-
认识Linux文件系统
-
磁盘组成及分区复习(正好给自己提几个问题)
-
什么是扇区,有哪两种格式
- 扇区(Sector)为最小的物理储存单位,且依据磁盘设计的不同,目前主要有 512bytes 与 4K 两种格式;
-
什么是磁柱
- 将扇区组成一个圆,那就是磁柱(Cylinder);
-
磁盘分区表的两种格式
- 磁盘分区表主要有两种格式,一种是限制较多的 MBR 分区表,一种是较新且限制较少的 GPT 分区表。
-
MBR第一个扇区由什么组成呢
- MBR 分区表中,第一个扇区最重要,里面有: (1)主要开机区(Master boot record, MBR)及分区表(partition
table), 其中 MBR 占有 446 bytes,而 partition table 则占有 64 bytes。
- MBR 分区表中,第一个扇区最重要,里面有: (1)主要开机区(Master boot record, MBR)及分区表(partition
-
实体磁盘的文件名是什么
- /dev/sd[a-p][1-128]
-
虚拟磁盘的文件名是什么
- /dev/vd[a-d][1-128]
-
-
文件系统特性
- 什么是格式化,(我以前只是觉得是清空哈哈哈哈,还真没想过),每种操作系统所设定的文件属性和权限并不相同,格式化分区槽是为了让它变成系统能够使用的"文件系统格式"
- 文件系统通常将权限和属性放到inode中,实际数据放到data block区块中,另外有一个超级区块(superblock)会记录整个文件系统的整体信息(inode与block的总量呀,使用量呀,剩下多少呀,听起来像一个管家哈哈哈哈)
- inode、block、superblock的简要概述
- superblock:记录此 filesystem 的整体信息(inode/block 的总量、使用量、剩余量, 以及文件系统的格式与相关信息)
- inode:记录文件的属性,一个文件占用一个inode,同时记录文件数据所在的block号码
- block:实际记录文件的内容,如果是很大的文件就多占一些block啦
- 关于碎片整理
- 需要碎片整理是因为写入的block过于离散啦,想想磁盘机械手臂的磁盘读取头来来回回的我都觉得累,碎片整理就是将同一个文件的block整理到一起,那么数据的读取就变得容易,但是Ext2是索引式文件系统(一下子将inode中的block号码对应的block全读出来,是不是有点像散列表哈哈哈),不太需要碎片整理啦,但是如果是以前的老式u盘呢,例如FAT格式(这里读取block是需要一个一个读取的,感觉像链表),就需要碎片整理了
-
Linux的Ext2文件系统(inode)
- 文件系统一开始就将inode与block规划好了,除非重新格式化or利用resize2fs等指令变更文件系统大小,否则inode和block就固定不再变动啦
-
关于区块群组
-
如果文件系统太大啦,那么那么夺得inode与block都放在一起也不好管理,于是Ext2文件系统在格式化的时候会区分为多个区块群组,而每个群组都有独立的inode、block、superblock系统
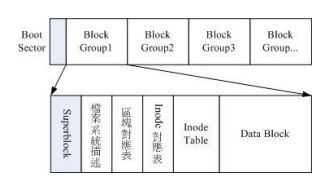
- 接上图,文件系统最前面有一个启动扇区(boot sector)可安装开机管理程序,所以我们才能由多重引导呀!
