之前的文章中,我们有介绍过动态数组ArrayList,双向队列LinkedList,键值对集合HashMap,树集TreeMap。他们都各自有各自的优点,ArrayList动态扩容,数组实现查询非常快但要求连续内存空间,双向队列LinkedList不需要像ArrayList一样创建连续的内存空间,它以链表的形式连接各个节点,但是查询搜索效率极低。HashMap存放键值对,内部使用数组加链表实现,检索快但是由于键是按照Hash值存储的,所以无序,在某些情况下不合适。TreeMap使用优化了的排序二叉树(红黑树)作为逻辑实现,物理实现使用一个静态内部类Entry代表一个树节点,这是一个完全有序的结构,但是每个树节点都需要保存一个父节点引用,左右孩子节点引用,还有一个value值,虽然效率高但开销很大。
今天我们将要介绍的PriorityQueue优先队列,更多的可以理解为是上述所有集合实现的一种折中的结构,它逻辑上使用堆结构(完全二叉树)实现,物理上使用动态数组实现,并非像TreeMap一样完全有序,但是如果按照指定方式出队,结果可以是有序的。本篇就将详细谈谈该结构的内部实现,以下是涉及的主要内容:
- 堆数据结构的简单介绍
- 构造PriorityQueue实例
- 有关优先队列的基本操作(增删改查)
- 其他相关操作的细节
- 一个简单的实例的应用
一、堆结构的简单介绍
这里的堆是一种数据结构而非计算机内存中的堆栈。堆结构在逻辑上是完全二叉树,物理存储上是数组。在介绍它之前,我们先了解完全二叉树的相关知识。首先我们知道,满二叉树除了叶子节点,其余所有节点都具有左右孩子节点,类似下图:
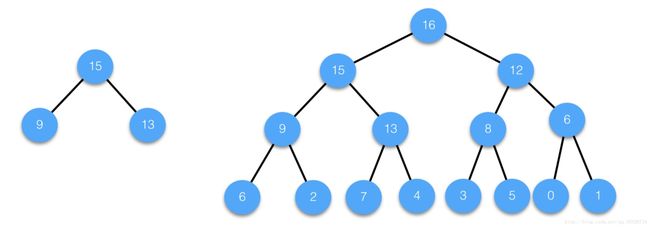
整棵树看起来是满的,除了叶子节点没有孩子节点外,其余所有节点都是左右孩子节点的。而我们的完全二叉树要求没这么严格,它并不要求每个非叶子节点都具有左右孩子,但一定要按照从左到右的顺序出现,不能说没有左孩子却有右孩子。以下是几个完全二叉树:
但是以下几个则不是完全二叉树:
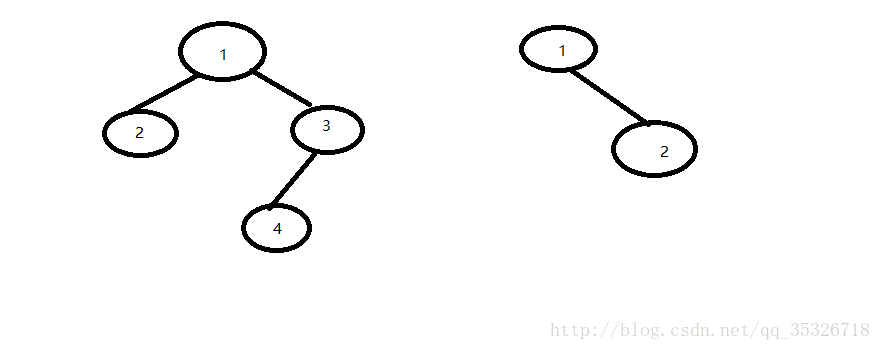
满足完全二叉树的前提是,在同一层上,前面的节点没有孩子节点,后面节点就不能有孩子节点。正如上图第一棵树一样,只有2节点具有左右孩子节点之后,3节点才能具有孩子节点。上图第二棵树为什么不满足完全二叉树,因为完全二叉树中每个节点必须是先有左孩子节点然后才能有右孩子节点。如果你学习过数据结构,上述文字可能会帮助你快速回忆起来相关概念,但是如果你没有学习过数据结构,那么你可能需要自行百度或者评论留言了解学习相关知识之后再继续下文。
