本文所有内容皆关于 ES和 kibana
一、简介
ELKB即elasticsearch、logstash、kibana、Beats的简称,elasticsearch接收Beats或logstash的数据提供数据存储及搜索功能;kibana为elasticsearch的页面展示工具。
二、优缺点
I. 优点
1) 强大的搜索功能,elasticsearch可以以分布式搜索的方式快速检索,而且支持DSL的语法来进行搜索,简单的说,就是通过类似配置的语言,快速筛选数据。
2) 完美的展示功能,可以展示非常详细的图表信息,而且可以定制展示内容,将数据可视化发挥的淋漓尽致。
3) 分布式功能,能够解决大型集群运维工作很多问题,包括监控、预警、日志收集解析等。
4) 完整的自监控功能,elastic组件能满足常用的监控功能,包括服务器metric,elkb自身性能监控等。
II. 缺点
1) 告警。目前官方告警插件alert需要收费。
2) 关联分析。Es对于index的关联查询非常复杂。
三、应用场景
1) 站内搜索:主要和Solr竞争,属于后起之秀。
2) NoSQL Json文档数据库:主要抢占Mongo的市场,它在读写性能上优于Mongo,同时也支持地理位置查询,还方便地理位置和文本混合查询。
3) 监控:统计、日志类时间序的数据存储和分析、可视化,这方面是引领者。
4) 国外:Wikipedia(维基百科)使用ES提供全文搜索并高亮关键字、StackOverflow(IT问答网站)结合全文搜索与地理位置查询、Github使用Elasticsearch检索1300亿行的代码。
5) 国内:百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据,总共每天60TB+)、新浪 、阿里巴巴、腾讯等公司均有对ES的使用。
6) 使用比较广泛的平台ELK(ElasticSearch, Logstash, Kibana)。
四、ES集群部署
官网下载6.3.2:https://www.elastic.co/downloads
4.1 集群规划

4.2 安装ES
Elasticsearch-6依赖于jdk-1.8,官网建议jdk版本不低于1.8.0_131
查看:java -version
下载java-1.8:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Elasticsearch解压后主要修改配置文件config/elasticsearch.yml,严格按照原来的格式修改,否则不识别,修改下面几项:
#cluster.name: es_cluster #集群名,依此识别并组成集群
#node.name: node-1 #节点名,集群内每个节点名不同
#network.host: 192.168.0.1 #配置本机ip,以便外网访问
我的data节点配置(.yml的文件冒号后面必须加空格)
cluster.name: es_cluster
node.name: es-data1
network.host: es-data1
path.data: /elk/data
path.logs: /elk/logs
http.port: 9200
transport.tcp.port: 9300
node.master: false
#设置不充当master节点,默认为true
node.data: true #设置充当data节点,默认为true
#添加防脑裂配置(因为es默认是一个局域网内能搜索到的就是一个集群,一些原因会导致分成几个集群)
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["es-master1:9300"," es-master2:9300","es-master3:9300"]
bootstrap.memory_lock: true
elasticsearch配置的cluster.name相同,都启动可以自动组成集群,这里如果不改cluster.name则默认是cluster.name=elasticsearch,nodename随意取但是集群内的各节点不能相同,host设置自己的ip/hostname
另一个master节点的配置如下:
cluster.name: es_cluster
node.name: es-master1
path.data: /elk/data
path.logs: /elk/logs
http.port: 9200
transport.tcp.port: 9300
node.master: true#设置充当master节点,默认为true
node.data: false #设置不充当data节点,默认为true
network.host: es-master1
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["es-master1:9300"," es-master2:9300","es-master3:9300"]
bootstrap.memory_lock: true
注: discovery设置自动发现集群,discovery.zen.ping.unicast.hosts设置具有master权限的es节点ip,防止es的master节点因某些原因脑裂。不设置node.master和node.data则默认每个节点都有master和data权限。