-
-
data block
-
Ext2 文件系统中所支持的 block 大小有 1K, 2K 及
4K 三种而已

- 上图非绝对,某些应用程序捕捉不到辣么大的文件
- 关于Ext2文件系统block的限制
- 原则上, block 的大小与数量在格式化完就不能够再改变了(除非重新格式化)
- 每个 block 内最多只能够放置一个文件的数据
- 如果文件大于 block 的大小,则一个文件会占用多个 block 数量
- 若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)
- 现在磁盘都太大啦,4k就好,知道原理就行
-
-
inode table
- inode记录的文件数据至少有:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性(flag),如 SetUID...;
- 该文件真正内容的指向 (pointer);
- 关于inode的特色
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes)
- 每个文件都仅会占用一个inode
- 文件系统能够建立的文件数量与inode的数量有关
- 系统读取文件需先找到inode,先分析inode所记录的权限与用户是否符合,如果符合才能够开始读取block内容
- 关于inode的12个直接、一个间接、一个双间接和一个三间接
-
如果文件很大呢,inode记录一个block号码要花费4byte,根本记录不下那么多block号码

- 直接就是直接指向block号码的对照
- 间接就是再拿一个block当作记录block号码的记录区
- 双间接就是使用第一个block来记录block号码
- 三间接就是使用第二个block记录block号码
-
- inode记录的文件数据至少有:
- 假如block大小为1k,inode能指定多少block呢
- 12个直接:12*1K=12K
- 间接:256*1K=256K
- 双间接:2562561K=2562K
- 三间接: 256256256*1K=2563K
- 总额=12 + 256 + 256256 + 256256*256 (K) = 16GB
- 注意2k与4k block不能这么计算,因为会受到Ext2文件系统本身的限制
-
superblock
- superblock记录的主要信息
- block与inode的总量
- 未使用与已使用的inode和block数量
- block与inode的大小(block 为 1, 2, 4K, inode 为 128bytes 或 256bytes)
- filesystem的挂载时间,最近一次写入数据的时间,最近一次检查磁盘(fsck)的时间等文件系统相关信息
- 一个valid bit数值,如果这个文件系统已经被挂载,valid bit为0,否则valid bit为1
- 注意:除了第一个block group含有superblock之外,后面的block group不一定含有superblock,如果有的话呢,主要是作为第一个block group内superblock的备份,用于救援
- Filesystem Description(文件系统描述谁说明)
- 该区段描述每个block group的开始和结束block号码,以及每个区段(superblock、bitmap、inodemap、data block)分别介于哪一个block号码之间
- superblock记录的主要信息
-
block bitmap(区块对照表)**
- block bitmap记录的主要信息
- 记录哪些block是空的
- 再删除某些文件时,文件原本占用的block号码需要释放,block bitmap中相应的block号码标志就会被修改为"空闲"
- block bitmap记录的主要信息
-
dumpe2fs:查询Ext家族superblock信息的指令**
- 语法
1. dumpe2fs [-bh] 装置文件名 - 选项与参数
1. -b :列出保留为坏轨的部分(用不到 ) 2. -h : 仅列出 superblock 的数据,不会列出其他的区段内容。 - blkid:显示目前系统被格式化的装置
- dumpe2fs的部分字段
1. Filesystem volume name:文件系统的名称 2. Last mounted on:上一次挂载的目录位置 3. Filesystem UUID:Linux对装置的定义码 4. Filesystem features:文件系统的特征数据 5. Default mount options:预设在挂载时会主动加上的挂载参数 6. Filesystem state:这块系统的文件的状态,clean是没问题的意思 7. Inode count:inode的总数 8. Block count:block的总数 9. Reserved block count:保留的block总数 10. Free blocks:空闲的block可用数量 11 Free inodes:空闲的inode可用数量 12. Block size:单个block的容量大小 13. inode size:inode的容量大小 14. Journal size:日志式数据的可供记录总量 15. Group 0:第一块block group位置 16. Primary superblock at 0, Group descriptors at 1-1:主要 superblock 的所在 17. Inode table at 161-672 (+161):inode table的所在 18. Free blocks:剩余的容量有多少
