此作业的要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
我的代码源地址:https://e.coding.net/xulijun/xulijun11.git
词频统计 SPEC 20180918
1.功能1
小文件输入。通过程序统计文件中单词的总量total,并统计各个单词出现的频率,total一项中相同的单词不重复计数数,出现两次的单词记为1次。
1.1 重点难点:
(1)题目要求用控制台输入命令行参数,python代码不能直接在控制台运行,所以我查阅资料,了解到python的命令行参数是用sys.argv[]获取的。
(2)统计单词词频我使用了re.findall()方法通过正则表达式生成列表,然后用collections.counter()统计单词数量。
代码如下
f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) def count(words): collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1]))
1.2 效果展示

2.功能2
支持命令行输入英文作品的文件名,请老五亲自录入。
2.1 重点难点
功能二要求输入的文件名不带txt后缀,我通过查阅资料,利用参数sys.argv[1]是否等于‘-s’来判断执行功能一还是功能二。
代码如下
def main(argv): if sys.argv[1] == '-s': if (len(sys.argv) == 3): doCount(sys.argv[2]) else: redicertText = sys.stdin.read() doCountByPurText(redicertText) elif os.path.isdir(sys.argv[1]): fileFindAndCount(sys.argv[1]) else: doCount(sys.argv[1]) def doCount(accept): s = '.txt' if s in accept: path = accept else: path = accept + '.txt' f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) count(words)
2.2 效果展示
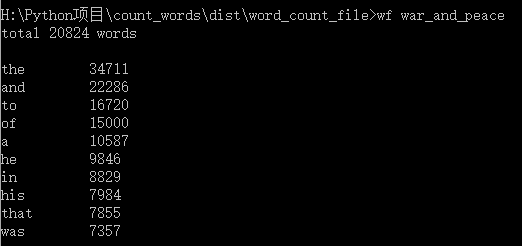
3.功能3
支持命令行输入存储有英文作品文件的目录名,批量统计。
3.1 重点难点
如何判断输入的路径是一个文件夹,可以用os.path.isdir()方法,用os.listdir()方法遍历文件夹。
代码如下:
def fileFindAndCount(path1): files = os.listdir(path1) for file in files: if os.path.isfile(file): doSomeFileCount(file)
3.2 效果展示

4.功能4
从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
4.1 重点难点
百度和请教了学长重定向的内容,了解了基本概念,但未能编译成功,我会努力把这个功能编写完善。
PSP表格
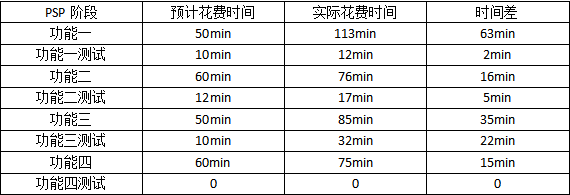
总结:刚开始第一个功能,由于查阅资料,时间较长由于能力和时间有限第四个功能没有编译成功,即使作业截止我也打算努力把他写出来。