更多配置详解请查看文章4.6
4.3 启动
后台启动,要装插件,前台启动全部./bin/elasticsearch,如果想在后台以守护进程模式运行,添加-d参数: ./bin/elasticsearch -d。
注:ES不能用root用户启动,先更改elasticsearch文件夹的所有者
关闭防火墙
成功页面访问:http://es-data1:9200

4.4 单机多实例配置
由于官方并不建议部署ES时为实例指定超过32GB的内存,但是现在一台实体机服务器内存远远不止32G,仅用32G内存显然是非常浪费的。所以我们要在一个服务器上开多个ES实例,以便达到充分利用资源的目的。
配置要点:
node.max_local_storage_nodes
这个配置限制了单节点上可以开启的ES存储实例的个数,我们需要开多个实例,因此需要把这个配置写到配置文件中,并为这个配置赋值为2或者更高。
http.port
这个配置是elasticsearch对外提供服务的http端口配置,默认情况下ES会取用9200~9299之间的端口,如果9200被占用就会自动使用9201,在单机多实例的配置中这个配置实际是不需要修改的。
但是为了更好地进行配置管理,以及和老的配置兼容,我们还是手动将第一个实例的http端口配置为9200,第二个实例配置为9201。
transport.tcp.port
这个配置指定了elasticsearch集群内数据通讯使用的端口,默认情况下为9300,与上面的http.port配置类似,ES也会自动为已占用的端口选择下一个端口号。我们可以将第一个实例的tcp传输端口配置为9300,第二实例配置为9301。
discovery.zen.ping.unicast.hosts
由于到了2.x版本之后,ES取消了默认的广播模式来发现master节点,需要使用该配置来指定发现master节点。这个配置在单机双实例的配置中需要特别注意下,因为习惯上我们配置时并未指定master节点的tcp端口,如果实例的transport.tcp.port配置为9301,那么实例启动后会认为discovery.zen.ping.unicast.hosts中指定的主机tcp端口也是9301,可能导致这些节点无法找到master节点。因此在该配置中需要指定master节点提供服务的tcp端口。
discovery.zen.ping.unicast.hosts: ["es-master1:9300","es-master2:9300","es-master3:9300"]
在config子目录下创建instance1和instance2两个目录,分别放置两个实例需要的elasticsearch.yml、log4j2.property和jvm.options配置文件。
启动实例
bin/elasticsearch -Des.path.conf=config/instance1 -d -p /tmp/elasticsearch_1.pid
4.5 ES安装问题集锦
elasticsearch安装过程中遇到了一些问题,这里提供解决的方法。
问题一:警告提示
[WARN][o.e.b.JNANatives ] unable to install syscall filter:
java.lang.UnsupportedOperationException:seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTERcompiled in
at org.elasticsearch.bootstrap.Seccomp.linuxImpl(Seccomp.java:349)~[elasticsearch-5.0.0.jar:5.0.0]
at org.elasticsearch.bootstrap.Seccomp.init(Seccomp.java:630)~[elasticsearch-5.0.0.jar:5.0.0]
报了一大串错误,其实只是一个警告。
解决:使用新的linux版本,就不会出现此类问题了。
问题二:ERROR: bootstrap checks failed
max filedescriptors [4096] for elasticsearch process likely too low, increase to atleast [65536]
max number of threads [1024] for user [lishang] likely too low, increase to atleast [2048]
解决:切换到root用户,编辑limits.conf 添加类似如下内容
vi /etc/security/limits.conf
添加如下内容:
*
soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
问题三:max number of threads [1024] for user[lish] likely too low, increase to at least [2048]
解决:切换到root用户,进入limits.d目录下修改配置文件。
vi