- 语法
-
-
与目录树的关系
-
目录
- 当我们在linux的文件系统建立一个目录时,系统会分配一个inode和至少一块block给该目录,inode记录该目录的权限、属性and分配到的block号码,block记录在这个目录下的文件名和该文件名占用的inode号数据[要记得这只是个目录呀]
- 当目录下的文件数过多导致一个block无法容纳所有文件名+inode对照号码时,Linux会给于该目录多一个block来记录相关的数据
-
文件
- 当我们在Linux的ext2建立一个一般文件时,ext2分配一个inode与相匹配与文件大小的block给该文件,[记得如果文件很大时候我们还有inode的12个直接、一个间接、一个双间接和一个三间接帮忙]
-
目录树读取
- eg:读取/etc/passwd的过程
- / 的 inode:
透过挂载点的信息找到根目录 inode,且 inode 规范的权限让我们可以读取该 block的内容(有 r 与 x); - / 的 block:
取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码; - etc/ 的 inode:
读取 etc的inode号码得知用户具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容; - etc/ 的 block:
取得 block 号码,并找到该内容有 passwd 文件的 inode 号码; - passwd 的 inode:
读取passwd的inode号码得知用户具有 r 的权限,因此可以读取 passwd 的 block 内容; - passwd 的 block:
将该 block 内容的数据读出来。
- / 的 inode:
- eg:读取/etc/passwd的过程
-
filesystem 大小与磁盘读取效能
- 文件系统过大可能会有文件数据离散的问题发生,合理规划分区
-
-
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
-
新增一个文件时文件系统的行为
- 确定新增文件的目录是不是有相应权限
- 根据inode bitmap找到没有使用的inode号码,将新文件的权限/属性写入
- 根据block bitmap找到未使用的block号码,将实际数据写入block,并更新inode的block指向
- 将刚刚写入的inode与block数据同步至inode bitmap与block bitmap,并更新superblock的内容
-
数据存放区域与中介数据
- 将inode table与data block称为数据存放区域
- 将其他eg:superblock、block bitmap与inode bitmap等区段称为metadata(因为superblock、block bitmap与inode bitmap数据经常变动,无论新增、删除还是修改都会影响这几个区段的数据,所以就叫中介数据啦)
-
数据不一致(inconsistent)状态
- 写入inode table与data block数据之后,嘣!停电了!系统不知道为啥断了!metadata的内容与实际数据存放区不一致
- Ext2中,如果有此情况,系统重新启动后会由superblock当中的valid bit与filesystem state等状态判断是否强行进行数据一致性检查(费事费力,要针对metadata区域与实际数据存放区进行对比,要搜寻整个filesystem,于是引出了日志式文件系统)
-
日志式文件系统(journaling filesystem)
- 简化了的一直性检查的步骤
- 预备:当系统要写入一个文件,在日志记录区块中记录某个文件准备要写入的信息
- 实际写入:写入文件的权限and数据,更metadata的数据
- 结束:完成数据与metadata的更新
- 这样做的好处在于有问题检查日志记录区块就好了,不用针对整块filesystem检查
- 简化了的一直性检查的步骤
-
Linux文件系统的运作
- 关于异步处理(asynchronously)的方式
系统加载一个文件到内存后,如果文件没有修改过,那么内存区段的文件数据就会设定为干净(clean)的,但是如果内存中的文件被修改过,此时内存中的数据就会被设定为脏的(dirty),此时所有的动作都在内存中进行,不写入到磁盘,然后系统不定时的将内存中设定为dirty的数据写回磁盘,以保持磁盘和内存数据一致性 - 关于Linux文件系统与内存的关系
- 系统将常用的文件数据放置到主存储器的缓冲区,用来加速文件系统的读写
- 所以Linux的物理内存最后都会被用光,这是正常滴,为了加速系统效能
- 可以使用sync来强迫内存中dirty的文件回写到磁盘
- 关机指令会主动呼叫sync
- 非正常系统中断,由于数据未回写到磁盘,重新启动可能要花费时间进行磁盘检验,还有可能导致文件系统的损毁(不是磁盘坏了...)