上述文字我们回顾了完全二叉树的相关概念,但是完全二叉树并不是堆结构,堆结构是不完全有序的完全二叉树。我们知道完全二叉树有个非常大的优点,你可以从任意节点根据公式推算出该节点的左右孩子节点的位置以及父节点的位置。例如:
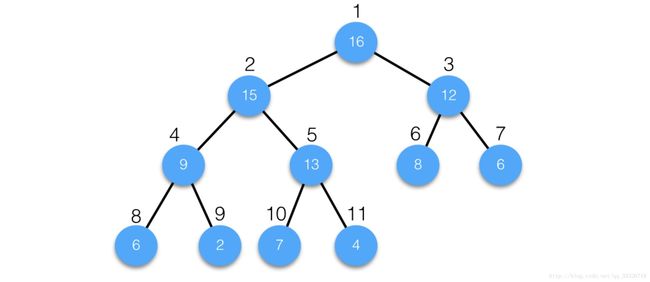
上图中,我们为每个节点编号,此时我们可以从任意一个节点推算出它的父节点,左右孩子节点的位置。例如:当前节点为4号节点,那么该节点的父节点编号为4/2,左孩子节点编号24,右孩子节点编号24+1。想必公式大家已经能够得出,当前节点位置为 i ,父节点位置 i/2,左孩子节点位置2i,右孩子节点2i+1。利用这个特性,我们就不必维护节点与节点之间的相互引用,TreeMap中定义一个Entry类,分别一个parent引用,left引用,right引用,并使用它们维护当前节点和别的节点之间的关系。而我们利用完全二叉树的这种特性,完全可以用数组作为物理存储。上述完全二叉树可以存储为以下的数组:

虽然数组中并没有显示出任何节点之间的关系,但是他们之间的关系是隐含的。例如:5号节点的父节点编号5/2,是2号,左右孩子节点分别为52,52+1节点。
以上我们便完成了对堆结构的大致描述,完全二叉树加数组。下面我们简单介绍堆结构中添加元素,删除元素是怎么做到保持堆结构不变的。在详细介绍之前,我们需要知道,堆分大根堆和小根堆。大根堆的要求是父节点比子节点的值大,小根堆要求父节点的值比子节点的值小,至于左右孩子节点的值的大小没有要求,所以我们说堆是不完全有序结构。下文我们将主要以小根堆为例,介绍堆结构中添加删除元素是怎么做到保持这种结构不发生改变的。
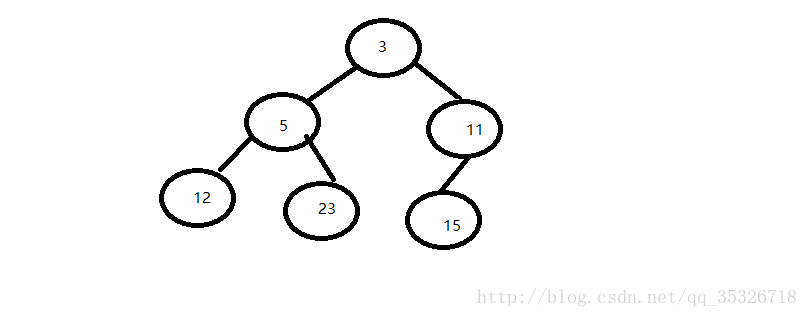
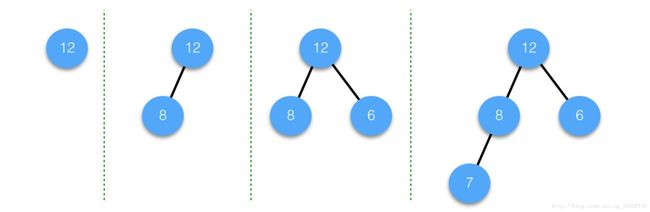
这是一个小根堆,假设我们现在要添加一个元素到该堆结构中。假定新元素的值为9,主要操作有以下两个步骤:
- 将新元素添加到堆结构的末尾(不论该值的大小)
- 不断调整直至满足堆结构
第一步,添加新元素到堆结构末尾:
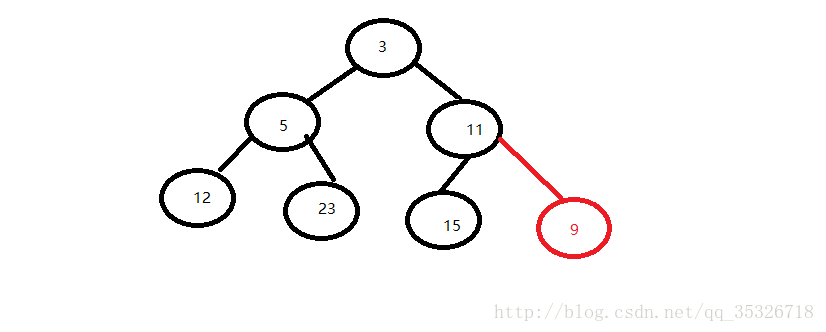
第二步,调整结构:
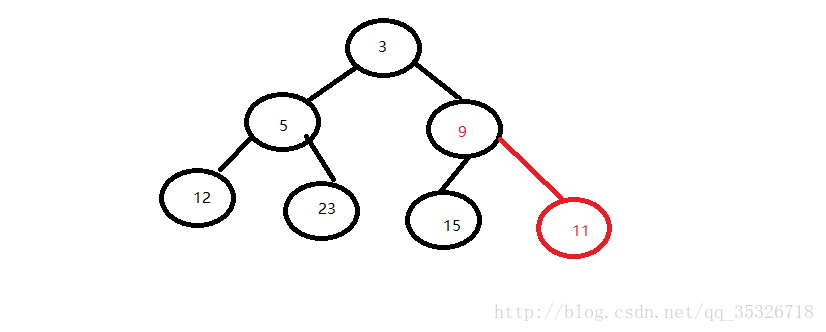