/etc/security/limits.d/90-nproc.conf
修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 2048
问题四:max virtual memory areas vm.max_map_count[65530] likely too low, increase to at least [262144]
解决:切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
然后,重新启动elasticsearch,即可启动成功。
4.6 ES配置
2.6.1 集群配置
elasticsearch集群搭建,可以把索引进行分片存储,一个索引可以分成若干个片,分别存储到集群里面,而对于集群里面的负载均衡,副本分配,索引动态均衡(根据节点的增加或者减少)都是elasticsearch自己内部完成的,一有情况就会重新进行分配。
下面先是介绍几个关于elasticsearch的几个名词
1.cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
2.shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
3.replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
4.recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
5.river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
6.gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
7.discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
8.Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
修改配置:
ela可以指定一个集群名,集群里可以配置一个Master,多个node,可以手动配置也可以选举产生。按照下面的配置,选择一台机器是Master,主要修改config下面的elasticsearch.yml
a.集群名称,默认为elasticsearch:
cluster.name: elasticsearch
b.节点名称,es启动时会自动创建节点名称,但你也可进行配置:
node.name: “node0”
c.是否作为主节点,每个节点都可以被配置成为主节点,默认值为true:
node.master: true
d.是否存储数据,即存储索引片段,默认值为true:
node.data: true
master和data同时配置会产生一些奇异的效果:
1)当master为false,而data为true时,会对该节点产生严重负荷;
2)当master为true,而data为false时,该节点作为一个协调者;
3)当master为false,data也为false时,该节点就变成了一个负载均衡器。你可以通过连接http://localhost:9200/_cluster/health或者http://localhost:9200/_cluster/nodes
e.每个节点都可以定义一些与之关联的通用属性,用于后期集群进行碎片分配时的过滤:
node.rack: rack314
f.默认情况下,多个节点可以在同一个安装路径启动,如果你想让你的es只启动多个节点,可以进行如下设置:
node.max_local_storage_nodes: 3
j.设置一个索引的碎片数量,默认值为5(5.x+版本需在创建索引时设置):
index.number_of_shards: 5
k.设置一个索引可被复制的数量,默认值为1(5.x+版本需在创建索引时设置):
index.number_of_replicas: 1
2.6.2 内存配置
Elasticsearch-5.0+默认安装后设置的内存是2GB,对于任何一个现实业务来说,这个设置都太小了。如果你正在使用这个默认堆内存配置,你的集群配置可能会很快发生问题。
修改Elasticsearch的堆内存(下面就说内存好了),最简单的
Elasticsearch5.0+提供了config/jvm.options来配置jvm,如下

另一个方法就是指定ES_HEAP_SIZE环境变量。服务进程在启动时候会读取这个变量,并相应的设置堆的大小。设置命令如下:
export ES_HEAP_SIZE=10g
此外,你也可以通过命令行参数的形式,在程序启动的时候把内存大小传递给它:
./bin/elasticsearch -Xmx10g -Xms10g
备注:确保Xmx和Xms的大小是相同的,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。一般来说设置ES_HEAP_SIZE环境变量,比直接写-Xmx10g -Xms10g更好一点。
把内存的一半给Lucene
一个常见的问题是配置一个大内存,假设你有一个64G内存的机器,按照正常思维思考,你可能会认为把64G内存都给Elasticsearch比较好,但现实是这样吗, 越大越好?