- 关于异步处理(asynchronously)的方式
-
挂载点的意义(mount point)
- 挂载点一定时目录,该目录未进入该文件系统的入口
- 这里要重点重重点记录一下了!!!这里我本来一直没搞清楚为什么/,/home,/boot这三个目录的inode的号码都是一样的,而且为什么说/,/home,/boot是三个不同的文件系统
因为他们都挂载在根目录啊,目录是目录,挂载只是挂在树上的果子而已,谁或三个果子不能长在一个枝桠上,剩下的事交给目录inode指向的block,而/,/home,/boot的文件属性并不相同,挂载点也不相同,所以自然是三个不同的文件系统 - 为什么/,/.,/..是一样的东西呢,可以看一看,文件属性相同,还指向一个inode,还都是一个挂载点,当然是一个东西[官方一点说,同一个filesystem的某个inode只会对应到一个文件内容,毕竟一个文件占用一个inode嘛]
-
-
其他 Linux 支持的文件系统与 VFS
-
常见的支持的日志式文件系统
- 传统文件系统: ext2 / minix / MS-DOS / FAT (用 vfat 模块) / iso9660 (光盘)等等
- 日志式文件系统: ext3 /ext4 / ReiserFS / Windows' NTFS / IBM's JFS / SGI's XFS / ZFS
- 网络文件系统: NFS / SMBFS
-
查看Linux支持的文件系统
ls -l /lib/modules/$(uname -r)/kernel/fs -
查看目前已加载到内存中支持的文件系统
cat /proc/filesystems -
Linux VFS(virtual filesystem switch)
- 整个linux系统都是通过名为vfs的核心功能来读取filesystem的,所以我们才无需知道每个partition是什么,vfs主动帮我们做好读取的工作
-
vfs简略图

-
-
XFS 文件系统简介
-
EXT 家族: 支持度最广,格式化超慢
- ext家族采用的是预先规划处所有的inode/block/metadata等数据,但是目前磁盘容量愈来愈大,传统MBR被GPT取代,格式化的时候预先分配inode和block要耗费大量时间
-
XFS 文件系统的配置
- xfs主要规划为三个部分,一个资料区 (data section)、一个文件系统活动登录区 (log section)以及一个实时运作区 (realtime section)
- 资料区(data section)
- 与ext家族一样包括 inode/data block/superblock 等数据
- 与ext家族类似,data section分为多个储存区群组(allocation groups),每个储存区群组包含(1)整个文件系
统的 superblock、 (2)剩余空间的管理机制、 (3)inode 的分配与追踪。 - inode与block在系统需用时动态生成
- 与ext家族不同之处,xfs的block与inode哟多种不同的容量可设定,block[512bytes ~ 64K,最高4k,不然linux核心不给挂载没法用],inode[256bytes ~2M,256bytes的默认值即可]
- 文件系统活动登录区(log section)
- 主要用来记录文件系统的变化,直至文件的变化完整的写入到数据区,该文件的该笔记录才会终结,文件系统意外中断后系统会依此登录区进行检验,来快速的修复文件系统
- 可指定外部的磁盘作为xfs的日志区块(因为读写频繁,可指定ssd)
- 实时运作区(realtime section)
- 文件建立时,xfs在这一区段找一个或书个extent区块用来将文件放置在这个区块内,等到分配完毕,再写入data section的inode与block中
- 这个extent区块大小在格式化时要先指定[4K~1G],默认即可,不要乱动[会影响到实际磁盘的效能]
- xfs主要规划为三个部分,一个资料区 (data section)、一个文件系统活动登录区 (log section)以及一个实时运作区 (realtime section)
-
XFS文件系统的描述数据观察
-
xfs_info 挂载点/装置文件名
