一. PHP数组特点介绍
php数组可谓是php的核心,其key=>value的存储结构,让我们处理数据可以游刃有余,并且在一般情况下增删查改都是O(1)的时间复杂度,并表现出一些特点让我们对其内部的结构充满了好奇。
「数组内存申请不需要自己控制」:数组的内存申请和释放是内部控制的,不需要人为的去干预。
「兼容关联数组和索引数组」:数组可以以数字为下标进行操作,也可以以字符串为下标进行操作,其实他俩本质上都是key=>value的格式。
「可以无key值存储」:像a[] = 10; 这样去存储一个value值,事实上他也是有key值的。
「不会出现数组越界的问题」:不会像我们操作C/C++等语言一样,要注意数组的边界,一定不能正向或者逆向越界。在php中不会有这些问题的存在。
「value值无严格的定义和统一」:这里就是php内部自己实现了一个范型。
「foreach遍历数组与插入顺序有关」:插入顺序和遍历输出一致。
二. PHP数组结构的演变
这个地方主要讲PHP5.6=>PHP7.0=>PHP7.1的演变过程

我们可以看到,数组本质就是一个hashtable结构,左侧的0~nTablemask便是hash下标,而后面有一个双向链表,便是我们通常所说的hash冲突的链地址法。
而绿色的双向链表,则是foreach遍历用的,这个地方用双向链表,主要是为了逆序访问来用的,遍历的时候,就是从pListHead开始不断的next便可以遍历所有的元素。这样要比下标遍历hashtable快得多。
但是这个结构有很明显的缺点:
①. 每次插入/删除元素都要申请/释放内存,这样会严重的导致内存碎片化,降低内存的使用率。
②. 再者,每次插入元素的时候都要去申请内存,会有一次寻址的过程,时间效率低。
③. 指针结构很复杂,有大量的指针操作。

针对上面5.6所有的问题,提出了如上的结构。arData结构便是我们插入数据的结构,是一段连续的内存,在初始化/数组扩充时一次性内存申请好,这样内存便不会产生碎片化问题,并且我们看,hash冲突的时候是单链表,并且没有插入元素时候的双向链表,因为我们可以直接扫描数组便可以顺序/逆序访问插入的数据。
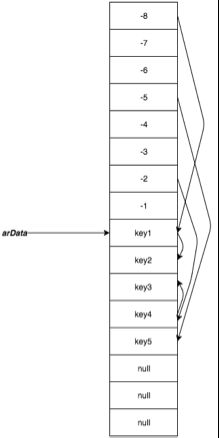
如上是最新的数据结构,最主要的区别是把7.0的两段内存转化为一段内存,算是在内存上的继续优化。他的内存申请是从下标-8位置申请的,然后移动指针到key1位置。
三. PHP7.0数组源码实现
3.1 PHP7.0数组的主要数据结构

Bucket结构便是我们所说的保存插入数据的结构。主要包括:key(字符串,如果是数字下标,转化位字符串), value, h(只会计算一次,如果是数组下标,直接把key作为h)。

这便是PHP7.0的数组结构,我后面讲全部是用7.0结构讲,比较清晰。nNextFreeElement是无key值存储时使用的数据,用来分配key值。
3.2 PHP数组的hash方法
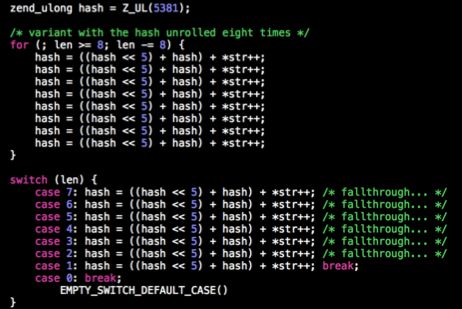
如上是php的hash源码,看一眼容易把人瞎蒙,然而把它简化一下便是:
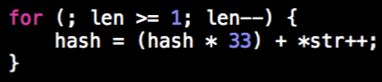
简单讲一下。其中源码中把 hash*33 转化为 (hash<<5) + hash
在一个就是,使用了循环展开策略,减少不必要的循环判断,在一个是连续的执行相同的指令,提高指令的cache命中率。可以看着:https://en.wikipedia.org/wiki/Loop_unrolling
那么计算出hash值来之后,并不是我们想要的下标,因为很有可能超过了hashmask值,所以需要一步计算来得到index。
•7.0:
hashmask = tablesize – 1; //tablesize一定是2的指数倍,和申请内存有关系,后面讲
h = hashcode & hashmask; //计算index
hashmask=7(10)=111(2) //十进制下的7转为二进制下的111
0<=h<8 //所有值 & hashmask 一定在0~7之间
•7.1:
hashmask = -tablesize;
h = hashcode | hashmask;
hashmask=-8(10)=11111000(2补码)
-8<=h<=-1
7.1的结构因为是hash负下标,所以用的另一种计算策略,大同小异。
3.3 PHP数组插入数据
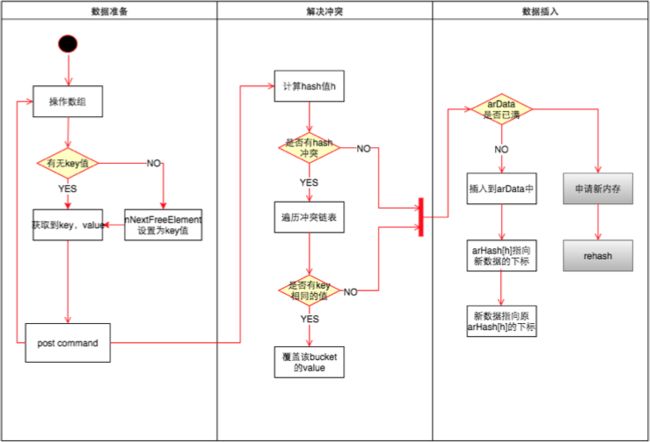
大致流程如上,看一下就好。讲一下插入数据的结构变化。