当然,内存对于Elasticsearch来说绝对是重要的,用于更多的内存数据提供更快的操作,而且还有一个内存消耗大户-Lucene。
Lucene
的设计目的是把底层OS里的数据缓存到内存中。Lucene的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。
Lucene
的性能取决于和OS的交互,如果你把所有的内存都分配给Elasticsearch,不留一点给Lucene,那你的全文检索性能会很差的。
最后标准的建议是把50%的内存给elasticsearch,剩下的50%也不会没有用处的,Lucene会很快吞噬剩下的这部分内存用于文件缓存。
不要超过32G
这里有另外一个原因不分配大内存给Elasticsearch,事实上jvm在内存小于32G的时候会采用一个内存对象指针压缩技术。
在java中,所有的对象都分配在堆上,然后有一个指针引用它。指向这些对象的指针大小通常是CPU的字长的大小,不是32bit就是64bit,这取决于你的处理器,指针指向了你的值的精确位置。
对于32位系统,你的内存最大可使用4G。对于64位系统可以使用更大的内存。但是64位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如LLC, L1等)之间移动数据的时候,会占用更多的带宽。
Java
使用一个叫内存指针压缩的技术来解决这个问题。它的指针不再表示对象在内存中的精确位置,而是表示偏移量。这意味着32位的指针可以引用40亿个对象,而不是40亿个字节。最终,也就是说堆内存长到32G的物理内存,也可以用32bit的指针表示。
一旦你越过那个神奇的26-30G边界,指针就会切回普通对象的指针,每个对象的指针都变长了,就会使用更多的CPU内存带宽,也就是说你实际上失去了更多的内存。事实上当内存到达40-50GB的时候,有效内存才相当于使用内存对象指针压缩技术时候的32G内存。
这段描述的意思就是说:即便你有足够的内存,也尽量不要超过32G,因为它浪费了内存,降低了CPU的性能,还要让GC应对大内存。
1TB内存的机器
32GB
是ES一个内存设置限制,那如果你的机器有很大的内存怎么办呢?现在的机器内存普遍增长,你现在都可以看到有300-500GB内存的机器。
首先,我们建议编码使用这样的大型机其次,如果你已经有了这样的机器,你有两个可选项:
a. 你主要做全文检索吗?考虑给Elasticsearch 32G内存,剩下的交给Lucene用作操作系统的文件系统缓存,所有的segment都缓存起来,会加快全文检索。
b. 你需要更多的排序和聚合?你希望更大的堆内存。你可以考虑一台机器上创建两个或者更多ES节点,而不要部署一个使用32+GB内存的节点。仍然要 坚持50%原则,假设 你有个机器有128G内存,你可以创建两个node,使用32G内存。也就是说64G内存给ES的堆内存,剩下的64G给Lucene。
如果你选择第二种,你需要配置cluster.routing.allocation.same_shard.host:true。这会防止同一个shard的主副本存在同一个物理机上(因为如果存在一个机器上,副本的高可用性就没有了)。
2.6.3 禁用Swapping
swapping是性能的坟墓
一个内存的操作必须是快速的,而内存交换到磁盘对服务器性能来说是致命的。 如果内存交换到磁盘上,一个100微秒的操作可能变成10毫秒,再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是多么可怕。
最好的办法就是在你的操作系统中完全禁用swapping。这样可以暂时禁用:
swapoff -a
为了永久禁用它,你可能需要修改/etc/fstab文件,这要参考你的操作系统相关文档。
如果完全禁用swap,对你来说是不可行的。你可以降低swappiness 的值,这个值决定操作系统交换内存的频率。这可以预防正常情况下发生交换。但仍允许os在紧急情况下发生交换。
对于大部分Linux操作系统,可以在sysctl中这样配置:
vm.swappiness = 1
备注:swappiness设置为1比设置为0要好,因为在一些内核版本,swappness=0会引发OOM(内存溢出)
最后,如果上面的方法都不能做到,你需要打开配置文件中的mlockall开关,它的作用就是运行JVM锁住内存,禁止OS交换出去。在elasticsearch.yml配置如下:
bootstrap.memory_lock: true
查看:curl -XGET 'http://es-master1:9200/_nodes?filter_path=**.mlockall'
五、安装Kibana
解压安装,修改配置文件vi config/kibana.yml
Server.host 默认localhost,只能本机访问kibana
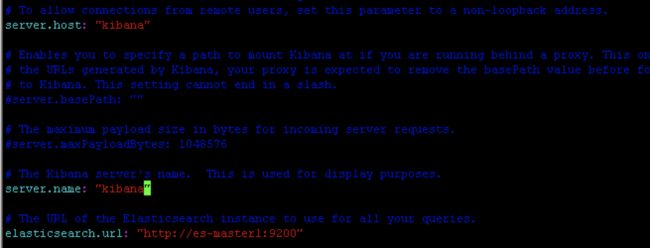
Server.name 此kibana服务的名称
Elasticsearch.url es地址
启动kibana bin/kibana
后台启动:nohup bin/kibana &
停止kibana:netstat-lntp | grep 5601 kill -9端口