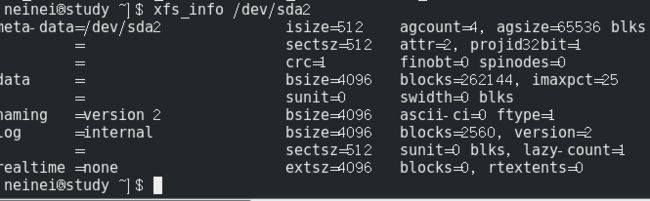
- 第一行,isize=inode的容量,agcount=储存区群组的个数,agsize=每个储存区群组具有65536个block,文件系统容量=4655364k*(第四行bsize=4096=4k)
- 第二行,sectsz=逻辑扇区(sector)的容量
- 第四行,bsize=block的容量
- 第五行,sunit与swidth与磁盘阵列的stripe相关性较高
- 第七行,internal指的是这个登录区的位置在文件系统内,而非外部设备
- 第九行,realtime=none表示没有使用,extent容量=4k
-
-
-
-
文件系统的简单操作
-
磁盘与目录的容量
-
df
- 语法
1. df [-ahikHTm] [目录或文件名] - 选项与参数
1. -a:列出所有文件系统,包括特有的/proc等文件系统 2. -k:以kbytes的容量显示 3. -m:以mbytes的容量显示 4. -h:以较易阅读的格式显示(G,M,K) 5. -H:以m=1000k取代m=1024k的方式 6. -T:连同partition的filesystem名称(eg:xfs)也列出来 7. -i:不用磁盘容量,而以inode的数量来显示 - 字段含义
- filesystem:代表文件系统是在哪个partition
- 1k-blocks:底下的数字单位是1kb
- used:使用掉的硬盘空间
- available:剩下的磁盘空间大小
- use%:磁盘使用率
- mounted on:挂载点
- 有个/dev/shm的目录是内存虚拟出来的磁盘空间哈,通常是总物理内存的一半
- 语法
-
du
- 语法
1. du [-ahskm] 文件或目录名称 - 选项与参数
1. -a列出所有的目录与文件容量 2. -h:同df 3. -s:列出总量,而不列出每个目录的占用容量 4. -S:不包括子目录的统计,与-s有差别 5. -k,-m:同上 - 直接输入du不加选项,du会分析当前目录的文件与目录所占用的磁盘空间,实际显示时仅会显示目录容量(不含文件)
- 语法
-
-
实体链接与符号链接
-
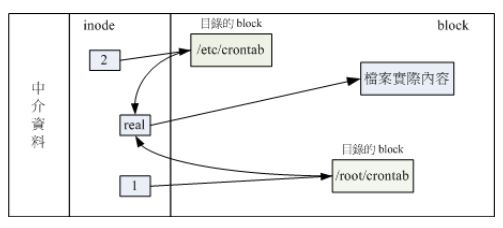
Hard link(实体链接、硬链接or实际链接)
有没有可能多个档名对应到同一个inode?hard link就是在某个目录下新增一笔档名链接到某个inode号码的关联记录
建立实体链接的指令
ln 目标文件名 将建立实体链接的文件名-
示意图
-
建立实体链接的好处
- 安全:将任何一个文件删除后,inode与block都依然存在,可通过另一个档名来读取到正确的文件数据
有没有可能hard link改变block呢,有,新增数据正好将目录的block填满时则需要再加一个block来记录时
-
hard link的限制
- 不能跨filesystem
- 不能link目录
-
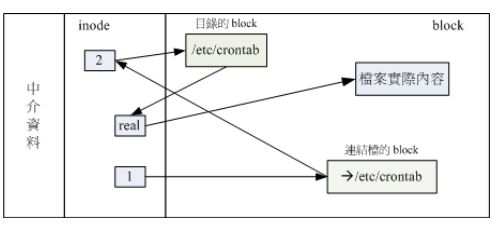
Symbolic link(符号链接)
- symbolic link就是建立一个独立的文件,当数据读取时这个文件会指向他link的文件的档名,当源档被删除后,符号链接的文件将找不到原始的档名
- 建立符号链接的指令
ln -s 目标文件名 将建立符号链接的文件名 - 连结档的重要内容就是他会写上目标文件的文件名(ll可以看到连结档的的大小其实就是目标文件名的路径)
-
示意图
-
ln
- 语法
1. ln [-sf] 来源文件 目标文件 - 选项与参数
-s:如果不加任何参数就进行连结,那就是 hard link,至于 -s 就是 symbolic link -f:如果目标文件存在时,就主动的将目标文件直接移除后再建立 - eg
cd /tmp;cp -a /etc/passwd du -sb;df -i .(计算/tmp下有多少个bytes的容量,使用了多少inode) ln passwd passwd_hd(实体链接) du -sb;df -i .(观察) ln -s passwd passwd_so(符号链接) du -sb;df -i .(观察) ll -i passwd*(观察) - 关于目录的link数量