添加元素还是比较简单的,就两个步骤。无论将要添加的新元素的值是多大,第一步始终是将该新元素添加到最后位置,第二步可能不止一次的调整结构,但最终会调整完成,保持该堆结构。下面我们看删除节点的不同情况。
1、删除头节点
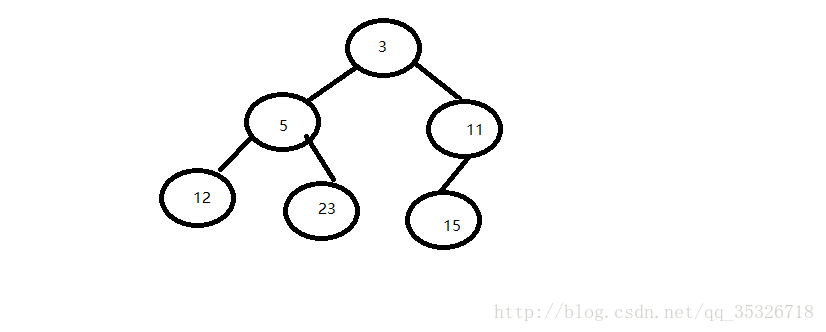
假定现在我们需要删除头部元素3,我们主要还是两个步骤:
- 用最后一个元素替换头部元素
- 用头元素和两个孩子中值较小的节点相比较,如果小于该节点的值则满足堆结构,不做任何调整,否则交换之后做同样的判断
第一步,用尾部元素替换头元素:
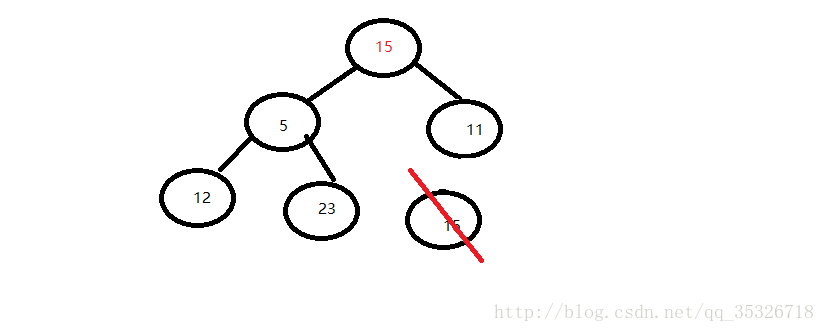
第二步,和较小值的子节点比较并完成交换:
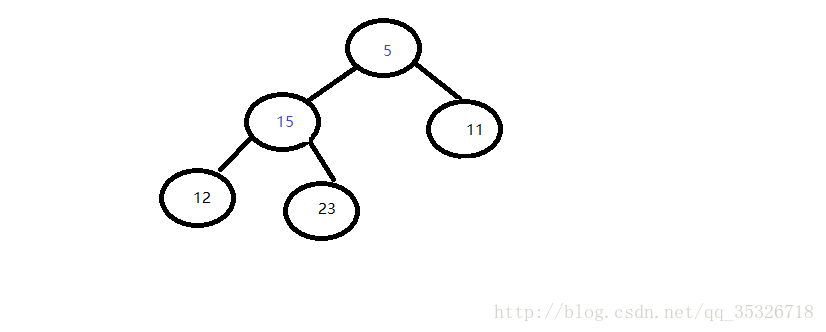
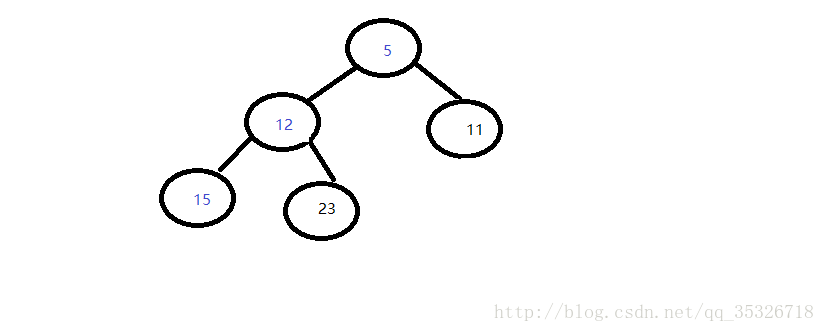
最后删除后的结果如上图所示,删除头节点的情况还是比较简单的,下面我们看从中间删除元素。
2、删除中间元素
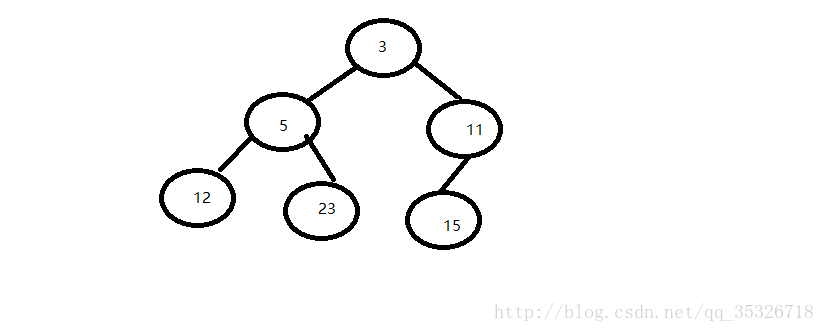
现在假如我们需要删除5号节点,主要是三个步骤:
- 用最后一个元素替换将要被删除的元素并删除最后元素
- 判断该节点的值与其子节点中最小的值比较,如果小于最小值则维持堆结构,否则向下调整
- 判断该节点的值是否小于父节点的值,如果小于则向上调整,否则维持堆结构
第一步,用最后元素替换将要被删除的元素:
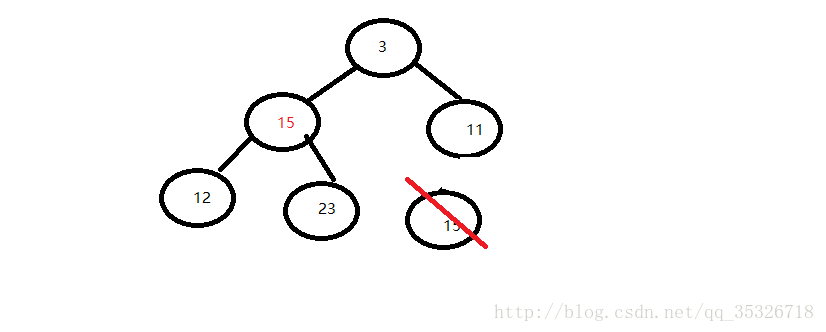
第二步,与子节点比较判断:
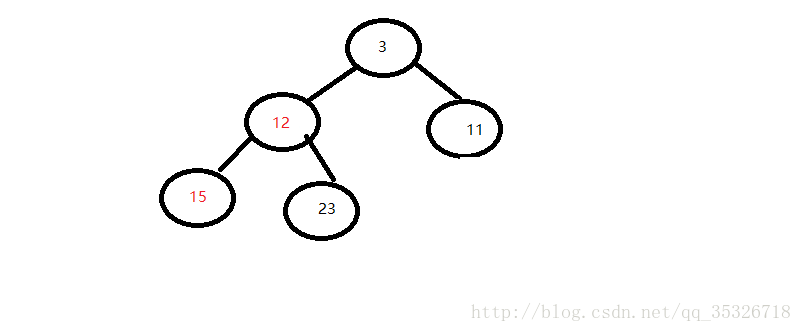
第三步,与父节点比较,满足条件,维持堆结构。
概括整个删除的过程,无论是从头部删除还是从中间删除元素,都是先用最后的元素替换被删元素,然后向下调整来维持堆结构,接着向上调整维持堆结构。
至此,我们简单介绍了堆这种数据结构,包括向其中添加删除元素的时候,它维持这种的结构的解决办法。我们花了大量文笔介绍这种结构,是因为PriorityQueue就是对这种堆结构的实现,只有理解了这种数据结构才能更好的理解PriorityQueue。下面我们开始看PriorityQueue的原理及具体实现的代码。
二、构造PriorityQueue实例