在我们插入key6这个key值之后,在arData数据往后排,我们假设他与key1的hash冲突,所以使用链地址法,直接插入到链表首部。
3.4 PHP数组删除数据
在上面的结构,假如我们删除key1,会有两种考虑。
①. 删除该元素之后,我们是否要保证空间的利用率,把后面的数据移动,覆盖当前位置。
②. 删除元素之后,直接把该位置空出。
其实第一种策略是不可接受,因为这样会导致时间复杂度退化为O(n),而第二种策略,我们控制当前位置之后,我们可以在内存扩充时,把这些空位置给删除掉即可。

3.4 PHP数组内存申请及rehash
假设我们要在如下结构中插入key9

发现当前arData已经满了,所以我们申请新内存(初始大小位2,以2的倍数不断扩充),把所有数据以内存的形式copy过去,然后扫描数组,把无用的数据给删除掉(用移动后面元素的策略)。因为nTableMask数值改变了然后进行rehash。
这里有一个点值得提一下:把原数据copy过去的时候,我们可以选择遍历原先的数组,把有用的数据copy过去,也可以先把原内存的数据复制到新内存的位置,然后去遍历数组去移动数据。PHP实现选择了第二种,这样考虑应该是我们删除元素的次数比较少,直接以内存的形式copy数据要比遍历copy的速度快,在权衡之下选择了第二种。
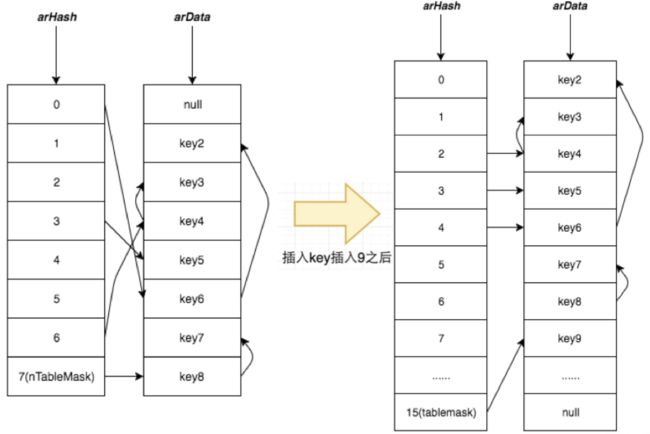
结构变化如上图。
四. PHP数组的可优化点
4.1 PHP数组的退化案例
本案例参考的鸟哥的博客。

大概测了一下

我们可以看到,时间效率差别很大。我们来分析一下为什么会这样。
•插入元素:key=0,1*65536,2*65536,….,65535*65536
•插入元素特点:h=key&65535=0,生成绝对的hash冲突导致退化1*****00000000&0****011111111=0
•大致的插入计算次数:1+2+3+4+5+…+65536(每次插入都会冲突,从而会去查询是否有相同的key值,所以会有扫描的次数总和如此)
•导致插入元素时间复杂度退化为O(n*(1+n)/2)=O(n^2)
那么65536^2在计算机1s处理10^8运算的情况下,大概36s以上,所以运行结果算是可预期的。

4.2 可进行优化的策略
我们参考Java中hashtable的实现来使用红黑树解决这个问题。
•①.设定链表冲突长度的阀值
•②.当链表长度超过阀值的时候,以key值为键值进行红黑树的转化,key全是字符串,所以我们可以以key的字典序进行排序
•③.Hashtable的指针指向树根
•④.增删查改,不断对红黑树结构进行调整
•⑤.使增删查改时间复杂度达到最差为O(logn)
我们来看下结构的变化为:

如果不了解红黑树,可以去参考一下《算法导论》中的详解
五. PHP数组的总结
「数组内存申请不需自己控制」
hashtable内存大小与arData大小相同,并且一定为2的指数倍不断扩展
「兼容关联数组和索引数组」
索引是hash值同时也是key值,转化为关联数组,关联数组用hashtable实现
「可以无索引(key值)存储」
无索引存储时,会自动为其分配最后一个没有被使用过的下标来作为key和hash值进行存储
「不会出现数组越界的情况」
索引即hash值,用无符号长整形存储,不会出现负向越界
索引的大小与内存的大小没有绝对的关系,不会出现正向越界
「value值无严格的定义或统一」
php对value值进行了范型处理
「foreach遍历数组与插入顺序有关」
foreach是对arData遍历,而arData是顺序存储的
用foreach比用for进行下标访问永远要快