- 新建一个目录,会有三样东西,目录本身,“.”,"..","."指向目录本身,".."指向上层目录,so...新的目录link数为2,上层目录的link数增加1
- 语法
-
-
-
磁盘的分区、格式化、检验与挂载
- 新增一颗磁盘时的动作
- 对磁盘进行分区,以建立可用的 partition
- 对该 partition 进行格式化 (format),以建立系统可用的 filesystem
- 若仔细一点,则对刚刚建立好的 filesystem 进行检验
- 在 Linux 系统上,需要建立挂载点 (亦即是目录),并将他挂载上来
-
观察磁盘分区状态
-
lsblk 列出系统上的所有磁盘列表
- 语法
1. lsblk [-dfimpt] [device] - 选项与参数
-d : 仅列出磁盘本身,并不会列出该磁盘的分区数据 -f :同时列出该磁盘内的文件系统名称 -i :使用 ASCII 的方式输出,不使用复杂的编码 -m :同时输出该装置在 /dev 底下的权限数据 (rwx 的数据) -p :列出该装置的完整文件名 -t :列出该磁盘装置的详细数据,包括磁盘队列机制、 预读写的数据量大小等 - 一些字段
NAME:装置的文件名(省略/dev等前导目录) MAJ:MIN:主要:次要装置代码(核心认识的装置都是透过这两个代码熟悉的) RM:是否为可卸除装置(usb、光盘...etc) SIZE:容量 RO:是否为只读装置 TYPE:是磁盘(disk),分区(partition)还是只读存储器(rom)等 MOUNTPOINT:挂载点 - eg
- 列出/dev/sda装置内所有数据的完整文件名
lsblk -ip /dev/sda - 列出装置的UUID参数
UUID:全局单一标识符,Linux将系统内所有的装置都给予一个独一无二的标识符,可用来挂载or使用
blkid - parted列出磁盘的分区表类型与分区信息
parted device_name print
几个字段
Model:磁盘的模块名(厂商
Disk /dev/sda:磁盘的总容量
Partition Table:分区表格式(MBR/GPT)
- 列出/dev/sda装置内所有数据的完整文件名
- 语法
-
-
磁盘分区:gdisk/fdisk
- __MBR分区使用fdisk分区,GPT分区使用gdisk分区
-
gdisk(不需要背)
-
gdisk 装置名称
eg:gdisk /dev/sda 几个常用的指令 d delete a partition # 删除一个分区 n add a new partition # 增加一个分区 p print the partition table # 印出分区表 (常用) q quit without saving changes # 不储存分区就直接离开 gdisk w write table to disk and exit # 储存分区操作后离开 gdisk 使用gdisk不要背,?之后就全都可以看到(可以随便玩,别按w,按q就行了)
-
p列出目前磁盘分区表信息后的几个字段
- Number:分区表编号,1指的是/dev/sda1
- Start(sector):每一个分区槽开始扇区号码位置
- End(sector):每一个分区的结束扇区号码位置,与 start 之间可以算出分区槽的总容量
- Size:分区槽容量
- Code:分区槽内可能的文件系统类型,linux为8300,swap为8200(只是一个提示,不见得真的代表分区槽内的文件系统)
- Name:文件系统的名称
-
几点重要的结论
- 可以看到最大扇区数及目前使用到的扇区数,可以进行额外的分区
- 新分区通常选用上一个分区的结束扇区号码+1作为起始扇区号码
- gdisk只有root可以执行,使用的装置文件名eg:/dev/sda,而不要使用/dev/sda1,因为我们是对整个磁盘进行分区而不是某个分区进行分区
-
用gdisk新增分区槽(下面是假设需求)
1GB 的 xfs 文件系统 (Linux)
1GB 的 vfat 文件系统 (Windows)
0.5GB 的 swap (Linux swap)(这个分区等一下会被删除喔! )
-
- 新增一颗磁盘时的动作