在实际介绍PriorityQueue原理之前,再次啰嗦PriorityQueue的内部结构。PriorityQueue中的元素在逻辑上构成了一棵完全二叉树,但是在实际存储时转换为了数组保存在内存中,而我们的PriorityQueue继承了接口Queue,表名这是一个队列,只是它不像普通队列(例如:LinkedList)在遍历输出的时候简单的按顺序从头到尾输出,PriorityQueue总是先输出根节点的值,然后调整树使之继续成为一棵完全二叉树 样每次输出的根节点总是整棵树优先级最高的,要么数值最小要么数值最大。下面我们看如何构造一个PriorityQueue实例。
在PriorityQueue的内部,主要有以下结构属性构成:
//默认用于存储节点信息的数组的大小
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//用于存储节点信息的数组
transient Object[] queue;
//数组中实际存放元素的个数
private int size = 0;
//Comparator比较器
private final Comparator comparator;
//用于记录修改次数的变量
transient int modCount = 0;
我们知道,堆这种数据结构主要分类有两种,大根堆和小根堆。而我们每次的调整结构都是不断按照某种规则比较两个元素的值大小,然后调整结构,这里就需要用到我们的比较器。所以构建一个PriorityQueue实例主要还是初始化数组容量和comparator比较器,而在PriorityQueue主要有以下几种构造器:
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity,Comparator comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
主要构造器有上述四种,前三种在内部会调用最后一个构造器。两个参数,一个指定要初始化数组的容量,一个则用于初始化一个比较器。如果没有显式指定他们的值,则对于容量则默认为DEFAULT_INITIAL_CAPACITY(11),comparator则为null。下面我们看获取到PriorityQueue实例之后,如何向其中添加和删除节点却一样保持原堆结构不变。
三、有关优先队列的基本操作(增删改查)
首先我们看添加一个元素到堆结构中,我们使用add或者offer方法完成新添一个元素到堆结构中。
