
4 Algorithm Details
首先,basic model同时降低softmax loss和triplet loss。随后被加入到basic model。
4.1 Basic Model
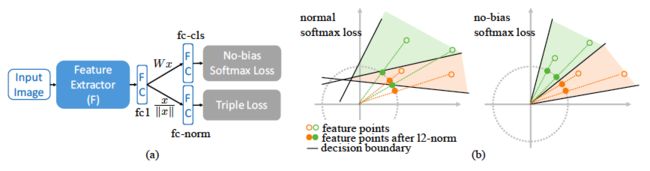
图三所示的是basic模型。输出的特征层后是一个全连接层(softmax loss)和一个规范化(simmilarity loss)层。
softmax 和similarity loss在之前的研究中有被结合起来,但是他们之间的关系并没有被深入的进行研究。
在特征向量空间(feature embedding space)中,所有相同类别的数据坐标经过规范化后应该是在一个单位超球面(unit hyper sphere)上,图2中的decision boundary将不同类别的数据分成K个类别,这种结构能加速收敛并达到理想化(optimal)的结果。但是传统的softmax loss不能很好兼容基于特征距离(distance-based)的similarity loss。如图3(b)中。由于偏置b的存在,decision boundary不能够通过原点,因此在规范化后,不同类别的点可能会重合。这将导致类间距离(inter-class)的缩小,影响特征向量的效果。因此文章中提出了一个没有偏执b的softmax loss。如图3(b)所示,这种无偏置softmax损失的所有决策边界都通过原点,并且决策区域是锥形的,其顶点位于原点。因此,同一类的样本在单位超球面上具有单独的投影,这确保了来自不同类别的示例之间的长的类间距离(inter-class)。
给定一个训练三元组其中为anchor图片的类别。无偏置的softmax定义为:
其中表示CNN网络的输出特征向量。随后网络通过缩小来训练(SGD)。
4.2 Adversarial Training
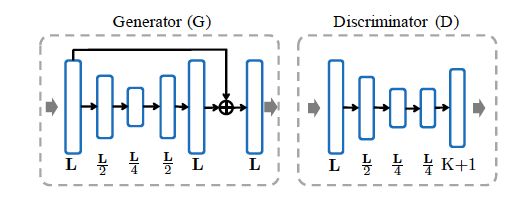
在basic model中,通过随机选取triplets来训练,现在我们打算在特征层面训练一个triplet生成器。
图4左边部分所示,的输入是L维的特征向量,这个向量是网络的输出,同时的输出具有相同的维度。包含4个全连接层,前两个降维,后两个升维,每一层后面跟了BatchNormalization和ReLU。最后的输出是输入向量和输出向量的对应位置相加。
另外,判别器接受产生的L维特征向量,并将其分成K+1类。也有4个全连接层,前三个后面跟了BatchNormalization和ReLU,最后一个跟的softmax。(怎么感觉接受的是应该是产生的?)
文章中使用的优化器是SGD,学习率,步骤在Section 3中介绍。
- 训练特征提取网络:
- 训练判别网络:
- 训练生成网络: 目的是为了生成更难判断的triplets,同时也会受到限制。
4.3 Harder Triplet Generation from Local Details
此外,文章中尝试构建一个更强大的提取器,允许HTG从细粒度的局部细节创建更hard三元组,因此视觉识别模型可以用更难的三元组示例挑战变得更加鲁棒。
实际上,局部特征在许多细粒度的视觉识别任务中起着关键作用。用于图像分类的典型深度神经网络擅长提取高级全局特征,但常常缺少局部细节的特征。这可能会限制HTG探索本地细节以创建更难的triplets。例如,在没有本地细节的情况下,HTG无法生成能够识别不同车辆的大多数有辨别力的部分的三元组,例如徽标,灯光和天窗。
为了解决这个问题,文章中介绍了一种更加关注局部特征的关键点图。例如ResNet-18包含了4个连续的卷积块,在最后一个卷积块后面跟着一个全连接层作为全局特征.对于卷积块来说,他的输出特征图可以表示为.随后我们加一个局部分支叫做keypoint bolck,它具有类似于卷积块的结构,用于本地化关键点的分布,这些关键点可以关注最具辨别力的部分以创建更难的三元组。高级语义特征映射是稀疏的(不太明白这里),我们假设关键点层的每个通道对应于特定类型的关键点,因此我们在关键点层的输出特征上应用通道层面(channel-wise)softmax来估计不同图像位置上关键点的密度:
是clock-l的输出特征图在通道c及位置(i,j)上的的点。
block-l局部特征:
文章中提取了bolck-3和block-4的特征,和全剧特征concat后作为最后的输出特征。
备注:这部分没有看的很明白,我理解的大概意思是在网络的中间层先做一个softmax,最后和全局特征的softmax concat起来。