本人从事音频软件开发10+年,既开发过voice相关的,又开发过music相关的,但大多数还是开发voice相关的。掐指一算到现在在通信终端上开发过的语音解决方案共有五套,它们既有有线通信的,又有无线通信的;既有在上层开发的,又有在底层开发的;既有在ARM上开发的,又有在DSP上开发的,总之各有特色。但因为都是语音通信解决方案,又有共同的地方,都要有语音的采集播放、编解码、前后处理和传输等。今天我就选取有代表性的三套方案,讲讲它们的实现。
1,在嵌入式Linux上开发的有线通信语音解决方案
这方案是在嵌入式Linux上开发的,音频方案基于ALSA,语音通信相关的都是在user space 做,算是一个上层的解决方案。由于是有线通信,网络环境相对无线通信而言不是特别恶劣,用的丢包补偿措施也不是很多,主要有PLC、RFC2198等。我在前面的文章(如何在嵌入式Linux上开发一个语音通信解决方案)详细描述过方案是怎么做的,有兴趣的可以去看看。
2,在Android手机上开发的传统无线通信语音解决方案
这方案是在Android手机上开发的,是手机上的传统语音通信方案(相对于APP语音通信而言)。Android是基于Linux的,所以也会用到ALSA,但是主要是做控制用,如对codec芯片的配置等。跟音频数据相关的驱动、编解码、前后处理等在Audio DSP上开发,网络侧相关的在CP(通信处理器)上开发,算是一个底层解决方案。该方案的软件框图如下:
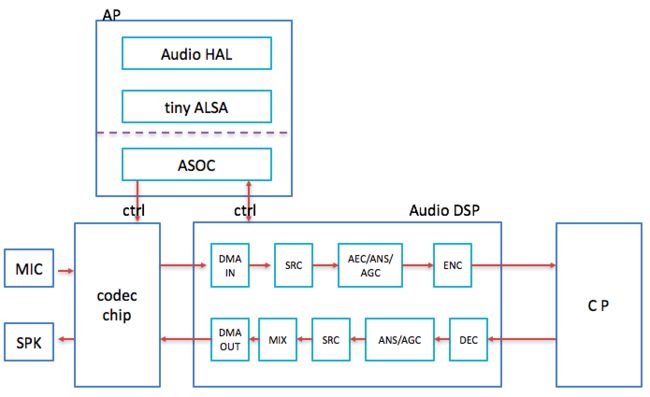
从上图看出,AP在方案中起控制作用,一是控制codec芯片上音频路径的选择(通过配置寄存器完成),二是控制Audio DSP上音频流的start/stop等。真正的音频数据处理是在Audio DSP和CP上实现的(Audio DSP和CP上的实现在两个不同的部门做,我是在Audio DSP上做音频开发,对CP上的实现只是了解,不能详细叙述CP上的Audio实现)。语音通信分上行和下行,先看上行。通过codec芯片采集到的语音数据由I2S送给Audio DSP。Audio DSP中有DMA IN中断,5ms发生一次,获取语音数据,然后做重采样(方案中codec芯片的采样率是48k Hz,而编解码codec的采样率是8k/16k等,需要做重采样)变成8k/16k等的语音数据并保存在buffer中。发生四次就获得了20ms的语音数据(基于20ms是因为AMR/EVS的一帧都是20ms),把这20ms数据先做前处理(AEC/ANS/AGC等),再做编码获得码流,并把码流通过IPC送给CP。CP中做些网络侧相关的处理最后通过空口发送给对方。再看下行。CP从空口收到语音数据后做网络侧处理(jitter buffer等)后将码流发给Audio DSP。Audio DSP收到码流后先解码成PCM数据并做后处理(ANS/AGC等),然后做重采样变成48k Hz的语音数据,还要做混音处理(主要是系统音,要一起播放出来),处理完后放在buffer里。下行也有一个DMA OUT中断,也是5ms一次,把一帧20ms的数据分四次送给codec芯片,也就是每次从上述buffer里取5ms数据,取四次buffer就取空了,然后再取下一帧的数据播放。送给codec芯片的数据就会通过外设播放出来。
由于在DSP上开发,硬件资源(DSP 频率/memory)成了瓶颈,好多时间花在load/memory的优化上。DSP频率只有300多MHZ,上下行的前后处理、编解码、重采样又是比较耗load的,不优化根本不能流畅运行,在C级别优化后一些场景还是不能流畅运行,最后好多地方用了终极大法汇编优化,才使各种场景下都能流畅运行。Memory分内部memory (DTCM(Data Tightly Coupled Memory, 数据紧密耦合存储器,用于存data)和PTCM(Program Tightly Coupled Memory, 程序紧密耦合存储器,用于存code))和外部memory(DDR)。要想快速运行,data和code最好都放在内部memory,但是内部memory的空间又特别小,DTCM和PTCM都只有几十K Word(DSP上的基本单位是Word,一个Word是两个字节),memory不仅不能随意用,在写代码时时时刻刻都要注意省内存,还要优化(经常遇到的是开发新feature,memory不够了,先优化memory,然后再开发,memory都是一点一点抠出来的),最后优化也抠不出memory了,怎么办呢?用了overlay机制,说白了就是在不同场景下的memory复用。比如播放音乐和打电话不可能同时出现,使用的部分memory就可以复用。再比如打电话时只有一种codec在工作,而系统会同时支持多种codec,这几种codec的使用的部分memory就可以复用。
3,在Android手机上开发的APP上的语音解决方案