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
实际上add方法的内部调用的还是offer方法,所以我们主要看看offer是如何实现添加一个元素到堆结构中并维持这种结构不被破坏的。首先该方法定义了一 变量获取queue中实际存放的元素个数,紧接着一个if判断,如果该数组已经被完全使用了(没有可用空间了),会调用grow方法进行扩容,grow方法会根据具体情况判断,如果原数组较小则会扩大两倍,否则增加50%容量,由于具体代码比较清晰,此处不再赘述。接着判断该完全二叉树是否为空,如果没有任何节点,那么直接将新增节点作为根节即可,否则会调用siftUp添加新元素并调整结构,所以该方法是重点。
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
此处会根据调用者是否传入比较器而分为两种情况,代码类似,我们只看一种即可。
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
该方法首先获取最后一个位置的父节点的索引,然后定义变量接受父节点的值,如果新增的节点值和父节点的值比较之后满足堆结构,则直接break返回,否则循环向上交换,最终完成堆结构调整。具体我们通过一个实例演示整个过程:
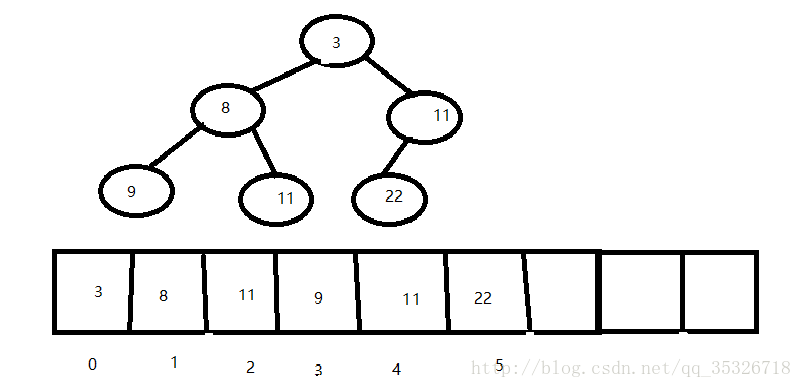
首先初始化一个小根堆,假如现在我们要添加一个新元素值为5,根据siftUpUsingComparator方法的代码,此时参数k的值应为6,那么最后一个节点的父节点的索引为2(即三号节点11),然后e的值就为11,通过比较器比较判断5是否小于e,如果小于则说明需要调整结构,那么会将最后一个节点的值用父节点e的值取代,也就是会变成这个样子:
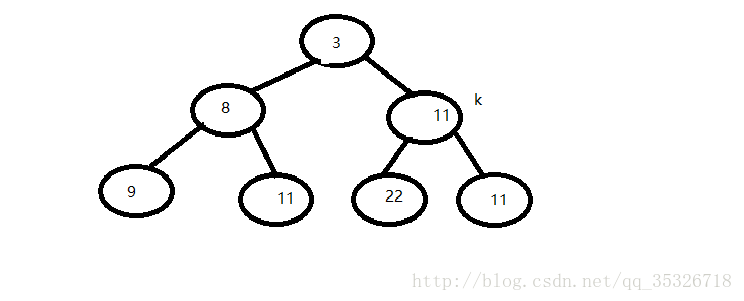
再次进入循环,parent 的值为(2-1)/2=0,比较器比较索引为0的节点和我们需要新插入的节点(值为5),发现3小于5,则break出循环,最后将queue[k] = x;,最终结果如下:
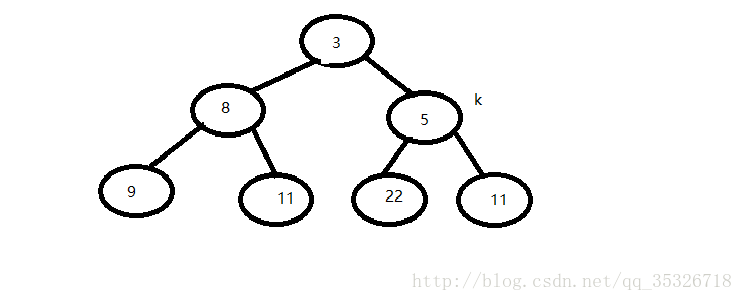
以上就完成了新添一个元素到堆结构中并保持堆结构不被破坏,可能上述文字在有些地方描述不清,但是相信大致意思应该是表达出来了,大家可以自行查看源码感受下。下面我们简单看看删除一个节点的代码部分:
private E removeAt(int i) {
modCount++;
int s = --size;
if (s == i)
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);
if (queue[i] == moved) {
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
该方法内部也调用了多个其他方法,此处为了节约篇幅,大致说明下整个删除过程,具体代码大家可以自行体会。首先该方法会获取到最后一个节点的索引并判断删除元素是否为最后一个节点,如果是则直接删除即可。
如果删除索引不是最后一个位置,那么首先会获取到最后一个节点的值并将其删除,紧接着将最后一个节点的值覆盖掉待删位置的节点值并调整结构,调整完成之后,会判断queue[i] == moved,如果为true表示新增元素之后并没有调整结构(满足堆结构),那么就会向上调整结构。(如果向下调整过结构自然是不需要再向上调整了),如果queue[i] != moved值为true表示向上调整过结构,那么将会返回moved。(至于为什么要在向上调整结构之后返回moved,主要是用于迭代器使用,此处暂时不会介绍)。
这里就是删除一个节点的大致过程,该方法还是比较底层的,其实PriorityQueue中是有一些其他删除节点的方法的,但是他们内部调用的几乎都是removeAt这个方法。例如:
//根据值删除节点
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
当然如果一个队列中有多个具有重复值的节点,那么该方法调用了indexOf方法会获取第一个符合条件的节点并删除。当然还有其他一些删除方法,此处不再介绍,大家可以自行体会。
四、有序出队
我们说过,PriorityQueue这种结构使用的是堆结构,所以他是一种不完全有序的结构,但是我们也提过,可以逐个出队来实现有序输出。下面我们看看它是如何实现的:
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
上述我们列出了两个方法的源码,peek方法表示获取队列队头元素,代码还是容易的,我们主要看poll方法,该方法用于出队头节点并维持堆结构。
有了之前的基础,poll方法的代码还是简单的,首先判断该队中是否有元素,如果没有则直接返回null,否则分别获取头节点的值和末节点的值,删除尾节点并将尾节点的值替换头节点的值,接着向下调整结构,最后返回被删除的头节点的值。下面我们看一个实例:
public static void main(String[] args){
PriorityQueue pq = new PriorityQueue();
pq.offer(1);
pq.offer(21);
pq.offer(345);
pq.offer(23);
pq.offer(22);
pq.offer(44);
pq.offer(0);
pq.offer(34);
pq.offer(2);
while(pq.peek()!=null){
System.out.print(pq.poll() + " ");
}
}
我们乱序添加一些元素到队列中,当然每次添加都会维持堆结构,然后我们循环输出。程序运行结果如下:
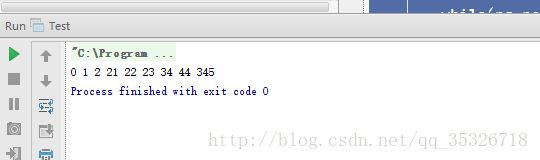
当然这里我们没有显式的传入比较器,此处会默认使用Integer的comparator,如果我们需要自己控制比较方式,可以传入一个comparator用于比较。例如:
public static void main(String[] args){
PriorityQueue pq = new PriorityQueue(
new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if((Integer)o1<=(Integer)o2){
return 1;
}
else
return -1;
}
}
);
pq.offer(1);
pq.offer(22);
pq.offer(4);
pq.offer(45);
pq.offer(12);
pq.offer(5);
pq.offer(76);
pq.offer(34);
pq.offer(23);
pq.offer(22);
while(pq.peek()!=null){
System.out.print(pq.poll() + " ");
}
}
以上代码在构建PriorityQueue实例对象的时候显式传入一个comparator比较器,按照从大到小的顺序构建一个堆结构。输出结果如下:
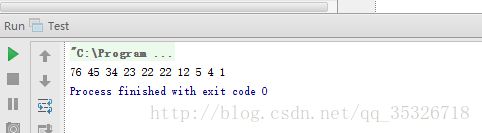
至此我们完成了对PriorityQueue这种堆结构的容器的简单介绍,至于在何种情况下选择该结构还需结合实际需求,总结不到之处,望大家补充!