这方案也是在Android手机上开发的,但是是APP语音通信,类似于微信语音,在Native层做,调用Android JNI提供的API,算是一个上层解决方案。该方案的软件框图如下:

本方案是在AP(应用处理器)上实现,语音采集和播放并没有直接调用系统提供的API(AudioTrack/AudioRecorder), 而是用了开源库openSL ES,让openSL ES去调用系统的API。我们会向openSL ES注册两个callback函数(一个用于采集语音,一个用于播放语音),这两个callback每隔20Ms被调用一次,分别获得采集到的语音以及把收到的语音送给底层播放,从底层拿到的以及送给底层的语音数据都是PCM格式,都配置成16k采样率单声道的模式。在上行方向,codec芯片采集到的语音PCM数据通过I2S送给audio DSP,audio DSP处理后把PCM数据送给AP,最终通过注册的采集callback函数把PCM数据送给上层。在上层先做前处理,包括AEC/AGC/ANS等,用的是webRTC的实现(现在APP语音内的前后处理基本上用的都是webRTC的实现),做完前处理后还要根据codec看是否需要做重采样,如codec是8k采样率的,就需要做重采样(16k转到8k), 如codec是16k采样率的,就不需要做重采样了。再之后是编码得到码流,同时用RTP打包,并用UDP socket把RTP包发给对方。在下行方向,先用UDP socket收语音RTP包,去包头得到码流放进jitter buffer中。每隔20Ms会从jitter buffer中拿一帧数据解码得到PCM,有可能还要做PLC和重采样,然后再做后处理(ANS/AGC),最终通过播放callback函数把PCM数据一层层往下送给Audio DSP,audio DSP处理后把PCM数据送给codec芯片播放出来。APP上的语音通信属于OTT (On The Top)语音,不像传统语音通信那样有QoS保障,要保证语音质量,必须要采取更多的补偿措施(由于无线网络环境是变化多端的,经常会比较恶劣,会导致乱序丢包等),常见的方法有FEC(前向纠错)、重传、PLC(丢包补偿)等。补偿措施是该方案的难点,通过补偿把语音质量提高了,但是增大了时延和增加了流量。
方案的实现是上图中灰色虚线上面的部分,我之所以画出灰色虚线下面部分,是想给大家看看整个完整的语音数据流向的实现,下面的部分对APP开发人员来说是黑盒子,他们可见的就是系统提供的API。我先是做APP上的语音通信,后来才做手机上的传统语音通信。做APP上的语音通信时不清楚底层是怎么实现的,很想知道,但是没有资料可供了解。我想很多做APP语音的人跟我有一样的困惑,底层实现到底是什么样的。后来做了手机上传统语音通信的实现,清楚了底层是怎么做的,算是把APP语音的整个数据流向搞清楚了。本文把底层实现框图也画出来,就是想让做APP语音通信的人也了解底层的实现。不同手机平台上的针对APP语音的底层实现是不一样的(主要是指DSP上的实现,Android Audio Framework上的实现基本是一样的),比如有的有前后处理(通常是中高端机),有的没有前后处理(通常是低端机)。中高端机在上层不做回声消除也没有回声,那是因为在底层做掉了。同样的回声消除算法在越接近硬件处做效果越好,主要是因为近远端之间的latency越靠近硬件算的越准确不变,latency准确不变回声消除才会有更好的性能。在上层算latency就会引入软件带来的时延,而且软件引入的时延有可能是变化的,这就导致在上层算latency不如底层精确。在APP上层做回声消除时,机型不一样,latency也就不同(硬件不同以及底层软件实现不同),当时是一个机型一个机型测出来的,有一百多毫秒的,也有两百多毫秒的,差异很大。至于怎么测的,有兴趣可以看我前面写的一篇文章(音频处理之回声消除及调试经验)。在底层DSP上做回声消除时,算是最靠近硬件了,我当时算DMA OUT和DMA IN之间的delay,只有五点几毫秒,而且多次测latency都是很稳定,误差不超过几个采样点,这样就保证了回声消除的高性能。当时测时在硬件上把speaker和MIC的线连起来,形成一个loopback,DMA OUT的数据就完全进入DMA IN,用特殊波形(比如正弦波)穿越,同时把DMA OUT和DMA IN的音频数据dump出来用CoolEdit看,从而得到latency的准确值。低端机在上层是一定要做回声消除的,那是因为底层没做。APP语音通信解决方案要兼顾所有机型,所以在APP语音解决方案内回声消除是一定要有的,当然还包括其他的前后处理模块,比如ANS、AGC。
以上方案就是我做过的三种典型的语音通信方案,有有线通信,有无线通信,也有APP语音通信,在我看来应该是把目前通信终端上的主要语音解决方案都囊括了。由于在不同的平台上开发,在不同的层次开发,从而表现出巨大的差异性,但是语音通信的核心模块都是一样的。